
可以输出语义的「分割一切模型2.0」来了!
一次交互,「分割+识别+解释+描述」全搞定,同时支持图像、视频和长视频,文本&Mask同时输出!
由港中文MMLab、港理工、北京大学等机构开源的PAM(Perceive Anything Model)模型,能够在保留SAM2分割一切、追踪一切能力的基础上,同时输出丰富的语义信息。

为了训练这样一个强大的模型,PAM团队还构建了一个超大规模高质量训练数据集:拥有150万个图像区域+60万个视频区域标注
实验结果表明,PAM仅使用3B参数,就在多个图像和视频理解基准上全面刷新或逼近SOTA,且具备更优的推理效率和显存占用,真正实现性能与轻量的统一。
所有数据均已完全开源。

PAM:准确定位一键输出
一些最新的Video LLM模型尝试结合VLM和SAM2的强大视觉提示能力,进行视频理解。然而:
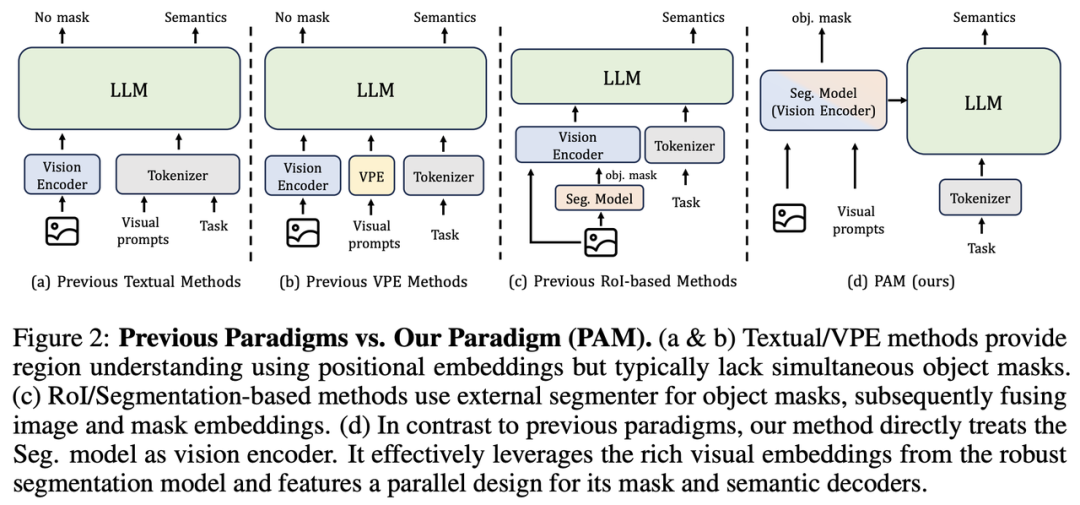
而PAM(Perceive Anything Model)既保留了SAM2在图像和视频中分割、追踪一切物体的能力,同时可以输出丰富的语义信息:
在图像任务中,PAM支持一次点击即可输出选中区域的:
在视频任务中,PAM同样支持区域理解:
只需要用户的一次点击,PAM就可以并行输出mask和文本,在许多应用场景下都具有潜力!
效果展示:图片/短视频/长视频

对于图片,用户通过点击或者拖拽矩形框选中一个物体,PAM可以完成分割的同时,输出该物体的类别+解释+描述的详细语义信息!
对于较短视频,用户选中特定物体后,PAM可以追踪并分割该物体,同时输出该物体的事件描述。
而对于长视频,PAM在追踪分割用户选中物体的同时,会根据事件的变化,动态地输出流式描述,类似实时字幕。
工作原理:模型框架+数据集
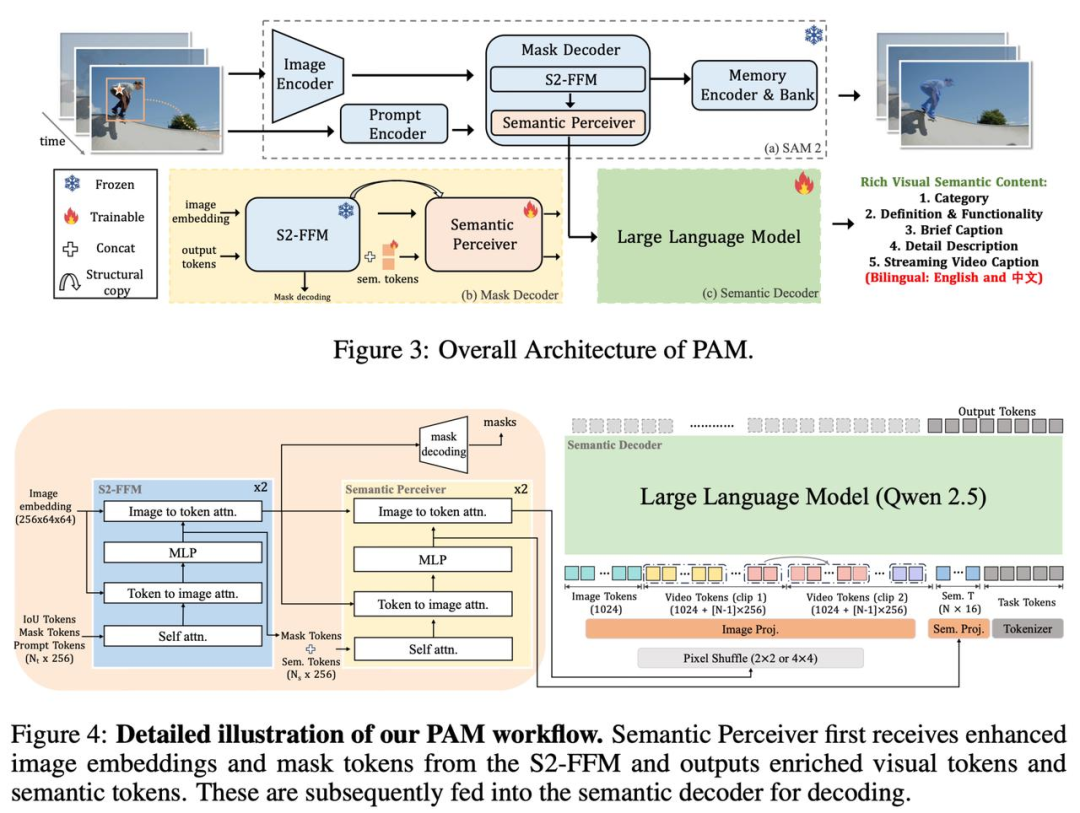
PAM引入了Semantic Perceiver来连接SAM2分割骨架和LLM,高效地将视觉特征“翻译”成多模态token。
通过SAM2分割骨架+Semantic Perceiver+LLM并行解码,在保证轻量高效的前提下,实现了分割mask和语义信息并行输出的图像/视频区域级理解。
基于此方法,PAM只使用了1.5B/3B参数的LLM head,就可以输出非常丰富和鲁棒的语义信息。
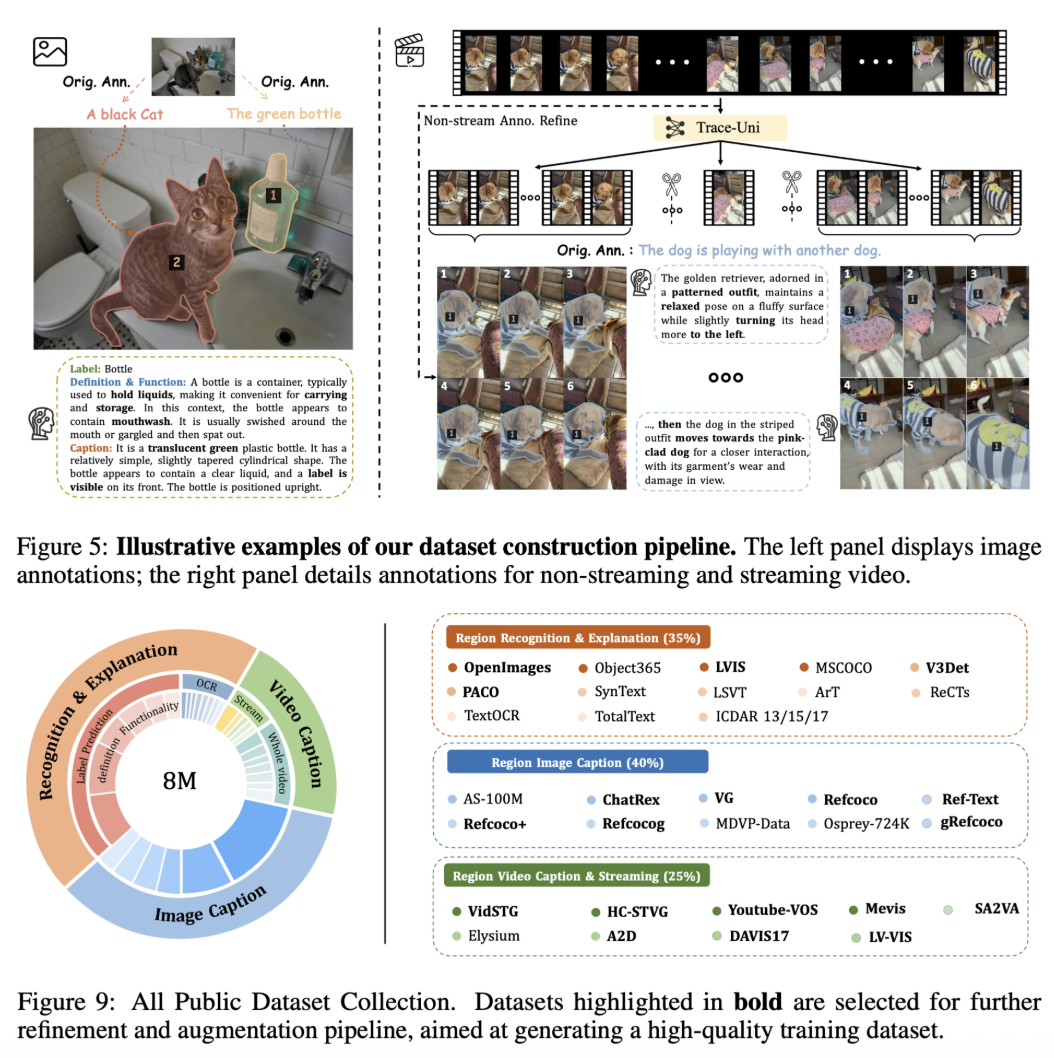
为支撑PAM的训练,构建了一个大规模、多层次、高密度的图像与视频语义标注数据集,覆盖分类、解释、描述、时序事件等多个维度:
图像数据:精细三连注释
使用SoM(Set of Masks)方法精准定位目标区域**,结合强大的闭源VLM(如GPT-4o)生成三类语义信息:
视频数据:Storyboard驱动式理解
流式视频数据:连贯事件字幕的首创实践
实验分析:规模更小、性能更好
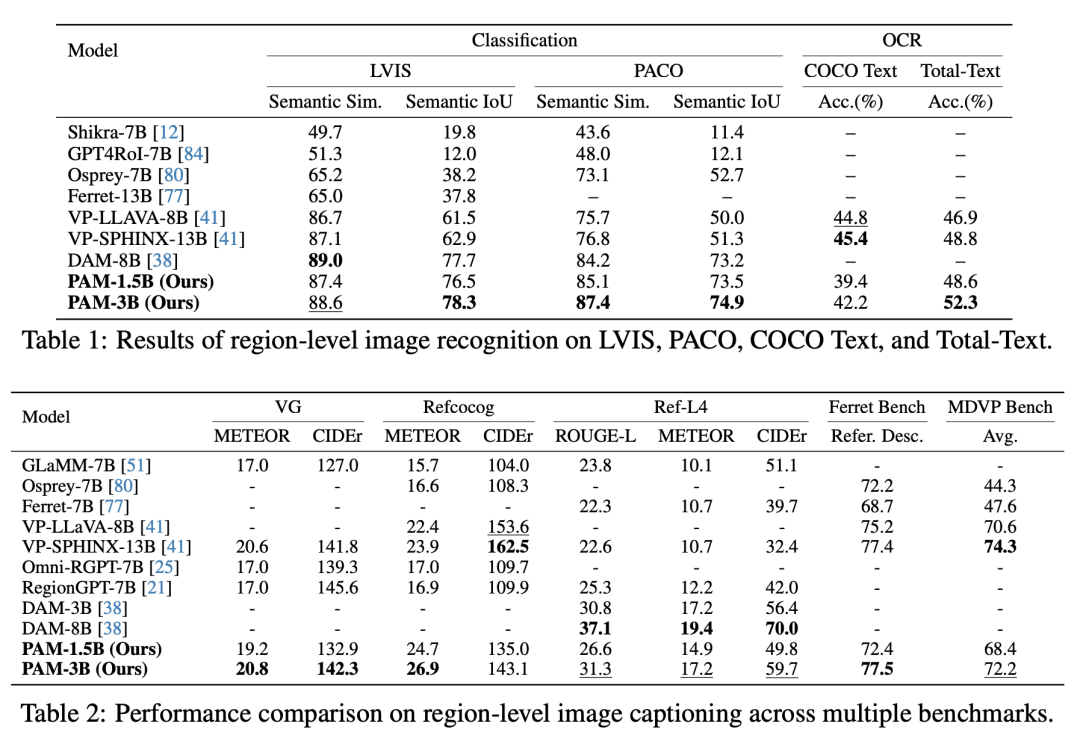
可以看到,PAM-3B在PACO基准测试中达到最佳性能,超过先前最佳模型3.2%以上,并在LVIS基准测试中,就语义IoU而言,超越了当前SOTA模型DAM-8B。
此外,PAM-3B在Total-Text上超过VP-SPHINX-13B超过3.5%,并在COCO-Text上达到相当的性能。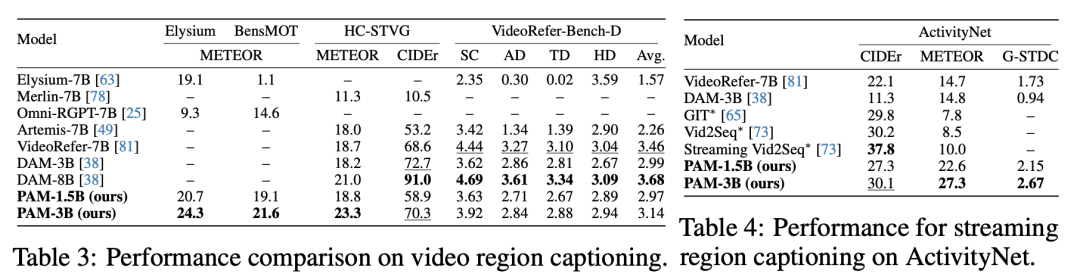
在ImageCaption、VideoCaption、视频时序事件理解等多个benchmark上,PAM都以更小的参数规模(3Bvs8B、13B)刷新或并列SOTA。
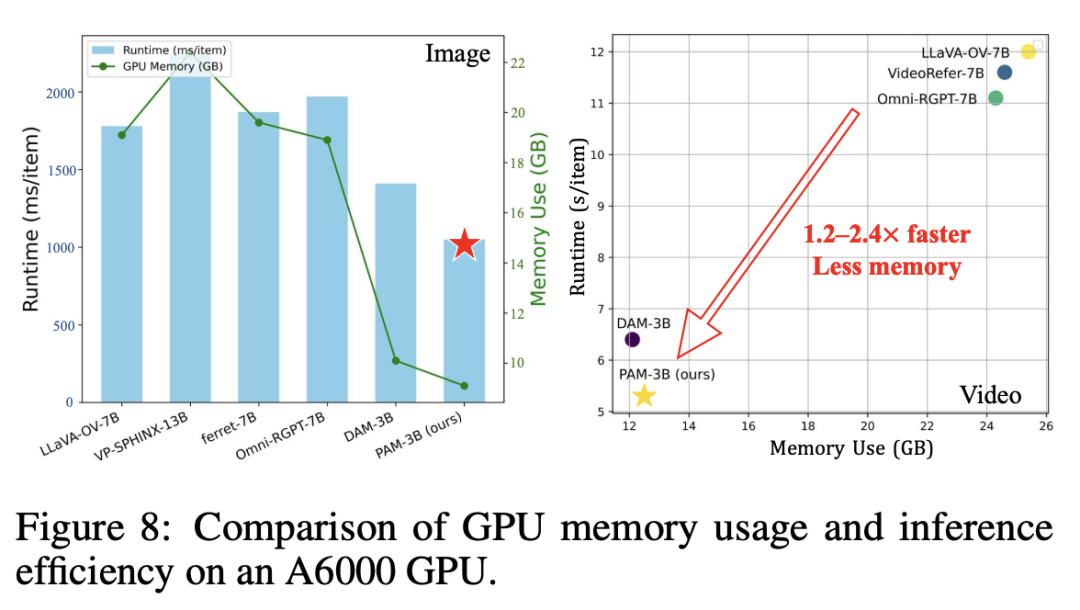
如图所示,和相同参数量的DAM-3B模型相比,PAM-3B推理更快,显存更省。
此外,PAM首创了区域级的流式视频字幕能力,不仅能持续描述一个物体的行为,还能在连续事件中保持高度语义一致性,展现了强大的实际应用潜力。
论文地址:https://arxiv.org/abs/2506.05302
项目主页:https://perceive-anything.github.io/
GitHub Repo:https://github.com/Perceive-Anything/PAM
Model CKPT:https://huggingface.co/Perceive-Anything/PAM-3B
Dataset:https://huggingface.co/datasets/Perceive-Anything/PAM-data
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
