
The GB200 NVL72 is the world's most advanced hardware for AI training and inference. In this blog post, we're excited to share early results from running DeepSeek 671B with prefill-decode disaggregation and large-scale expert parallelism on the GB200 NVL72. By leveraging Blackwell-specific features to enhance existing components, SGLang achieved 7,583 tokens per second per GPU for decoding on the GB200 NVL72—a 2.7x speedup compared to the H100 per GPU (link) for 2,000-token input lengths. Performance is expected to improve further with ongoing optimizations. You can find reproduction instructions here.
Methods
As a preliminary work, we integrated the following components into SGLang:
- Blackwell DeepGEMM: A high-performance General Matrix Multiplication (GEMM) library tailored for FP8 precision, rewritten to fully exploit the Blackwell architecture. Quantization and packing are introduced for input scales in the new API, and the newly introduced UMMA feature are used for fast matrix multiplications.Blackwell DeepEP: A communication library designed to shuffle tokens for routed experts in Mixture of Experts (MoE). The new NVLink-only environment is supported by mapping remote GPU memory to the local virtual address space. We also slightly improved DeepEP performance by 15%.FlashInfer Blackwell FMHA: A high-performance Fused Multi-Head Attention (FMHA) kernel for DeepSeek prefilling, rewritten to support Blackwell architecture.Blackwell CUTLASS MLA: A Multi-Head Latent Attention (MLA) kernel optimized for Blackwell architecture. It leverages the new UMMA feature and enables 2-SM cluster mode for TMA, reducing L2 read traffic on the KV cache.Blackwell Mooncake: A transfer engine utilized in Key-Value (KV) cache transfer for prefill-decode disaggregation. It also employs techniques similar to DeepEP to support NVLink.
Experiments
End-to-end Performance
To assess the decode performance of DeepSeek on the GB200 NVL72, we conducted end-to-end experiments with a comparison to H100. Since we are provided 14 nodes in a GB200 NVL72, we use 12 nodes for decode and the remaining for prefill. This scenario roughly mimics real-world cases when users use 6 nodes for prefill and 12 nodes for decode when having 18 nodes. To ensure consistency, the experimental setup mirrors that of our previous blog post and baselines are reused directly from it. The slow-down API in the previous blog is also used to make decode nodes saturated. The yellow baseline bar indicates simulated MTP in the previous blog, and other bars do not enable MTP. Thus, the speedup is higher than displayed if the same setup is used.
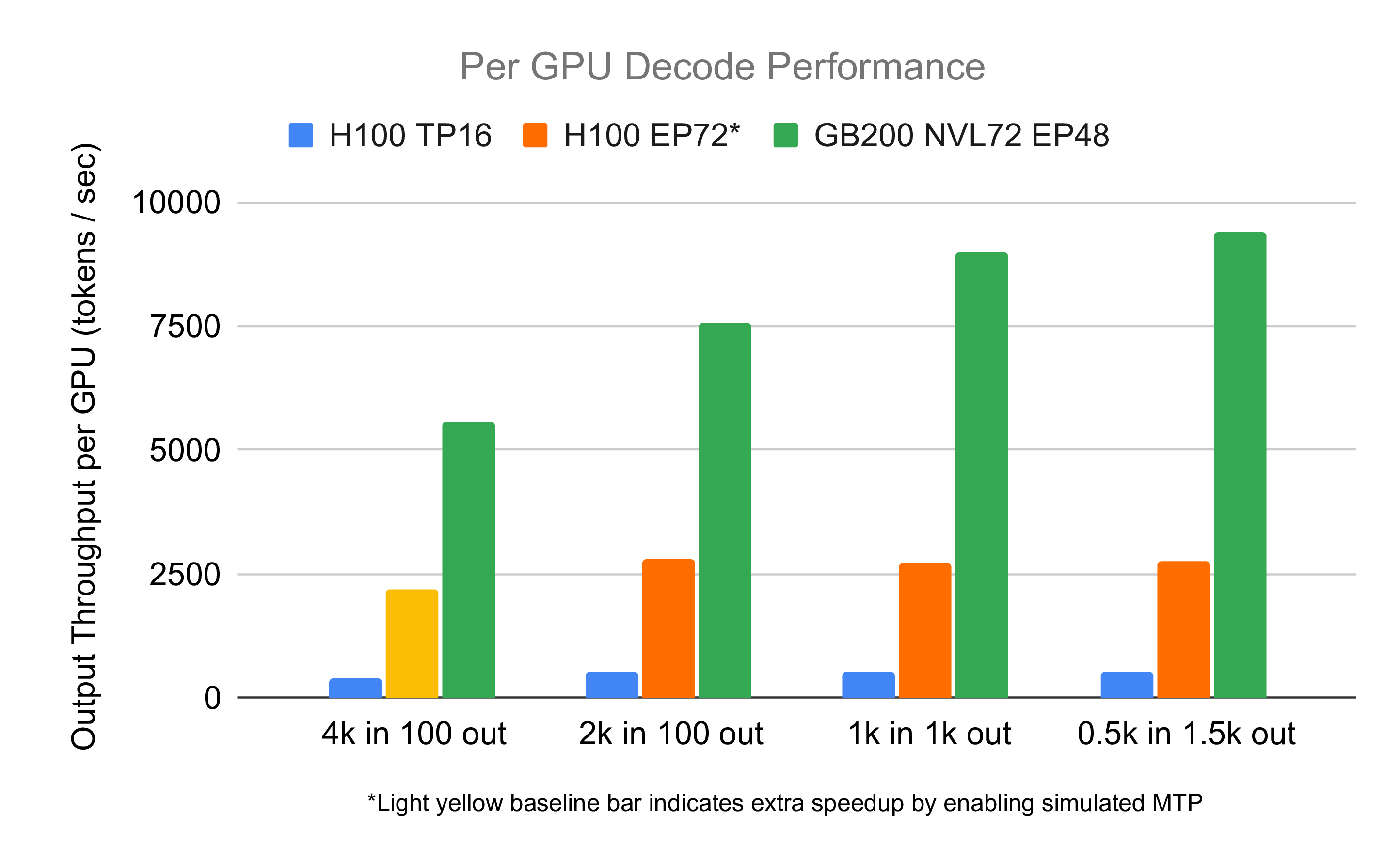
The results demonstrate a 2.5-3.4x performance speedup across various sequence lengths on the GB200 NVL72 compared to the H100, driven by several key factors:
- Enhanced Memory Bandwidth and Computation Power: The GB200 NVL72 offers higher memory bandwidth and computation FLOPS compared to H100, accelerating kernel execution.Larger Memory Capacity to Allow Larger Batch Sizes: The increased memory capacity allows a larger KV cache, supporting larger batch sizes, thus resulting in improved kernel efficiency. Combined with the kernel speedup aforementioned, the system is still able to fulfill Inter-Token Latency (ITL) requirements similar to H100’s.Larger NVLink Domain: Unlike the reliance on RDMA for cross-node communication in the H100 cluster, the pure-NVLink solution in GB200 NVL72 significantly reduces communication latency. This allows two-batch overlap to be disabled, resulting in both kernel performance speedup and avoiding waste when overlapped communication is longer than computation.PD and Large-scale EP: Compared to a vanilla TP16 baseline, PD disaggregation enables flexible decoupling of the prefill and decode stages, optimizing resource utilization. Large-scale EP enhances MoE performance by reducing memory access pressure.
Ablation Study: Batch Size
To better understand the impact of batch size on the system, we conducted an ablation study by testing a range of batch sizes, though the system has not been optimized for small batch sizes. The input and output lengths are set to 2000 and 100, respectively. The results show that larger batch sizes boost throughput. Meanwhile, the GB200 NVL72 hardware demonstrates faster performance at the same batch size compared to the H100.
Future Work
Our preliminary results already demonstrate a 2.5-3.4x speedup, but there is still significant potential for further improvements:
- Other Hardware and Parallelism Configuration: Execution without large-scale EP, such as small batch sizes on a single node, which commonly happens on hardware like B200 and RTX 5090, has not been optimized yet, so the performance is expected to be highly suboptimal.Prefill Performance Enhancements: While our current focus has been on decode performance, the next phase will prioritize optimizing the prefill stage.Latency-oriented Optimizations: While we focus on throughput in this blog, minimizing latency is a future work direction.Kernel Optimizations: Many kernels have yet to fully saturate the GB200’s memory bandwidth or computational capabilities.Communication Overlap: Given the change in communication hardware in GB200 NVL72, communication can be overlapped with computation using techniques similar to or different from what is utilized in H100 to further reduce latency and improve throughput.Multi-Token Prediction (MTP): Predicting multiple tokens in one forward pass is beneficial, especially when the batch size is too small for kernels to achieve full performance.
Acknowledgement
We would like to express our heartfelt gratitude to the following teams and collaborators:
SGLang Core Team and Community Contributors — Jingyi Chen, Baizhou Zhang, Jiexin Liang, Qiaolin Yu, Yineng Zhang, Ke Bao, Liangsheng Yin and many others.
FlashInfer Team — Zihao Ye, Yong Wu, Yaxing Cai — for Blackwell FMHA kernel optimizations.
Mooncake Team — Shangming Cai, Feng Ren, Teng Ma, Mingxing Zhang, and colleagues — for their collaboration on PD disaggregation in SGLang.
NVIDIA Team — including members from Hardware (Juan Yu), DevTech (Yingcan Wei, Shifang Xu, Hui Wang, Kai Sun), DGX Cloud (Paul Abruzzo, Mathew Wicks, Lee Ditiangkin, Carl Nygard) and Enterprise Product (Pen Li, Trevor Morris, Elfie Guo, Kaixi Hou, Kushan Ahmadian, Pavani Majety) — for their contributions to Blackwell DeepGEMM and DeepEP, support with GB200 NVL72 operations and DeepSeek kernel optimizations.
Dynamo Team — Kyle Kranen, Vikram Sharma Mailthody, and colleagues - for extra support on PD disaggregation in SGLang.
