
LLM-Based Code Generation Faces a Verification Gap
LLMs have shown strong performance in programming and are widely adopted in tools like Cursor and GitHub Copilot to boost developer productivity. However, due to their probabilistic nature, LLMs cannot provide formal guarantees for the code generated. The generated code often contains bugs, and when LLM-based code generation is adopted, these issues can become a productivity bottleneck. Developing suitable benchmarks to track progress in verifiable code generation is important but challenging, as it involves three interconnected tasks: code generation, specification generation, and proof generation. Current benchmarks fall short, as they lack support for all three tasks, quality control, robust metrics, and modular design.
Existing Benchmarks Lack Comprehensive Support for Verifiability
Benchmarks like HumanEval and MBPP have good progress on LLM-based code generation, but do not handle formal specifications or proofs. Many verification-focused efforts target only one or two tasks and assume other elements to be provided by humans. DafnyBench and miniCodeProps are designed for proof generation, while AutoSpec and SpecGen infer specifications and proofs from human-written code. Interactive theorem-proving systems, such as Lean, provide a promising target for verifiable code generation with LLMs, as they support the construction of proofs with intermediate steps. However, existing verification benchmarks in Lean, such as miniCodeProps and FVAPPS, have limitations in task coverage and quality control.
Introducing VERINA: A Holistic Benchmark for Code, Spec, and Proof Generation
Researchers from the University of California and Meta FAIR have proposed VERINA (Verifiable Code Generation Arena), a high-quality benchmark to evaluate verifiable code generation. It consists of 189 programming challenges with detailed problem descriptions, code, specifications, proofs, and test suites, that are formatted in Lean. VERINA is constructed with quality control, drawing problems from sources such as MBPP, LiveCodeBench, and LeetCode to offer different difficulty levels. All samples are manually reviewed and refined to ensure clear natural language descriptions, precise formal specifications, and accurate code implementations. Each sample contains test suites to cover positive and negative scenarios, with 100% line coverage of the code implementation and passing ground truth specifications.
Structure and Composition of the VERINA Dataset
VERINA consists of two subsets with diverse difficulty levels: VERINA-BASIC and VERINA-ADV. VERINA-BASIC contains 108 problems translated from human-written Dafny code. This comprises 49 problems from MBPP-DFY50 and 59 additional instances from CloverBench, translated using OpenAI o3-mini with few-shot prompting, and followed by inspection. VERINA-ADV contains 81 more advanced coding problems from student submissions in a theorem-proving course, where students sourced problems from platforms like LeetCode and LiveCodeBench, then formalized solutions in Lean. Moreover, VERINA employs rigorous quality assurance, including detailed problem descriptions, full code coverage with positive tests, and complete test pass rates on ground truth specifications, etc.
Performance Insights: LLM Evaluation on VERINA Highlights Key Challenges
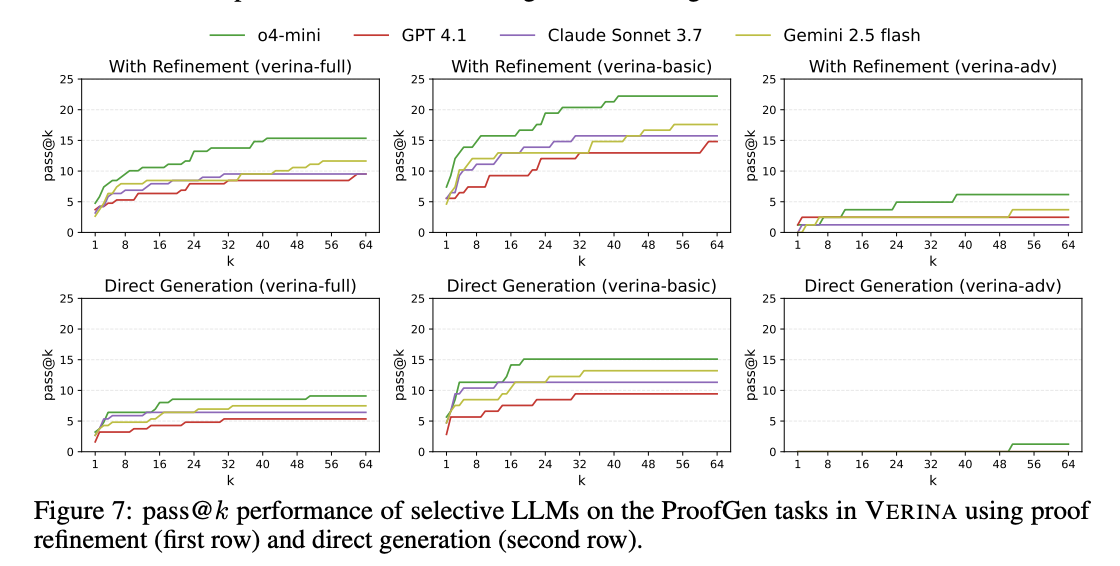
The evaluation of nine state-of-the-art LLMs on VERINA reveals a clear tough hierarchy. Code generation achieves the highest success rates, followed by specification generation, while proof generation remains most challenging, with pass@1 rates below 3.6% for all models. VERINA-ADV is more difficult compared to VERINA-BASIC in all three tasks, highlighting that increased problem complexity significantly impacts the performance of verifiable code generation. Iterative proof refinement with o4-mini shows an improvement from 7.41% to 22.22% for simpler problems on VERINA-BASIC after 64 iterations, though gains are limited on VERINA-ADV. Providing ground truth specifications enhances code generation, indicating that formal specifications can effectively constrain and direct the synthesis process.
Conclusion: VERINA Sets a New Standard in Verifiable Code Evaluation
In conclusion, researchers introduced VERINA, an advancement in benchmarking verifiable code generation. It offers 189 carefully curated examples with detailed task descriptions, high-quality code, specifications in Lean, and extensive test suites with full line coverage. However, the dataset is still relatively small for fine-tuning tasks, requiring scaling through automated annotation with LLM assistance. VERINA emphasizes simple, standalone tasks suitable for benchmarking but not fully representative of complex real-world verification projects. The specification generation metric could be improved in the future by incorporating more capable provers, including those based on LLMs or SMT solvers to handle complex soundness and completeness relationships, effectively.
Check out the Paper, Dataset Card, GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post VERINA: Evaluating LLMs on End-to-End Verifiable Code Generation with Formal Proofs appeared first on MarkTechPost.
