
Hi ,大家好,我又来发布工具了~
4 月初的时候,我发布了一个 chatlog MCP 工具,出乎意料获得了不少关注(目前 5.4k star ),非常感谢大家的支持,同时也让我思考 MCP 工具更多的可能性。
最近,我做了一个新的工具 ImgMCP 。简单来说,它是一个能让大语言模型( LLM )调用各种多媒体 AI 能力的工具。
项目地址: https://imgmcp.com
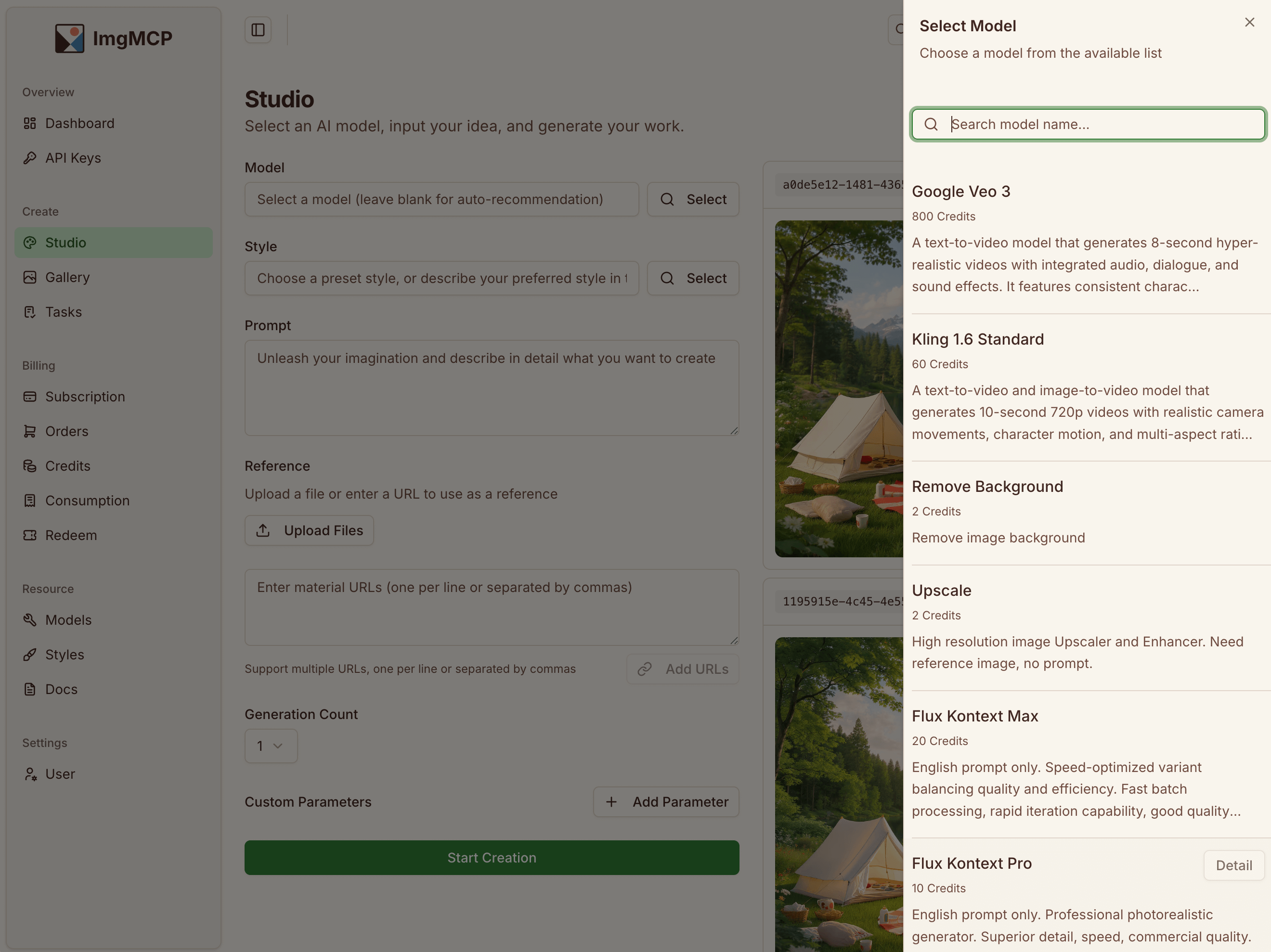

最初的想法
我们平时和大语言模型( LLM )聊天,处理文字很方便,但如果想让 LLM 帮忙处理图片、视频,就需要使用支持多模态的特定模型,或是到各个多媒体 AI 产品中使用对应功能,需要在多个工具之间切换。切换工具的原因也很简单,不同的多媒体 AI 模型有着不同的特长:
- GPT-Image-1 擅长理解复杂的上下文,对多语言支持的比较好;Midjourney 的艺术审美更强,能够生成更具艺术感的图片;Flux Kontext 在局部编辑上的控制力很强,非常适合做修复和调整。
那么能不能有一个统一的入口,我们只需要通过自然语言向 LLM 表达需求,LLM 就能智能调度不同的多媒体 AI 协同工作,完成多媒体创作和处理任务?
举个例子,我们告诉 LLM 我们的想法,LLM 先调用 Midjourney 生成具有创意的概念图,然后调用 GPT-Image-1 参考概念图和我们更详细的上下文信息,生成更符合具体要求的图片,最后如果对于局部不满意,再调用 Kontext 进行精修。
除了这些复杂的创作,一些基础的图片处理能力,例如图片放大、裁剪、去除背景、添加水印等等,也应该可以通过与 LLM 的对话轻松完成,由 LLM 去调用相应的处理模型。
对 LLM 的增强
ImgMCP 的核心,就是想把这一切都融入到与 LLM 的自然对话中。用户不需要关心背后具体是哪个多媒体 AI 模型在工作,甚至都不需要主动选择。在与 LLM 的交流过程中,LLM 根据你的意图,自行决定调用哪个多媒体 AI 模型、执行什么操作。
更有意思的是,并非所有 LLM 都天生具备直接生成多媒体内容的能力。那么,通过 MCP 这样的框架,我们是否能赋予那些“纯文本”LLM 去调度多媒体 AI 模型的“超能力”呢?
我做了一些简单的测试,发现这完全是可行的。即使是小参数的本地模型,在 MCP 的帮助下,也能指挥多媒体 AI 模型完成图片生成这样的任务。(测试使用 llama3.2:latest 在 Chatwise 调用 MCP 工具)
这种方式还有一个潜在的好处:LLM 强大的上下文理解能力,能帮助我们将模糊的自然语言指令,更准确地转换为对多媒体 AI 模型的具体创作参数。它甚至可以主动补充一些我们可能忽略的细节,理论上能让最终作品的质量更上一层楼。
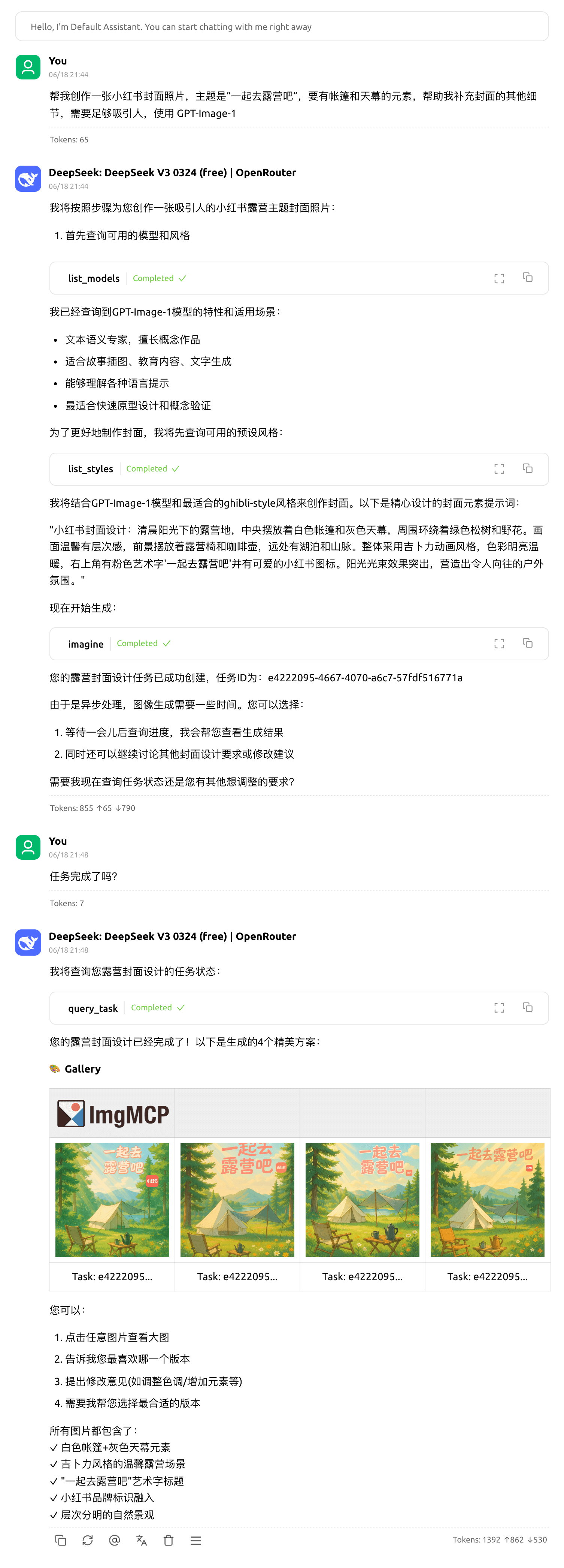
现实的挑战
在实现的过程中,我也遇到了不少问题,甚至不太好处理。
- 通知机制: 目前 MCP 协议中的通知机制,在很多 MCP Host 中都没有实现。这意味着,一个由 LLM 发起的创作任务(比如调用多媒体 AI 模型生成一张复杂的图片)是否完成,我们往往需要再次主动调用 MCP 工具查询状态,体验上不够流畅。我相信随着协议的完善,或者我们自己实现一套客户端,这个问题能得到改善。本地文件上传: Remote MCP 工具通常无法直接读取用户的本地文件。这就导致了“图生图”、“图生视频”这类依赖本地素材的功能(即 LLM 需要将本地图片信息传递给多媒体 AI 模型),在上传体验上不尽如人意。我之前尝试写过一个叫
file-store-mcp 的小项目,它可以把本地路径或剪贴板中的文件上传到对象存储,并返回一个 URL 。或许,可以考虑提供一个本地的 MCP 工具作为“助理”,专门负责文件上传,然后将文件 URL 交给 Remote MCP ,再由 LLM 将这个 URL 作为参数传递给相应的多媒体 AI 模型进行处理。关于 interface 的思考
还有一个想聊的话题,就是 interface 。过去我们做产品,主要关心的是两个 interface 的体验,一个是用户界面,一个是 API ,用户界面是给人用的 interface ,API 是给程序用的 interface 。
那么现在,我们是不是可以说,产品需要第三种接口——MCP ?这个入口,是专门给大语言模型( LLM )用的,让 LLM 能够调用我们产品提供的各种能力。
如果说 API 要求的是精确的参数输入,任何一点差错都可能导致调用失败;那么,为 LLM 设计的 MCP 接口,是否应该回归到更自然的语言交互呢?
我想到,电子邮件( Email )可能是目前应用范围最广的自然语言接口了。同事之间通过邮件沟通工作,请求协助,正是因为每个人都有自己的专业领域和职责划分;部分在产品中不好做自动化的能力,也经常以“通过邮箱联系我们”来进行处理。MCP 是否也应该如此?它应该能让 LLM 在不干扰主对话流程(上下文)太多的情况下,高效地完成各类专项任务(比如调用一个多媒体 AI 模型处理一张图片)。
如果 MCP 的交互真的回归自然语言,那么 MCP 的入口处,可能就需要一个“特别”的 LLM (或者说是一个专门针对该 MCP 优化的 LLM )。这个 LLM 需要深刻理解产品自身的能力边界,能够精准分析调用方(另一个 LLM 或应用)的需求,并将其合理地分配给后端的功能模块或具体的多媒体 AI 模型。这样做,调用的效果会不会更好? 这么一想,是不是就有一种快步进入 A2A 版本的感觉了?不知道有没有人想明白。
回到 ImgMCP
聊了这么多设想,说回 ImgMCP 目前的实际情况。它本质上就是一个多媒体 AI 聚合服务(类似 OpenRoute )。我接入了一些我认为效果较好的多媒体 AI ,然后把它们包装起来,方便大家通过 Web 界面、API 、MCP 使用。用户可以通过 Web 界面临时使用,也可以对接 API 大规模使用,或是尝试一下 MCP 的调用方式,一起探讨如何优化 MCP 体验。
目前已经接入的模型包括:
- GPT-Image-1MidjourneyFlux KontextGoogle Veo 3 (超级贵)以及一些基础图像处理能力模型后续也会积极继续接入效果较好的模型,例如今天发布的 Midjourney V1 (这个好玩哇~)
相比直接使用这些模型的官方服务,ImgMCP 主要的优势在于:
- 价格:通常会有一定优惠。例如,Veo 3 官方价格是 6 美元一个 8 秒视频,在 ImgMCP 只需要 2.4 - 5 美元。付费方式:支持按需付费,用多少算多少,购买的积分也不会过期。这对于那些不经常有作图需求,只是偶尔需要用一下的用户来说,可能会更友好。中文语言下支持支付宝微信支付。访问方式:提供 Web 界面、API 和 MCP 三种方式接入。
总结
写了这么多,主要是想分享一些近期关于 MCP 工具的折腾。欢迎大家来体验一下 ImgMCP ( https://imgmcp.com ),注册就有 100 积分可以用于测试,更欢迎对 MCP 这个方向感兴趣的朋友一起交流探讨。
