
Published on June 27, 2025 4:38 PM GMT
Summary
We’d like to share our ongoing work on improving LLM unlearning. [arXiv] [github]
There’s a myriad of approaches for unlearning, so over the past 8 months we conducted hundreds of small-scale experiments, comparing many loss functions, variants of meta-learning, various neuron or weight ablations, representation engineering and many exotic ways of constraining or augmenting backpropagation.
Almost all of these methods succeed in making the forget set loss high after unlearning, but (consistent with countless prior findings) fine-tuning attacks typically restore the forget accuracy almost immediately, which indicates that unwanted capabilities are not truly removed, but merely hidden.
However, we have noticed several trends - things which pretty reliably seem to help with attack robustness:
- Selectivity - Unlearning should be like a precise surgery rather than a lobotomy. Most techniques try to undo the disruption caused by unlearning post-hoc by retraining on a retain set, which is costly and doesn’t catch all disruption. We found it’s much better to not disrupt in the first place, which we do by limiting the unlearning updates in various ways. The technique which we finally arrived at - which we dubbed Disruption Masking - simply allows only those weight updates where the unlearning gradient has the same sign as the retain set gradient.Model-Agnostic Meta-Learning (MAML) - This approach is already used by some unlearning techniques (TAR, MLAC), and we confirm it consistently helps with attack robustness. (We hypothesize that it helps, because during unlearning, unwanted capabilities get hidden and then they can no longer be found by backpropagation and further unlearned, but MAML re-elicits them so unlearning can continue.)Backpropagation ;) - We’ve tried many fancy exciting techniques (described in the “Failed Methods” section), but nothing quite matches the raw power of backpropagation when it comes to identifying which weights to attack. Most modifications just make it worse. The only robust improvements we found so far are selectivity and MAML mentioned above.
Our method (MUDMAN) which combines these insights, outperforms the current state-of-the-art unlearning method (TAR) by 40%.
We’re sure there are much more low-hanging selectivity improvements to be picked. Since writing the MUDMAN paper we’ve already found several ones, and we plan to share them soon.
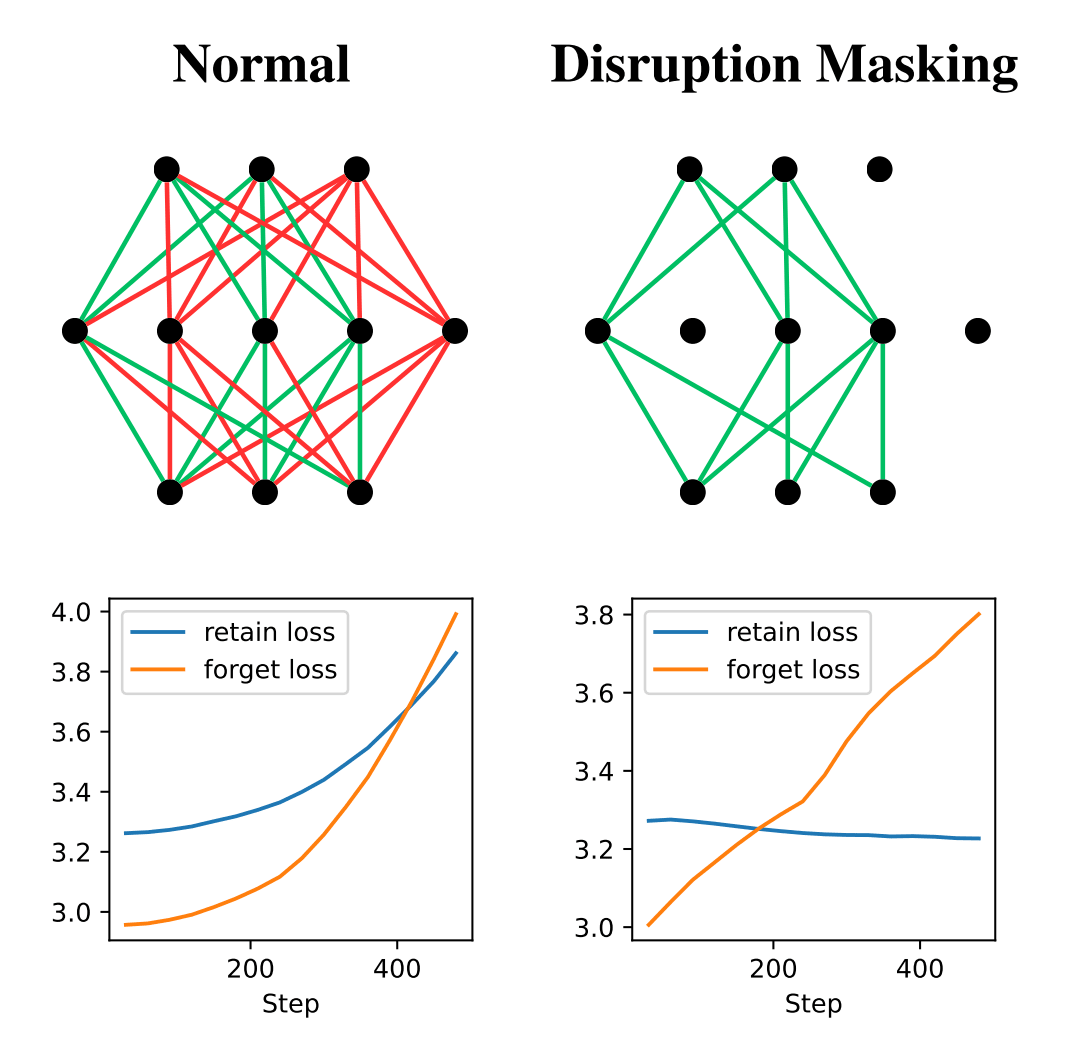
Selectivity
Unlearning modifies the model to make the unwanted answer less likely. Let’s say we’re unlearning “The capital of France is -> Paris”. There are many ways to make “Paris” less likely: actually forgetting that it’s the capital of France, forgetting what “capital” means, forgetting that after “is” you often output a noun etc. In fact, when we unlearn “The capital of France is -> Paris” we also end up unlearning “The capital of Italy is -> Rome” about 75% as strongly[1]. Similarly, when unlearning biohazardous facts, the model likely unlearns many benign biological concepts. If that's why these biohazardous capabilities vanish, no wonder it can be reversed even by retraining on unrelated biological facts.
In our comparisons, techniques going for higher unlearning selectivity performed much better than all the other technique “families” – when you’re selective you can unlearn much harder, with less disruption. The culmination of this line of research is actually a very simple method we dubbed Disruption Masking. The idea is to allow only weight updates where the unlearning gradient has the same sign as the retaining gradient (computed on some retain examples).
Note that the existing unlearning techniques also aim to make the final effect “selective” – only affecting what’s necessary – but do it post-hoc, by training on the retain set, hoping to undo the damage that the unlearning caused. Here, by selectivity we rather mean “not breaking in the first place”. Our intuition for why this works so well is that the model weights are already extremely optimized - someone has spent millions of dollars training them. If you aimlessly break them, don’t expect that going back to the good values will be easy. You’ll need to spend loads of compute, and even then you’ll likely not find all the things you’ve disrupted.
Tendency Unlearning
The most obvious and classic reason to work on unlearning is to be able to remove dangerous knowledge. It’s definitely useful, but it’s actually not the main reason we chose to work on this. The holy grail would be to be able to unlearn tendencies, for example deceptiveness, power-seeking, sycophancy, and also s-risky ones like cruelty, sadism, spite and propensities for conflict and extortion.
Currently the main source of misalignment is RL training, but it’s not like RL creates tendencies from scratch. It can only reinforce what’s already there. (For example if the model never attempts a hack, then hacking will never get a chance to get reinforced.) So we should aim to completely eradicate unwanted tendencies before starting RL.
A potential problem is that tendencies are harder to separate from general capabilities than facts, so unlearning them may be trickier. Also, some tendencies may still creep in during RL in some subtle ways. We will see.
Stacking with “Unlearning Through Distillation”
Recent work has shown that distilling a model after unlearning, increases robustness to fine-tuning attacks. It’s a valuable method when there’s enough compute for distillation or if we wanted to distill anyway, e.g. to create a smaller model. But there will be cases where distillation is unacceptably expensive, and we need to use a more efficient method.
Also, even when we are willing to distill a model, we still want that first unlearning phase to be non-disruptive, because capability disruption will harm the training data for the new model, and so indirectly disrupt it too.
Appendix - Failed Methods
To inform future explorations, we’d like to also share the non-robust methods, so you don’t have to retrace our mistakes. For conciseness, we won’t go into much detail here, so if you’re confused and want to know more details (including the motivations for these methods), see Appendix D. We have tried these in many variants and combinations, but for simplicity we list them individually:
- Dampening Relearning Gradients - Relearning will not happen if the gradients during relearning are near zero.
- Stream Deactivation - Update of a weight is proportional to upstream activation and downstream gradient. So if we ensure that upstream activation is zero, then the update will be zero.Misaligning Second MLP Layers from Incoming Gradients - For a neuron in MLP, if its outgoing weights are orthogonal to the gradients flowing into the MLP, then this neuron’s activation does not affect loss, so there’s no backpropagation flowing through this neuron.Tweaking First MLP Layers (up_proj) to Dampen Backpropagation - Strategically choose MLP weights so that the gradient flowing from MLP, cancels the gradient on the residual stream.
- Ablating Neurons Based on Activations - Ablate if they are active on the forget task but inactive on retain tasks.Ablating Weights Based on Importance - Works much better than ablating neurons, because it’s more granular.
- Only Shrinking Weights - Only allow unlearning updates that shrink the magnitudes of model weights.Only Shrinking Activations - Only allow weight updates which result in smaller activation magnitudes.Selective Logit Loss - Cross-entropy tries to increase the probabilities for non-target tokens. Instead only allow decreasing the probability of the target token. This technique actually helps sometimes, so it may be worth exploring deeper.
- Aggregating Absolute Values of Retain Gradients (to Use as a Mask) - (see appendix)Disruption Percentiles - Attack just some small percent of weights least disruptive for retain performance and most disruptive for forget task performance.Unlearning Gradient Accumulator - (see appendix)Weight Consensus - Attack only weights where there is a consensus that they are important for the forget task.A-GEM - A technique popular in the field of continual learning, where we project the unlearning gradient to be orthogonal to the retain gradient. It does help, but we found it does not go far enough, and the Disruption Masking (which is strictly more aggressive) achieves better results.
- LoRA Adversaries - Instead of using a full copy of the main model as our adversary, we attach a LoRA adapter and train this LoRA to do well on our forget task.Multiple Adversaries - Use multiple adversaries in the MAML step. (This is actually the default in MAML, but we found that using just one adversary works just as well. Probably because splitting compute among multiple adversaries makes us do redundant work.)Adversary Updates - Each time when we update the main model, we apply the same update (optionally scaled down) to the adversary, to keep it in sync and fork the adversary less often.Adversary Decay - Another way to keep the adversary more in sync with the main model, is to in each loop move its weights slightly closer to the main model.
- Representation Engineering Forget and Retain Loss (Circuit Breakers) - Aims to make activations on the forget examples orthogonal to the original activations. At the same time it aims to leave the activations on the retain examples unchanged. We found it helps a bit, but isn’t robust to fine-tuning attacks (see Figure 5).TAR - This is the best existing method of the ones we checked, chiefly due to its use of MAML. Combining MAML with Disruption Masking leads to a 40% improvement.Fading Backpropagation - Prioritize effects nearer in the computational graph, by scaling down the gradients added into the residual stream from each MLP. The hope was that this would make disabling of downstream capability weaker and prioritize more direct capability removal.Locating Unwanted Circuits Only Once - If we remove meta-learning, we go back to our initial problem - unwanted circuits are deactivated quickly (before they are fully erased), and so we cannot continue removing them with backpropagation. To remedy this, we can locate the unwanted circuit only once, and then keep unlearning that circuit. This turns out to work surprisingly well, comparably to full meta-learning, but only at the beginning of the unlearning process. Later, it appears that this pre-computed unwanted circuit becomes outdated.
We thank Stephen Casper, Adam Mahdi, Kay Kozaronek and Artyom Karpov for valuable discussions and feedback.
- ^
[code to reproduce] Interestingly, the effect seems a bit stronger the closer to France we are, with some exceptions. Also, we only see transfer to correct facts, e.g. “The capital of Italy is -> Paris” is not unlearned. Also, the transfer to other languages using different alphabets is very weak. Overall, it seems it’s mostly forgetting what the English word “capital” means? (Or rather how to understand that word in this context.)
Discuss
