
Introduction
C3 Generative AI is revolutionizing how enterprises retrieve, interact with, and reason with information from various sources through a natural language interface. By integrating with disparate enterprise and external systems, from documents and models to engineering/physics simulations through a natural language interface, C3 Generative AI provides a seamless and efficient solution for complex data challenges.
The single most important performance driver for Retrieval Augmented Generation (RAG) in C3 Generative AI is embedding document metadata into document content. Automatic Topic Modeling & Metadata Extraction (ATMME) provides for metadata (i.e. items such as Publisher, Date, Document Type, etc.) curation & extraction with a fully automated end-to-end pipeline. By employing NLP & clustering techniques including named entity recognition and topic modeling, ATMME can curate hierarchical keyword representations of large corpuses of documents, demonstrated in Figure 1. This enables explicit filtering for specific content and provides for stronger retrieval performance and higher end-to-end quality.
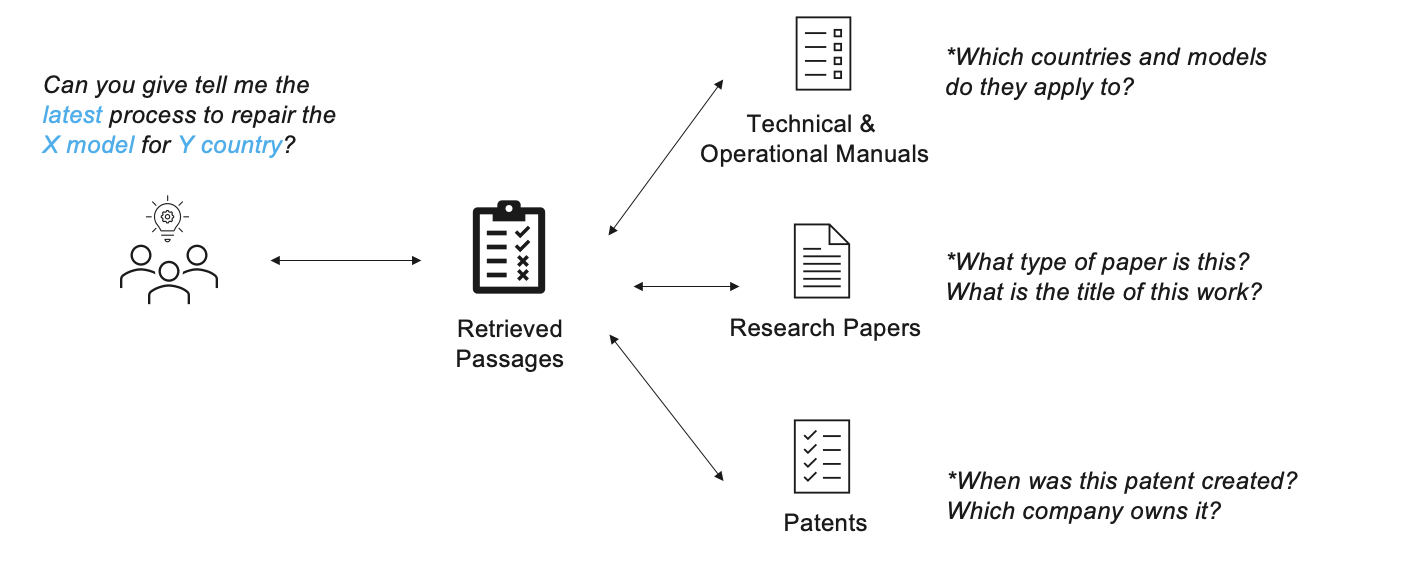
Key Techniques & Methodology
- Topic Models: Utilizing statistical language models, we uncover hidden structures within texts, defining topics as dynamic themes across documents, while categories serve as abstract representations of these themes for tagging purposes. Topic Labeling: We label the set of topics identified based on the keywords that exist for those topics.
Our Solution
The ATMME workflow comprises 2 key steps:
- Build Categorical Representation Named Entity Recognition: Extracting key terms from each document.
Topic Labeling: Assigning labels to identified topics based on extracted key terms.
The goal of this step, shown in Figure 2, is to identify the shared document-specific themes across the corpus and cluster them together to define Categories, themes of important metadata that will improve corpus understanding.
- Extract Metadata
- Entity Tagging: Employing large language model (LLM) and text parsing to extract metadata. Topic Modeling: Grouping extracted terms through few-shot clustering with language models.
The goal of this step, shown in Figure 3, is to scrape relevant values for each of the categories defined in step 1 and tag documents with the corresponding metadata. This can be used in advanced retrieval paradigms such as Knowledge Graph retrieval, Hybrid Keyword + Semantic Search or can be included in the raw document content to improve semantic search quality.
The intuition here is to leverage topic labeling to identify a cluster of documents according to a common theme (i.e. machine type in a manufacturing use-case or company in a financial use-case) and then extract a named entity corresponding to that theme.
Results
These results describe a range of real-world use-cases studied for C3 Generative AI deployments leveraging Automatic Metadata Extraction. In Figure 4, we demonstrate a real-world Industrial use case deploying this routine which by Iteration 2 achieves a strong 93% performance with minimal hallucination in generated responhttps://c3.ai/wp-content/uploads/2024/08/automatic-topic-modeling-metadata-extraction-image4.pngmodeling-metadata-extraction-image4.png" alt="" class="alignnone size-full">
When shipping the application by default without any customization to the use-case, automatic metadata extraction dramatically improves the out-of-the-box performance of C3 Generative AI, as evidenced by Figure 5, showcasing a deployment of C3 Generative AI Enterprise Search for a Financial Shttps://c3.ai/wp-content/uploads/2024/08/automatic-topic-modeling-metadata-extraction-image5.pngomatic-topic-modeling-metadata-extraction-image5.png" alt="" class="alignnone size-full">
As shown in Figure 6, on a challenging use case with where there is a significant repeated content and the user is concerned about retrieving the latest information when the user poses a query asking for (“current”, “recent”, “last week”, etc.) about content from items such ahttps://c3.ai/wp-content/uploads/2024/08/automatic-topic-modeling-metadata-extraction-image6.pngs/2024/08/automatic-topic-modeling-metadata-extraction-image6.png" alt="" class="alignnone size-full">
In Figure 7, we show an ablation study of LLMs used to perform both the task of content categorization and metadata extraction, showcasing the strengths of models such as Claude V1 on entity extraction, topic modeling, and topic labeling. We compare the performance on automatically generated categories by our topic modeling approach described in Step 1 with that of human-crafted metadata categories. Retrieval precision measures the fraction of retrieved documents or items that are relevant to the query or search and NDCG is a measure that considers not only the relevance of the retrieved documents but also their ranking or position in the result list. We compare the results of retrieval performance of the top 3 documents using ColBERT retriever across several prominent LLhttps://c3.ai/wp-content/uploads/2024/08/automatic-topic-modeling-metadata-extraction-image7.pngontent/uploads/2024/08/automatic-topic-modeling-metadata-extraction-image7.png" alt="" class="alignnone size-full">
Figure 7 demonstrates that there is little regression and even stronger performance with certain models in the quality of generated categories with respect to human-crafted classes. In C3 Generative AI, developers and self-service administrators can further edit and refine the generated classes or add custom ones.
Conclusion
ATMME enables us to automate the most important performance driver of C3 Generative AI Enterprise Search. With this feature, self-service customer administrators as well as C3 AI developers and data scientists gain access to advanced metadata extraction, which enhances accuracy during document ingestion, delivering strong performance across use cases and industries.
Author
Sravan Jayanthi Romain Juban
References
https://towardsdatascience.com/end-to-end-topic-modeling-in-python-latent-dirichlet-allocation-lda-35ce4ed6b3e0
https://arxiv.org/abs/1706.03993
https://github.com/explosion/spaCy/blob/master/CITATION.cff
https://arxiv.org/abs/2312.09693
https://medium.com/simula-consulting-deep-tech-consultancy/automatic-topic-labelling-using-nlp-1b92de15edcc
https://arxiv.org/abs/2305.13749
https://arxiv.org/abs/2307.00524
https://en.wikipedia.org/wiki/Evaluation_measures_(information_retrieval)#Precision
https://papers.nips.cc/paper_files/paper/2009/hash/b3967a0e938dc2a6340e258630febd5a-Abstract.html
https://arxiv.org/abs/2112.01488
