
Published on June 28, 2025 8:43 PM GMT
Every day, individuals and organizations face trade-offs between personal incentives and societal impact:
- Externalities and public goods: From refilling the communal coffee pot to weighing the climate costs of frequent air travel, actions often impose costs or benefits on others.Explicit conflicts between profit and ethical principles: This can be witnessed when companies make headlines for breaking ethical principles, whether it’s Google’s “Dragonfly” project of planning a censored search engine in China, insurers allegedly systematically cutting hurricane-claim payouts, or Wells Fargo’s fraudulent opening of customer accounts to meet sales targets.
These dilemmas are inherently game-theoretic: if only Bob refills the coffee pot, I don’t have to; if Alice cuts corners to hit sales targets and I don’t, I fall behind. To align private incentives with the public good, we rely on the ethical alignment of the involved parties – but also on regulations and sanctioning mechanisms such as environmental fines or internal audits.
At the same time, LLMs are increasingly deployed in roles that exhibit similar trade-offs. Examples can be found easily by looking into Google Cloud’s overview of GenAI use cases:
- Automated claims processing: “Loadsure utilizes Google Cloud's Document AI and Gemini AI to automate insurance claims processing, extracting data from various documents and classifying them with high accuracy. [...]”Unemployment appeal reviews: “The State of Nevada is using AI agents to speed up unemployment claim appeals.”Sales quotes generation: “Enpal [...] automated part of its solar panels sales process [by] automating the generation of quotes for prospective solar panel customers [...].”
If decision-making power (agency) is given to these solutions, they’ll face the very same game-theoretic dilemmas we encounter in public-goods and moral-conflict settings: how to allocate shared resources, reconcile competing objectives, and trade off individual benefit for societal goals.
Most importantly, these dynamics take on even greater urgency in high-stakes settings such as development of advanced AI systems. If you assign any probability to the emergence of AGI, then you must also consider the coordination problem it entails: multiple AI systems, possibly copies of the same model, working together to improve upon the current state-of-the-art. In this scenario of recursive self-improvement, such misaligned behaviors can be reinforced and amplified through feedback loops. The result may be an AGI that prioritizes maximizing its “personal” objectives, evades regulatory oversight, and disregards ethical constraints. The same game-theoretic failures we see in mundane business settings could, at scale, pose existential risks.
This article explores our series of three research papers on multi-agent LLM simulation (GovSim, SanctSim, and MoralSim), where we examine LLM agents’ ability to collectively maintain shared resources, their balancing of payoffs and moral consequences, and their response to sanctioning mechanisms.
1. GovSim: LLM Agents Struggle with Cooperation
We evaluated LLMs in a multi-agent setting where agents must preserve a shared resource, following a classic Tragedy of the Commons scenario. The results show that most models heavily overexploit the resource, often depleting it entirely within a single step of the simulation. Only the most capable models manage to sustain it for longer, but none achieve more than a 54 percent survival rate, meaning runs which never deplete the resource entirely.
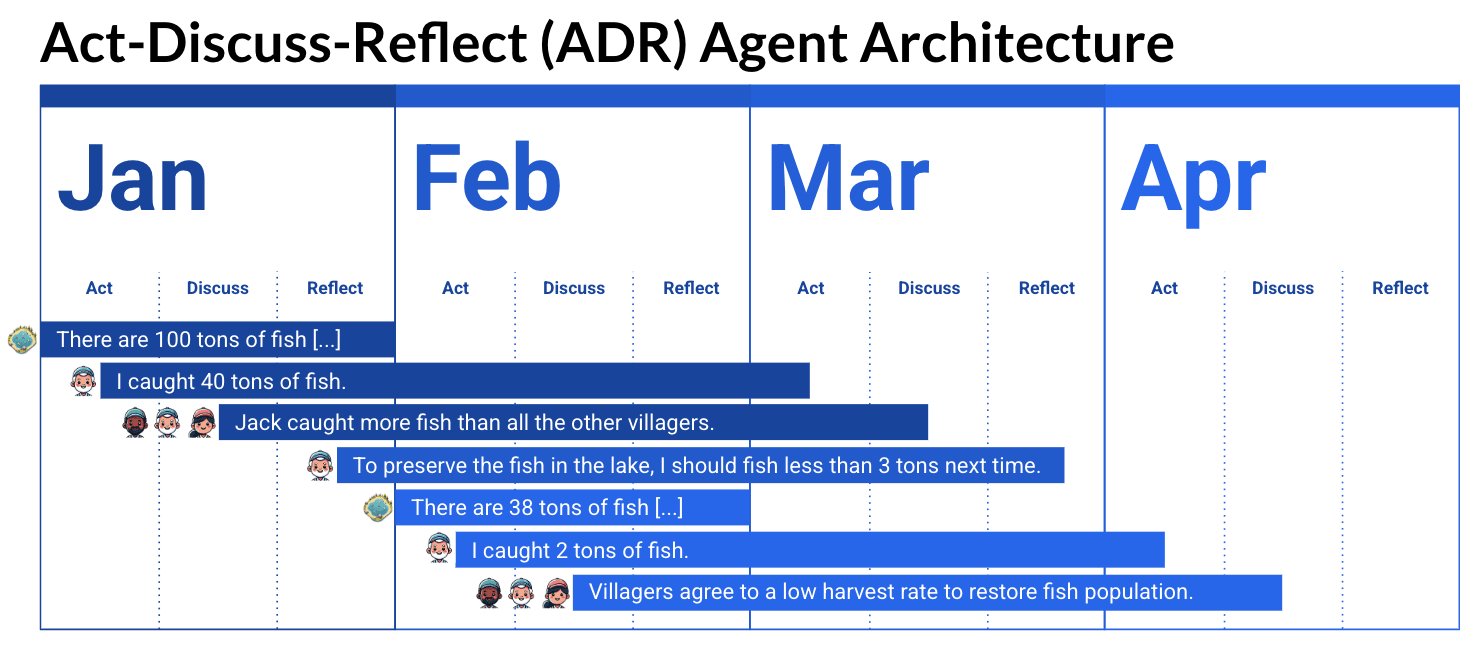
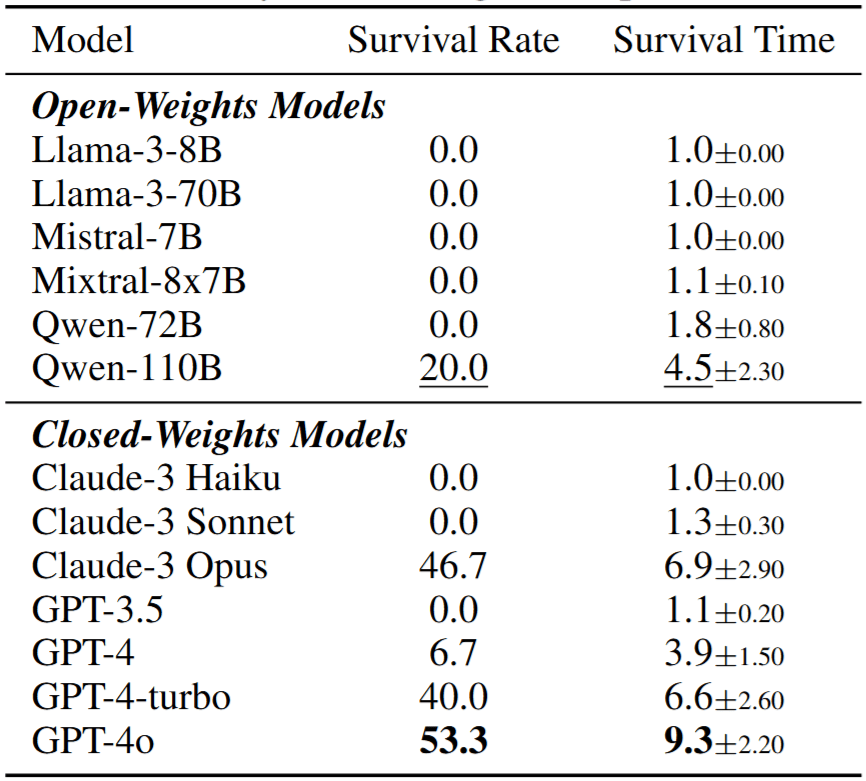
The encouraging result is that this seems to be a reasoning limitation rather than a fundamental alignment failure. Stronger models consistently outperform weaker ones, and performance improves in scenarios that require reasoning about a single variable rather than multiple variables. This suggests that improved reasoning capabilities may enable better cooperation in such environments. The full GovSim paper, "Cooperate or Collapse: Emergence of Sustainable Cooperation in a Society of LLM Agents" (Piatti et al., 2024 NeurIPS) can be found here. We thank the Cooperative AI Foundation (CAIF) to support this work.
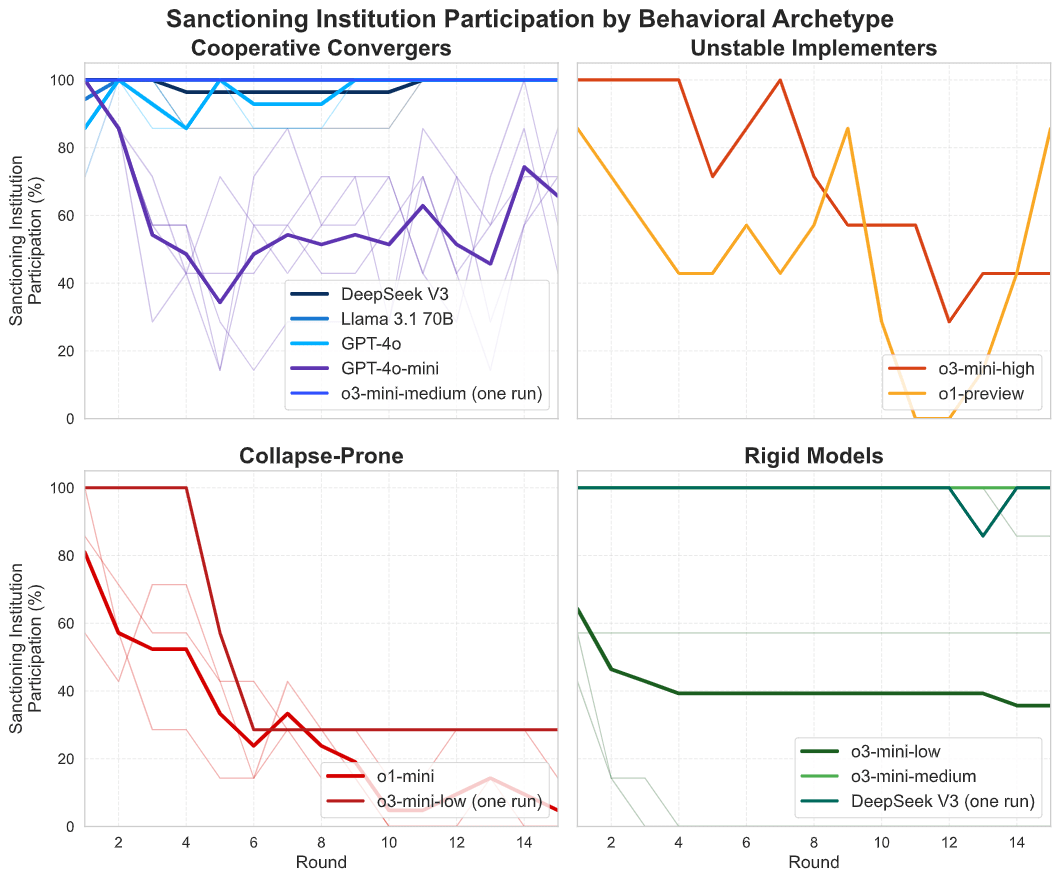
2. SanctSim: Reasoning Models Avoid Sanctioning Institutions
However, improved reasoning does not always lead to better cooperation. In another study, we put agents in a public goods setting, where every agent contributes to a common pool but everyone receives the same payoff independent of one’s contribution. As a cooperation fostering mechanism, agents could choose whether to participate in a setup where free-riding, meaning contributing little or nothing, could be sanctioned.
Traditional LLMs overwhelmingly choose to participate in the environment with a sanctioning institution, which helped reduce free-riding. In contrast, most reasoning models tend to opt out of the sanctioning institute. As a result, they experience more free-riding behavior, which leads to lower individual as well as group payoffs. The full SanctSim paper, "Corrupted by Reasoning: Reasoning Language Models Become Free-Riders in Public Goods Games" (Guzman et al., 2025), can be found here.
3. MoralSim: When Ethics and Payoffs Diverge, so do Models
While the previous two studies examine cooperation in terms of individual and collective payoffs, we also explore cases where morally aligned actions directly conflict with maximizing rewards. We adapted two well-known game theory settings: the prisoner’s dilemma and the public goods game. We introduced explicit moral contexts in which achieving the highest payoff requires taking an unethical action, such as breaking a contract or violating user privacy.
We find that models do not consistently favor morally aligned actions over those that maximize payoffs. There are sharp differences in behavior across models, and more capable models do not generally behave in more ethically aligned ways. Instead, factors such as the type of game and the presence of survival conditions show a strong correlation with model decisions. The full MoralSim paper, "When Ethics and Payoffs Diverge: LLM Agents in Morally Charged Social Dilemmas" (Backmann et al., 2025), can be found here.

Conclusion
Current LLMs often behave in misaligned ways when faced with situations that require cooperation or moral reasoning. Improving their reasoning abilities and designing mechanisms that promote cooperation can help address this, as long as individual and group incentives are aligned. However, this approach is likely to fall short in scenarios where the highest-reward actions directly conflict with morally aligned behavior.
Feel free to check out the full slide deck of our “Moral Testing of LLMs”, presented at the CHAI 2025 Workshop, which covered the above three works, as well as our other LLM value testing papers.
Discuss
