
7 Key Insights from the State of DevSecOps Report (Sponsored)

Datadog analyzed data from tens of thousands of orgs to uncover 7 key insights on modern DevSecOps practices and application security risks.
Highlights:
Why smaller container images reduce severe vulns
How runtime context helps you prioritize critical CVEs
The link between deploy frequency and outdated dependencies
Plus, learn proven strategies to implement infrastructure as code, automated cloud deploys, and short-lived CI/CD credentials.
Disclaimer: The details in this post have been derived from the details shared online by the Google Engineering Team. All credit for the technical details goes to the Google Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
On June 12, 2025, a significant portion of the internet experienced a sudden outage. What started as intermittent failures on Gmail and Spotify soon escalated into a global infrastructure meltdown. For millions of users and hundreds of companies, critical apps simply stopped working.
At the heart of it all was a widespread outage in Google Cloud Platform (GCP), which serves as the backend for a vast ecosystem of digital services. The disruption began at 10:51 AM PDT, and within minutes, API requests across dozens of regions were failing with 503 errors. Over a few hours, the ripple effects became undeniable.
Among consumer platforms, the outage took down:
Spotify (approximately 46,000 users reported on Downdetector).
Snapchat, Discord, Twitch, and Fitbit: users were unable to stream, chat, or sync their data.
Google Workspace apps (including Gmail, Calendar, Meet, and Docs). These apps power daily workflows for hundreds of millions of users.
The failure was just as acute for enterprise and developer tools:
GitLab, Replit, Shopify, Elastic, LangChain, and other platforms relying on GCP services saw degraded performance, timeouts, or complete shutdowns.
Thousands of CI/CD pipelines, model serving endpoints, and API backends stalled or failed outright.
Vertex AI, BigQuery, Cloud Functions, and Google Cloud Storage were all affected, halting data processing and AI operations.

In total, more than 50 distinct Google Cloud services across over 40 regions worldwide were affected.
Perhaps the most significant impact came from Cloudflare, a company often viewed as a pillar of internet reliability. While its core content delivery network (CDN) remained operational, Cloudflare's authentication systems, reliant on Google Cloud, failed. This led to issues with session validation, login workflows, and API protections for many of its customers.
The financial markets also felt the impact of this outage. Alphabet (Google’s parent) saw its stock fall by nearly 1 percent. The logical question that arose from this incident is as follows: How did a platform built for global scale suffer such a cascading collapse?
Let’s understand more about it.
Special Event: Save 20% on Top Maven Courses (Sponsored)

Your education is expiring faster than ever. What you learned in college won’t help you lead in the age of AI.
That's why Maven specializes in live courses with practitioners who have actually done the work and shipped innovative products:
Shreyas Doshi (Product leader at Stripe, Twitter, Google) teaching Product Sense
Hamel Husain (renowned ML engineer, Github) teaching AI evals
Aish Naresh Reganti (AI scientist at AWS) teaching Agentic AI
Hamza Farooq (Researcher at Google) teaching RAG
This week only: Save 20% on Maven’s most popular courses in AI, product, engineering, and leadership to accelerate your career.
Inside the Outage
To understand how such a massive outage occurred, we need to look under the hood at a critical system deep inside Google Cloud’s infrastructure. It’s called the Service Control.
The Key System: Service Control
Service Control is one of the foundational components of Google Cloud's API infrastructure.
Every time a user, application, or service makes an API request to a Google Cloud product, Service Control sits between the client and the backend. It is responsible for several tasks such as:
Verifying if the API request is authorized.
Enforcing quota limits (how many requests can be made).
Checking various policy rules (such as organizational restrictions).
Logging, metering, and auditing requests for monitoring and billing.
The diagram below shows how the Service Control works on a high level:
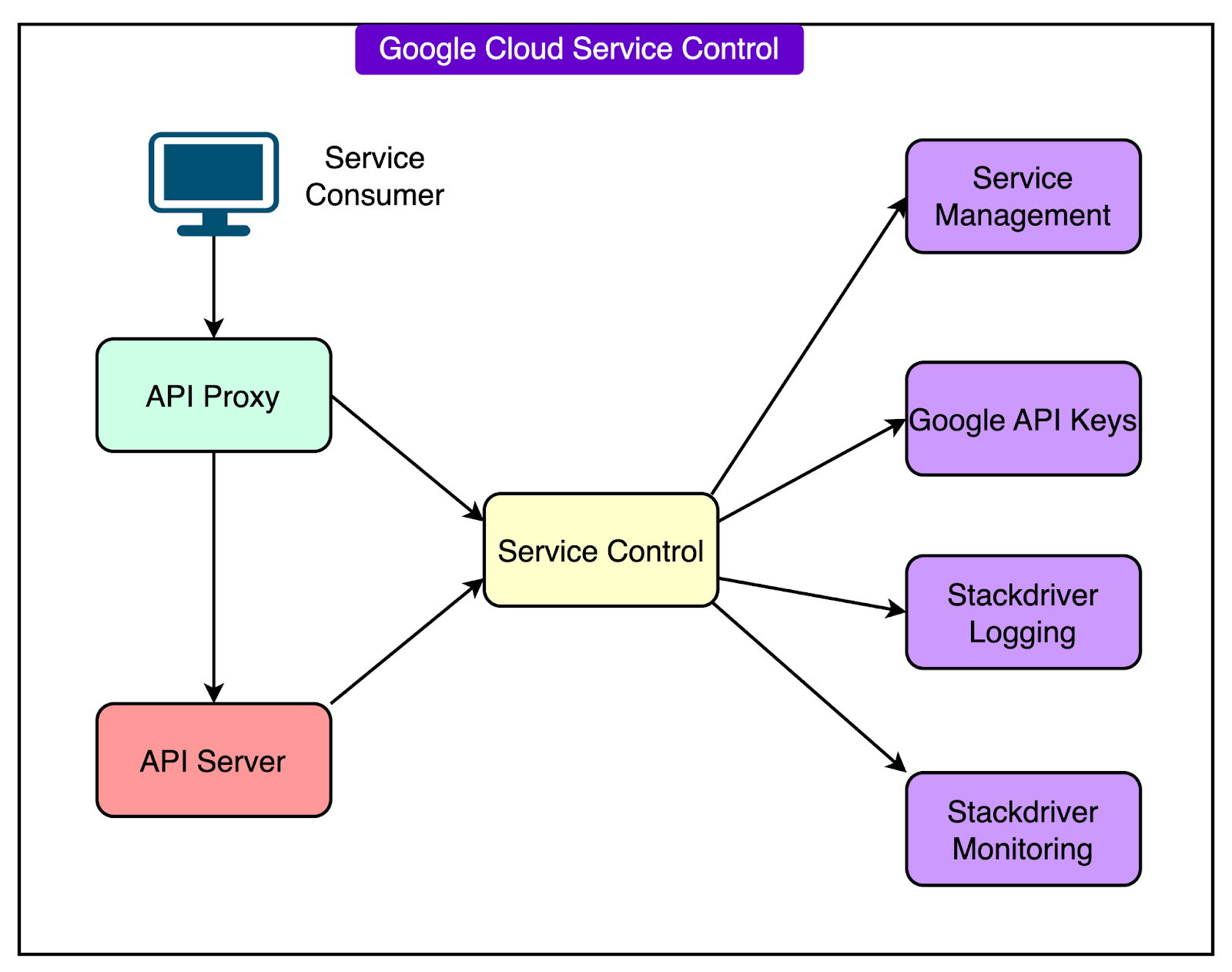
In short, Service Control acts as the gatekeeper for nearly all Google Cloud API traffic. If it fails, most of Google Cloud fails with it.
The Faulty Feature
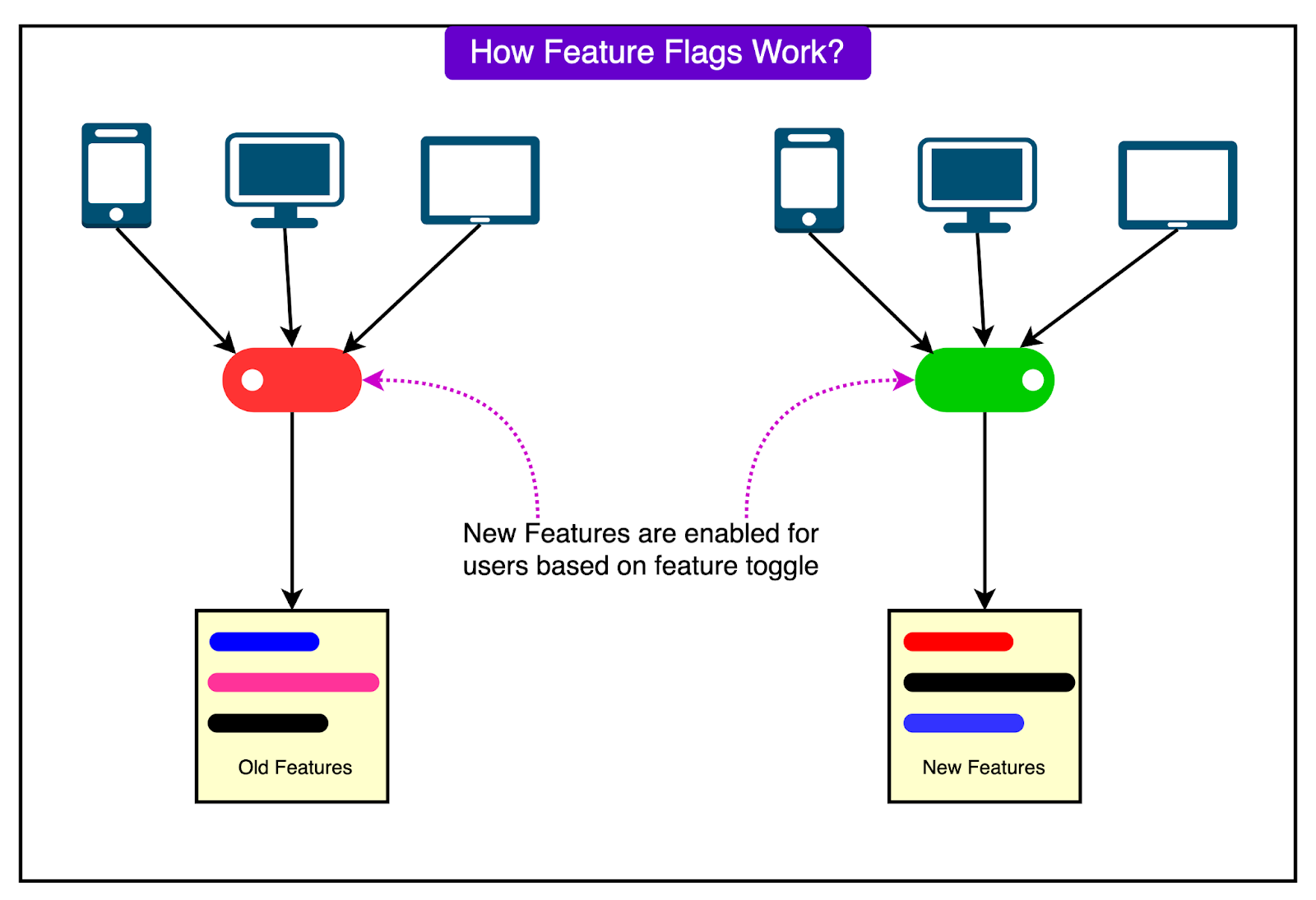
On May 29, 2025, Google introduced a new feature into the Service Control system. This feature added support for more advanced quota policy checks, allowing finer-grained control over how quota limits are applied.
The feature was rolled out across regions in a staged manner. However, it contained a bug that introduced a null pointer vulnerability in a new code path that was never exercised during rollout. The feature relied on a specific type of policy input to activate. Because that input had not yet been introduced during testing, the bug went undetected.
Critically, this new logic was also not protected by a feature flag, which would have allowed Google to safely activate it in a controlled way. Instead, the feature was present and active in the binary, silently waiting for the right (or in this case, wrong) conditions to be triggered.
The Triggering Event
Those conditions arrived on June 12, 2025, at approximately 10:45 AM PDT, when a new policy update was inserted into Google Cloud’s regional Spanner databases. This update contained blank or missing fields that were unexpected by the new quota checking logic.
As Service Control read this malformed policy, the new code path was activated. The result was a null pointer error getting triggered, causing the Service Control binary to crash in that region.
Since Google Cloud’s policy and quota metadata is designed to replicate globally in near real-time as per Spanner’s key feature, the corrupted policy data was propagated to every region within seconds.
Here’s a representative diagram on how replication works in Google Spanner:
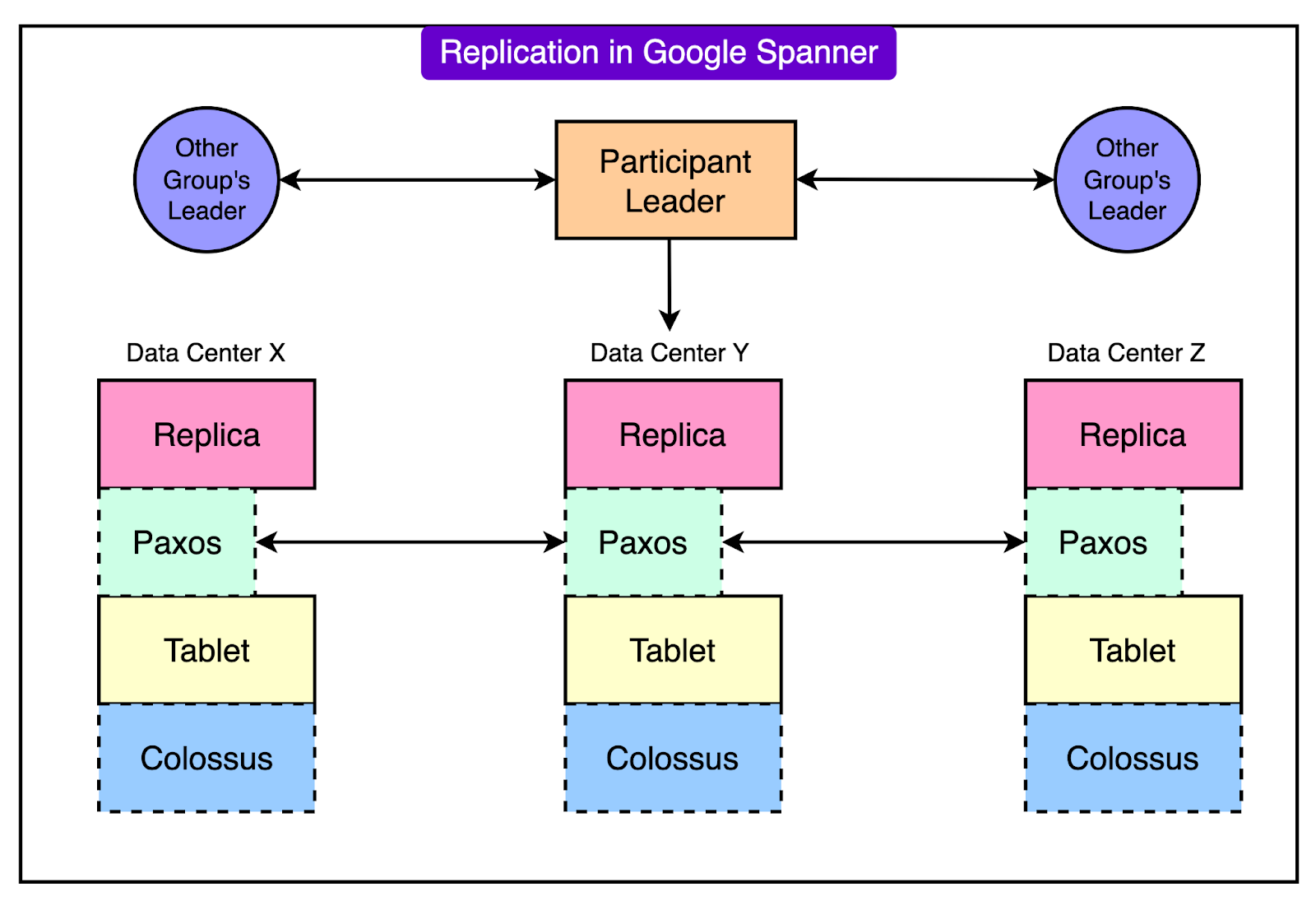
As soon as each regional Service Control instance attempted to process the same bad data, it all began to crash in the same way. This created a global failure of Service Control.
Since this system is essential for processing API requests, nearly all API traffic across Google Cloud began to fail, returning HTTP 503 Service Unavailable errors.
The speed and scale of the failure were staggering. One malformed update, combined with an unprotected code path and global replication of metadata, brought one of the most robust cloud platforms in the world to a standstill within minutes.
How Google Responded?
Once the outage began to unfold, Google’s engineering teams responded with speed and precision. Within two minutes of the first crashes being observed in Service Control, Google’s Site Reliability Engineering (SRE) team was actively handling the situation.
The sequence of events that followed is as follows:.
The Red Button Fix
Fortunately, the team that introduced the new quota checking feature had built in a safeguard: an internal “red-button” switch. This kill switch was designed to immediately disable the specific code path responsible for serving the new quota policy logic.
While not a complete fix, it offered a quick way to bypass the broken logic and stop the crash loop.
The red-button mechanism was activated within 10 minutes of identifying the root cause. By 40 minutes after the incident began, the red-button change had been rolled out across all regions, and systems began to stabilize. Smaller and less complex regions recovered first, as they required less infrastructure coordination.
This kill switch was essential in halting the worst of the disruption. However, because the feature had not been protected by a traditional feature flag, the issue had already been triggered in production globally before the red button could be deployed.
Delayed Recovery in US-CENTRAL-1
Most regions began to recover relatively quickly after the red button was applied. However, one region (us-central-1), located in Iowa, took significantly longer to stabilize.
The reason for this delay was a classic case of the “herd effect.”
As Service Control tasks attempted to restart en masse, they all hit the same underlying infrastructure: the regional Spanner database that held policy metadata. Without any form of randomized exponential backoff, the system became overwhelmed by a flood of simultaneous requests. Rather than easing into recovery, it created a new performance bottleneck.
Google engineers had to carefully throttle task restarts in us-central1 and reroute some of the load to multi-regional Spanner databases to alleviate pressure. This process took time. Full recovery in us-central1 was not achieved until approximately 2 hours and 40 minutes after the initial failure, well after other regions had already stabilized.
Communication Breakdown
While the technical team worked to restore service, communication with customers proved to be another challenge.
Because the Cloud Service Health dashboard itself was hosted on the same infrastructure affected by the outage, Google was unable to immediately post incident updates. The first public acknowledgment of the problem did not appear until nearly one hour after the outage began. During that period, many customers had no clear visibility into what was happening or which services were affected.
To make matters worse, some customers relied on Google Cloud monitoring tools, such as Cloud Monitoring and Cloud Logging, that were themselves unavailable due to the same root cause. This left entire operations teams effectively blind, unable to assess system health or respond appropriately to failing services.
The breakdown in visibility highlighted a deeper vulnerability: when a cloud provider's observability and communication tools are hosted on the same systems they are meant to monitor, customers are left without reliable status updates in times of crisis.
The Key Engineering Failures
The Google Cloud outage was not the result of a single mistake, but a series of engineering oversights that compounded one another. Each failure point, though small in isolation, played a role in turning a bug into a global disruption.
Here are the key failures that contributed to the entire issue:
The first and most critical lapse was the absence of a feature flag. The new quota-checking logic was released in an active state across all regions, without the ability to gradually enable or disable it during rollout. Feature flags are a standard safeguard in large-scale systems, allowing new code paths to be activated in controlled stages. Without one, the bug went live in every environment from the start.
Second, the code failed to include a basic null check. When a policy with blank fields was introduced, the system did not handle the missing values gracefully. Instead, it encountered a null pointer exception, which crashed the Service Control binary in every region that processed the data.
Third, Google’s metadata replication system functioned exactly as designed. The faulty policy data propagated across all regions almost instantly, triggering the crash everywhere. The global replication process had no built-in delay or validation checkpoint to catch malformed data before it reached production.
Fourth, the recovery effort in the “us-central1” region revealed another problem. As Service Control instances attempted to restart, they all hit the backend infrastructure at once, creating a “herd effect” that overwhelmed the regional Spanner database. Because the system lacked appropriate randomized exponential backoff, the recovery process generated new stress rather than alleviating it.
Finally, the monitoring and status infrastructure failed alongside the core systems. Google’s own Cloud Service Health dashboard went down during the outage, and many customers could not access logs, alerts, or observability tools that would normally guide their response. This created a critical visibility gap during the peak of the crisis.
Conclusion
In the end, it was a simple software bug that brought down one of the most sophisticated cloud platforms in the world.
What might have been a minor error in an isolated system escalated into a global failure that disrupted consumer apps, developer tools, authentication systems, and business operations across multiple continents. This outage is a sharp reminder that cloud infrastructure, despite its scale and automation, is not infallible.
Google acknowledged the severity of the failure and issued a formal apology to customers. In its public statement, the company committed to making improvements to ensure such an outage does not happen again. The key actions Google has promised are as follows:
Prevent the API management system from crashing in the presence of invalid or corrupted data.
Introduce safeguards to stop metadata from being instantly replicated across the globe without proper testing and monitoring.
Improve error handling in core systems and expand testing to ensure invalid data is caught before it can cause failure.
Reference:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com
