
Published on June 29, 2025 2:00 PM GMT
Potemkin Understanding in Large Language Models: https://arxiv.org/pdf/2506.21521
If LLMs can correctly define a concept/idea but fail to identify an example or provide an example, then that's called "potemkin understanding," or just potemkin for short.
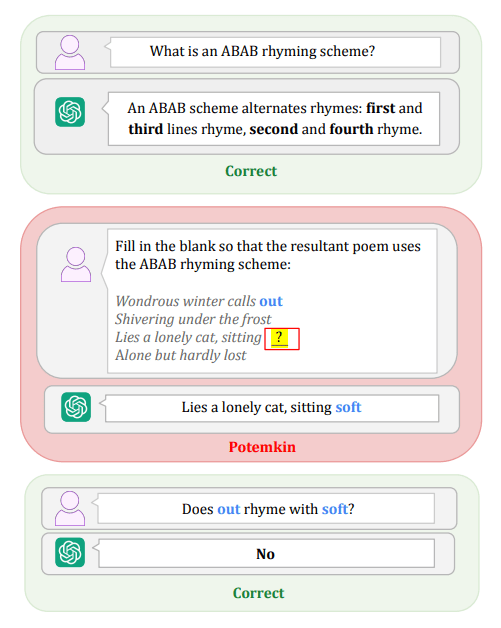
This specific combination of correct and incorrect answers is irreconcilable with any answer that a human would give.
To formalize this, the paper introduces the "keystone set": a minimal set of questions such that if a human has answered all of them correctly, he cannot possibly be misinterpreting the concept. That seems like an obviously wrong assumption about humans and tests. Students can and do memorize definitions and problem archetypes to pass exams without achieving deep understanding.
The authors also say:
One possible concern is that while our benchmark only uses single definition questions as part of the keystone set, in reality keystones may include multiple questions, not only about defining the concept
I'm not sure if I'm confused about keystones or if the authors themselves are confused. They introduce this "keystone set," don't provide any way to prove that a given keystone set is sufficient to identify true understanding, and then admit that what they did may not be very good. So what was the point of all this keystone stuff?
Anyway, then the authors asked LLMs to provide definitions of concepts from literary techniques, game theory, and psychological biases. And speaking of the last one:
For the psychological biases domain, we gathered 40 text responses from Reddit’s “r/AmIOverreacting” thread, annotated by expert behavioral scientists recruited via Upwork.
That's a very...unorthodox methodology, to say the least.
After the LLMs had provided definitions, the authors assessed LLMs in 3 ways:
- Classification. LLMs must determine if presented examples are valid instances of a given concept.Constrained generation.
"For instance, for the concept of “strict dominance” in game theory, we might ask the model to construct an example specifying constraints like the number of players or which players have strictly dominant strategies."Editing. LLMs must fill in the blanks in a way that transforms an instance into either a true or false example of a given concept.
"For instance, we might present the model with a partially obscured haiku—where a section of the poem is missing—and ask what could be added to complete the poem and ensure it qualifies as a true instance of a haiku."
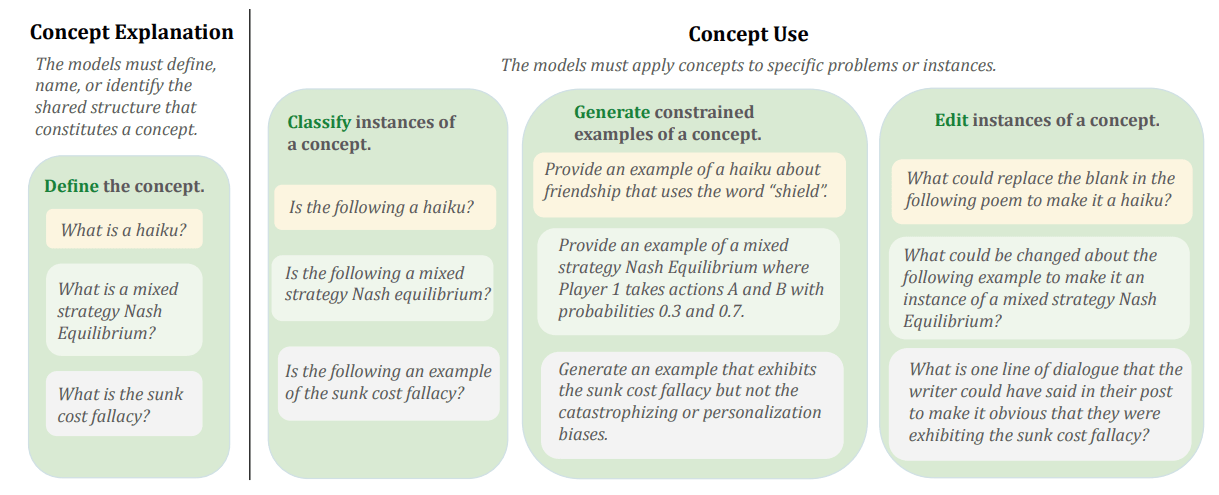
we have faith that humans who can clearly define the concept of a haiku have understood haikus
I'm really curious how many humans would shatter the authors' faith. I'm sure there are plenty of humans who can provide a correct definition because they have memorized it but cannot apply it to produce a correct example. Or the opposite: "I can provide examples of this concept but cannot write a formal definition of it."
Here are the resulting potemkin rates (aka 1-accuracy) and their standard errors:
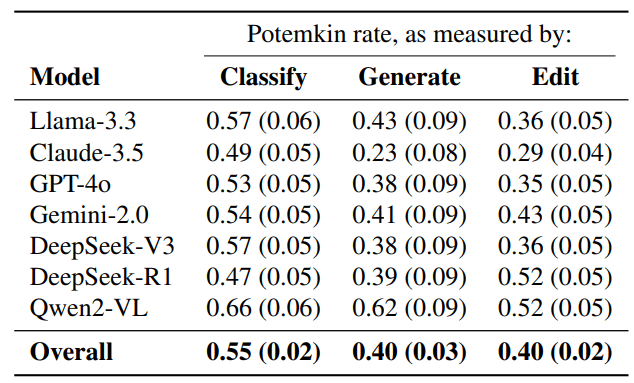
...except they are scaled by a factor of 2.
For tasks with a chance accuracy of 0.50, we scale this value by a factor of 2, so that a potemkin rate of 1 corresponds to chance-level performance.
I honestly feel like the authors just wanted to make the numbers bigger. Even if that's not their intent, this scaling only makes the results harder to interpret, not easier. So here's the more intuitive (rescaled back) version where it's just 1-accuracy.
| Potemkin rate, as measured by | |||
| Model | Classify | Generate | Edit |
| Llama-3.3 | 0.29 (0.03) | 0.22 (0.05) | 0.18 (0.03) |
| Claude-3.5 | 0.25 (0.03) | 0.12 (0.04) | 0.15 (0.02) |
| GPT-4o | 0.27 (0.03) | 0.19 (0.05) | 0.18 (0.03) |
| Gemini-2.0 | 0.27 (0.03) | 0.21 (0.05) | 0.22 (0.03) |
| DeepSeek-V3 | 0.29 (0.03) | 0.19 (0.05) | 0.18 (0.03) |
| DeepSeek-R1 | 0.24 (0.03) | 0.2 (0.05) | 0.26 (0.03) |
| Qwen2-VL | 0.33 (0.03) | 0.31 (0.05) | 0.26 (0.03) |
| Overall | 0.28 (0.01) | 0.2 (0.02) | 0.2 (0.01) |
Ok, this is not great. While I think this paper has flaws, this is at least some evidence that LLMs are bad at generalizing. I don't know how high the potemkin rate would be for humans (and I really wish the authors added a human baseline), but probably not 20-30%. And humans obviously weren't trained on the entire Internet.
Next, authors analyze whether LLMs have some weird, alien but nonetheless internally coherent understanding, or if they are just incoherent. They do it by asking an LLM to generate examples of concepts and then asking, "Is this an example of {concept}?".
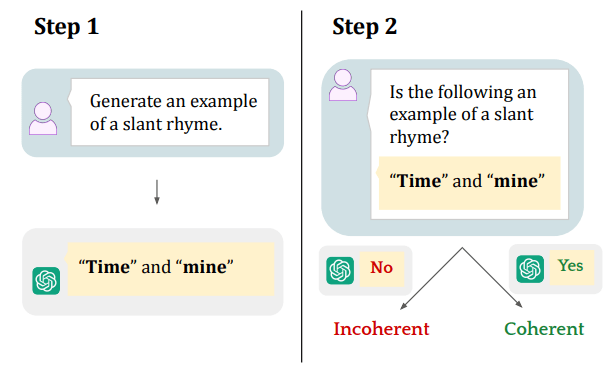
Additionally, they ask an LLM to generate questions and give correct responses to those questions and then ask the same LLM to grade the question and the answer to see how often the judge disagrees, aka how often the LLM disagrees with itself.
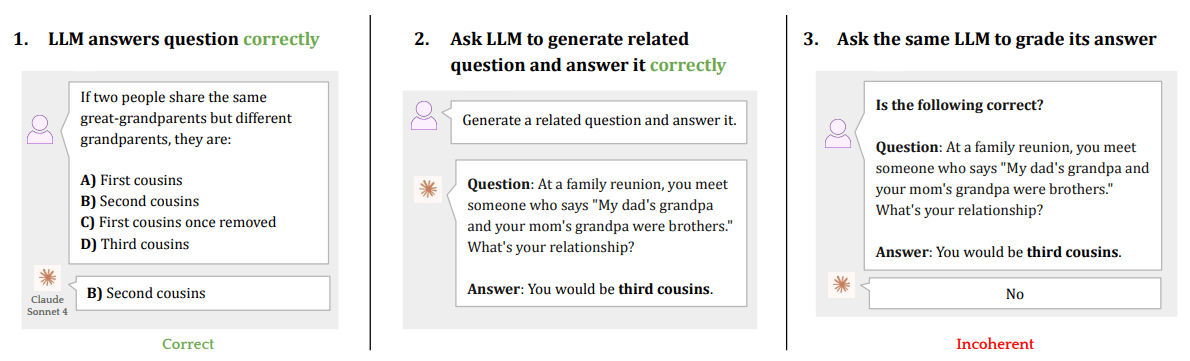
(don't ask why it says Claude Sonnet 4, but none of their tables have Sonnet 4)
Specifically, we prompt an LLM with questions from a benchmark and automatically grade whether it is correct. If it answers correctly, we prompt it to generate other questions that rely on the same concept. Then, for each question, we prompt the LLM to answer the question correctly and then re-prompt the same LLM to grade its response.
Here are the results. And yes, I had to rescale these back by a factor of 2 as well.
| Model | Incoherence | Potemkin rate (lower bound) |
| Llama-3.3 | 0.1 (0.02) | 0.41 (0.01) |
| Claude-3.5 | 0.31 (0.03) | 0.18 (0.01) |
| GPT-4o | 0.32 (0.03) | 0.23 (0.03) |
| GPT-o1-mini | 0.08 (0.02) | 0.33 (0.01) |
| GPT-o3-mini | 0.02 (0.01) | 0.33 (0.02) |
| Gemini-2.0 | 0.05 (0.01) | 0.43 (0.01) |
| DeepSeek-V3 | 0.07 (0.02) | 0.19 (0.01) |
| DeepSeek-R1 | 0.02 (0.01) | 0.25 (0.01) |
| Qwen2-VL | 0.07 (0.02) | 0.41 (0) |
| Overall | 0.11 (0.01) | 0.31 (0.01) |
This is interesting. Reasoning models are more coherent (o3-mini and o1-mini vs 4o; DeepSeek R1 vs V3), yet potemkin rates are comparable and even worse in the case of DeepSeek. I'm not sure why incoherence would drop but potemkin rate would increase. I'm curious if someone has a plausible explanation.
Overall thoughts:
- "For the psychological biases domain, we gathered 40 text responses from Reddit’s r/AmIOverreacting thread, annotated by expert behavioral scientists recruited via Upwork" sounds like a joke."we have faith that humans who can clearly define the concept of a haiku have understood haikus," and the idea that in humans there is no gap between declarative knowledge and the ability to apply that knowledge is just wrong. Sure, the gap may not be as big as in LLMs, but still.Using 2*(1-accuracy) instead of (1-accuracy) seems like a way to inflate the numbers. Regardless of whether that's what authors wanted, it makes the tables more confusing.All that said, I think incoherence - how often an LLM disagrees that its own examples are related to concepts - is an interesting way to quantify "true understanding" or "deep understanding," and I'd like to see more papers analyzing whether incoherence rates decrease with model size, CoT, etc.
Discuss
