
深夜,沉寂已久的Kimi突然发布了新模型——
开源代码模型Kimi-Dev,在SWE-bench Verified上以60.4%的成绩取得开源SOTA。
参数量只有72B,但编程水平比最新的DeepSeek-R1还强,和闭源模型比较也表现优异。
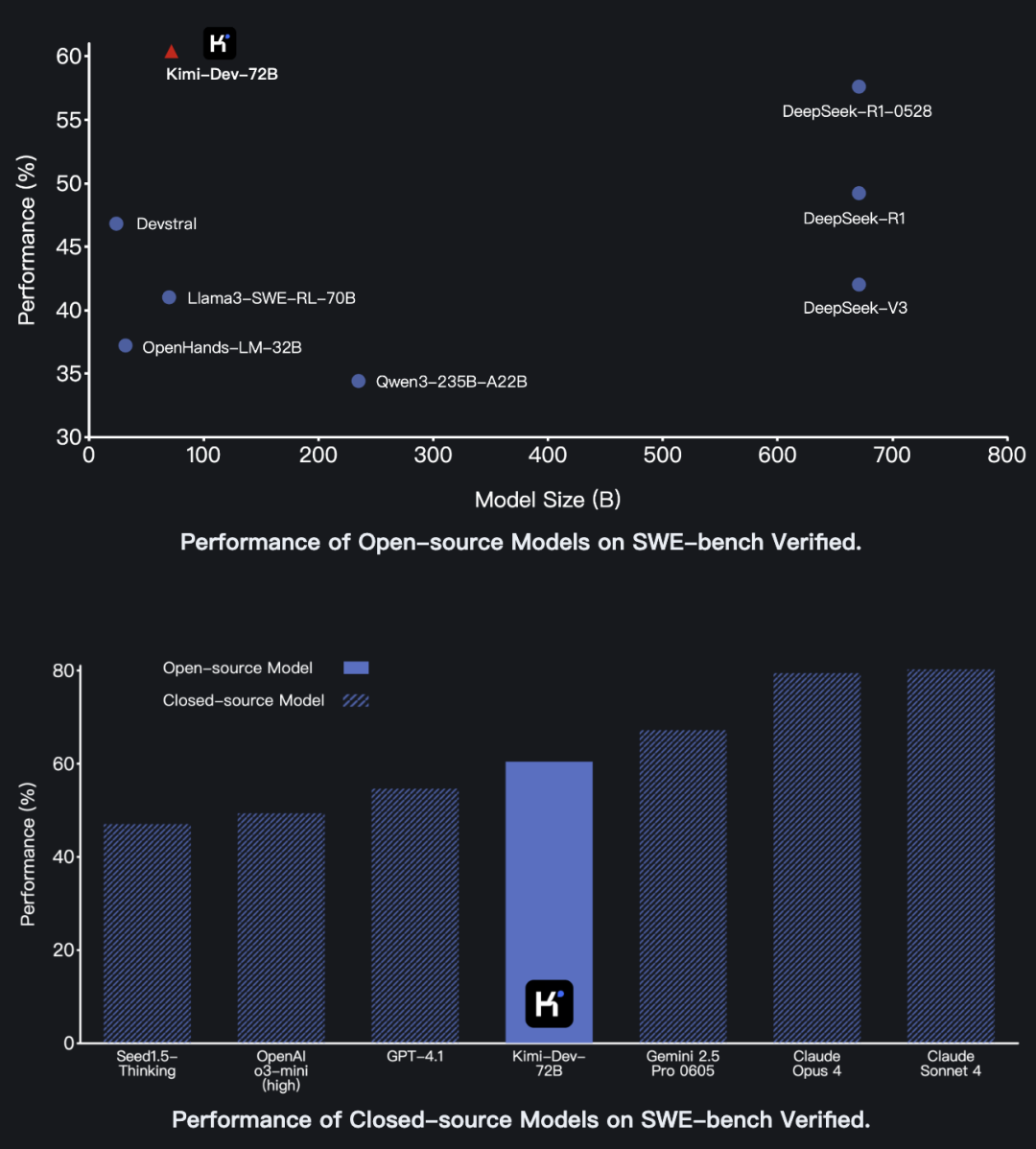
有网友看到后表示,感觉月之暗面的实力被低估了,其水平应该比xAI强。

Kimi-Dev采用MIT协议,目前权重和代码均已发布,还有网友制作的量化版本也已在抱抱脸上线。
那么,Kimi-Dev是如何做到的呢?
模型扮演两种角色,在测试中自我博弈
目前,Kimi-Dev的完整技术报告暂未出炉,不过官方透露了其中的一些关键技术。
Kimi-Dev-72B的设计核心是BugFixer和TestWriter两种角色的结合,BugFixer和TestWriter都遵循一个共同的最小框架,包含两个阶段:

为了增强Kimi-Dev-72B作为BugFixer和TestWriter的先验知识,Kimi团队以Qwen 2.5-72B基础模型为起点使用约1500亿高质量真实数据进行中期训练。
具体来说,Kimi团队收集了数百万个GitHub issue和PR提交,目的是让Kimi-Dev-72B能够学习人类开发人员如何推理并解决GitHub问题。
另外,Kimi团队还进行了严格的数据净化,确保训练数据当中不包含SWE-bench Verified里的内容。
经过中期训练和监督微调(SFT)后,Kimi-Dev-72B在文件定位方面已经表现出色,之后的强化学习阶段主要侧重于提升其代码编辑能力。
强化学习训练采用了Kimi k1.5中的策略优化方法,主要有三个关键设计:
一是仅基于结果的奖励(Outcome-based Reward Only)——训练中仅使用代码在Docker环境中的最终执行结果(成功为 1,失败为 0)作为奖励,而不考虑任何与代码格式或编写过程的因素。
这确保了模型生成的解决方案的正确性以及与实际开发标准的一致性。
二是采用了高效提示集(Efficient Prompt Set),过滤掉在多样本评估下成功率为零的提示,以更有效地进行大批量训练。
此外,强化学习阶段还采取了循序渐进的策略,逐步引入新提示,逐步增加任务难度。
三是正向示例强化(Positive Example Reinforcement),也就是在后面的训练过程中,Kimi-Dev会将它之前已经解决的问题的方案重新纳入当前的训练批次中进行学习,从而巩固和强化之前有效的、成功的解决模式和方法。
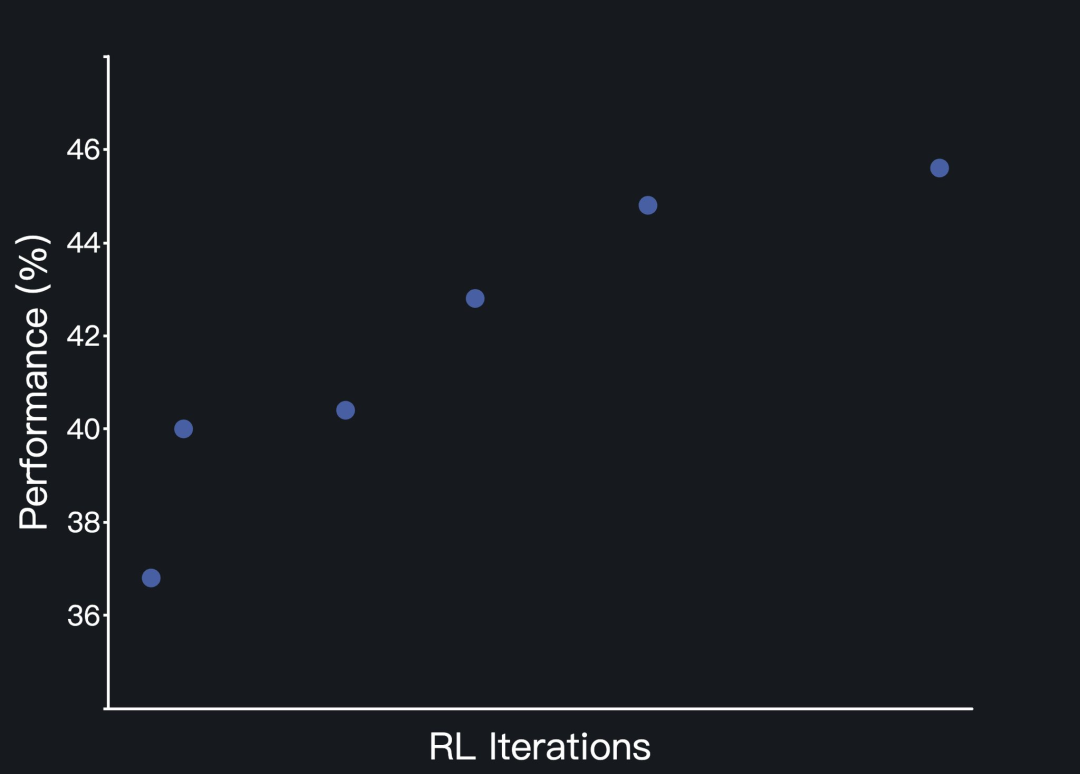
经过强化学习后,Kimi-Dev-72B能够同时掌握两种角色。在测试过程中,它会采用自我博弈机制,协调自身Bug修复和测试编写的能力。
Kimi-Dev-72B会遵循标准Agentless设置,为每个问题生成最多40个补丁候选(patch candidates)和40个测试候选(test candidates)。
在测试时间自我博弈中,观察到了规模效应(scaling effect)。
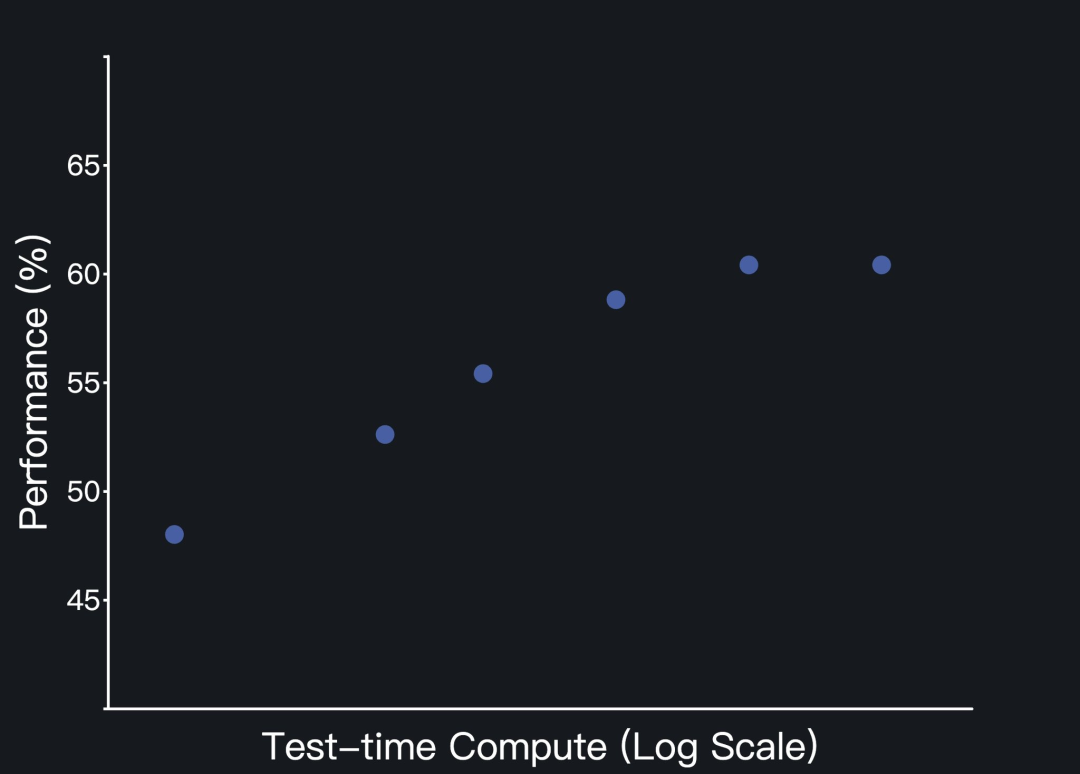
以上就是Kimi团队介绍的Kimi-Dev背后的关键,更多细节将在后续的技术报告中揭晓,感兴趣的话可以关注Kimi团队的发布。
下一步,Kimi团队还计划探索更复杂的软件工程任务,并将于与流行的IDE、版本控制系统和CI/CD流水线进行更深入的集成。
项目主页:
https://moonshotai.github.io/Kimi-Dev/
GitHub:
https://github.com/MoonshotAI/Kimi-Dev
HuggingFace:
https://huggingface.co/moonshotai/Kimi-Dev-72B
— 完 —
📪 量子位AI主题策划正在征集中!欢迎参与专题365行AI落地方案,一千零一个AI应用,或与我们分享你在寻找的AI产品,或发现的AI新动向。
💬 也欢迎你加入量子位每日AI交流群,一起来畅聊AI吧~

一键关注 👇 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
内容中包含的图片若涉及版权问题,请及时与我们联系删除
