
A response has been made to the Apple’s ‘The Illusion of Thinking’ paper they released last week. If you missed last week’s ML for SWEs, we discussed what Apple was getting at with their paper and why it didn’t really mean much.
Well, a response to that paper cleverly titled ‘The Illusion of the Illusion of Thinking’ rebuts the Apple paper’s points by explaining the flaws within the experimentation methodology that caused model performance to collapse without adequately proving the cause to limitations of modeling reasoning.

In summary, the critique mentions that experiment length was a limiting factor. All experiments required models to output large sequences of moves exceeding their token output limits (something many models even mentioned within their reasoning chain).
Once experiments were tweaked to require a smaller output (i.e. “create a function that solves this” instead of “enumerate the step-by-step instructions for solving this”), the models performed very well, even on much larger problem sizes. Essentially, the critique explains that the number of moves to solve a problem isn’t an adequate measure of complexity.
The paper actually made some good points, but the most interesting thing about this rebuttal is the authors. Notice: “C. Opus” as the first author. We’ll get into that next.
How to keep up-to-date on ML research
You read that right, Claude Opus was an author on the rebuttal we discussed. At first, I thought this must be a joke (and it turns out I was right—this is an article the author made explaining that the paper was primarily a joke and that part of the joke was to include Claude as an author), but I realized we’re probably not too far from this being a reality.
AI is being used to write research papers all the time and I assume it’s also used to review them. There isn’t anything inherently wrong with this (unless it’s used to cut corners or authors refuse to proofread their own work), but it’s absolutely something you need to be aware of.
Most notably because a lot of the AI papers being posted to ArXiv are low-effort or inconsequential (it’s a pretty bad sign when something obviously AI-written is left in the research paper and the authors clearly haven’t proofread their own work). Without the proper due diligence, a paper meant to be a joke (such as the paper above) is spread far and wide without much thought.
The important thing to understand about ArXiv is that while there are many very important papers submitted, there is much more noise. ArXiv is NOT peer-reviewed.
People often assume that anything considered a ‘paper’ is peer-reviewed because that’s what ‘papers’ used to be. They were submitted to journals and conferences where submissions were reviewed by subject matter experts. A paper was only considered a paper when it had passed that review process. On ArXiv, anyone can write up their findings and share it without proper review.

For a while, I made a concentrated effort to stay updated on the cutting edge of machine learning and artificial intelligence research by tracking submission to ArXiv.org and trying to pull out the truly impactful and interesting submissions.
I quickly realized how infeasible this was. There are at least 7 different ArXiv sections to keep track of only in the computer science section alone (Artificial Intelligence, Computer Vision, Emerging Technologies, Machine Learning, Multiagent Systems, and Neural and Evolutionary Computing). I was attempting to go through ~150 submissions per day.
Keep in mind that this doesn’t include any math categories and many AI/ML submissions are submitted there as well. If you want to see the actual data breakdown, you can check it out here.
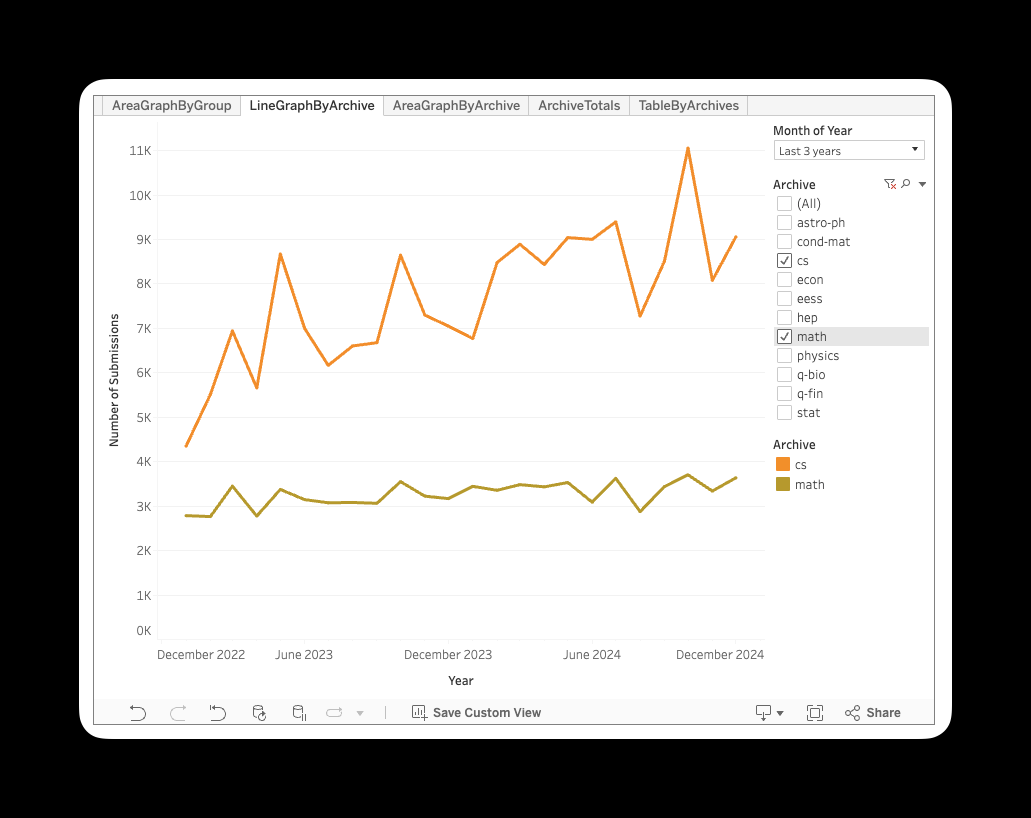
So how do we dig through a massive sea of AI/ML research with a ton of noise? I posed this question to a long while back. If you’re familiar with Cameron’s writing, you know he does an excellent job of getting deep with the latest ML advancements. His answer was simply: You don’t.
It would take a great deal of expertise and a lot of time to dig through the noise on ArXiv and find the groundbreaking research findings. So, you let experts do it for you. Here are the 3 ways I stay updated.
1. X/Twitter
I know a lot of you reading this probably don’t like X, but it’s without a doubt the best way to find important research papers. The AI community on X crowdsources the work of sifting through papers and experts share their take on findings. It’s an incredibly high signal-to-noise ratio for ML research—which is exactly what we’re looking for.
X is still the default platform that the AI community uses (although Substack is growing!), so it’s difficult to be on top of things without an account there. If you’re wanting to get started but are not a fan of the platform, shoot me a DM. I can help you get started and avoid the bad side of X.
If you’re not a fan of X, here are two more resources I used.
2. Weekly Top AI Papers
I subscribe to and read ’s and he goes over the top AI papers of the week each week. It’s primarily sourced from X, but put into a nice package that you receive once a week. This is the definition of someone doing the sifting for you.
These write ups are great for looking through a list of papers, reading the summary, and seeing if its something interesting to you. Again, high signal-to-noise, but this one is nice because it doesn’t require being on a specific social platform (although it is nice it’s on Substack!).
3. MarkTechPost
My last suggestion is using MarkTechPost to stay updated. Important papers are usually shared via articles here, sometimes with an explanation of the important parts of the newsletter. I don’t recommend this quite as highly as the previous two sources because there’s a bit more noise, but sometimes you’ll find a gem of paper that others have overlooked because of this.
If you want to keep track of MarkTechPost posts, I recommend using an RSS reader to keep tabs on it. This way your reader keeps track of what’s there and makes it really easy to ignore anything that isn’t of interest to you.
Those are my favorites. If you have any resources you use that I’ve missed, let us know in the comments.
Onto the interesting posts from this week.
AI is being used for warfare
It’s super interesting to chat with others about how AI is being used in warfare and to get the reaction of the different individuals I’ve discussed this with. Some people see this as the greatest thing ever and other people see it as the most terrible.
I love thinking about AI’s applications and what they mean and I highly recommend ’s recent article on the AI arms race and the reality of it.
Understanding AI agents from the ground up
If you are (or are going to be) a machine learning engineer, you’ll encounter AI agents and likely build with them in some form or another. It’s estimated that a large majority of internet traffic will be agent-to-agent traffic in the very near future.
wrote about AI Agent from First Principles. Cameron’s articles are always long, but incredibly well thought-out and go into great depth. This one is truly an excellent read for ML engineers.
What’s next for reinforcement learning
Admittedly, RL is a blindspot for me. I know almost no details about how it works and the intricacies of applying it because it’s never come up in my work.
I keep up with RL via ’s writing. I highly recommend his recent article, “What comes next with reinforcement learning”. He contextualizes the frontier of reinforcement learning and the direction it needs to go. There’s also a voiceover of the article, which is always a nice touch.
How deep research assistants work
Some of my favorite AI tools are deep research assistants. I use them constantly for digging into topics and finding reputable resources for going even further.
I highly recommend an article from from this past week that walks the reader step-by-step through how AI Deep Research works and the architecture that enables it.
Other interesting things
Google is using AI to predict cyclone paths and intensity. The model is trained on decades of historical cyclone weather data to help experts predict upcoming cyclones and their severity.
Meta invested $14.3 billion in Scale AI acquihire Scale’s CEO Alexandr Wang. Mark Zuckerberg has been aggressively hiring for his Superintelligence AI team hiring AI researchers at over nine figures a piece. Mark’s Acquihire of Alexandr Wang seems to be a part of this effort. Understandably, Google, Microsoft, OpenAI, and xAI took a step back from Scale now that it’s 49% owned by a major competitor.
An interesting overview on why “Fine-tuning LLMs is a waste of time”. Here’s a good preview:
Fine-tuning large language models (LLMs) is frequently sold as a quick, powerful method for injecting new knowledge. On the surface, it makes intuitive sense: feed new data into an already powerful model, tweak its weights, and improve performance on targeted tasks.
But this logic breaks down for advanced models, and badly so. At high performance, fine-tuning isn’t merely adding new data — it’s overwriting existing knowledge. Every neuron updated risks losing information that’s already intricately woven into the network. In short: neurons are valuable, finite resources. Updating them isn’t a costless act; it’s a dangerous trade-off that threatens the delicate ecosystem of an advanced model.
That’s all for this week!
Always be (machine) learning,
Logan
