
Overview
C3 Generative AI is revolutionizing how enterprises retrieve, interact with, and reason with information from various sources through a natural language interface. By integrating with disparate enterprise and external systems, from documents and models to engineering/physics simulations through a natural language interface, C3 Generative AI provides a seamless and efficient solution for complex data challenges.
The C3 Generative AI Enterprise Search application leverages a customer information corpus to generate responses grounded in their documents. The vast majority of these documents consist of three major modalities of information, namely, pure text, tables, and images content. In order to effectively and reliably retrieve the necessary information for a customer query, we introduce a multimodal approach for extracting information from the documents.
Stage 1: Document Parsing
The content in unstructured documents (i.e. pdf, word, html) comes in three main modalities: Text, Tables and Images. The first stage of enabling a reliable and effective information retrieval from such documents, is parsing and extracting different modalities from these documents. This process can be mostly done in parallel for all different modalities, shown in Figure 1.
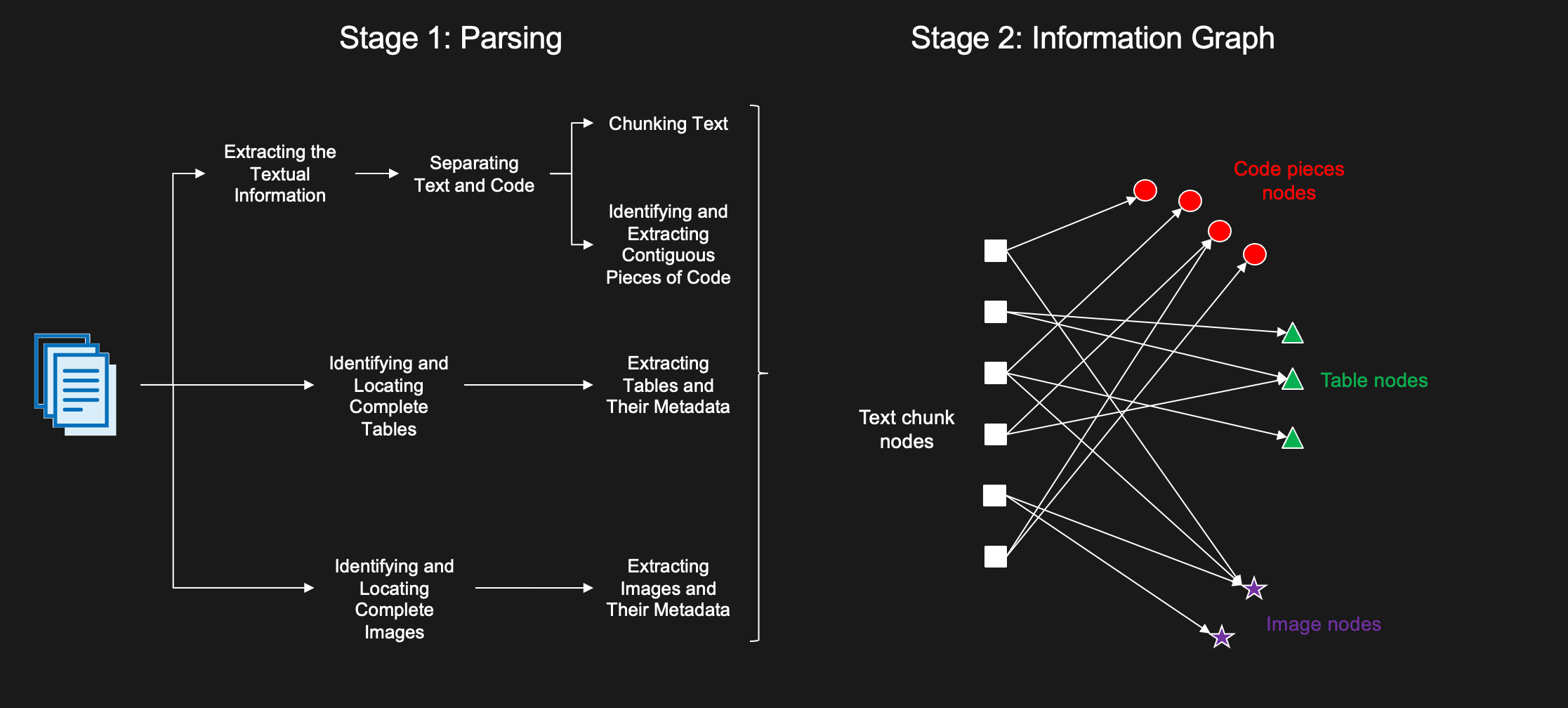
Figure 1: Two-stage process for document parsing & information graph retrieval
a) Parsing text
Depending on the file format, extracting textual information can entail many different difficulties and may require leveraging different libraries. Irrespective of the document type, we need to go through a few steps to prepare for other downstream stages. Depending on the file format, some of these steps may or may not be trivial. Specifically,
- Parsing textual information from the document through file-parsing or OCR-based models. The output of this step needs to include all the textual information (that are not image and table captions) from the documents, which can be then used for further separating text and code pieces. The parsed results need to be with high fidelity (no introduction of random spaces, weird characters that would break the meaning of sentences), and robust to font, size, colors, location with respect to other elements of the pages. Chunking text blocks as contiguous passages. This means not cutting mid-sentence or mid paragraph or splitting due to breakages between pages. We want to capture the document structure in text chunks by ensuring page-level content maps to specific sections and subsections in documents.
We represent this content in an object-oriented fashion with a dedicated class for Text components. These classes, at a minimum, will have fields keeping track of the content, location in the document, number of tokens of the content. Each Text Component may refer to child components representing the subsections or paragraphs created from the chunking process per Figure 2.
Figure 2: Scalable and hierarchical chunking strategy for text components
b) Parsing tables
Documents can contain important structured and numerical data in tables inline within text. To be able to conduct effective information retrieval, we need to first locate and identify tables in full. Tables may be span multiple pages or multiple may appear in a odd ways across a single page and for certain file formats like .pdf or .jpg, this may be quite difficult to extract. Once the tables are identified, they are extracted both as an image and as structured data in a json representation. Then, the table is verbalized to be able to perform text-based semantic search, as shown in Figure 3. We also extract the caption or title of the table, column headers, potentially also the row index(es), as metadata. Similar to Text, we have a Table class that keeps track of the extracted table content, its location, title/caption, and additional metadata.
Figure 3: Table Verbalization stored with text chunks to enable cross-modal information retrieval
c) Parsing images
Documents can contain rich visual content and we seek to parse all figures, diagrams, or images within a document. Similar to how we deal with tables, we also start with identifying and locating images in full, as shown in Figure 4. We can then use an Image class to keep track of the images in the documents, that is the content, the location of the image in the doc and its caption/title as metadata associated withhttps://c3.ai/wp-content/uploads/2024/08/next_gen_image-4.pngnt/uploads/2024/08/next_gen_image-4.png" alt="" class="alignnone size-full">
Figure 4: Image Parsing Workflow using layout detection & image verbalization
We identify all text blocks near the image and parse the relevant text block that represents the corresponding caption for the image, see Figure 5. This is done by scanning several adjacent text blocks and looking for the presence of a keyword (i.e. “figure”, “capthttps://c3.ai/wp-content/uploads/2024/08/next_gen_image-5.pngrc="/wp-content/uploads/2024/08/next_gen_image-5.png" alt="" class="alignnone size-full">
Figure 5: Example of image layout detection & caption parsing
The next step is to verbalize the image content for text-based semantic search using multimodal models such as GPT4-V (closed-source) or Llava (openhttps://c3.aihttps://c3.ai/wp-content/uploads/2024/08/next_gen_image-6.pnging="async" src="https://c3.ai/wp-content/uploads/2024/08/next_gen_image-6.png" alt="" class="alignnone size-full">
Figure 6: Sample verbalization provided by various Vision-Language Models on a parsed figure
With the capability to accurately identify images, this opens up the ability to perform visual question-answering over document content and leverage the sophisticated image understanding capabilities of Large Multimodal Models to answer customer querhttps://c3.aihttps://c3.ai/wp-content/uploads/2024/08/next_gen_image-7.png
Figure 7: Example of visual question-answering with Vision-Language Models
Stage 2: Information Graph
In order to facilitate an effective information retrieval, we represent the information in each document using a so-called information graph, shown in Figure 8. The nodes of this graph correspond to different instances of the 3 classes of modality from Stage 1. This is a directed bipartite graph, with edges going out from the Text nodes to all other modality nodes. Notice that there is an edge between a text node to other modality nodes, if there is reference (relation) between them. This can be established based on explicit references within the document or even bashttps://c3.aihttps://c3.ai/wp-content/uploads/2024/08/next_gen_image-8.pngr title.
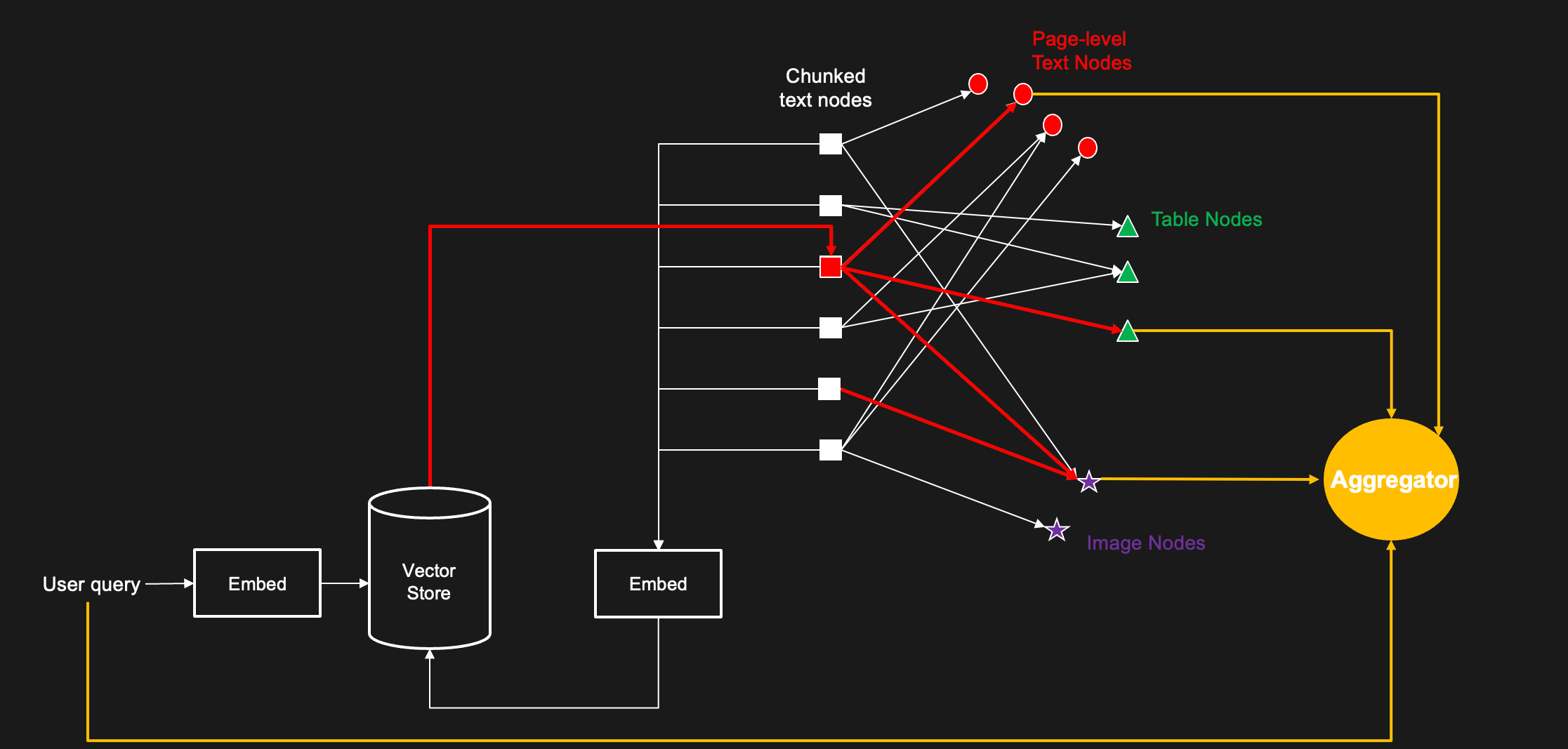
Figure 8: Information Graph that maps text content to underlying multimodal object
Stage 3: Retrieval Process
Given the information graph, we can now outline our process for information retrieval. First, we embed the text content for each node (or other textual metadata associated with other modalities) and storing the embeddings in a vector store. Given a user query, we embed it and find the most relevant text chunks or text nodes associated with it. This would be our entry to the graph. At that point we traverse the graph to other modality nodes. We can extract relevant insights from each modality node given the query (Text, Image, Table). This method can be powered by different approaches, including multi-modal models or other tools for understanding and querying the specific modalities. These insights, together with the text chunks and the user query can then be combined for querying a LLM or Large Multimodalhttps://c3.aihttps://c3.ai/wp-content/uploads/2024/08/next_gen_image-9.pngas shown in Figure 9.
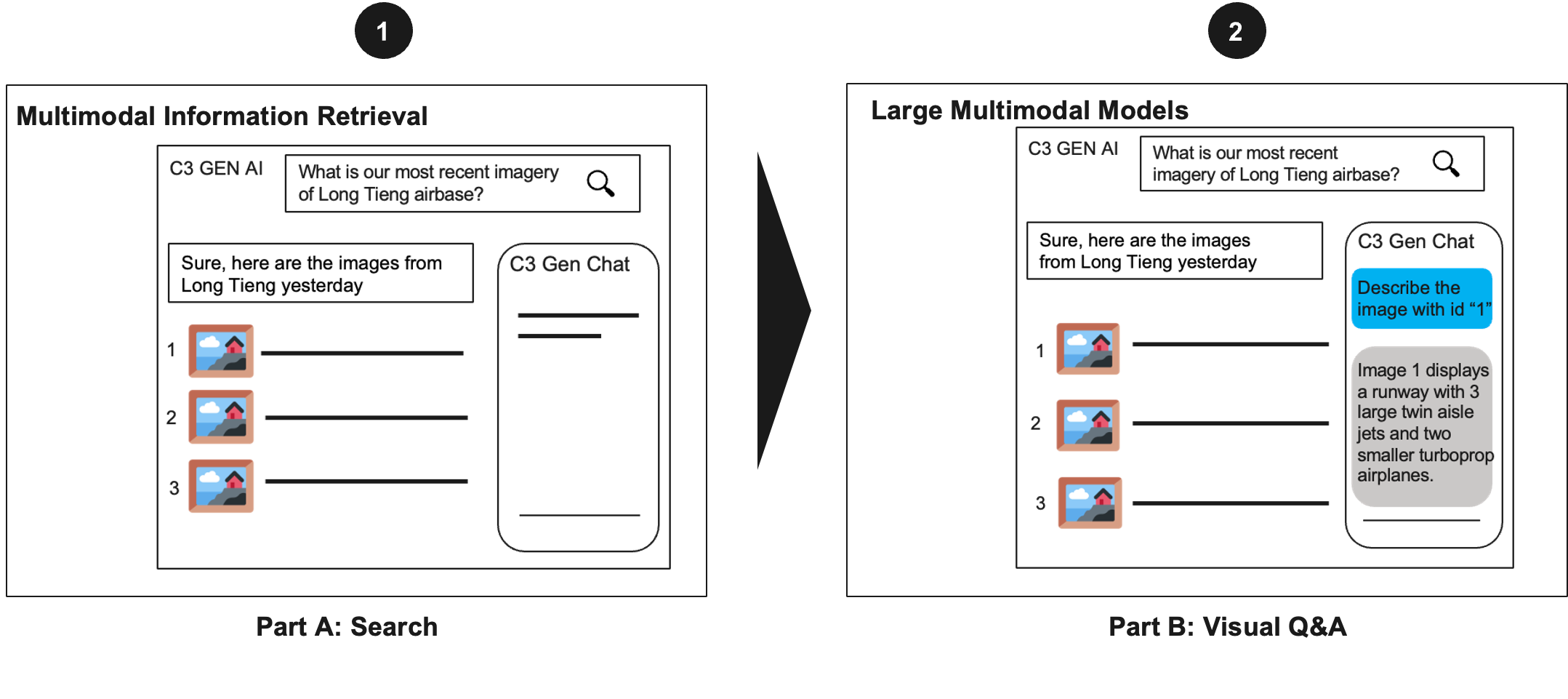
Figure 9: Example of leveraging multimodal retrieval with visual Q&A for advanced image question answering
Summary
C3 Generative AI leverages a highly modular and sophisticated document ingestion pipeline to enable rich understanding of multimodal content embedded in documents. This pipeline leverages a unified component interface to standardize the representation of unstructured content and embed it into an information graph to enable next-gen information retrieval. Multimodal information retrieval is available to developer and self-service administrators on C3 Generative AI Enterprise Search.
Authors
Sravan Jayanthi
Sina Pakazad
Ian Wu
Simon Rosenberg
Long Chen
Yueling Wu
