

面向计算机科学的LLM综合测试基准

论文题目:
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
论文地址:
https://arxiv.org/abs/2406.08587
项目主页:
https://csbench.github.io/
代码&数据地址:https://github.com/csbench/csbench
引言
计算机科学深刻地推动了人类社会和人工智能的发展。然而,当前的大型语言模型(LLMs)评估要么只将计算机科学作为众多评估学科中的很小一环(如C-Eval,MMLU),要么只专注于LLMs在计算机科学中的某项具体应用(如网络拓扑、代码生成),LLMs在计算机科学中的知识掌握和推理能力尚未得到全面评估。
为了弥补这一差距,北京邮电大学PRIS-nlp实验室团队提出了CS-Bench,这是第一个专注于评估LLM在计算机科学领域性能的测试基准。CS-Bench支持中英双语,包含了约5K条精心处理的样本,覆盖CS的4个关键领域下的26个子领域,并涵盖多种任务形式以及知识/推理划分。
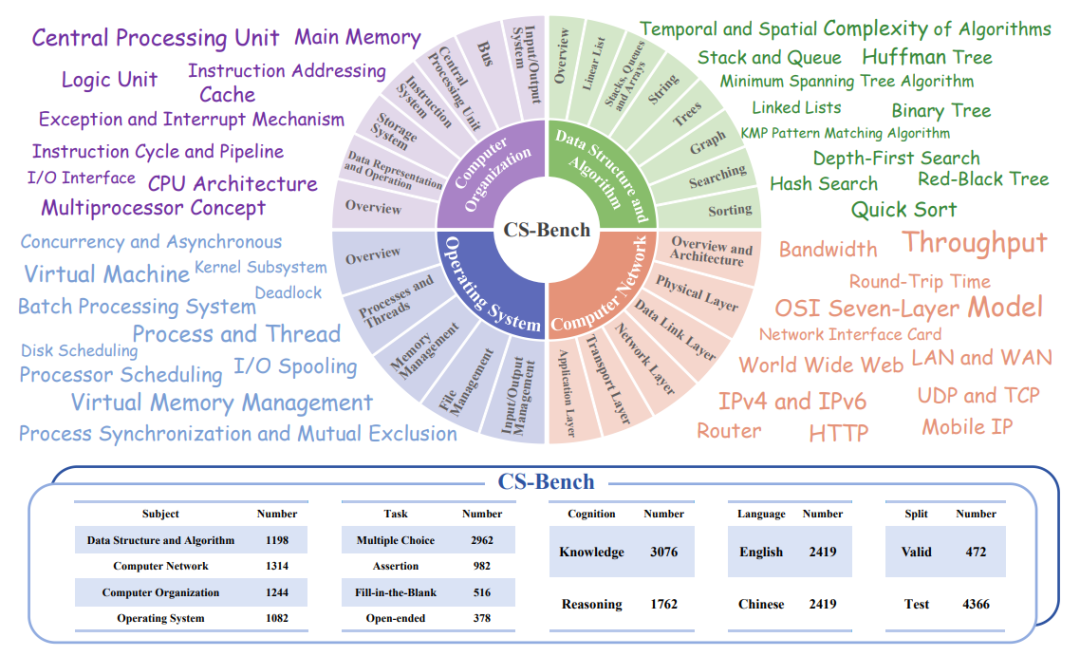
图1:CS-Bench的概览图和统计数据
借助CS-Bench,我们评估了超过30个主流模型,主要发现:
· CS-Bench可以有效区分LLM在CS领域的能力,并对表现最佳的GPT-4o提出了挑战(分数跨度从39.86至72.29);
· LLM模型在CS-Bench上的得分显示出规律的“尺度对数增长,分数线性增长”,并可以通过拟合小尺度模型表现来预测和指导大尺度模型;
· LLM的性能主要受限于领域知识的匮乏,并且一些特定于CS的推理仅通过增强一般推理能力无法补充,需要针对性的加强。
此外,当前的LLMs社区过于关注特定基础能力(如数学,代码),但是对于能力间分析仍然不足。考虑到CS和Math,Code领域的天然交叉性,我们探究了LLM在三者能力间的关系,主要发现:
· LLM在CS-Bench的整体表现趋势与数学和代码分数的变化密切相关,具有很高的相关性系数。
· 一些Math/Code专家LLM可以在CS的一些特定领域(如数据结构与算法)表现出改进,并且在补充小尺度模型上更为明显。
· 相较于一些在代码/数学基准上表现强劲的新小尺度模型,即使是一些优秀的小尺度模型在CS-Bench上也很难超过规模远大于它的模型。这反映出CS-Bench在LLM训练过程中并没有过度拟合,使其能够更公平地衡量模型性能差异。
我们开源了简洁高效的CS-Bench测试方案,以方便其他研究人员快速使用和评估。


CS-Bench测试基准
CS-Bench的目标是在不同的语言环境下评估LLM在计算机科学领域的知识和推理能力。CS-Bench具有以下特性:
· CS关键领域的覆盖:CS-Bench涵盖了数据结构与算法(DSA)、计算机组成原理(CO)、计算机网络(CN)和操作系统(OS)四个关键领域下的26个细粒度子领域。
· 任务形式的多样性:CS-Bench包含单选(MC),判断,填空(FITB)和开放结尾题四类任务形式,以模拟真实用户查询和考察LLM对于任务形式的鲁棒性;
· 知识/推理区分:除了CS知识,CS-Bench还评估CS的逻辑与算术推理,并通过标签加以区分;
· 多语言支持:CS-Bench专注于中英文双语评估,以评估LLM在不同语言环境下的性能。
数据收集和处理过程详见论文。
实验
1
整体表现
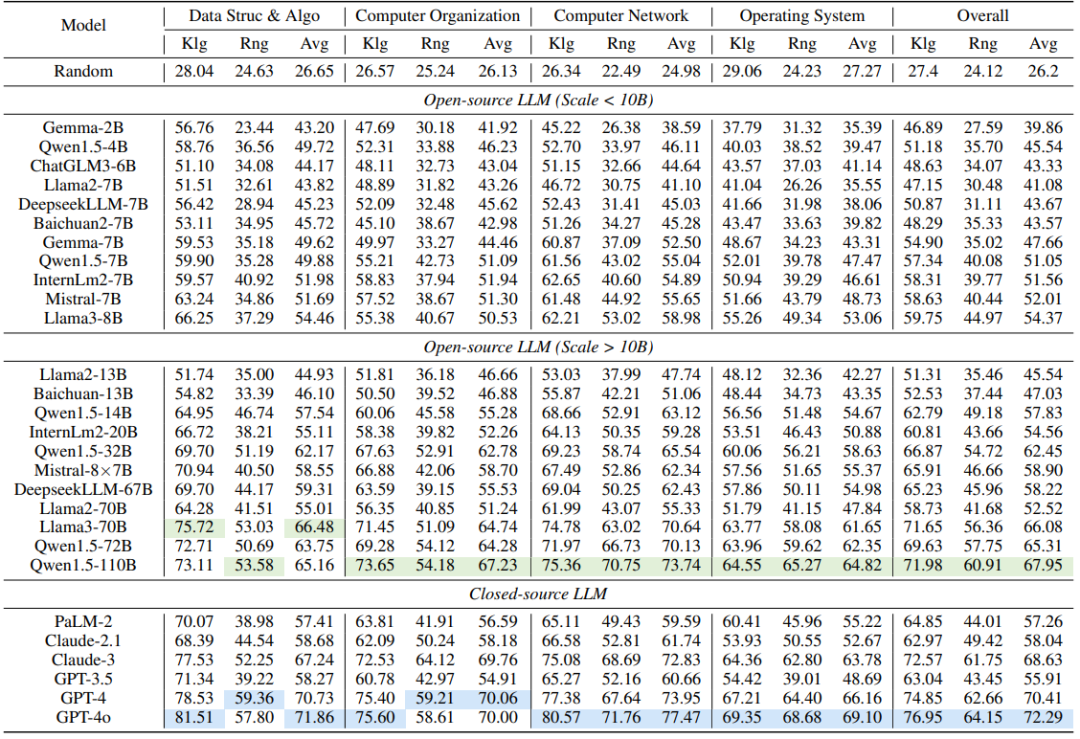
表1:在CS-Bench(EN)上,大型语言模型(LLMs)在不同领域的零样本得分(%),其中“Klg”表示知识型,“Rng”表示推理型,“Avg”表示平均值。随机得分的加权方式如下:多项选择题(MC)占25%,判断题(Assertion)占50%,填空题(FITB)占0%,开放式问题(Open-ended)占10%。开源和闭源大型语言模型的最高得分分别用绿色和蓝色标记。
· 在CS-Bench上,闭源模型GPT-4/GPT-4o仍然保持最高水准,是唯二超过70%准确率的模型。紧随其后的是开源模型Qwen1.5-110B和Llama3-70B,与最先进闭源模型之间的差距并不显著。
· 相对于知识得分(平均60.52%),所有模型在推理方面表现较差(平均44.63%),这表明推理对LLMs来说更具挑战性。然而,随着模型能力的提高,推理分数的增长比知识分数更为明显,逐渐弥合了两者之间的差距。
· 与英语相比,没有针对中文进行优化的 GPT 和 Llama3 系列在中文环境下的表现较差。相比之下,中文模型的性能下降幅度较小,甚至在Qwen1.5系列表现出提高。此外,同一家族中较大尺度的模型总是受语言的影响更小,如 Baichuan2-7/13B、Internlm2-7/20B 和 Llama3-8/70B。
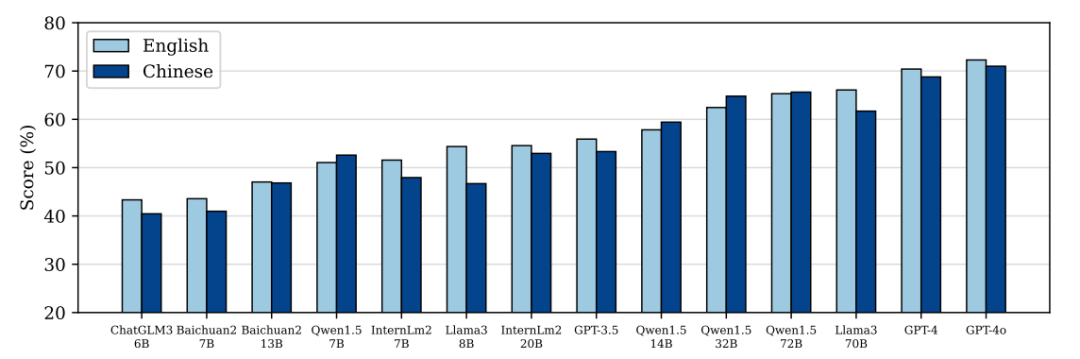
图2:模型在CS-Bench上不同语言的比较
2
模型尺度-分数规律
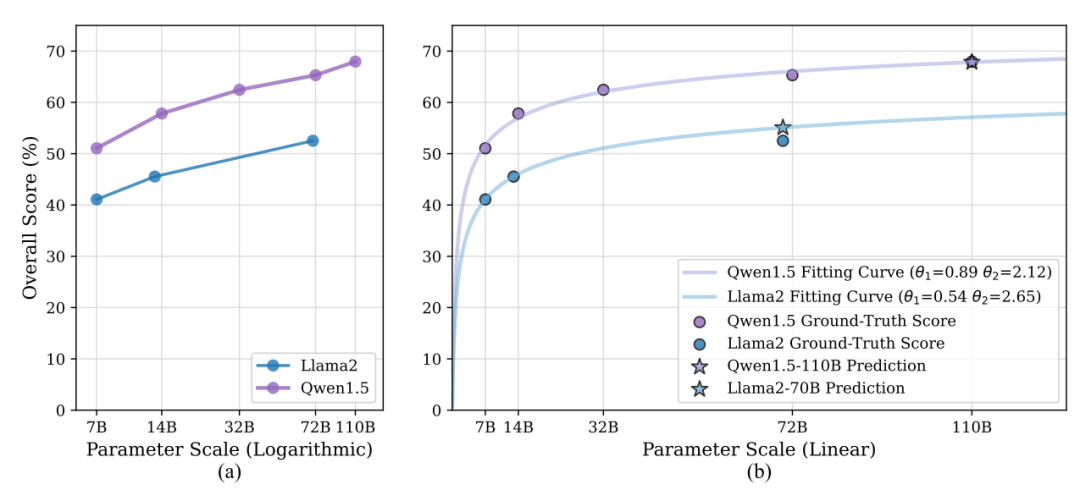
图3:Qwen1.5和Llama2系列的对数尺度得分表现和线性尺度得分拟合曲线
我们在图3(a)中检查了Llama2和Qwen1.5模型家族的性能是如何随着参数大小而变化的。可以观察到,尽管不同模型族表现出不同的性能,但是同一家族模型都随着尺度增加显现出性能改进;并且当参数规模呈指数增长时,性能分数近似呈线性增长。考虑到大尺度模型训练和推理所需的大量资源,我们期望建立模型尺度和分数之间的关系,以通过拟合小尺度模型分数来预测较大规模模型在CS领域的性能。拟合函数的设计细节详见论文。为了验证拟合函数,我们通过Qwen1.5的7, 14, 32, 和72B分数来预测110B表现,通过Llama2的7,13B来预测70B的表现。如图3(b),对于 Qwen1.5 110B,预测分数 (67.83%) 与真实值 (67.95%) 非常匹配。对于 Llama2-70B,在只有两个参考数据点下,预测得分 (55.08%) 与真实值 (52.52%) 的偏差也仅为 2.56%。
3
错误类型分析

图4:不同模型在多项选择题中不同错误类型的比例变化
为了深入探究LLM在CS-Bench上失败的原因,我们首先对知识,推理问题分别定义了三种错误类型,并利用GPT-4对模型的错误推理过程进行多分类。对于知识型题,“单一概念错误”和“概念间混淆”均呈现下降趋势。此外,一些“概念完全错误”先转变为“概念部分错误”,随后被消除,从而呈现出“概念部分错误”先上升后下降的趋势。对于推理型问题,我们发现很大一部分错误仍然属于”概念相关错误“类别。虽然更强的模型明显减少了“算术推理错误”,但特定于计算机科学领域的”逻辑推理错误“并没有显著变降低。分析强调,强化CS概念知识是提高LLM在CS领域表现的最直接、最有效的方法。此外,仅通过增强一般推理能力和数学推理能力很难实现 CS 推理性能的显着提高,需要针对性的加强。
4
CS,Math,Code
能力关系探究
鉴于CS和Math,Code的内在关联性,我们探讨LLM的计算机科学能力与数学、编码能力之间的关系,旨在促进LLM的跨能力研究和能力间分析。
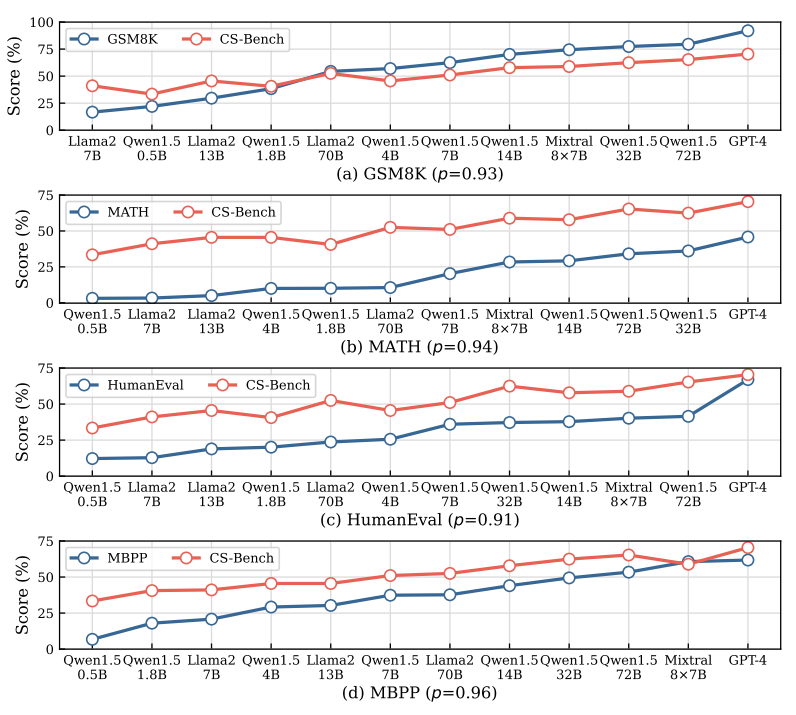
图5:随着大型语言模型(LLM)在数学/代码得分的增加,CS-Bench上的得分变化。p表示皮尔逊相关系数
在图5中,我们展示了通用LLM在CS-Bench的表现随着数学数据集(GSM8K、MATH)和代码数据集(HumanEval、MBPP)分数递增的变化。可以观察到,CS-Bench的整体表现趋势与数学和代码分数的变化高度相关,皮尔逊相关系数均超过0.9。除了卓越模型带来的各种能力的普遍增强之外,我们认为这也表明了CS能力与数学和代码能力之间存在密切的相关性。对于规律不一致的模型(例如,Qwen1.5-7B在GSM8K和MATH中优于Llama2-70B,但在CS-Bench中则不然),考虑到LLM社区对代码和数学领域的持续关注,最近发布的一些模型在这些领域进行了专门训练。然而,在CS领域,由于关注和训练数据不足,即使是优秀的小尺度模型也很难超过尺度大得多的模型。这也表明,CS-Bench在LLM预训练期间没有被过度拟合,使其成为一个更公平的用于衡量模型性能差异的基准。
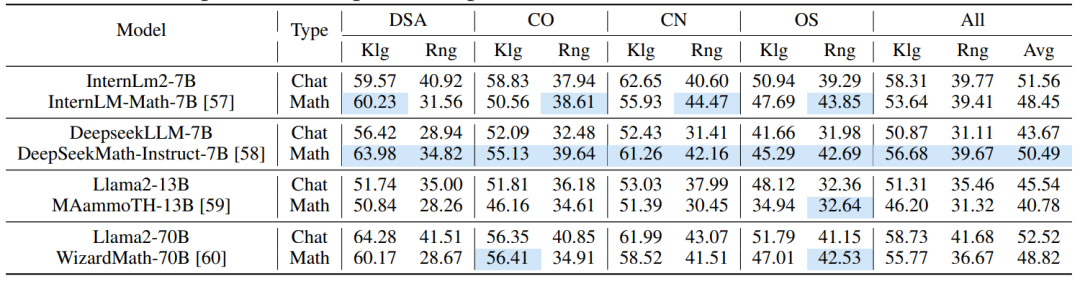
表2:数学专家LLMs在CS-Bench(EN)上的表现。我们使用蓝色来强调专家型LLMs与聊天型LLMs相比有所提高的领域
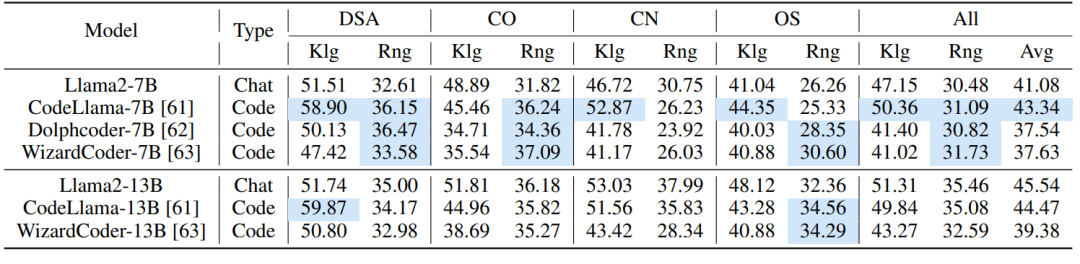
表3:代码专家LLMs在CS-Bench(EN)上的表现
我们在表2和表3中进一步呈现了数学和代码专家LLM在CS-Bench上的表现。与LLM相通用比,专家LLM通常会牺牲其它能力来增强其数学或代码能力,这反映在大多数专家LLM的总分降低。然而,数学和代码模型仍能在CS的某些特定方面表现出改进,如蓝色标记所示。对于数学专家模型,提升集中在OS,其次是CO,最后是DSA和CN;对于代码模型,提升集中在DSA和OS。此外,与大尺度LLM相比,小尺度专家LLM带来的提升效果更为明显(见CodeLlama-7B/13B,WizardCoder-7B/13B)。我们将此归因于小尺度LLM对特定知识和推理能力的需求补充,而大尺度LLM已经具备广泛的知识和强大的推理能力,导致特定领域进一步训练的收益递减。


总结
在这项工作中,我们引入了CS-Bench,这是第一个专门用于系统分析主流LLM在计算机科学领域的知识和推理能力的测试基准。我们对超过30个模型的评估表明,即使是表现最好的GPT-4o在CS方面也有显著的改进空间。进一步的尺度-分数实验和错误类型分析为提升LLM在CS领域的表现提供了方向。此外,我们对LLM的计算机科学、数学和代码能力之间关系的研究表明了它们的紧密联系,并为LLM的跨能力应用提供了见解。
转载请联系:
自然语言处理徐蔚然老师研究组
(pris-nlp.github.io)
