
AMD大招逆袭,最强AI芯片号称大模型推理比英伟达B200快30%!
CEO苏姿丰与OpenAI奥特曼共同登台发布。
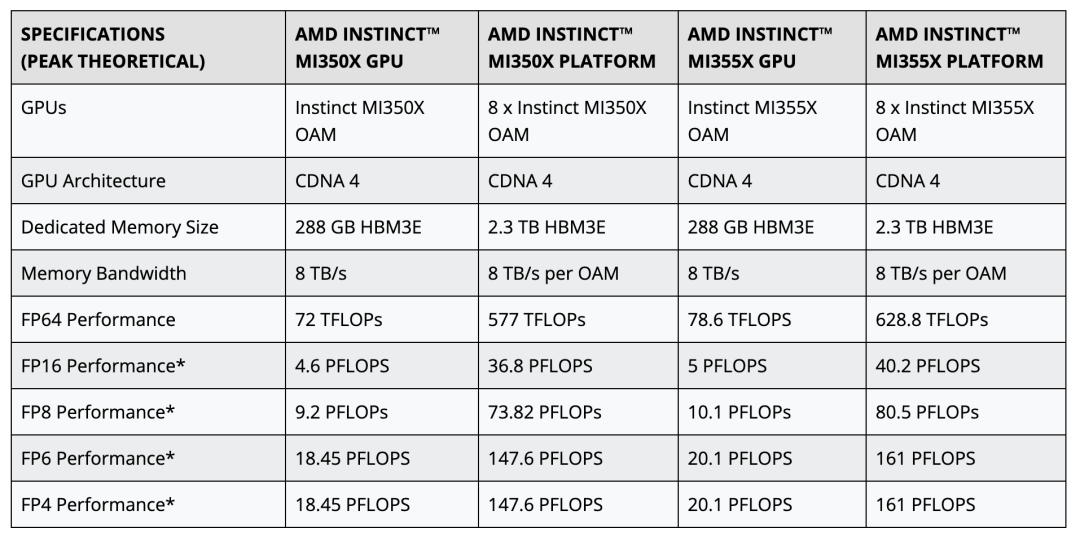
这次AMD发布了MI350X和MI355X两款GPU,采用3nm工艺,包含1850亿晶体管,配备HBM3E内存。
相比前代的MI300X,MI350系列的算力提升了4倍,推理速度快了35倍。

MI350系列也是叫板英伟达B200,内存是B200的1.6倍,训练推理速度相当或更快。
并且由于芯片功耗低于英伟达,在MI355X上每花费1美元,可以比B200多跑40%的tokens。

同时,AMD还预告明年将会发MI400系列,并且奥特曼也来给苏妈站台,透露OpenAI参与了MI400系列的联合研发。

大模型运行更快,MI350系列叫板英伟达
MI350X和MI355X在核心设计上是相同的,二者的区别是针对不同的散热方式设计,前者采用风冷,后者则和B200一样采用了更先进的液冷。
它们都基于第四代Instinct架构(CDNA 4),并配备288GB的HBM3E内存和8TB每秒的内存带宽,这一容量是英伟达GB200和B200 GPU的1.6倍。
功耗上,风冷的MI350X最高TBP为1000W,液冷的MI355X则达到了1400W,更高的TBP之下,MI355X的性能也高于同架构的MI350X。

在精度较高的FP64上,MI350X和MI355X的算力分别是72和78.6TFLOPs,据介绍是英伟达的2倍。
而在低精度格式(例如FP16、FP8和FP4)上,MI350系列的性能则与英伟达相当或略胜一筹。
值得注意的是,MI350系列上,FP6性能的运算可以以FP4的速率运行,这被AMD认为是一个差异化特征。
搭配AMD第五代EPYC(Turin)芯片,8个GPU通过153.6 GB/s的双向Infinity Fabric链路进行通信,可以组成一个节点。

这些节点还将继续组合成风冷或液冷机柜,形成最高128GPU的集群,FP8算力达到1.3EFLOPs。

除了列性能数据,AMD还直观地介绍了MI350系列运行大模型应用的性能,并分别与自家前代产品和英伟达进行了对比。
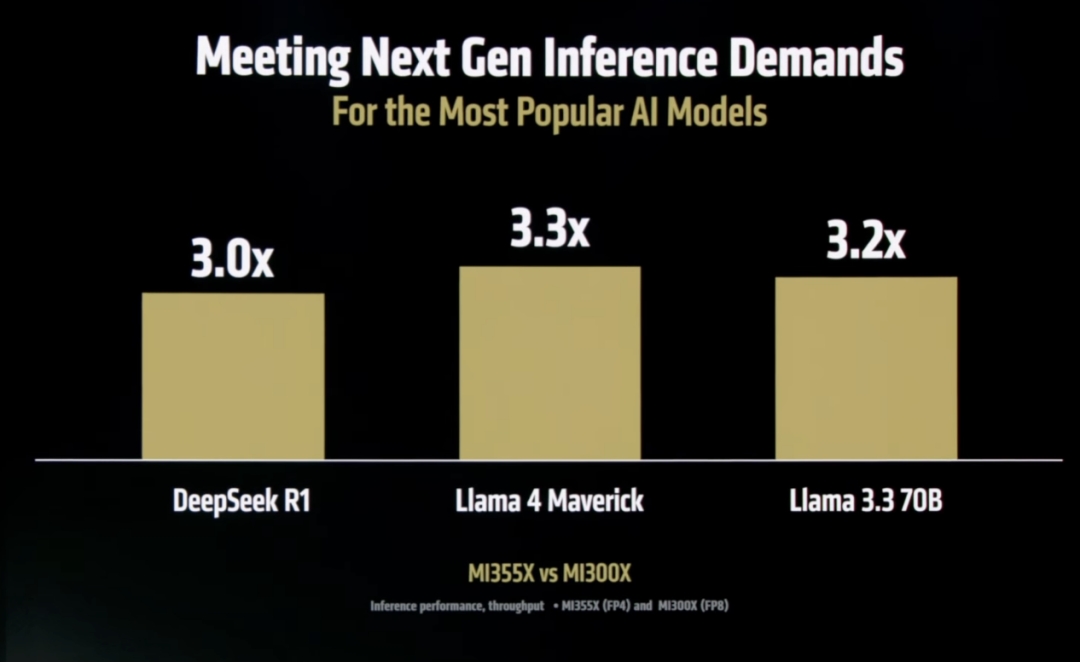
相比于MI300X(FP8),MI355X(FP4)运行Llama 3.1 405B的速度达到了35倍。

运行DeepSeek R1、Llama 4 Maverick和Llama 3.3 70B的推理性能也均达到了3倍。
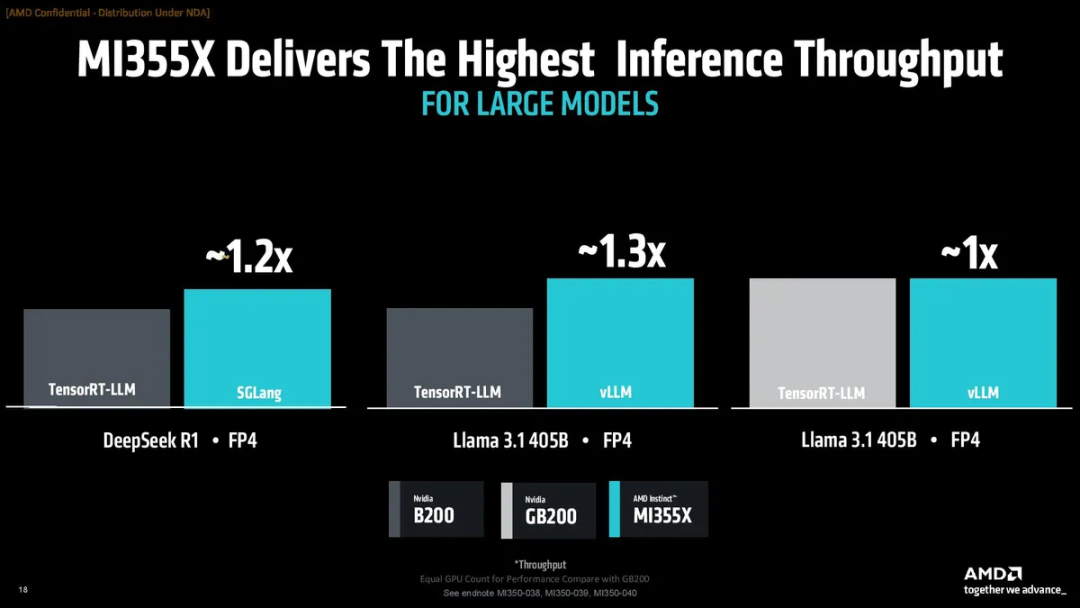
和英伟达的B200或GB200相比,MI355X也能达到相当或更高的性能(均为FP4精度,使用不同框架),DeepSeek R1和Llama 3.1 405B的性能分别比B200高20%和30%。
训练和微调上,也是相比MI300X大幅提升,并拥有和B200/GB200相当或更高的性能。
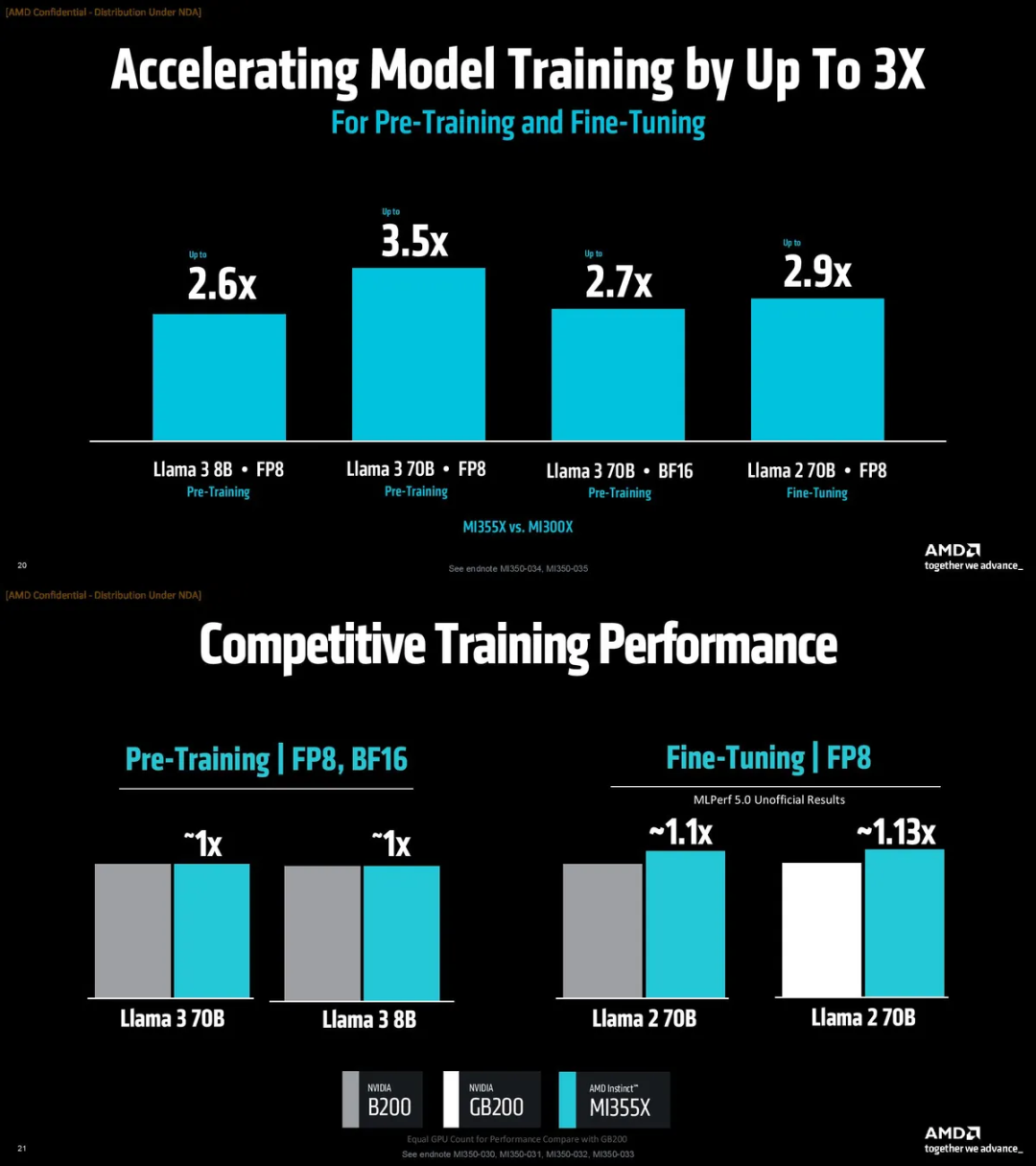
成本方面,MI350系列也拥有较高的性能密度,同样花费1美元,在MI355X上可以比B200上多处理40%的token。

AMD表示,MI350系列在本月初已经批量出货,云服务商正在进行安装。
微软、Meta、xAI等正在使用AMD产品的AI大厂,也均对MI350表示了期待。
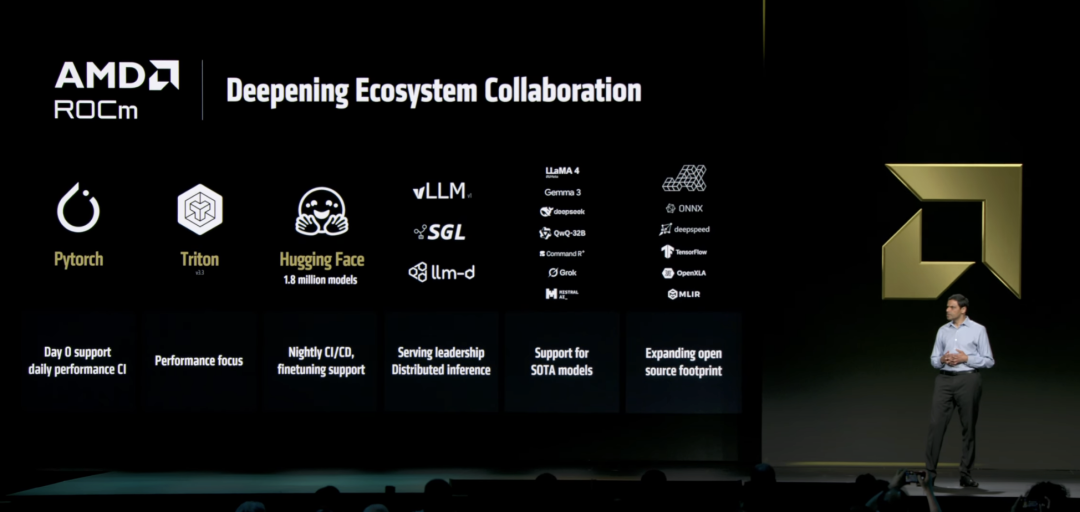
另外,为了搭配MI350系列,AMD还发布了全新的ROCm 7软件栈,相比ROCm 6带来了3.5倍的推理性能提升和3倍的训练性能提升,同时引入了分布式推理支持。
ROCm 7还与VLM和SGLang等开源推理框架深度集成,并且支持超过180万个Hugging Face模型的开箱即用。
AMD公布路线图,MI400明年亮相
发布MI350系列的同时,苏妈也公布了AMD在AI芯片上新的路线图。
根据这张路线图,AMD的下一代GPU,也就是MI400系列,将于明年亮相。

MI400系列由AMD和OpenAI联合研发,OpenAI为MI400系列的训练和推理需求提供了重要反馈。
奥特曼也来到现场为AMD站台,表示MI400非常适合推理,并且也可能是训练的绝佳选择。

MI400系列将采用下一代CDNA架构,预计速度比MI300系列快10倍,FP4运行速度将达到40PFLOPs。
还将配备高达432GB的HBM4内存和19.6TB/s的内存带宽,这个数字让现场的奥特曼也为之一震。

搭配2nm的Venice CPU和Vulcano网卡,MI400可以组装成完整的Helios AI机架。
Venice拥有多达256个Zen6高性能核心,计算性能预计比当前的Turin CPU提升70%。

代号为“Vulcano”的下一代扩展AI网卡,支持PCIe和UAL接口,并提供800GB/s的线速吞吐量。

整体上,Helios机架将连接多达72个GPU,拥有260TB/s的扩展带宽。

另外,AMD还计划到2027年推出MI500系列GPU和Verono CPU,将“进一步突破性能、效率和可扩展性的极限”。

那么你认为,AMD这次Yes了吗?
发布会回放:
https://www.youtube.com/watch?v=5dmFa9iXPWI
参考链接:
[1]https://www.tomshardware.com/pc-components/gpus/amd-announces-mi350x-and-mi355x-ai-gpus-claims-up-to-4x-generational-gain-up-to-35x-faster-inference-performance
[2]https://www.amd.com/en/blogs/2025/amd-instinct-mi350-series-and-beyond-accelerating-the-future-of-ai-and-hpc.html
— 完 —
📪 量子位AI主题策划正在征集中!欢迎参与专题365行AI落地方案,一千零一个AI应用,或与我们分享你在寻找的AI产品,或发现的AI新动向。
💬 也欢迎你加入量子位每日AI交流群,一起来畅聊AI吧~

一键关注 👇 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
内容中包含的图片若涉及版权问题,请及时与我们联系删除
