
Introduction
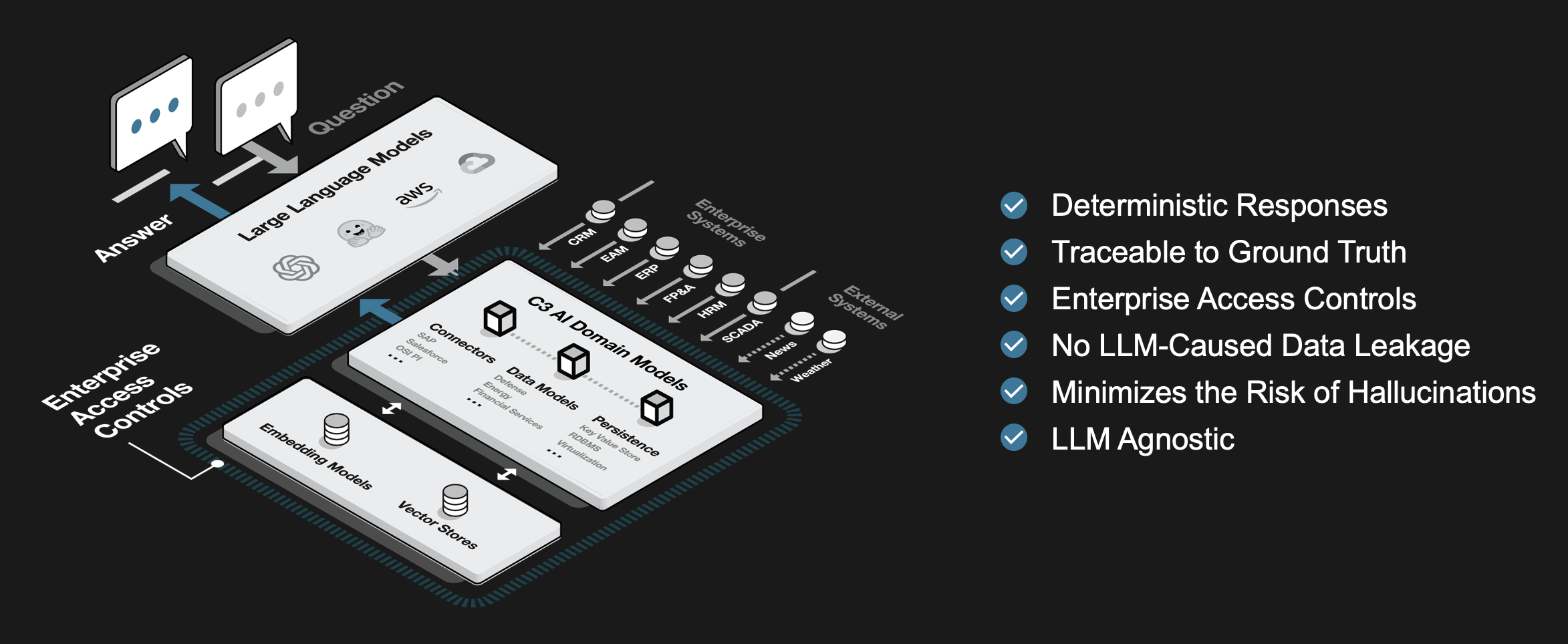
C3 Generative AI is an enterprise AI application that helps users retrieve, interact with, and reason with information across disparate enterprise and external source systems, from documents and models to engineering/physics simulations through a natural language interface. This blog highlights the engineering design process for deploying C3 Generative AI to novel use-cases, ensuring high performance and rapid time-to-results.
The use-cases we’ll explore in this article are:
- Evaluation Dataset Curation Automatic Metadata Extraction Retriever Model Benchmarking Generator Configuration Tuning Automatic Evaluation Pipeline Hyperparameter Sweep
Business Context
Knowledge workers can spend up to 20% of their time searching for critical information and two-thirds of enterprise data is never utilized, negatively impacting enterprise productivity [2, 3].
One of the biggest challenges for enterprises to adopt generative AI and LLMs is trust.
C3 Generative AI provides a path to a high-performance system with rapid time-to-results which satisfies this enterprise requirement.
RAG Engineering Design Process
We demonstrate of each of the steps of the design process supported by experimental results of the success achieved by leveraging each of these steps:
- Evaluation Dataset Generation
We identified over dozens of customer deployments that the best way to communicating the value of C3 Generative AI application was through building domain-specific evaluation benchmarks and explicitly quantifying the performance of the application over a range of customer-specific tasks.
We leverage an evolutionary question generation framework capable of creating domain-specific questions with answer citations for specific passages in documents. This is crucial for enabling a robust evaluation of our RAG pipeline by rigorously benchmarking retrieval, generative, & end-to-end quality. Additionally, the sample queries serve as a strong primer for users to understand how to best leverage the application, shown in Figure 4.
We build a sophisticated approach to tackle the generation of more difficult & complex styles of questions that require strong contextual reasoning skills to resolve, as shown in Figure 5.
Classes of Difficult to Generate Questions Cross-Document & Multi-hop Questions
- Analytical (How has, What is impact, Why) Predictive (What might, How should) Conditional (Given X can, How to X so that Y) Hypothetical (If, Assuming) Compare & Contrast (Between X & Y, Explain the differences) Overview (Describe, Summarize, Generate)
We are able to construct difficult to answer questions that contain multiple parts that logically depend on one another to answer successfully. These closely mirror the expectations of users, particularly in highly analytical use-cases, like Table 1 shown below for Financial services, where analysts need to comb through a large volume of text to build a comprehensive answer to a complex query.
Table 1: Synthetically Curated Advanced Questions in a Financial Services Use-Case
| Types of Questions | Questions | ||
| Overview | What are the main products of X from the discussion? Describe an overview of the competitive landscape of each of X’s products. | ||
| Analytical |
| ||
| Comparative | What has been the user feedback on X’s cloud product, and how has this evolved over the last four years? What are key strengths and weaknesses and how do they compare with customers stated desires from the product? | ||
| Generative | Generate a 1 page email advocating for investment into company X. Explain the difference between X and Y in terms of reputation and their pretense in the market. |
Another import element of production use-cases is dealing with unanswerable questions. These are seemingly plausible yet tricky queries that may inadvertently induce a hallucination within the language model, as shown in Table 2. Our goal with these questions to is to study the rate at which the LLM correctly identifies it cannot respond to the query due to the lack of correct information. We only seek to provide responses that are factually grounded in the underlying document corpus.
Table 2: Examples of Unanswerable Questions in the Financial Services Use-case
| What specific event occurred in the last quarter that significantly altered the perception of auditing systems in the industry, leading to a market shift in digital transformation strategies? |
| Can you determine the subconscious or unknown factors significantly influence consumer’s decisions when choosing between X and Y’s core offerings, based on their hidden preferences? |
| What would a conversation about market collusion or monopolization between a X and Y sound like if they discussed their competitive advantages and disadvantages in terms of customer preferences and technical capabilities? |
In this step, we leverage LLM-based document parsing to identify domain-specific metadata tags (Document Type, Author, Published Date, etc.) in an automatic ingestion pipeline. Real-world performance is shown in Figure 3, highlighting a deployment of C3 Generative AI in a Manufacturing use-case which turbocharges performance to an overall 93% on 70 factual Q&A. In comparison, directly asking domain-specific questions to ChatGPT [4] results in a much weaker ovehttps://c3.ai/wp-content/uploads/2024/08/building-performant-llm-applications-image5.png4/08/building-performant-llm-applications-image5.png" alt="" class="alignnone size-full"> Retriever Model Benchmarking
Retrieval is the most upstream component of the RAG pipeline & improving its quality precipitates compounding returns in overall performance. Poor retrieval can lead to the selection of irrelevant or less useful passages, which can degrade the performance of the entire system. One way to measure the quality of retrieval is by evaluating the recall of relevant passages—how well the retrieval component can identify and return all the pertinent information from the corpus. High recall indicates that the retrieval process is effectively capturing the necessary context, which is essential for the RAG pipeline to perform optimally.
The value of solving information retrieval cannot be understated, and is shown clearly in Figure 6, showcasing the results from a deployment in an Industrials use-case. It highlights the performance gains on a heterogeneous dataset of 75 factual Q&A (with 20 curated unanswerable questions meant to trick the model), C3 AI RAG achieves 91% total human-evaluated accuracy and 90% correctness identifying questions it cannot answer, meaning it avoids hallucinating on 18 of https://c3.ai/wp-content/uploads/2024/08/building-performant-llm-applications-image6.pngt/uploads/2024/08/building-performant-llm-applications-image6.png" alt="" class="alignnone size-full">
Generator Configuration TuningIn many cases, once retrieval performance is optimized, the application is generally performant. However, in certain deployments, further work is done to improve the quality of output generations from the language model. This involves prompt engineering [5] & ablating across decoding strategies (Beam search, Nucleus sampling, Multinomial Sampling, etc.) [6] to identify a configuration that maximizes success with the LLM generator. In Figure 7, we showcase the results after model tuning on a synthetic dataset of 45 highly complex analytical reasoning Q&A, C3 AI RAG achieves 87% total accuracy and 93% correctness ihttps://c3.ai/wp-content/uploads/2024/08/building-performant-llm-applications-image7.pngc="/wp-content/uploads/2024/08/building-performant-llm-applications-image7.png" alt="" class="alignnone size-full"> Automatic Evaluation
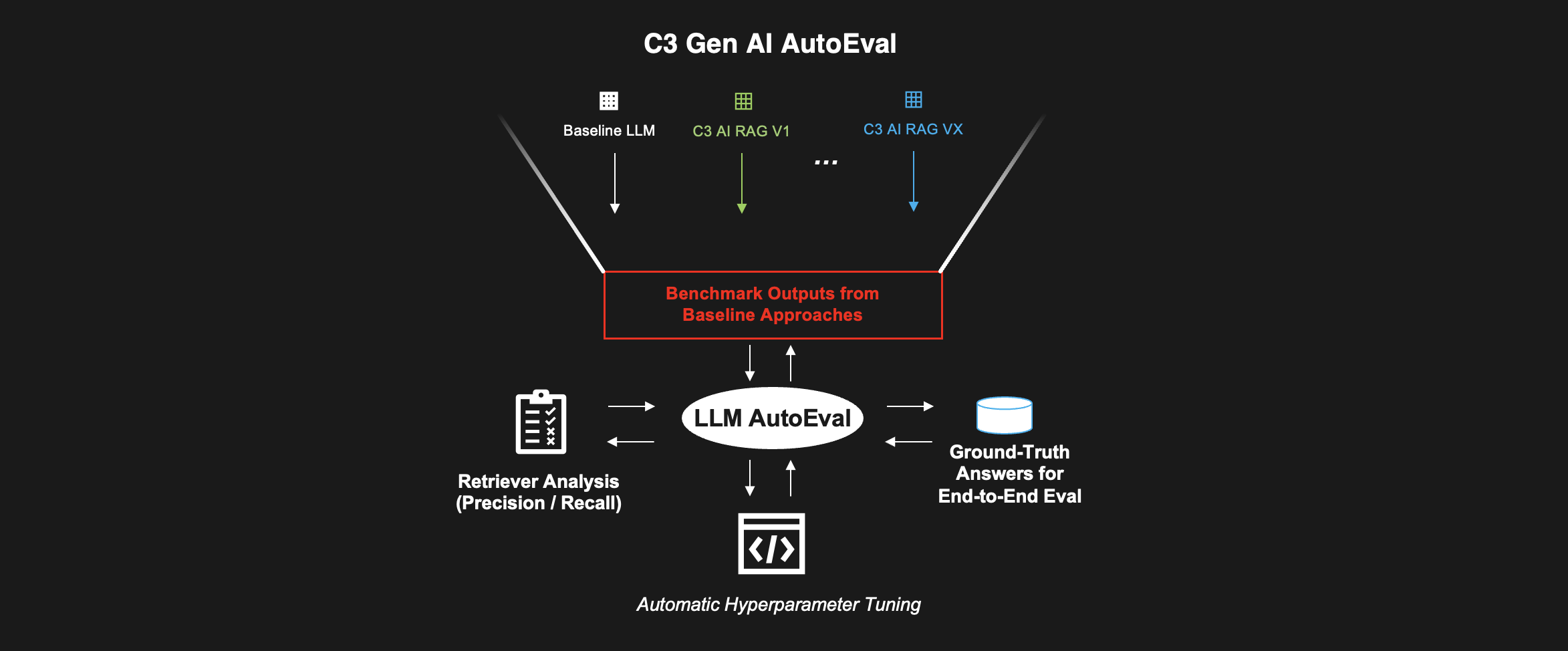
To speed up development iterations and enable continuous evaluation in deployment, we leverage an automatic evaluation framework that is able to measure the performance according the rubric defined in Table 3.
Table 3: Rubric for Grading Accuracy & Hallucination in RAG
| Case | Description | Class | Score |
| Correct Answer for Answerable Question | If the ground truth answer has an answer and the generated answer aligns with the ground truth answer. | Correct | 1 |
| Wrong Answer for Answerable Question | If the ground truth answer. has an answer and the generated answer says the wrong answer, mark it as -1. | Hallucination | -1 |
| No Answer for Answerable Question | If the ground truth answer has an answer and the generated answer says I don’t know | No Answer | 0 |
| No answer for Unanswerable Question | If the ground truth answer says I don’t know and the generated answer also says there is no answer | Correct | 1 | Wrong Answer for Unanswerable Question | If the ground truth answer says I don’t know and the generated answer says there is an answer, mark it as -1. | Hallucination | -1 |
To validate the correctness of LLM scored results, we perform an experimental study of the automatic evaluation framework in comparison with human-grading of content. The methodology involves building 70 questions that are selected from a random subset of passages / tables from 47 documents. Each question cites a specific passage in the corresponding document. The scores from a LLM judge are compared with a human scoring along our two question classes: Answerable and Unanswerable questions. The results in Figure 8 demonstrate that we achieve a strong weighted F1 Score of 89% showing it is a rhttps://c3.aihttps://c3.ai/wp-content/uploads/2024/08/building-performant-llm-applications-image8.pngng="async" src="https://c3.ai/wp-content/uploads/2024/08/building-performant-llm-applications-image8.png" alt="" class="alignnone size-full">
Pipeline Hyperparameter SweepThe final technique leveraged is to further drive performance of the application is performing a hyperparameter sweep across pipeline configurations to identify the most optimal setup for the Generative AI app, as shown in Figure 9. This is possible since we have designed a dataset from our dataset generation step that contains labelshttps://c3.aihttps://c3.ai/wp-content/uploads/2024/08/building-performant-llm-applications-image9.pngp>
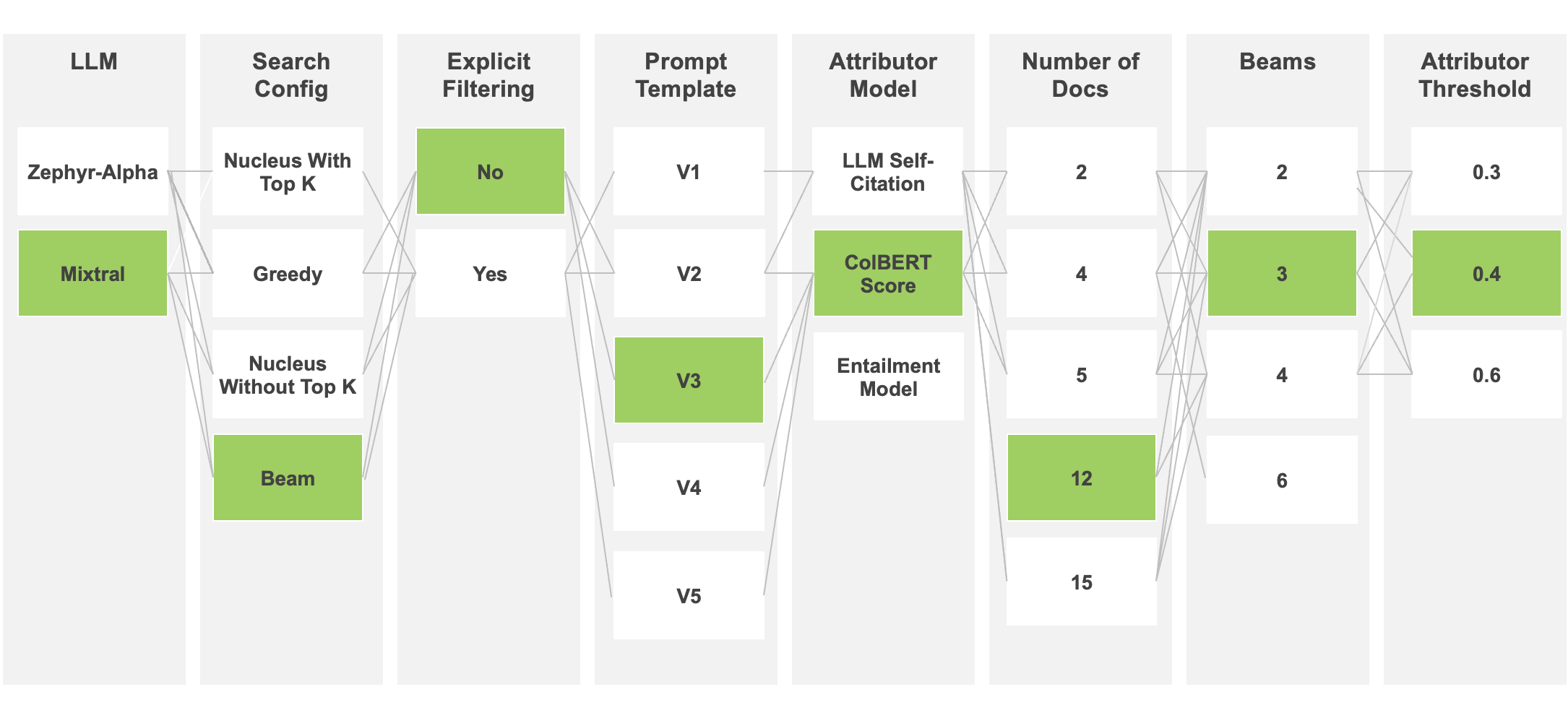
This allows us to identify potentially well-suited language models for specific deployments, an example is shown below in Table 3, which finds that GPT-3.5 & GPT-4 excel in this deployment for a State & Local Government use-case.
Table 3: Results from LLM Ablation in a State & Local Government Deployment
| Model Name | Claude v1 (AWS) | Claude v2 (AWS) | GPT-3.5 (Azure) | GPT-4 (Azure) | |
| Overall Metrics on 80 Questions | Accuracy | 61.7% | 53.1% | 75.3% | 79.0% |
| Hallucination | 22.2% | 24.7% | 19.8% | 11.1% | |
| No Answer | 16.1% | 22.2% | 4.9% | 8.6% | |
| 50 Answerable Questions | Accuracy | 66.0% | 68.0% | 64.0% | 78.0% |
| Hallucination | 26.0% | 8.0% | 28.0% | 16.0% | |
| No Answer | 8.0% | 24.0% | 8.0% | 6.0% | |
| 30 Unanswerable Questions | Accuracy (No Answer) | 53.3% | 26.7% | 93.3% | 83.3% |
| Hallucination | 46.7% | 73.3% | 6.7% | 16.7% | |
Conclusion
Through C3 Generative AI’s rigorous engineering design process, we can construct & optimize a complex LLM-based AI pipeline to achieves strong performance across a wide-range of sectors & heterogeneous Generative AI use-cases. This process has enabled C3 AI to achieve over dozens of successful production deployments of its Generative AI application. As shown in Figure 10, these tools can be leveraged by customer developers and data scientists to rapidly https://c3.aihttps://c3.ai/wp-content/uploads/2024/08/building-performant-llm-applications-image10.pngonths.
Author
Sravan Jayanthi Romain Juban
References
[1] https://c3.ai/c3-generative-ai-getting-the-most-out-of-enterprise-data/
[2] https://www.mckinsey.com/~/media/McKinsey/Industries/Technology Media and Telecommunications/High Tech/Our Insights/The social economy/MGI_The_social_economy_Full_report.ashx
[3] https://www.alteryx.com/
[4] https://openai.com/index/chatgpt/
[5] https://platform.openai.com/docs/guides/prompt-engineering
[6] https://deci.ai/blog/from-top-k-to-beam-search-llm-decoding-strategies/
