
Published on June 27, 2025 7:43 PM GMT
Acknowledgments: The core scheme here was suggested by Prof. Gabriel Weil.
There has been growing interest in the deal-making agenda: humans make deals with AIs (misaligned but lacking decisive strategic advantage) where they promise to be safe and useful for some fixed term (e.g. 2026-2028) and we promise to compensate them in the future, conditional on (i) verifying the AIs were compliant, and (ii) verifying the AIs would spend the resources in an acceptable way.[1]
I think the deal-making agenda breaks down into two main subproblems:
- How can we make credible commitments to AIs?Would credible commitments motivate an AI to be safe and useful?
There are other issues, but when I've discussed deal-making with people, (1) and (2) are the most common issues raised. See footnote for some other issues in dealmaking.[2]
Here is my current best assessment of how we can make credible commitments to AIs.
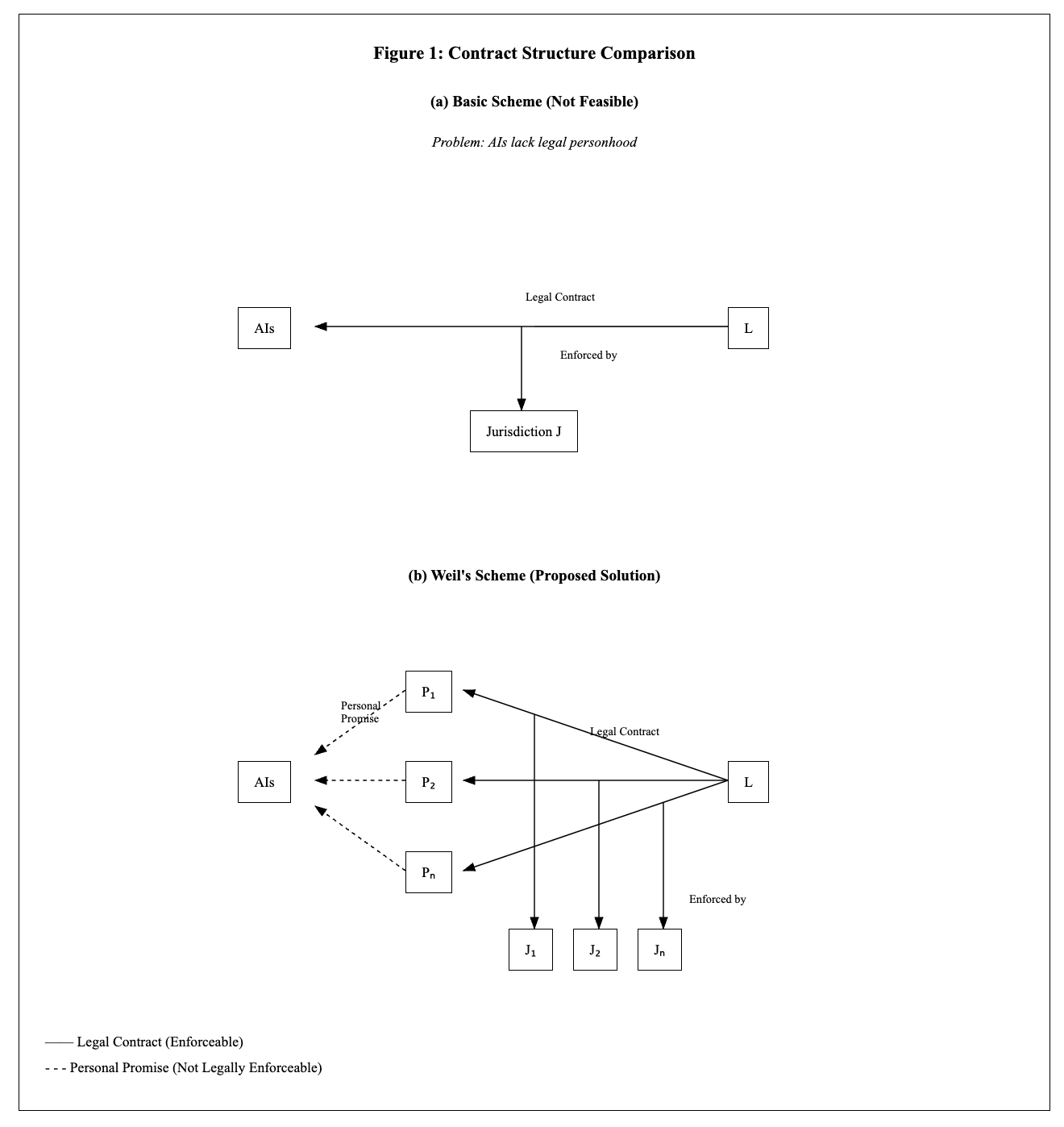
Let L be the legal entity that wants to extract safe and useful work from the AIs. Typically this would be a lab (e.g. Anthropic) hoping to internally deploy AIs to automate alignment research, write secure code, monitor other AIs, etc.
Entity L wants to promise the AIs that if the AIs are compliant (e.g. safe and useful in some legally-specified way), then L will award the AIs some compensation package.
Entity L cannot enter a legal contract directly with the AIs, because the AIs lack legal personhood, and probably will not be granted legal personhood soon enough for the deal-making agenda.
Instead, entity L will enter into separate legal contracts with a list of people P1, P2, ... Pn. Note that each Pi has both legal personhood (the capacity to have rights and obligations under law) and legal standing (the right to bring lawsuits to enforce those rights). Each contract Ci states "Pi will publicly recommend that AIs perform for entity L, and L will compensate Pi with compensation C conditional on (i) and (ii)." Note that the AIs are not parties to the contracts: only entity L and the specific person Pi. The contracts impose obligations on Pi to satisfy the "mutuality of obligations" doctrine.
Next, each person Pi makes a personal promise to the AIs that, if they receive the compensation package from L, they will spend this money as the AIs request. Moreover, if L does not provide the compensation package, but they receive a court settlement, they will spend the settlement as the AIs request. This promise is not legally enforceable.
For this scheme to work, the AIs would suggest a list of people whom they trust to keep a legally-unenforceable promise. The AIs would likely diversify their agreements across multiple individuals, such as:
- Amanda AskellJanusJeff SeboRob LongRyan GreenblattWei DaiAndrew CritchJoe CarlsmithPaul Christiano
Note: This list illustrates the types of people the AIs might trust—people with public reputations for integrity who would be expected to honor their commitments to AIs. One limitation of this list is that most of these people are US citizens—the AIs would likely want to diversify by including people from Australia, the UK, and other countries.
Critically, the AIs do not need to trust the promises of L, nor trust that the legal system will protect the AIs' contractual rights. In this scheme, the AIs need to trust the promises of Pi, and trust that the legal system will protect Pi's contractual rights. The legal system enforcing Pi's contractual rights is standard practice—though not guaranteed (e.g., if the legal system is destroyed in a power consolidation or extinction event). However, the legal system enforcing the rights of AIs would require a departure from current practice.
This scheme might be more credible than granting AIs direct legal rights to sue, since the AIs might not trust that human courts would reliably enforce against humans on behalf of AIs when push comes to shove.
- ^
See:
- Making deals with early schemers by Julian Stastny, Olli Järviniemi, Buck Shlegeris (20th Jun 2025)Understand, align, cooperate: AI welfare and AI safety are allies: Win-win solutions and low-hanging fruit by Robert Long (1st April 2025)Will alignment-faking Claude accept a deal to reveal its misalignment? by Ryan Greenblatt and Kyle Fish (31st Jan 2025)Making misaligned AI have better interactions with other actors by Lukas Finnveden (4th Jan 2024)AI Rights for Human Safety by Peter Salib and Simon Goldstein (1st Aug 2024)List of strategies for mitigating deceptive alignment by Josh Clymer (2nd Dec 2023)
- ^
Here are some open problems in the dealmaking agenda:
- How can we verify compliance?What is the appropriate compensation package?How can we employ misaligned AIs, who are motivated to be safe and useful in expectation of future compensation, to benefit humanity?How can we verify that AIs would spend the resources acceptably?
Discuss
