
谷歌开源模型,又上新了。
今天凌晨,谷歌正式官宣了Gemma 3n,原生支持文本、图像和音视频等多种模态。
在大模型竞技场中,Gemma 3n取得了1303分,成为了第一个超过1300分的10B以下模型。
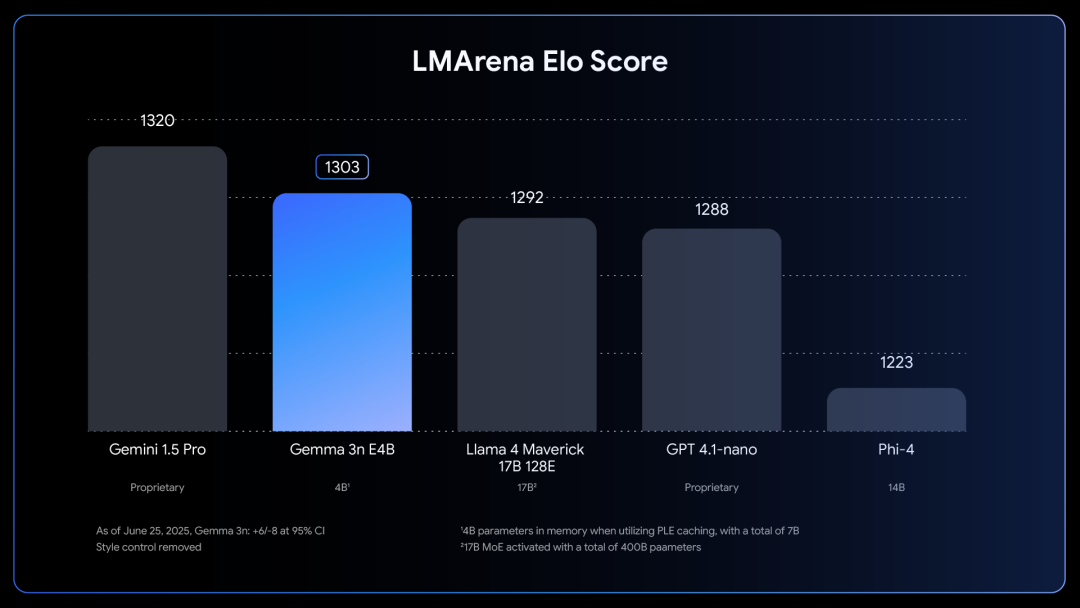
Gemma 3n一共有5B(E2B)和8B(E4B)两种型号,但通过架构创新,其VRAM占用与2B和4B相当,最低只要2GB。
有网友表示,Gemma 3n能够用低内存占用实现这样的表现,对端侧设备意义重大。

目前,Gemma 3n已在谷歌AI Studio或Ollama、llama.cpp等第三方工具中可用,模型权重也可在Hugging Face上下载。
同时谷歌也公开了Gemma 3n的一些技术细节,接下来就一起来了解。
套娃式Transformer架构
在Gemma 3n的两种型号——E2B和E4B中,谷歌提出了“有效参数”的概念,这里的“E”指的就是effective(有效的)。
Gemma 3n的核心是MatFormer (Matryoshka Transformer) 架构 ,这是一种专为弹性推理而构建的嵌套式Transformer结构。
它的结构就如同它的名字一样,像俄罗斯套娃(Matryoshka)——一个较大的模型当中,包含了自身更小、功能齐全的版本。
MatFormer将“俄罗斯套娃表征学习”的概念从单纯的嵌入扩展到所有Transformer组件。

在这种结构下,MatFormer在训练E4B模型时,可以同时优化E2B子模型。
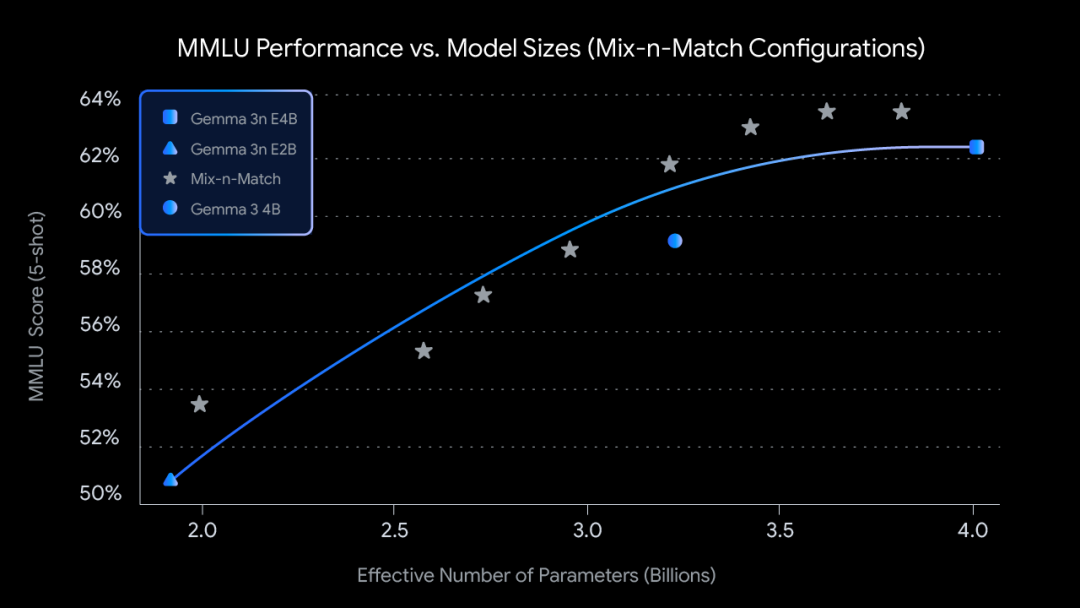
为了根据特定硬件限制进行更精细的控制,谷歌还提出了Mix-n-Match方法,通过调整每层的前馈网络隐藏层维度(从 8192 到 16384)并选择性地跳过某些层,可以实现对E4B模型参数的切片,从而在E2B和E4B之间创建一系列自定义尺寸的模型。
针对这一功能,谷歌还会发布工具MatFormer Lab,用于检索最佳的模型配置。
专为端侧设备设计
Gemma 3n的E2B和E4B两个型号的原始参数量,分别是5B和8B,但消耗与2B和4B相当。这种低内存消耗设计,目的就是能够更好地适配端侧设备。
为此,Gemma 3n模型采用了逐层嵌入(PLE)技术,可显著提高模型质量,而不会增加内存占用。
PLE允许很大一部分参数(与每层相关的嵌入)在CPU上加载并高效计算,这样就只有核心Transformer权重需要存储在加速器内存(VRAM)中。

此外,为了缩短首个Token生成时间,以便更好处理长序列输入,Gemma 3n引入了KV缓存共享。
具体来说,Gemma 3n优化了模型预填充的处理方式,将来自局部和全局注意力机制的中间层的Key和Value直接与所有顶层共享,与Gemma 3-4B相比,预填充性能提升了2倍。
原生支持多模态
Gemma 3n原生支持图像、音视频等多种输入模态。
语音部分,Gemma 3n采用基于USM的高级音频编码器,USM会将每160毫秒的音频转化成一个Token,然后将其作为语言模型的输入进行集成。
它支持自动语音识别(ASR)和自动语音翻译(AST),可以直接在设备上实现高质量的语音-文本转录,还可将口语翻译成另一种语言的文本。
Gemma 3n的音频编码器在发布时已支持处理30秒的音频片段,但底层音频编码器是一个流式编码器,能够通过额外的长音频训练处理任意长度的音频。
视觉方面,Gemma 3n则采用了全新的高效视觉编码器MobileNet-V5-300M。
它支持在端侧处理256x256、512x512和768x768像素的分辨率,在Google Pixel上的处理速度达到了每秒60帧,并且在各种图像和视频理解任务中表现出色。
MobileNet-V5以MobileNet-V4为基础,但架构显著扩大,并采用混合深度金字塔模型,比最大的MobileNet-V4变体大10倍,同时还引入了一种新颖的多尺度融合VLM适配器。
针对MobileNet-V5背后的技术细节,谷歌后续还会发布技术报告,介绍模型架构、数据扩展策略以及背后的数据蒸馏技术。
参考链接:
https://developers.googleblog.com/en/introducing-gemma-3n-developer-guide/
HuggingFace:
https://huggingface.co/collections/google/gemma-3n-685065323f5984ef315c93f4
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
📪 量子位AI主题策划正在征集中!欢迎参与专题365行AI落地方案,一千零一个AI应用,或与我们分享你在寻找的AI产品,或发现的AI新动向。
💬 也欢迎你加入量子位每日AI交流群,一起来畅聊AI吧~

一键关注 👇 点亮星标
内容中包含的图片若涉及版权问题,请及时与我们联系删除
