

SIGGRAPH(Special Interest Group on Computer Graphics and Interactive Techniques)是计算机图形学领域最顶级的国际学术会议,被中国计算机学会(CCF)推荐为A类会议,其论文代表该领域最高研究水平。会议涵盖渲染、动画、几何处理、交互技术等方向,以学术严谨性和产业影响力著称。
近日,由浙江大学沈春华教授课题组与阿里巴巴集团安全部联合提出的基于生成式视频扩散模型的全新视频抠图算法—“Generative Video Matting"被SIGGRAPH 2025录用。该成果旨在有效缓解视频人像抠图领域长期存在的高质量数据不足和模型泛化性欠缺两大核心痛点。

视频抠图(Video Matting)是将视频中的前景目标与背景精确分离的关键技术,在影视制作、特效合成、视频编辑、在线直播、虚拟现实(VR)与增强现实(AR)等众多领域扮演着至关重要的角色。然而,长期以来,视频抠图技术的发展面临着一大核心瓶颈:大规模、高质量、精细标注的视频抠图训练数据极难获取。这直接导致传统的视频抠图模型在面对多样化、复杂场景时,难以实现有效的泛化,抠图效果往往不尽如人意,出现边缘粗糙、细节丢失、动态模糊以及时间序列上不稳定等问题。如何突破数据桎梏,提升模型的泛化能力和抠图质量,成为业界和学术界共同关注的焦点。

针对上述问题,本研究从数据和模型的方面提出对应的解决方案,主要包括以下几点:
🎈大规模高质量合成数据,打破真实数据依赖瓶颈:
针对真实场景视频人像抠图数据难以获取的问题,本研究提出借助大规模合成分割数据集以及少量高质量渲染视频人像抠图数据来打破数据瓶颈。本研究利用渲染引擎Blender内置的毛发系统,以及3D人像资产,针对性地渲染了一个高质量视频人像数据集。
🎈生成式扩散模型抠图框架,提升模型泛化性能:
研究团队创新性地将近年来在图像生成领域的生成式视频扩散模型(Generative Video Diffusion Models)引入视频抠图任务。他们巧妙地设计了全新的模型架构与训练策略,使模型能够深刻理解视频内容中前景对象与背景的复杂关系,并学习生成高精度、时序连贯的Alpha Matte(即前景蒙版)。
这一框架的优点在于,它不再过度依赖海量的像素级精确标注数据,而是能够通过扩散模型的强大生成能力和生成式预训练,有效缓解甚至突破现有方法对大规模标注数据集的依赖,为在数据稀疏乃至无标注情况下的视频抠图研究开辟了新道路。
🎈实现卓越泛化与时序一致性,提升抠图质量上限:
针对传统模型在未知场景下泛化能力不足、抠图结果易产生时序抖动等核心痛点,新算法充分利用了生成式扩散模型所学习到的丰富视觉先验知识。结合专为视频数据特性设计的时空注意力机制和精细的细节保持模块,该算法能够精准捕捉前景对象的动态边缘和细微特征(如发丝、半透明物体),并在连续视频帧之间保持高度的平滑与稳定。无论是在复杂的动态背景、光照变化,还是面对训练数据中未曾出现过的新颖场景,该模型均能展现出鲁棒的抠图性能和优异的视觉效果,显著提升了抠图的精准度和自然度。
🎈高效的推理速度:
与需要多步推理才能获得粗略透明度的传统扩散模型方法不同,该方法通过流匹配机制,可以在1-3步内获得满意的结果,大大加速了预测速度。
下图展示了本文的渲染管线
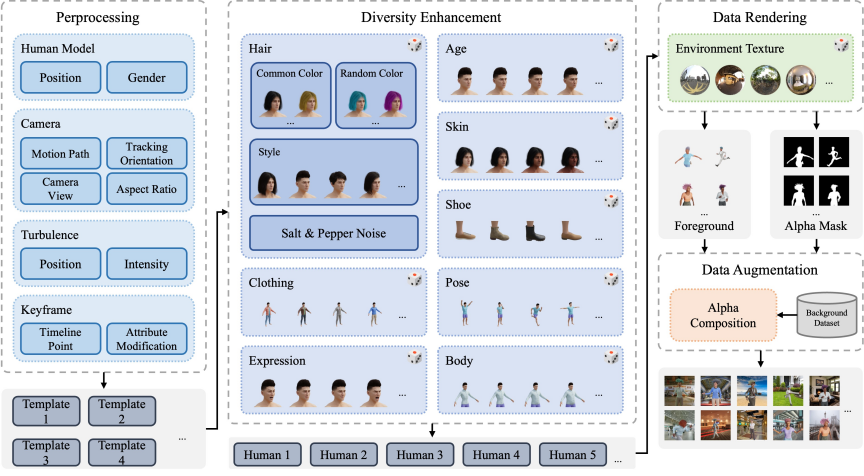
下图展示了本研究渲染的合成视频抠图数据集的几个片段:



论文的主要贡献包括:提出了一种全面的训练策略,来有效结合大规模合成视频分割数据与少量高质量合成视频Matte数据。首次将视频扩散先验引入视频抠图生成任务,并进行了一系列关键改进,包括在隐空间中进行流匹配监督以加速推理速度,以及在隐空间和图像空间中进行混合监督以实现精细抠图 。
实验结果表明,提出的方法能够精确地抠出动态视频人像,尤其是在发丝密集以及背景复杂的场景中,本文提出的方法显著优于之前的算法。下面介绍本研究生成的结果以及与RVM算法的对比。

(第一行为输入视频序列,第二行为RVM预测结果,第三行为本研究预测结果)

(第一列为输入视频序列,第二列为RVM预测结果,第三列为本研究预测结果)
除了人像抠图,论文提出的方法可以应用于动物抠图,如下图所示:












内容中包含的图片若涉及版权问题,请及时与我们联系删除
