
思维链(Chain of Thought, CoT)推理方法已被证明能够显著提升大语言模型(LLMs)在复杂任务中的表现。而在多模态大语言模型(MLLMs)中,CoT 同样展现出了巨大潜力。
然而,当视觉信息与数学推理结合时,传统的 CoT 方法就显得力不从心了——视觉输入中的数学细节往往被忽略,导致推理结果不准确。
最近,香港中文大学 MMLab 团队正式发布了全新的视觉推理方案——MINT-CoT,专为解决“多模态数学推理”中的难题而设计。

为什么数学视觉推理这么难?
尽管已有一些研究尝试把视觉信息引入 CoT 推理,例如 Visual-CoT、Visual SKETCHPAD、VPT、ICoT 等方法,但在数学场景下依然存在 三大瓶颈:
1. 粗粒度图像区域选择
大部分方法依赖边界框(Bounding Box)来截取图像区域。但数学图像里的元素(比如坐标轴、几何图形、标注文字等)高度关联,简单裁剪很容易把无关或干扰信息带进推理过程。
2. 视觉编码器“看不懂数学”
目前主流视觉编码器(如 CLIP、SigLIP)都是针对自然图像训练的,对于公式、几何图等“数学型图像”,它们属于“分布外”内容,感知力严重不足。
3. 过度依赖外部功能
像 MVoT 或 Visual SKETCHPAD 等方法,需要借助外部工具或能力来生成或修改图像,训练和推理过程成本高、不通用。

MINT-CoT:细粒度视觉交错推理新范式
为了解决上述痛点,团队提出了 MINT-CoT(Multimodal Interleaved Chain-of-Thought)——一种细粒度、轻量级的视觉交错 CoT 推理方法,专为数学推理场景设计。
核心创新在于引入了一种特殊的 Interleave Token——模型在生成下一个 token 时,会动态从图像中选取与当前推理步骤最相关的视觉 token,并嵌入文本推理链中。这个过程通过计算计算 Interleave Token 的隐藏层与所有视觉 token 的隐藏层的相似度来实现,从而动态选取与数学概念最相关的视觉区域,将图像与文本细粒度地融合。
相比传统基于矩形区域的方法,MINT-CoT 可以灵活选取任意形状的视觉区域,比如几何图形、坐标、线段等结构化数学元素,实现真正的 “图文联合推理”。
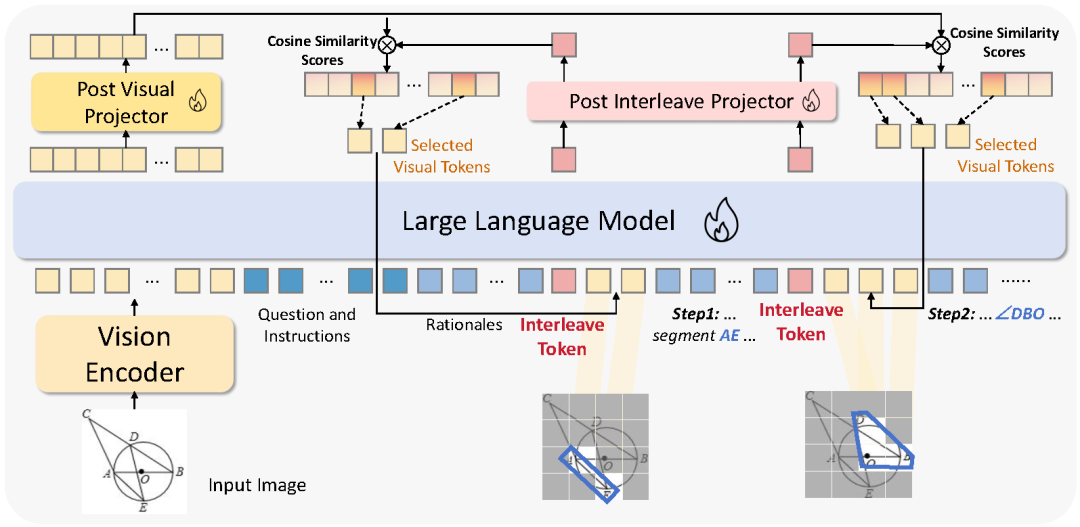
数据集:打造“视觉交错推理”的专属训练集
为了支撑MINT-CoT的训练,团队还构建了 MINT-CoT 数据集,共 5.4 万条视觉交错推理样本,每条数据都包含推理步骤与相应图像中 token 的对齐信息。基于 Mulberry-260K 数据集生成文本推理链,再通过以下四步流程完成视觉区域标注:
(1) 将图像划分为网格区域, (2) 利用 OCR 检测图像中文本并映射到对应网格, (3) 提取推理关键词, (4) 使用MLLM关联关键词与图像区域,完成 token级别的匹配标注。
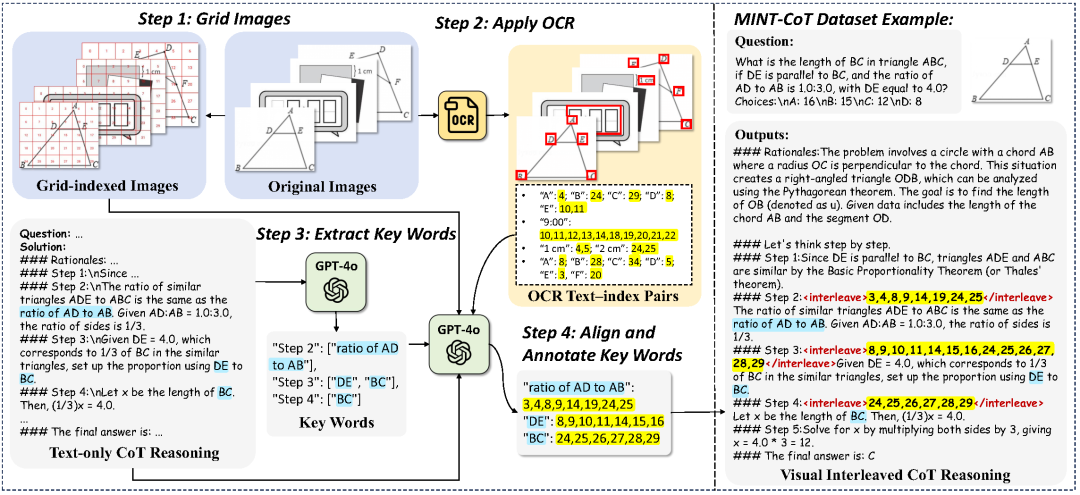
三阶段训练策略:逐步提升视觉交错推理能力
在MINT-CoT框架和数据集的基础上,设计了一个三阶段的训练策略,逐步提升模型的推理能力,具体包括:
(1) 文本CoT微调:通过纯文本推理数据训练模型,打下通用推理格式的基础 (2) 交错模态CoT微调:使用两个损失函数监督文本推理和视觉token选择,教会模型在推理过程中合理插入视觉内容,实现图文联合推理能力。 (3) 交错模态CoT强化学习:利用强化学习优化视觉内容选择和推理策略,让模型自主探索更优解法。
实验效果:全面超越现有方法
我多模态大模型Qwen-VL-7B的基础上应用MINT-CoT框架,训练出 MINT-CoT-7B 模型,在数学视觉推理任务中表现优越。下面的可视化结果表明,MINT-CoT-7B 相比于基线模型,表现出更合理的推理形式,可以在推理过程中选择相关的视觉token,并和文本内容一起交错推理。
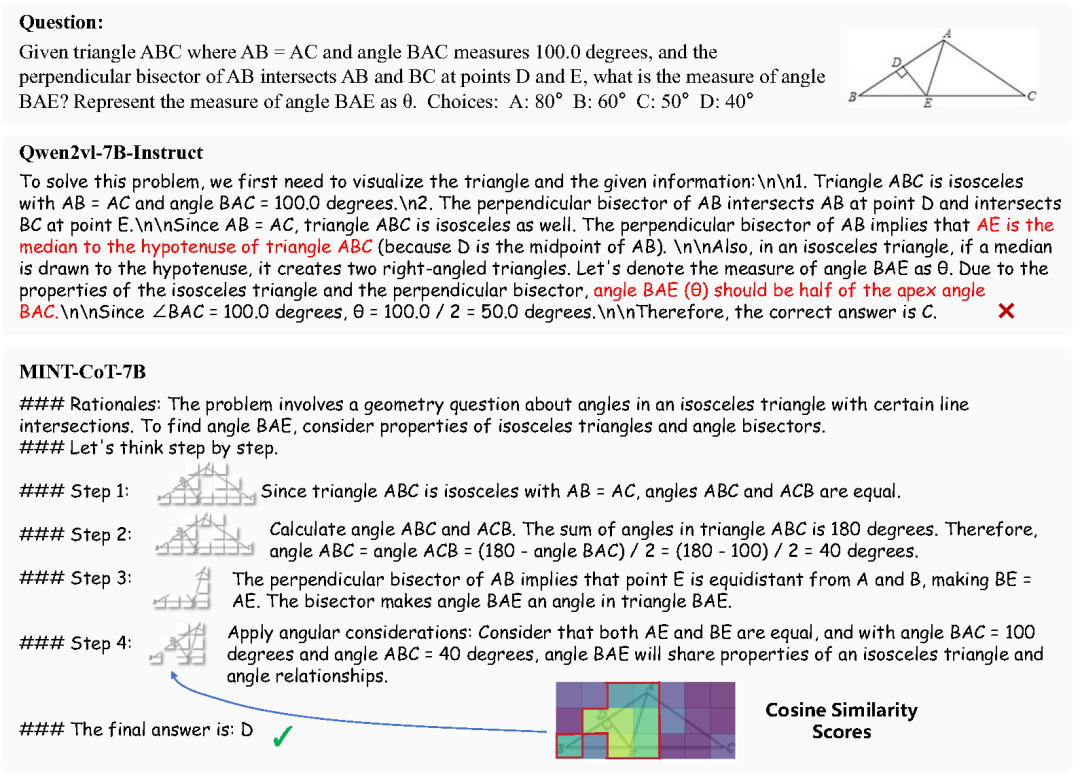
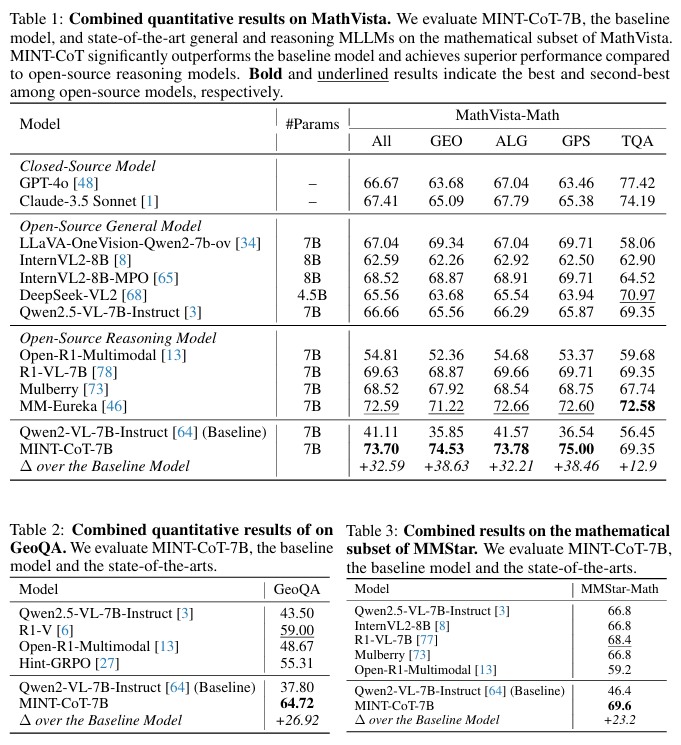
定量的实验结果也表明了本方法的有效性。MINT-CoT-7B 在多个基准上实现显著提升:在MathVista上提升 +32.59%,在GeoQA上提升+26.92%,在MMStar上提升 +23.2%。不仅如此,MINT-CoT-7B全面超越原有SOTA模型,成为数学视觉推理领域的新标杆。
小结:
通过提出MINT-CoT,实现了细粒度视觉信息与思维链推理的深度融合,显著提升多模态大模型在数学视觉推理任务中的表现。未来,MINT-CoT有望拓展至更多结构化视觉场景,推动多模态推理技术进一步发展。
论文:https://arxiv.org/abs/2506.05331
代码:https://github.com/xinyan-cxy/MINT-CoT
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
