

摘要
强化学习理论将人类行为解释为受最大化奖励这一目标的驱动。然而,传统方法对于人们如何从过往经验推广到新情境提供的见解有限。在此,我们提出通过纳入高效编码原则来改进经典强化学习框架,该原则强调使用最简必要的表征来最大化奖励。这一改进后的框架预测,受更简单表征所限的智能体必然:1)将环境刺激提炼为更少的抽象内部状态,以及 2)检测并利用环境中的奖励特征。因此,复杂刺激被映射到紧凑的表征,从而为泛化奠定基础。我们在两项考察人类泛化能力的实验中检验了这一想法。我们的研究结果表明,传统模型在泛化方面表现不佳,但纳入高效编码的模型达到了人类水平的表现。我们认为,将高效编码加入经典强化学习目标,能构建一个更全面的计算框架,有助于理解人类在学习和泛化方面的行为。
关键词:高效编码(Efficient Coding)、强化学习(Reinforcement Learning)、状态抽象(State Abstraction)、奖励特征提取(Rewarding Feature Extraction)、泛化能力(Generalization)
如果你对大模型可解释性感兴趣,集智最近策划的「大模型可解释性」读书会,你一定不要错过。第一期分享主讲人从自下而上视角理解大模型机制可解释性。作为概览和入门引导,绝对不能错过!


论文题目:Humans learn generalizable representations through efficient coding
论文链接:https://doi.org/10.1038/s41467-025-58848-6
发表时间:2025年4月29日
论文来源:Nature Communications
在瞬息万变的世界中,人类能够从有限的经验中提取知识并应用于新情境,这种能力被称为泛化(Generalization)。例如,一个学会骑自行车的小孩可以将其平衡技能迁移到滑板车上,而无需从头学习。传统强化学习理论认为人类行为以奖励最大化为目标,但这一框架对泛化能力的解释有限。近日,一项发表在Nature Communications 的研究提出,将高效编码原则(Efficient Coding Principle)融入强化学习框架,可以更好地解释人类如何通过简化表征实现泛化。研究发现,人类在学习过程中会压缩环境刺激的冗余信息,形成抽象的内部状态,并提取与奖励相关的关键特征,从而在新任务中表现出色。
传统强化学习的局限与高效编码的提出
传统强化学习的局限与高效编码的提出
传统的强化学习理论将人类行为视为奖励最大化的过程,但其假设任务表征是预先定义且固定的,无法解释人类如何从复杂动态的环境中推断出有效的表征。例如,在现实决策中,人类需要从原始感官输入中提取模式并构建抽象表征,而传统RL模型缺乏这一机制。
为解决这一问题,研究者提出将高效编码原则融入强化学习框架。高效编码源于一个基本事实:人类大脑作为生物信息处理系统,认知资源有限。这一原则强调,智能体应在最大化奖励的同时,使用最简单必要的表征。此前,高效编码已被用于解释感知、工作记忆和运动控制等领域,但其在强化学习中的作用尚未明确。
高效编码如何驱动状态抽象?
高效编码如何驱动状态抽象?
研究通过两个实验验证高效编码的作用。实验一采用获得性等价范式(Acquired Equivalence Paradigm),参与者学习将不同外形的“外星人”刺激与特定场景关联。训练阶段,参与者通过反馈学习刺激-动作关联;测试阶段,他们需将所学应用于未训练的新关联。
研究者构建了三个计算模型:
1. RLPG(强化学习策略梯度模型):仅优化奖励,不压缩表征。
2. ECPG(高效编码策略梯度模型):在奖励最大化基础上最小化表征复杂度。
3. CPG(级联策略梯度模型):作为对照,架构与ECPG相同但不压缩表征。
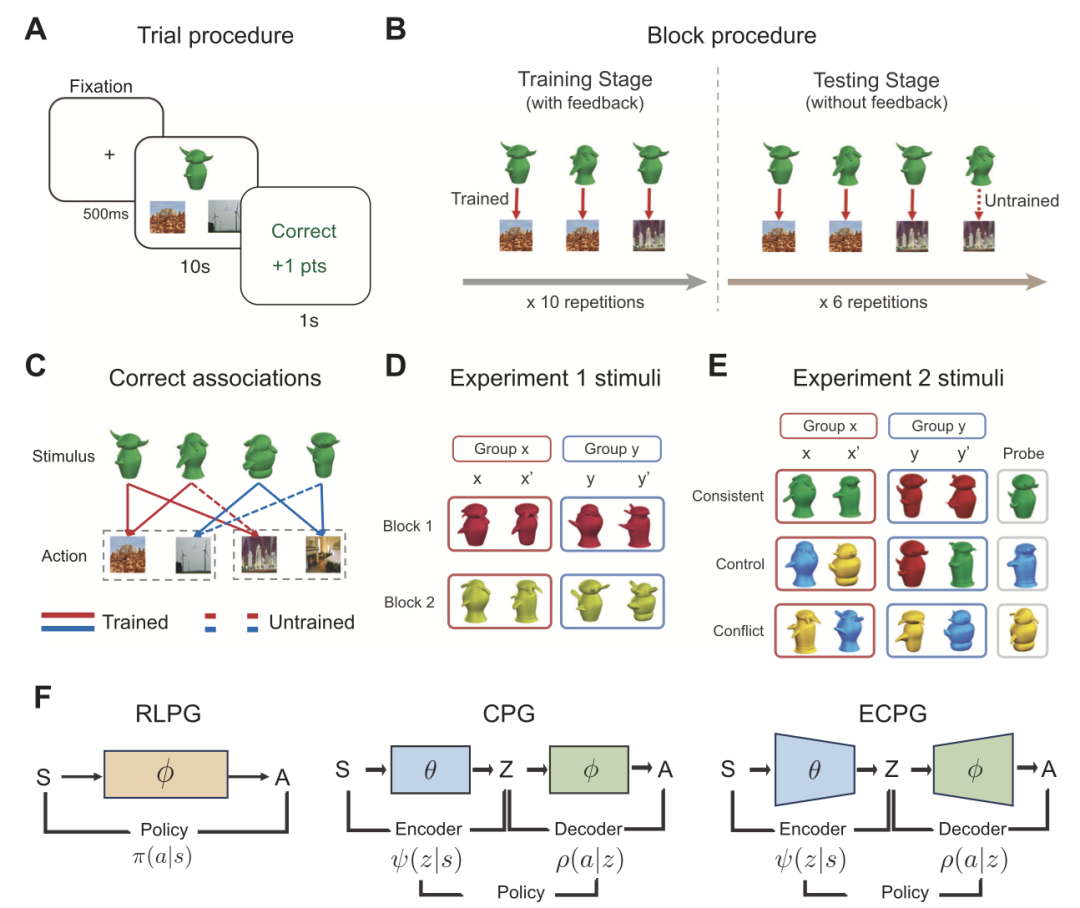
图 1. 实验一的获得性等价范式及模型架构。A. 单个试次的构成;B. 一个block包含两个阶段。训练阶段通过反馈训练三个关联。测试阶段测试一个未经训练的关联(虚线),同时测试三个已训练的关联,但不提供反馈。C. 一个block包含两组,每组有两个刺激物。一组的错误动作对应另一组的正确动作。D 实验 1 中使用的刺激物设计为相同颜色但形状和附属物不同,以控制感知相似性。这四个刺激物分别称为 x、x0、y、y0,其中 x 和 x0 关联相同的动作,y 和 y0 也是如此。E 实验 2 中使用的刺激物。每个模块包含一种不同类型的感知相似性。F 模型架构。经典的强化学习策略梯度(RLPG)模型学习一种策略,该策略将刺激 s 映射到动作 a 的分布。由于引入了表示 r,级联策略梯度(CPG)和高效编码策略梯度(ECPG)模型的策略被分解为编码器 ψ 和解码器 ρ。ECPG 和 CPG 模型具有相同的架构,只是 ECPG 模型优化以使用更简单的表示 z。
结果显示,ECPG模型通过信息瓶颈(Information Bottleneck)压缩表征,将共享相同动作的刺激映射到相似的内部状态(即状态抽象),从而在测试阶段表现出与人类相当的泛化能力。而RLPG和CPG模型因缺乏表征简化机制,泛化性能始终处于随机水平。
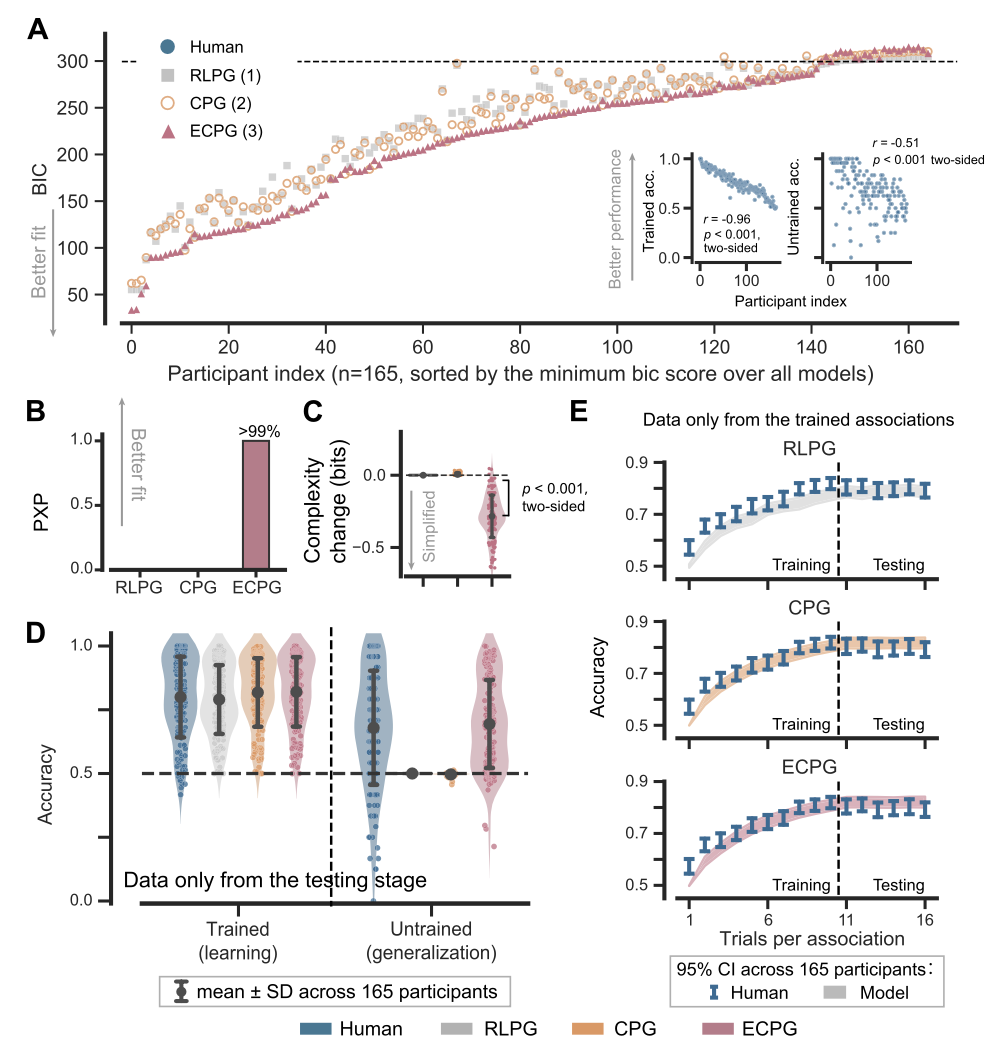
图 2. 实验一中人类和模型的表现。
奖励特征提取与条件依赖性
奖励特征提取与条件依赖性
实验二进一步考察了感知与功能泛化的交互作用。研究者设计了三种实验条件:
1. 一致条件(Consistent):颜色与奖励直接相关。
2. 冲突条件(Conflict):颜色与奖励负相关,形状和附属物才是关键特征。
3. 控制条件(Control):所有特征同等重要。
ECPG模型的模拟表明,在一致条件下,模型快速将注意力集中在颜色特征上;而在冲突条件下,模型需抑制颜色并转向其他特征。这一过程体现了奖励特征提取的灵活性。此外,研究者引入探针刺激(Probe Stimulus)(测试阶段的新刺激)发现,人类参与者的反应与ECPG模型的预测高度一致:在一致条件下,探针的响应与颜色相同的刺激匹配;在冲突条件下,则与形状相同的刺激匹配。
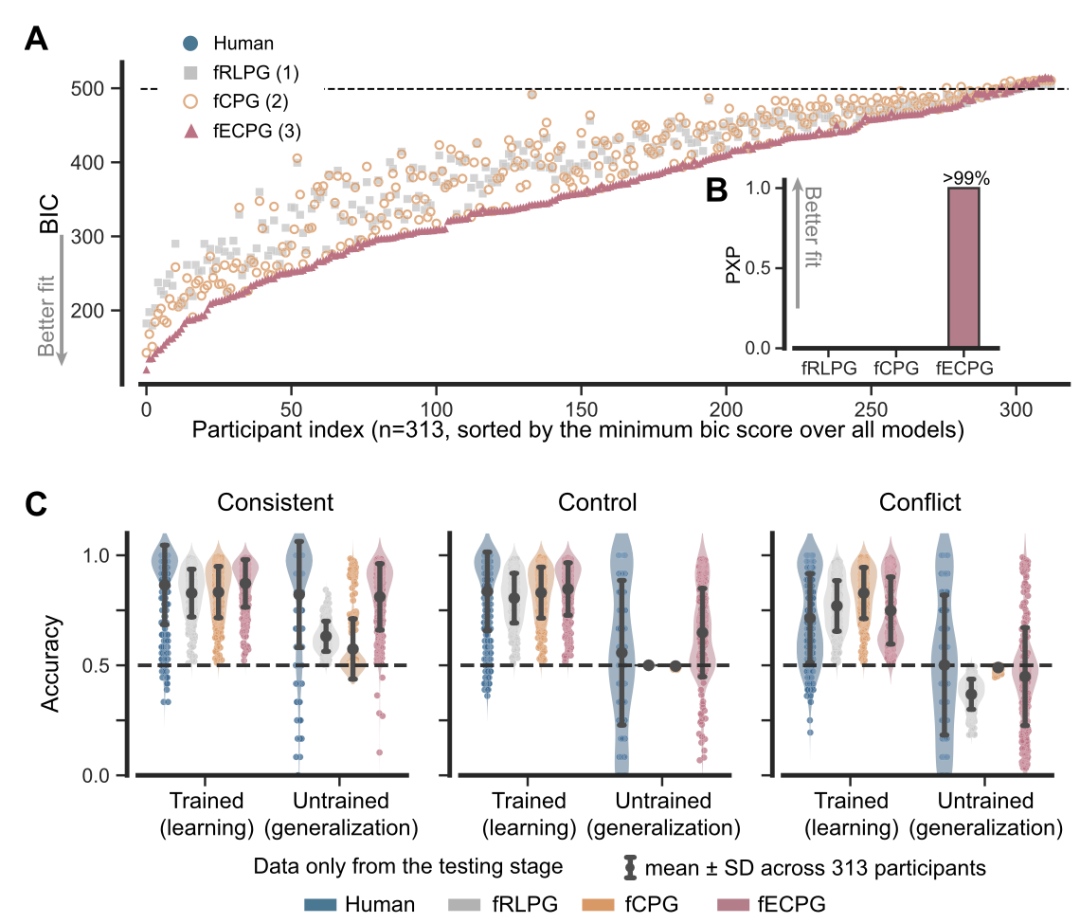
图 3. 实验二中人类和模型的表现。
高效编码:超越算法机制的通用框架
高效编码:超越算法机制的通用框架
研究者对比了ECPG模型与多个算法级模型(如潜在原因聚类模型LC、记忆关联模型MA和注意力选择模型ACL),发现ECPG在解释人类行为上更具优势。这些算法模型虽能实现部分泛化,但其机制(如聚类或注意力分配)本质上是高效编码的具体实现。例如,LC模型通过聚类简化表征,ACL模型通过注意力筛选特征,均符合高效编码的目标。
研究还排除了其他正则化方法(如L1/L2范数)的干扰,证明信息论复杂度是解释人类泛化的最佳指标。模型恢复分析进一步验证了ECPG的独特性,其优势并非来自参数灵活性,而是对认知机制的准确刻画。
理论意义与未来方向
理论意义与未来方向
高效编码与奖励最大化的结合,体现了资源理性(Resource Rationality)原则:人类在有限认知资源下优化决策。这一框架不仅解释了泛化能力,还为理解精神分裂症、阿尔茨海默病等患者的表征学习障碍提供了新视角。
未来研究可将该框架扩展至多步决策(如马尔可夫决策过程)和复杂任务(如规划与多任务学习),进一步验证高效编码的普适性。此外,这一成果对人工智能具有启示意义:在开放环境中,智能体需像人类一样通过简化表征实现高效学习与迁移。
关于集智俱乐部
集智俱乐部成立于 2003 年,是一个从事学术研究、享受科学乐趣的探索者的团体,也是国内最早的研究人工智能、复杂系统的科学社区。它倡导以平等开放的态度、科学实证的精神,进行跨学科的研究与交流,力图搭建一个中国的 “ 没有围墙的研究所 ”。集智科学研究中心(民间非盈利企业)是集智俱乐部的运营主体,长期运营社区生态,催化理论创新。使命:营造跨学科探索小生境,催化复杂性科学新理论。
大模型可解释性读书会
集智俱乐部联合上海交通大学副教授张拳石、阿里云大模型可解释性团队负责人沈旭、彩云科技首席科学家肖达、北京师范大学硕士生杨明哲和浙江大学博士生姚云志共同发起「大模型可解释性」读书会。本读书会旨在突破大模型“黑箱”困境,尝试从以下四个视角梳理大语言模型可解释性的科学方法论:
自下而上:Transformer circuit 为什么有效?
自上而下:神经网络的精细决策逻辑和性能根因是否可以被严谨、清晰地解释清楚?

6. 加入集智,玩转复杂,共创斑图!集智俱乐部线下志愿者招募
内容中包含的图片若涉及版权问题,请及时与我们联系删除
