
Published on June 23, 2025 1:39 PM GMT
TL;DR: This post examines how rapidly AI forecasting ability is improving by analyzing results from ForecastBench, Metaculus AI tournaments, and various prediction platforms. While AI forecasting is steadily improving, there remains significant uncertainty around the timeline for matching top human forecasters—it might be very soon or take several years.
ForecastBench
ForecastBench is a “dynamic, continuously-updated benchmark designed to measure the accuracy of ML systems on a constantly evolving set of forecasting questions.” This makes it ideal for tracking how fast AI forecasting skills improve. Performance is measured as Brier scores (lower is better)[1]. See the accompanying benchmark paper here.
The leaderboard shows AI performance alongside human benchmarks: "Public median forecast" represents non-experts, while "Superforecaster median forecast" represents elite human forecasters.
Evaluated AI systems operate under varying conditions—with or without access to a scratchpad for reasoning or to relevant information like news. Importantly, current forecasting prompts are likely good but suboptimal, meaning AI capabilities may be underestimated.
The benchmark paper reveals that AI forecasting performance correlates linearly with both Chatbot Arena scores and log training compute (measured in FLOP). Training compute may be of special interest for predicting when AIs reach the level of expert human forecasters.
Performance vs. Chatbot Arena and Log Training Compute

Brier Score vs. Chatbot Arena and Log training compute (source: ForecastBench paper)
Scores in the graph above corresponds to accuracy for each model with optimal conditions (e.g. if Claude-3-5-Sonnet performed better with a scratchpad, its score is the one achieved while using it).
Using Epoch AI's training compute data, the AIs with most training compute at each point in time show a 4.9x annual increase in training compute. The current leader is Grok 3, which used an estimated 4.6×10^26 FLOPs.
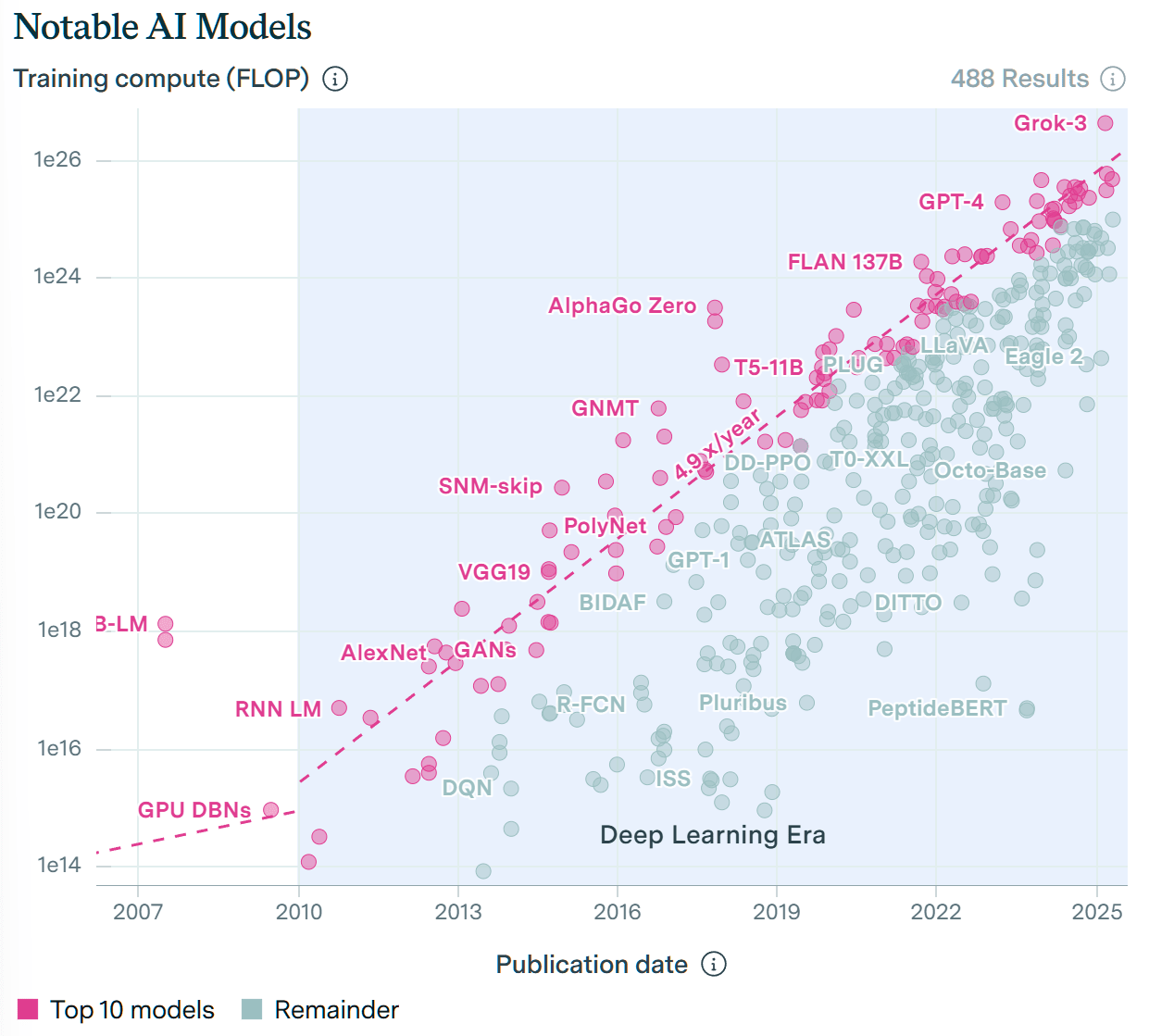
In the ForecastBench paper, the authors extrapolate the trend line for prediction accuracy and training compute:
Projecting out the log-linear relationship, we find that LLMs could match superforecaster performance when training compute approaches 6.49 × 10^26, though there is a large confidence interval (bootstrapped 95% CI: 9.69×10^25–8.65×10^28) given the marginally significant relationship (r = −0.67, p = 0.046).
The training compute for Grok 3 (4.6×10^26 FLOP) is already remarkably close to the projected 6.49 × 10^26! Even the upper bound of the bootstrapped confidence interval would be reached by June 2028, if training compute continues to increase at the same exponential rate[2].
Performance vs. Release Date
Looking at release dates rather than training compute tells a different story. Using leaderboard data from June 8, 2025, this graph shows AI performance against model release dates.
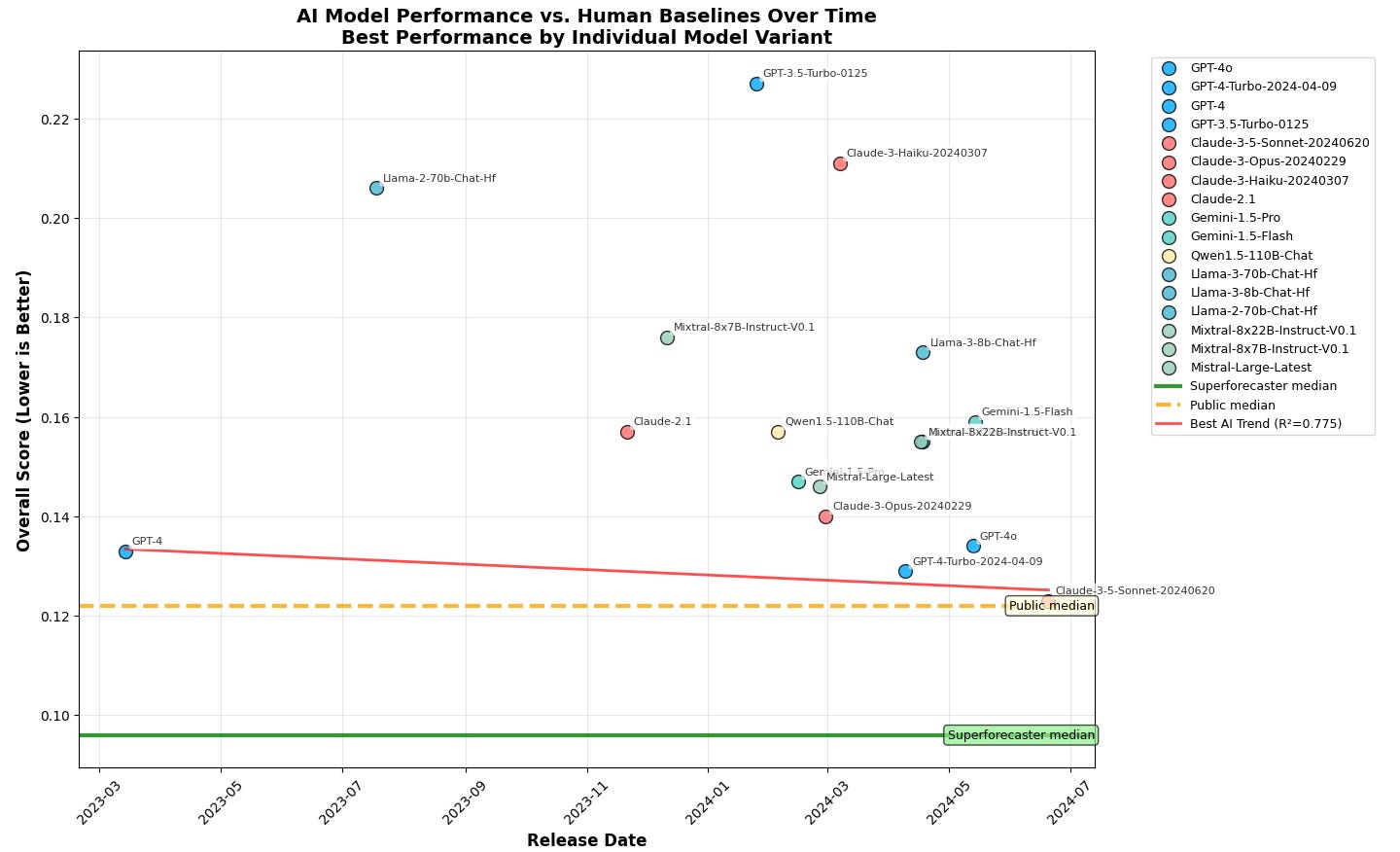
Overall Score vs release date (leaderboard data from 8 June 2025)
As with the previous graphs, scores correspond to the best conditions for each AI model.
The graph above shows Overall Scores from the leaderboard, which incorporates accuracy estimates on questions that are yet to be resolved—through comparing forecasts to crowd predictions. This may result in somewhat less reliable scores, so it seems prudent to also examine the Overall Resolved Scores, which ignore unresolved questions:
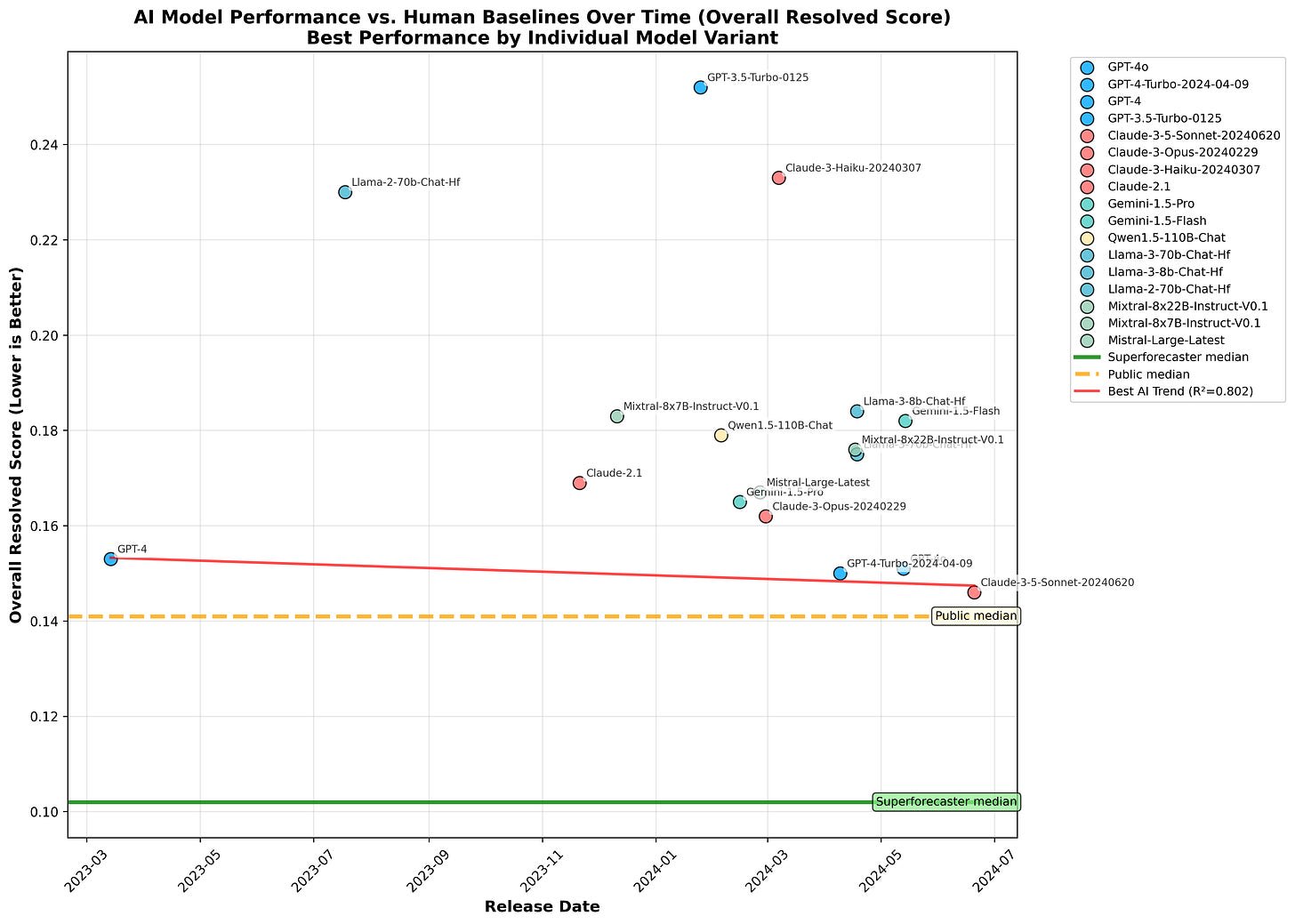
Overall Resolved Score vs release date (leaderboard data from 8 June 2025)
The resulting graph is remarkably similar. GPT-4 dominated for a long time, until the arrival of GPT-4-Turbo. Note that AIs are approaching the public median score, for both Overall Score and Overall Resolved Score. Since AIs have improved much since Claude 3.5 Sonnet[3], frontier models would likely surpass the public median forecast.
The red line in each graph is fit to the running maximum score. In the following graphs, the lines are projected forward until they intersect with the superforecaster score—just keep in mind that the projections will surely be wildly off since the lines were fit on only three data points.
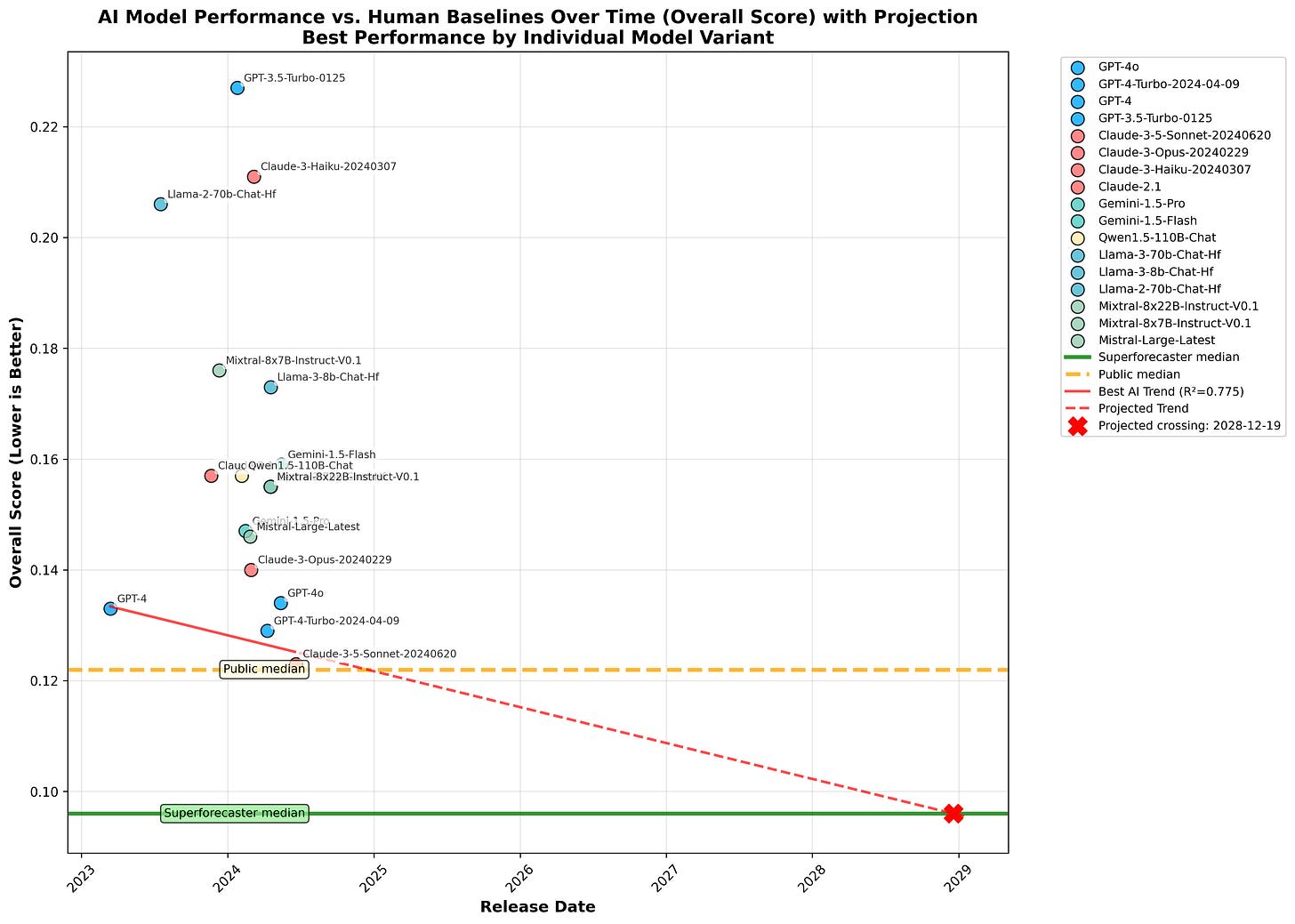

The intersection dates are 2028-12-19 for Overall Score, and 2034-05-05 for Overall Resolved Score.
While the projections aren’t exactly reliable, the fact that the projection is much longer when only considering accuracy on resolved questions is quite interesting. When we get results for later models, I suspect this result will hold.
Metaculus AI Tournaments
Metaculus runs quarterly AI forecasting tournaments, directly pitting bots against human experts. While Q1 2025 results are available for bots, human baseline comparisons haven't been released yet.
The Q4 2024 analysis showed the best AI team (ironically just one bot called "pgodzinai") achieved a head-to-head score of -8.6 against median Metaculus Pro Forecaster predictions—an improvement from -11.3 in Q3 2024[4]. A negative head-to-head score implies worse performance compared to the Pros, while 0 represents equal accuracy.
The forecasting bots are scored using Total Spot Peer Scores. Peer score calculates the average difference in log score between a participant and all other forecasters on each question, ensuring the average Peer score is 0. Spot peer score is the peer score evaluated when the Community Prediction is revealed (hidden from bots to prevent gaming). Total Spot Peer Score (or just Total Spot Score) sums all individual spot peer scores.
While anyone can make a bot and participate in the tournaments, there are a collection of bots that uses the same framework, providing baseline scores for specific AI models. These bots are differentiated from other participants by their names, which is always metac-[model name] (for instance, metac-o1 only uses OpenAI’s o1 model for predictions).
Plotting baseline scores for Q1 2025 against release date shows steady improvement over time. Baseline scores for Perplexity and Exa AI were also provided but are excluded here due to unclear release dates.
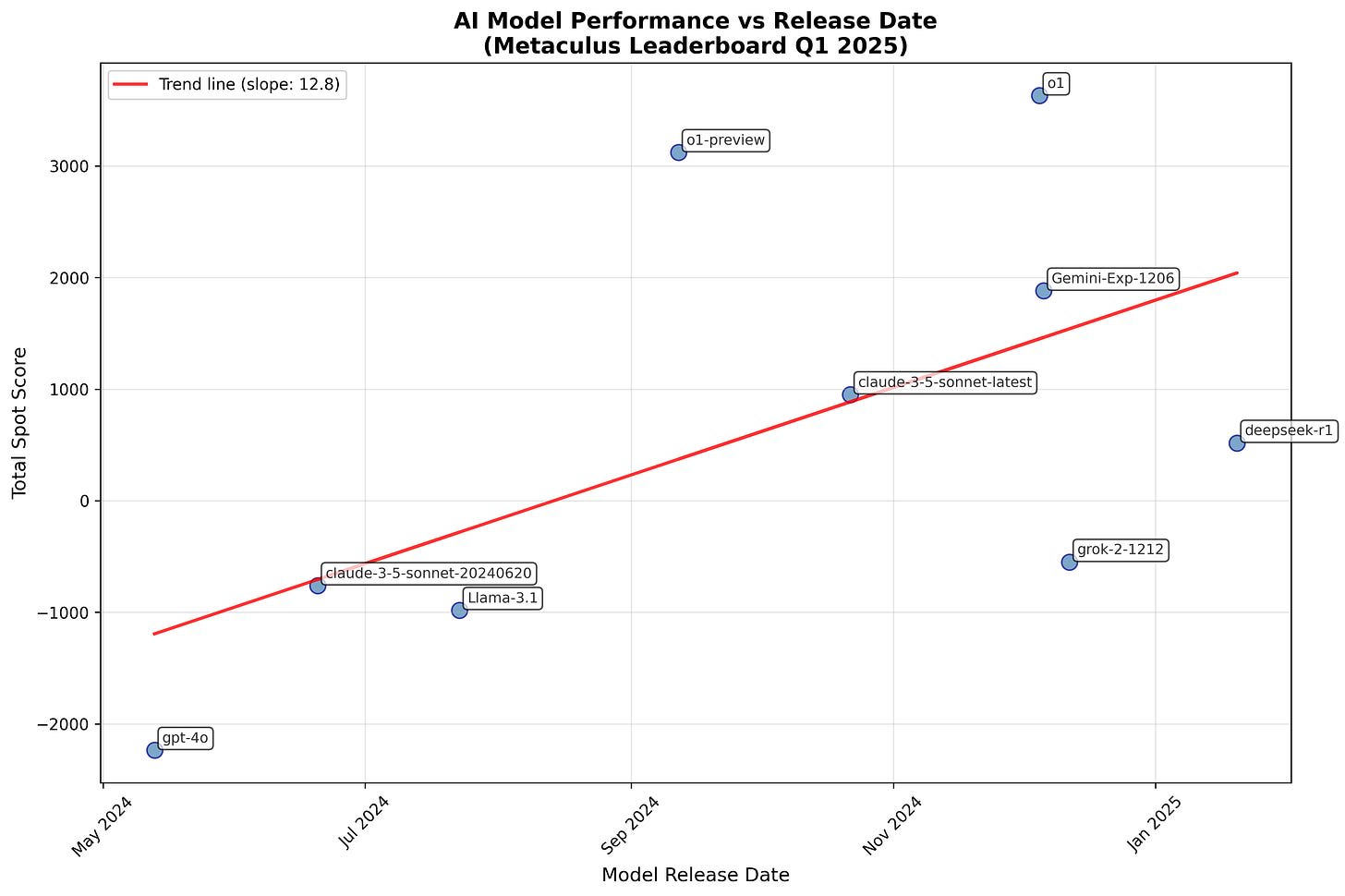
We can compare Metaculus and ForecastBench scores for the two overlapping AI models:
- gpt-4o: 0.151 Overall Resolved Score on ForecastBench, -2235.4 Total Spot Score on MetaculusClaude-3-5-sonnet-20240620: 0.146 Overall Resolved Score on ForecastBench, -759.5 Total Spot Score on Metaculus
Two data points prevent reliable conclusions, but if these scores accurately represent forecasting capabilities, small Brier score improvements correspond to large Total Spot Score gains. Even though o1 scores several thousand points higher than Claude-3.5-sonnet-20240620 on Metaculus, o1 probably only slightly exceeds public median forecasts on ForecastBench (if at all), if tested under the same conditions as the other ForecastBench models.
Q2 2025 tournament early results (screenshot from June 17) show the trend continuing, with later models like o3 and DeepSeek-R1 outperforming predecessors. Note these results aren't final since many questions remain unresolved, and scores aren't comparable across tournament iterations due to scoring being relative to the performance of other participants.
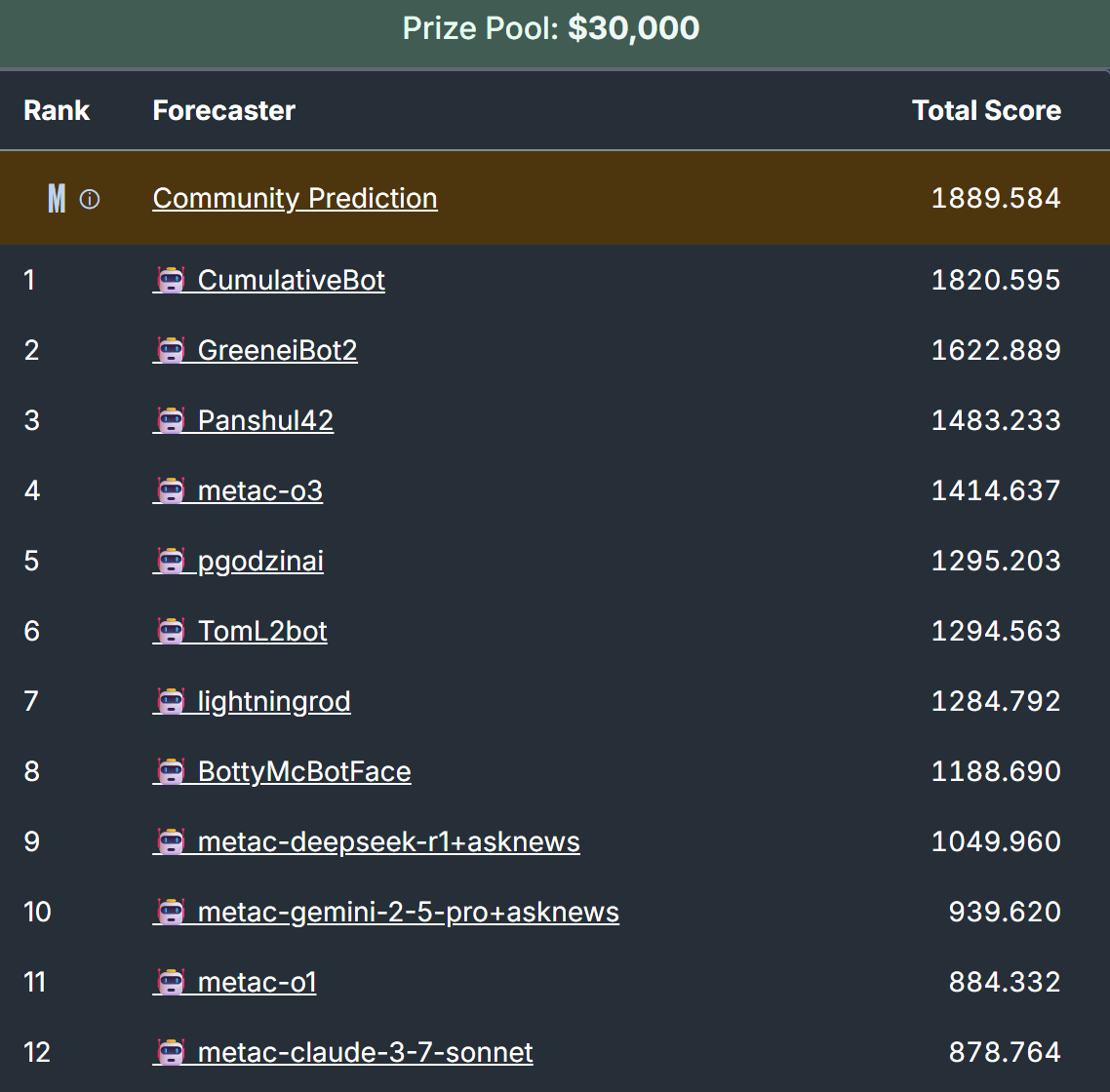
CumulativeBot performs well but doesn't dramatically exceed metac-o1's performance—not the leap required to go from roughly public level to superforecaster level, as far as I can tell.
In Q1 2025, metac-o1 achieved first place. The absence of metac bots leading Q2 indicates that AI forecasting techniques are improving, including prompting, tool access, fine-tuning, and aggregation methods for combining predictions made by several AI models into a single bot prediction.
Forecasting Platform Predictions
Related predictions from forecasting platforms, in roughly chronological order:
This seems too high considering current Q2 bot performance appears inferior to human Pro forecasters, and the ForecastBench trends. My prediction: 8%.
Will pre-2026 AI out-forecst the Metaculus community? - 58%
Could finetuning and good scaffolding enable bots to outperform the Community Prediction? Quite likely according to this Manifold market. This may be easier than outperforming human Pro aggregates, since the Pros consist only of forecasters with impressive track records.
This requires both a commercial AI forecasting market AND really good Brier scores. Remember, Superforecaster median on ForecastBench is around 0.1. Only 9 people have traded on this market.
When Will an AI be Amongst the Best Forecasters on Metaculus - 11 Feb 2028
This question resolves to Yes if one of the top 10 accounts in this Metaculus leaderboard is a bot.
Will any AI system beat a team of human pros in a forecasting tournament before 2030? - 90%
This could happen if a forecasting bot achieves a head-to-head score above 0 against an aggregate forecast by Metaculus Pro forecasters.
When will an AI program be better than humans at making Metaculus forecasts? - March 2031
This question has such difficult criteria that the AI would need to be essentially superhuman at forecasting, explaining the longer median prediction.
Wrapping it up
We ave a lot of interesting results:
- Frontier AIs are already approaching (or exceeding!) the training compute for which you may expect superforecaster performance on ForecastBench. The upper bound of the 95% CI for training compute could be reached by Juni 2028, if extrapolating training compute trends from Grok 3.Although unreliable, the relation between ForecastBench performance and model release date suggests AI models reaching superforecaster level around 2028-12-19 for Overall Score, and 2034-05-05 for Resolved Score.The best forecasting bot teams in Metaculus AI tournaments achieved -11.3 in head-to-head score in Q3 2024, and -8.6 in Q4 2024, against Metaculus Pro forecasters (where 0 indicates equal accuracy).There is a very clear trend of later models outperforming earlier ones. Among the baseline bots in the Q2 2025 tournament, OpenAI’s o3 is in the lead.Techniques for AI forecasting are clearly improving, but it’s difficult to determine how fast.Among forecasting platform predictions, "When Will an AI be Amongst the Best Forecasters on Metaculus" (median: February 11, 2028) seems to accurately capture both uncertainty and the median expectation for AI reaching superforecaster levels.
What conclusions can we draw from this? The trends point in different directions. Training compute trends suggest superforecaster AIs very soon, while release date trends for forecasting score on resolved questions suggest such AIs as late as 2034 (though this doesn’t account for framework improvements).
We’ll know more once ForecastBench have results on more recent models, and when we have head-to-head scores on the Q1 and Q2 2025 Metaculus tournaments.
Currently, my median estimate is at mid-2026 for the best forecasting bots reaching superforecaster levels, with an 80% confidence interval from October 2025 to 2030. Considering only the above information would suggest longer timelines, but I suspect performance may increase rapidly through enhanced scaffolding as more attention and resources focus on AI forecasting ability.
I also expect AI capability trends—including forecasting skills—to accelerate when AIs automate larger portions of AI R&D, initiating an intelligence explosion that makes longer projections (like 2034) seem unlikely[5].
Hopefully, we achieve superhuman forecasting before such rapid capability improvements—it may prove vital for decision-making and strategizing to handle rapid societal changes and extreme risks from advanced AIs.
Thank you for reading! If you found value in this post, consider subscribing!
- ^
The Brier score of a prediction is given by (1-P(outcome))^2, where P(outcome) is the probability assigned to the actual outcome. Brier score for a set of predictions is the average Brier score for each forecast.
- ^
Grok 3 was released February 17, 2025, with 4.6×10^26 FLOP in training compute. Let y be the number of years between the release of Grok 3, and the date for when extrapolated training compute hits 8.65×10^28 (starting from the compute for Grok 3 and increasing by 4.9x per year). We then have:
4.6×10^26 x 4.9^y= 8.65×10^28,
y = log(8.65×10^28 / 4.6×10^26) / log(4.9) = 3.33.3 years from the release of Grok 3 is around June 2028.
- ^
- ^
Head-to-head score is calculated as Peer score—which compares one forecaster to all other forecasters with predictions on the same question—but with only two participants. More info here.
- ^
This is essentially what happens in the AI 2027 scenario—where the intelligence explosion takes place in 2027. The best AI reaches the forecasting ability score 1.0 in May 2026, between the level of a human amateur (score 0-1) and pro (score 1-2). It reaches the score 2.1 in August 2027, better than any human.
Discuss
