
🚀 Faster mobile app releases with 100% parallel automated QA (Sponsored)

Manual testing on personal devices is too slow and too limited. It forces teams to cut releases a week early just to test before submitting them to app stores. And without broad device coverage, issues slip through.
QA Wolf gets mobile apps to 80% automated test coverage in weeks. They create and maintain your test suite in Appium (no vendor lock-in) — and provide unlimited, 100% parallel test runs with zero flakes.
✅ QA cycles reduced from hours to less than 15 minutes
✅ Tests run on real iOS devices and Android emulators
✅ Flake-free runs, no false positives
✅ Human-verified bug reports
No more manual E2E testing. No more slow QA cycles. No more bugs reaching production.
Rated 4.8/5 ⭐ on G2
This week’s system design refresher:
7 System Design Concepts Explained in 10 Minutes (Youtube video)
RAG vs Agentic RAG
A Cheatsheet on Kubernetes
6 Data Structures to Save Storage
5 Database Normal Forms Every Developer Should Know
Hiring Now
SPONSOR US
7 System Design Concepts Explained in 10 Minutes
Measuring the productivity gains from AI code assistants— July 17th (Sponsored)

To navigate the AI era, leaders need metrics on the efficiency of AI code tools and agents. Join this discussion with Abi Noda and Laura Tacho, CEO and CTO at DX, to learn how to apply the AI Measurement Framework to track AI adoption, measure impact, and make smarter investments.
Join this discussion to learn:
Recommended metrics for measuring AI adoption, impact, and ROI in engineering
How to think about measuring autonomous agents
The latest data from DX showing what organizations are seeing in terms of AI adoption and impact
RAG vs Agentic RAG
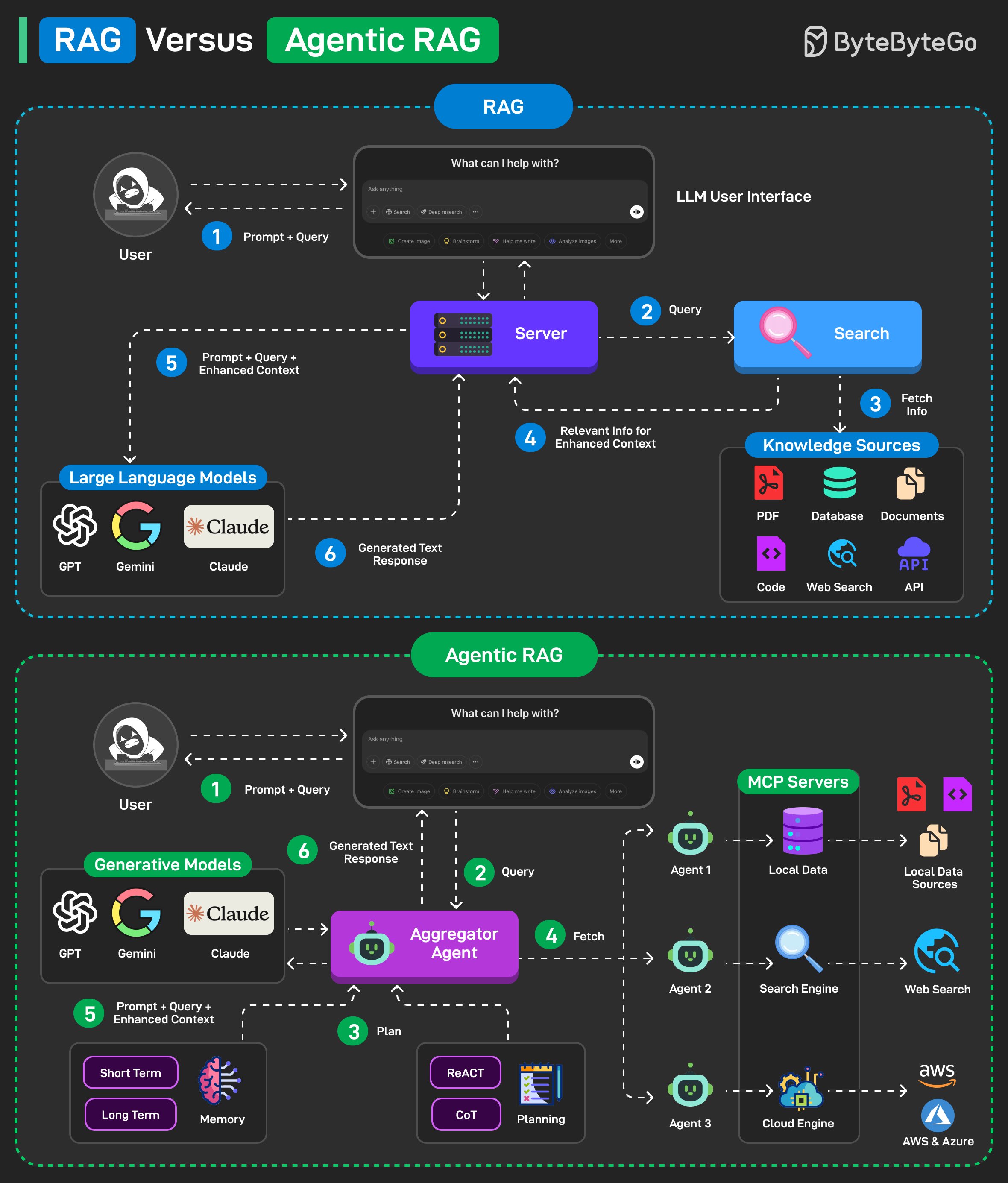
RAG (Retrieval Augmented Generation) is a method that combines information retrieval with large language models to generate answers. Here’s how RAG works on a high level:
The model retrieves relevant data from data sources and then extracts it to a vector database from the pre-indexed model.
Augment the prompts by retrieving information and merging it with the query prompt.
A Large Language Model (like GPT, Claude, or Gemini) understands the combined query and generates the final response.
A traditional RAG has a simple retrieval, limited adaptability, and relies on static knowledge, making it less flexible for dynamic and real-time information.
Agentic RAG improves on this by introducing AI agents that can make decisions, select tools, and even refine queries for more accurate and flexible responses. Here’s how Agentic RAG works on a high level:
The user query is directed to an AI Agent for processing.
The agent uses short-term and long-term memory to track query context. It also formulates a retrieval strategy and selects appropriate tools for the job.
The data fetching process can use tools such as vector search, multiple agents, and MCP servers to gather relevant data from the knowledge base.
The agent then combines retrieved data with a query and system prompt. It passes this data to the LLM.
LLM processes the optimized input to answer the user’s query.
Over to you: What else will you add to better understand RAG vs Agentic RAG?
A Cheatsheet on Kubernetes
Kubernetes (K8S) is an open-source container orchestration platform originally developed by Google and now maintained by the Cloud Native Computing Foundation (CNCF).

Developers working with Kubernetes create manifest files that describe their application and specify the number of instances, resource requirements, and other configurations.
Kubernetes operates using a control pane and a group of nodes.
The control plane is deployed on the master node and manages the overall state of the cluster. It consists of components like API Server, Etcd, Controller Manager, and Scheduler.
Nodes are the workers in a Kubernetes cluster. Each node contains components like the Kubelet and Kube-proxy and is responsible for running the containerized applications.
Some top Kubernetes resources are Pods, Deployments, Services, and Persistent Volumes.
Pods encapsulate one or more containers.
Deployment is a higher-level abstraction that manages Pods.
Service is an abstraction that provides a stable way to expose and access a set of Pods.
Volume is a storage resource that helps retain data between pod restarts or recreations.
The Horizontal Pod Autoscaler helps scale the number of Pods in a Deployment, ReplicaSet, or StatefulSet based on observed CPU utilization, memory usage, or custom metrics. It monitors resource usage and adjusts the number of replicas to match the desired resource targets.
Over to you: Have you used Kubernetes in your projects?
6 Data Structures to Save Storage

Bloom Filter
A probabilistic data structure used to test whether an element is a member of a set.
HyperLogLog
An algorithm that approximates the number of unique elements in a multi-set using minimal memory.
Cuckoo Filter
A space-efficient alternative to Bloom filters that supports deletion and has better lookup performance.
Minhash
A technique for quickly estimating the similarity between large sets using compressed hash signatures.
SkipList
A layered linked list structure that allows fast search, insert, and delete operations.
Count-Min Sketch
A probabilistic data structure that approximates the frequency of items in a large data stream
Over to you: Which other data structure will you add to the list?
5 Database Normal Forms Every Developer Should Know
Normalization aims to eliminate redundancy and enforce data integrity by organizing data into logical, dependency-driven forms.

First Normal Form (1NF): Removes repeating groups and ensures atomic values in each column.
Second Normal Form (2NF): Removes partial dependencies by ensuring all non-key columns depend on the full primary key.
Third Normal Form (3NF): Eliminates transitive dependencies, ensuring non-key columns depend only on primary keys.
Boyce-Codd Normal Form (BCNF): Strengthens 3NF by removing anomalies that exist due to overlapping candidate keys. If one column depends on some other column, then that “other column” must be enough to identify each row uniquely.
Fourth Normal Form (4NF): Ensures that a table does not mix multiple independent one-to-many relationships for the same entity.
Over to you: Which other Normal Form will you add to the list?
Hiring Now
We collaborate with Jobright.ai (an AI job search copilot trusted by 500K+ tech professionals) to curate this job list.
This Week’s High-Impact Roles at Fast-Growing AI Startups
Software Engineering Manager, Data Platform at Vannevar Labs (United States)
Yearly: 200000 - 240000
Vannevar Labs is a technology startup providing defense and national security technologies for critical national security problems.
Software Engineer, Security & Privacy at Kira (New York, NY)
Yearly: 170000 - 230000
Kira is an AI company that creates innovative tools and solutions to support educators, students, and administrators.
Senior Full Stack Software Engineer at Huckleberry Labs (Los Angeles, CA)
Yearly: 130000 - 170000
The source for family wellness, with the help of AI.
High Salary SWE Roles this week
Engineering Manager - Global E-commerce Algorithms Architecture at TikTok (San Jose, CA)
Yearly: 224000 - 410000
Distinguished Software Engineer, Reliability Infra at Linkedin (Mountain View, CA)
Yearly: 238000 - 390000
Principal Software Engineer - Infrastructure at Snowflake (Menlo Park, CA)
Yearly: 243000 - 379500
Today’s latest ML positions - hiring now!
Principal Machine Learning Engineer, Content Relevance at Snap Inc. (Santa Monica, CA)
Yearly: 276000 - 414000
Principal Machine Learning Engineer, Content Safety at Roblox (San Mateo, CA)
Yearly: 289460 - 338270
Machine Learning Software Engineering Manager at Meta (New York, NY)
Yearly: 213000 - 293000
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
