
Published on June 13, 2025 8:55 AM GMT
We’re finally ready to see why unawareness so deeply undermines action guidance from impartial altruism. Let’s recollect the story thus far:
- First: Under unawareness, “just take the expected value” is unmotivated.Second: Likewise, “do what seems intuitively good and high-leverage, then you’ll at least do better than chance” doesn’t work. There’s too much room for imprecision, given our extremely weak evidence about the mechanisms that dominate our impact, and our track record of finding sign-flipping considerations.Third: Hence, we turned to UEV, an imprecise model of strategies’ impact under unawareness. But there are two major reasons comparisons between strategies’ UEV will be indeterminate: the severe lack of constraints on how we should model the space of possibilities we’re unaware of, and imprecision due to coarseness.
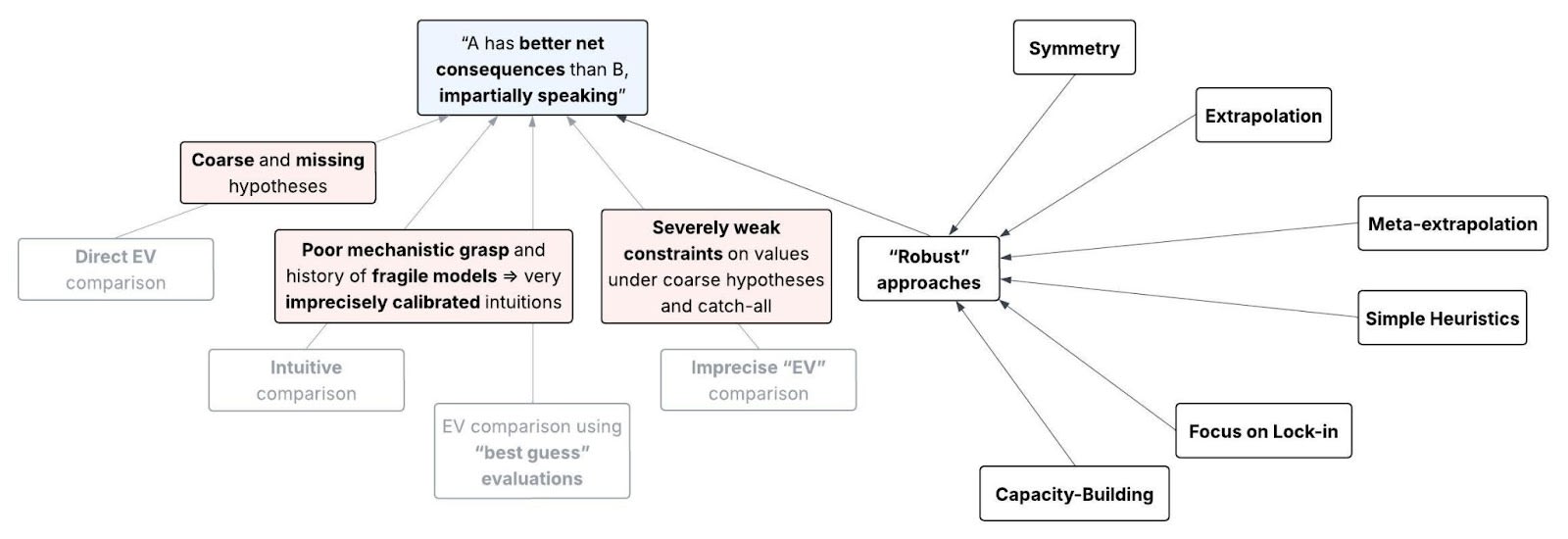
The EA community has proposed several approaches to “robust” cause prioritization, which we might think avoid these problems. These approaches don’t explicitly use the concept of UEV, and not all the thinkers who proposed them necessarily intended them to be responses to unawareness. But we can reframe them as such. I’ll outline these approaches below, and show why each of them is insufficient to justify comparisons of strategies’ UEV. Where applicable, I’ll also explain why wager arguments don’t support following these approaches. Afterwards, I’ll share some parting thoughts on where to go from here.
Why each of the standard approaches is inadequate
(See Appendix D for more formal statements of these approaches. I defer my response to cluster thinking to Appendix E, since that’s more of a meta-level perspective on prioritization than a direct response to unawareness. In this list, the “contribution” of a hypothesis to the UEV for some strategy equals {value under } x {probability of given that strategy}. Recall that our awareness set is the set of hypotheses we’re aware of.)
Table 3. Outline of the standard approaches to strategy comparisons under unawareness.
| Approach | Reasoning | Sources |
| Symmetry: The contribution of the catch-all to the UEV is equal for all strategies. | Since we have no idea about the implications of possibilities we haven’t considered, we have no reason to think they’d push in one direction vs. the other, in expectation. Then by symmetry, they cancel out. | St. Jules and Soares.[1] Cf. Greaves’s (2016) discussion of “simple cluelessness”, and the principle of indifference. |
| Extrapolation: There’s a positive correlation between (i) the difference between strategies’ UEV and (ii) the difference between the contributions of the awareness set to their UEV. | Even if our sample of hypotheses we’re aware of is biased, the biases we know of don’t suggest the difference in UEV should have the opposite sign to the difference in EV on the awareness set. And we have no reason to think the unknown biases push in one direction vs. the other, in expectation. | Cotton-Barratt, and Tomasik on “Modeling unknown unknowns”. |
| Meta-extrapolation: Take some reference class of past decision problems where a given strategy was used. The strategy’s UEV is proportional to its empirical average EV over the problems in this reference class. | If there were cases in the past where (i) certain actors were unaware of key considerations that we’re aware of, but (ii) they nonetheless took actions that look good by our current lights, then emulating these actors will be more robust to unawareness. | Tomasik on “An effective altruist in 1800”, and Beckstead on “Broad approaches and past challenges”. |
| Simple Heuristics: The simpler the arguments that motivate a strategy, the more strongly the strategy’s UEV correlates with the EV we would have estimated had we not explicitly adjusted for unawareness. | More conjunctive arguments have more points of possible failure and hence are less likely to be true, especially under deep uncertainty about the future. Then strategies supported by simple arguments or rules will tend to do better. | Christiano. This approach is sometimes instead motivated by Meta-extrapolation, or by avoiding overfitting (Thorstad and Mogensen 2020).
|
| Focus on Lock-in: The more a strategy aims to prevent a near-term lock-in event, the more strongly the strategy’s UEV correlates with the EV we would have estimated had we not explicitly adjusted for unawareness. | Our impacts on near-term lock-in events (e.g., AI x-risk and value lock-in) are easy to forecast without radical surprises. And it’s easy to assess the sign of large-scale persistent changes to the trajectory of the future. | Tarsney (2023), Greaves and MacAskill (2021, Sec. 4), and Karnofsky on “Steering”. |
| Capacity-Building: The more a strategy aims to increase the influence of future agents with our values, the higher its UEV. | Our more empowered (i.e., smarter, wiser, richer) successors will have a larger awareness set. So we should defer to them, by favoring strategies that increase the share of future empowered agents aligned with our values. This includes gaining resources, trying to increase civilizational wisdom, and doing research. | Christiano, Greaves and MacAskill (2021, Sec. 4.4), Tomasik on “Punting to the future”, and Bostrom on “Some partial remedies”. |
 |
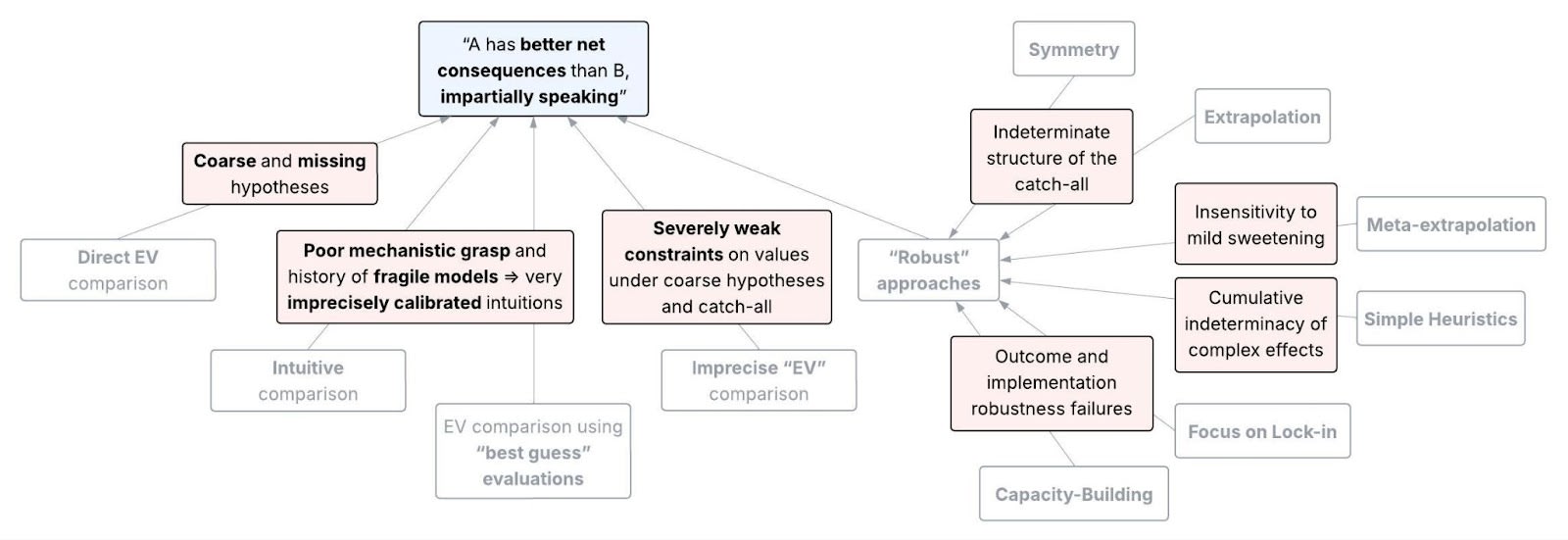
Symmetry
Key takeaway
We can’t assume the considerations we’re unaware of “cancel out”, because when we discover a new consideration, this assumption no longer holds.
According to this approach, we should think the catch-all affects all strategies’ UEV equally. After all, it appears we have no information either way about the strategies’ likelihood of leading to outcomes in the catch-all.
Response
Upon closer inspection, we do have infomation about the catch-all, as we saw when we tried to model it. When we update our model of the catch-all on the discovery of a new hypothesis, the symmetry breaks. Specifically:
- Assume Symmetry is true, to start. In the case of digital minds advocacy, for example, let’s say you assign equal contributions of the catch-all to the values of strategies Advocate and Don’t Advocate.Let be the catch-all after you discover a new hypothesis that’s pessimistic about digital minds advocacy.Presumably the arguments for being more optimistic than given this discovery aren’t exactly as strong as the arguments for more pessimism. So the contributions of to the values of Advocate and Don’t Advocate are no longer equal.And, as we’ve seen, it’s very unclear how to pin down the likelihood of discovering this new hypothesis. Thus we should have highly imprecise estimates of the UEV difference between the two strategies.
A common intuition is, “If it really is so unclear how to weigh up these updates about the catch-all, don’t the optimistic and pessimistic updates cancel out in expectation?” But our actual epistemic state is that we have reasons pointing in both directions, which don’t seem precisely balanced. If we treated these reasons as balanced anyway, when we could instead suspend judgment, we’d introduce artificial precision for no particular reason.[2]
(How about an intuition like, “If I can’t tell whether the considerations I’m unaware of would favor or , these considerations are irrelevant to my decision-making”? I’ll respond to this below.)
Extrapolation
Key takeaway
We can’t trust that the hypotheses we’re aware of are a representative sample. Although we don’t know the net direction of our biases, this doesn’t justify the very strong assumption that we’re precisely unbiased in expectation.
Although the post-AGI future seems to involve many unfamiliar mechanisms, perhaps we can still get some (however modest) information about an intervention’s net impact based on our awareness set. And if these considerations are a representative sample of the whole set of considerations, it would make sense to extrapolate from the awareness set. (Analogously, when evaluating coarse hypotheses, we could extrapolate from a representative sample of fine-grained scenarios we bring to mind.)
Response
Our analysis of biased sampling showed that our awareness set is likely highly non-representative, so straightforward extrapolation is unjustified. What about the “Reasoning” for Extrapolation listed in Table 3? The claim seems to be that we should regard our net bias as zero ex ante, after adjusting for any (small) biases we know how to adjust for. But here we have the same problem as with Symmetry. If it’s unclear how to weigh up arguments for our biases being optimistic vs. pessimistic, then treating them as canceling out is ad hoc. The direction of our net bias is, rather, indeterminate.
Meta-extrapolation
Key takeaway
We can’t trust that a strategy’s past success under smaller-scale unawareness is representative of how well it would promote the impartial good. The mechanisms that made a strategy work historically could actively mislead us when predicting its success on a radically unfamiliar scale.
The problem with Extrapolation was that strategies that work on the awareness set might not generalize to the catch-all. We can’t directly test how well strategies’ far-future performance generalizes, of course. But what if we use strategies that have successfully generalized under unawareness with respect to more local goals? We could look at historical (or simulated?) cases where people were unaware of considerations highly relevant to their goals (that we’re aware of), and see which strategies did best. From Tomasik:
[I]magine an effective altruist in the year 1800 trying to optimize his positive impact. … What [he] might have guessed correctly would have been the importance of world peace, philosophical reflection, positive-sum social institutions, and wisdom. Promoting those in 1800 may have been close to the best thing this person could have done, and this suggests that these may remain among the best options for us today.
The underlying model here is: We have two domains, (i) a distribution of decision problems from the past and (ii) the problem of impartially improving overall welfare. If the mechanisms governing successful problem-solving under unawareness are relevantly similar between (i) and (ii), then strategies’ relative performance on (i) is evidence about their relative performance on (ii).
Response
I agree that we get some evidence from past performance, as per this model. But that evidence seems quite weak, given the potentially large dissimilarities between the mechanisms determining local vs. cosmic-scale performance. (See footnote for comments on a secondary problem.[3])
Concretely, take Tomasik’s example. We can mechanistically explain why a 19th century EA would’ve improved the next two centuries on Earth by promoting peace and reflection (caveats in footnote[4]). On such a relatively small scale, there’s not much room for the sign of one’s impact to depend on factors as exotic as, say, the trajectory of space colonization by superintelligences or the nature of acausal trade. Obviously, the next two centuries went in some surprising directions. But the dominant mechanisms affecting net human welfare were still socioeconomic forces interacting with human biology (recall my rebuttal of the “superforecasting track records” argument). So on this scale, the consistent benefits of promoting peace and reflection aren’t that surprising. By contrast, we’ve surveyed various reasons why the dominant mechanisms affecting net welfare for all sentient beings might differ from those affecting local welfare.
We might think the above is beside the point, and reason as follows:
Weak evidence is still more informative than no evidence. As long as past success generalizes to some degree to promoting the impartial good, we can wager on Meta-extrapolation. If we’re wrong, every strategy is (close to) equally effective ex ante anyway.
Like we saw in the imprecision FAQ, however, this wager fails because of “insensitivity to mild sweetening”: When we compare strategies’ UEV, we need to weigh the evidence from past performance against other sources of evidence — namely, object-level considerations about strategies’ impact on certain variables (e.g., how they affect lock-in events). And, as shown in the third post, our estimates of such impacts should be highly imprecise. So the weak evidence from past performance, added on top of other evidence we have no idea how to weigh up, isn’t a tiebreaker.[5]
Simple Heuristics
Key takeaway
The argument that heuristics are robust assumes we can neglect complex effects (i.e., effects beyond the “first order”), either in expectation or absolutely. But under unawareness, we have no reason to think these effects cancel out, and should expect them to matter a lot collectively.
We’ve just seen why heuristics aren’t justified by their past success. Nor are they justified by rejecting detailed world models,[6] nor by the reliability of our intuitions.
The most compelling motivation for this approach, instead, goes like this (Christiano;[7] see his post for examples): Informally, let’s say an effect of a strategy is some event that contributes to the total value of the world resulting from that strategy. E.g., speeding up technological growth might have effects like “humans in the next few years are happier due to greater wealth” and “farmed animals in the next few years suffer more due to more meat consumption”. The effects predicted by arguments with fewer logical steps are more likely. Whereas complex effects are less likely or cancel out. So strategies supported by simple reasoning will have higher UEV.
Response
I’d agree that if we want to say how widely a given effect holds across worlds we’re unaware of, logical simplicity is an unusually robust measure. But this doesn’t mean the overall contribution of complex effects to the UEV is small in expectation. More precisely, here’s my understanding of how the argument above works:
- We can decompose the UEV of a strategy into a sum of all possible effects of , weighted by our credence in each effect.All else equal, our credence in each effect should decrease with the number of logical steps in the argument that justifies the existence of the effect (which we call an -step effect). In particular, our credence should decrease with sufficiently quickly that the UEV is dominated by 1-step effects. This is because the more logical steps there are in the argument, the more opportunities there are for our reasoning to be flawed.And we should expect to be aware of most of the 1-step effects, after a modest amount of thinking/research. Thus, we can estimate the UEV to a high level of precision.
The counterargument: In order to say that the UEV is dominated by 1-step effects, we need either (for ):
- a reason to think the -step effects average out to some small range of values, ora sufficiently low upper bound on our total credence in all -step effects.
But all the reasons for severe imprecision due to unawareness that we’ve seen, and the counterargument to symmetric “canceling out”, undermine (1). And we’ve also seen reasons to consider our unawareness vast, suggesting that the -step effects we’re unaware of are collectively significant. This undermines (2).
Focus on Lock-in
Key takeaway
Even if we focus on near-term lock-in, we can’t control our impact on these lock-in events precisely enough, nor can we tease apart their relative value when we only picture them coarsely.
This approach is a more general version of the logic critiqued in our case study: The long-term trajectory (or existence) of Earth-originating civilization could soon be locked into an “attractor state”, such as extinction or permanent human disempowerment. Plausibly, then, we could have a large-scale, persistent, and easy-to-evaluate impact by targeting these attractor states. And these states seem foreseeable enough to reliably intervene on. So, trying to push toward better attractor states appears to score well on both outcome robustness and implementation robustness. (Which is why I think Focus on Lock-in is one of the strongest approaches to UEV comparisons, in theory.)
Response
Unfortunately, as illustrated by the case study, we seem to have severe unawareness at the level of both the relative value, and likelihood given our strategy, of different attractor states. To recap, if our candidate intervention is “try to stop AIs from permanently disempowering humans”:
- Problems for outcome robustness: We’re only very coarsely aware of attractors like “Earth-originating space colonization (‘SC’) by benevolent humans”, “SC by human-disempowering AI”, etc. So, their relative value (from an impartial perspective) seems indeterminate. Considerations like acausal trade, the possibility of other civilizations in our lightcone, various possible path-dependencies in SC, and pessimistic induction worsen this problem.Problems for implementation robustness: Even if the lock-in events of interest occur quite soon, they’re still fairly unprecedented and riddled with complexity that warrants imprecise estimates. We have no experience with shaping the values of superintelligent agents. And we need to account for our off-target effects on lock-in events other than the one we aim to intervene on. (This is a problem even if we can precisely weigh up our effects on the likelihood of different lock-in events! See Appendix F for a toy example.)
Put differently: There’s a significant gap between “our ‘best guess’ is that reaching a given coarse-grained attractor would be positive” and “our concrete attempts to steer toward rather than away from this attractor will likely succeed and ‘fail gracefully’ (i.e., not land us in a worse-than-default attractor), and our guess at the sign of the intended attractor is robust”. When we account for this gap, we can’t reliably weigh up the effects that dominate the UEV.
This discussion also implies that, once again, we can’t “wager” on Focus on Lock-in. The problem is not that the future seems too chaotic for us to have any systematic impact. Instead, we’re too unaware to say whether, on net, we’re avoiding locking in something worse.
Capacity-Building
Key takeaway
This approach doesn’t help for reasons analogous to those of Focus on Lock-In.
Even if the direct interventions currently available to us aren’t robust, what about trying to put our successors in a better position to positively intervene? There seem to be two rough clusters of Capacity-Building (CB) strategies:
- High-footprint: Community/movement building; broad values advocacy; gaining significant influence on AGI development, deployment, or governance; aiming to improve civilizational “wisdom” (see, e.g., the conclusion of Carlsmith (2022)).
- Argument: You should expect the value of the future to correlate with the share of future powerful agents who have your goals. This is based on both historical evidence and compelling intuitions, which don’t seem sensitive to the details of how the future plays out.
- Argument: If your future self has more resources/information, they’ll presumably take actions with higher UEV than whatever you can currently do. Thus, if you can gain more resources/information, holding fixed how much you change other variables, your strategy will have higher UEV than otherwise.
Response
High-footprint. Once more, historical evidence doesn’t seem sufficient to resolve severe imprecision. Perhaps the mechanism “gaining power for our values increases the amount of optimization for our values” works at a very general level, so the disanalogies between the past and future aren’t that relevant? But the problems with Focus on Lock-in recur here, especially for implementation robustness: How much “power” “our values” stably retain into the far future is a very coarse variable (more details in footnote[8]). So, to increase this variable, we must intervene in the right directions on a complex network of mechanisms, some of which lie too far in the future to forecast reliably. Our overall impact on how empowered our values will be, therefore, ends up indeterminate when we account for systematic downsides (e.g., attention hazards, as in the case of AI x-risk movement building). Not to mention off-target effects on lock-in events. For example, even if pushing for the U.S. to win the AI race does empower liberal democratic values, this could be outweighed by increased misalignment risk.[9]
We might have the strong intuition that trying to increase some simple variable tends to increase that variable, not decrease it. Yet we’ve seen compelling reasons to distrust intuitions about our large-scale impact, even when these intuitions are justified in more familiar, local-scale problems.
Low-footprint. I’d agree that low-footprint CB could make our successors discover, or more effectively implement, interventions that are net-positive from their epistemic vantage point. That’s a not-vanishingly-unlikely upside of this strategy. But what matters is whether low-footprint CB is net-positive from our vantage point. How does this upside compare to the downsides from possibly hindering interventions that are positive ex post? (It’s not necessary for such interventions to be positive ex ante, in order for this to be a downside risk, since we’re evaluating CB from our perspective; see Appendix C.) Or other off-target large-scale effects we’re only coarsely aware of (including, again, our effects on lock-in)?
Real-world implementations of “saving money” and “doing research” may have downsides like:
- Suppose that instead of spending money on yourself, you put it in escrow for future promising altruistic opportunities. Perhaps others follow your example and save more, when they would’ve otherwise spent money on a time-sensitive intervention that might have been highly (yet non-robustly) positive.Or suppose that instead of spending some of your free time reflecting on virtue ethics, you reflect on whether some intervention could be robust to unawareness. Maybe this shapes the salience of different strategies to your future self, and you end up attempting an intervention that’s worse than what you would’ve done by default.
Intuitively, these side effects may seem like hand-wringing nitpicks. But I think this intuition comes from mistakenly privileging intended consequences, and thinking of our future selves as perfectly coherent extensions of our current selves. We’re trying to weigh up speculative upsides and downsides to a degree of precision beyond our reach. In the face of this much epistemic fog, unintended effects could quite easily toggle the large-scale levers on the future in either direction.
 |
Another option: Rejecting (U)EV?
Key takeaway
Suppose that when we choose between strategies, we only consider the effects we can weigh up under unawareness, because (we think) the other effects aren’t decision-relevant. Then, it seems arbitrary how we group together “effects we can weigh up”.
No matter how we slice it, we seem unable to show that the UEV of dominates that of , for any given and . Is there any other impartial justification we could offer for our choice of strategy?
The arguments in this sequence seem to apply just as well to any alternative to EV that still explicitly aggregates over possible worlds, such as EV with risk aversion or discounting tiny probabilities. This is because the core problem isn’t tiny probabilities of downsides, but the severe imprecision of our evaluations of outcomes.
Here’s another approach. Clifton notes that, even if we want to make choices based purely on the impartial good, perhaps we get action guidance from the following reasoning, which he calls Option 3 (paraphrasing):
I suspend judgment on whether results in higher expected total welfare than . But on one hand, is better than with respect to some subset of their overall effects (e.g., donating to AMF saves lives in the near term), which gives me a reason in favor of . On the other hand, I have no clue how to compare to with respect to all the other effects (e.g., donating to AMF might increase or decrease x-risk; Mogensen 2020), which therefore don’t give me any reasons in favor of . So, overall, I have a reason to choose but no reason to choose , so I should choose .[10]
In our setting, “all the other effects” might be the effects we’re only very coarsely aware of (including those in the catch-all).
I have some sympathy for Option 3 as far as it goes. Notably, insofar as Option 3 is action-guiding, it seems to support a focus on near-term welfare, which would already suggest significant changes to current EA prioritization. I’m keen for others to carefully analyze Option 3 as a fully-fledged decision theory, but for now, here are my current doubts about it:
- There are many different ways of carving up the set of “effects” according to the reasoning above, which favor different strategies. For example: I might say that I’m confident that an AMF donation saves lives, and I’m clueless about its long-term effects overall. Yet I could just as well say I’m confident that there’s some nontrivially likely possible world containing an astronomical number of happy lives, which the donation makes less likely via potentially increasing x-risk, and I’m clueless about all the other effects overall. So, at least without an argument that some decomposition of the effects is normatively privileged over others, Option 3 won’t give us much action guidance.Setting the above aside, suppose Option 3 uniquely recommends . Should I interpret this as, “I ‘expect’ to have systematically better effects than , impartially speaking”? In particular, should I consider the impartial altruistic argument for choosing over to be as strong as if “all the other effects” canceled out in expectation? Arguably not. I still care about those other effects, whether or not I can determine which strategy they recommend. I think that, properly disentangled, these effects give me some reasons in favor of , some in favor of , and it’s indeterminate how to weigh these reasons up. So I’m not sure I see the moral urgency of the Option 3 argument.
This matters because, as I’ve argued previously, even if the impartial good gives no reasons for choice, we can choose based on other normative criteria. And these criteria might be more compelling than Option 3.[11]
That said, I’m not highly confident in this answer, and I think this is a subtle (meta-)normative question.Conclusion and taking stock of implications
Stepping back, here’s my assessment of our situation:
- Insofar as we’re trying to be “effective altruists”, the reason we’d choose to work on some cause is: We think this cause will have better consequences ex ante than the alternatives, accounting for all the hypotheses that bear significantly on our impact on all moral patients.
- This is a wildly far-reaching objective! So it’s no surprise if strategies that succeed on everyday scales are unjustified here.
- Even if I’m wrong about what exactly constitutes “making up guesses”, this broader point seems very neglected in EA cause prioritization. If a robust-to-unawareness EA portfolio exists, I doubt it would look similar to the status quo.
So, I’m not aware of any plausible argument that one strategy has better net consequences under unawareness than another. Of course, I’d be excited to see such an argument! Indeed, one practical upshot of this sequence is that the EA project needs more rethinking of its epistemic and decision-theoretic foundations. That said, I think the challenge to impartial altruist action guidance runs very deep.
We might be tempted to say, “If accounting for unawareness implies that no strategy is better than another, we might as well wager on whatever looks best when we ignore unawareness.” This misses the point.
First, as we’ve seen in this post, wager arguments don’t work when the hypotheses you set aside say your expected impact is indeterminate, rather than zero.
Second, my claim is that no strategy is better than another with respect to the impartial good, according to our current understanding of epistemics and decision theory. Even if we suspend judgment on how good or bad our actions are impartially speaking, again, we can turn to other kinds of normative standards to guide our decisions. I hope to say more on this in future writings.
Finally, whatever reason we may have to pursue the strategy that looks best ignoring unawareness, it’s not the same kind of reason that effective altruists are looking for. Ask yourself: Does “this strategy seems good when I assume away my epistemic limitations” have the deep moral urgency that drew you to EA in the first place?
“But what should we do, then?” Well, we still have reason to respect other values we hold dear — those that were never grounded purely in the impartial good in the first place. Integrity, care for those we love, and generally not being a jerk, for starters. Beyond that, my honest answer is: I don’t know. I want a clear alternative path forward as much as the next impact-driven person. And yet, I think this question, too, misses the point. What matters is that, if I’m right, we don’t have reason to favor our default path, and the first step is owning up to that. To riff on Karnofsky’s “call to vigilance”, I propose a call to reflection.
This is a sobering conclusion, but I don’t see any other epistemically plausible way to take the impartial good seriously. I’d love to be wrong.
Appendix D: Formal statements of standard approaches to UEV comparisons
Recalling the notation from Appendix B, here’s some shorthand:
- .The value of strategy under with respect to some in is
Then:
- Symmetry: For any pair of strategies , we have for all in .Extrapolation: For any pair of strategies , we have for all in .Meta-extrapolation: Consider some reference class of past problems where the decision-maker had significant unawareness, relative to a “local” value function . Let be two categories of strategies used in these problems, and be the average local value achieved by strategies in . Then if is relatively similar to and is relatively similar to , we have for all in .Simple Heuristics: Let be some measure of the complexity of the arguments that motivate . Then for any strategy , we have that correlates more strongly with the EV we would have estimated had we not explicitly adjusted for unawareness, the lower is (for all in ).Focus on Lock-in: Let be the amount of time between implementation of and the intended impact on some target variable, and be the amount of time the impact on the target variable persists. Then for any strategy , we have that correlates more strongly with the EV we would have estimated had we not explicitly adjusted for unawareness, the higher is and the lower is (for all in ).
Capacity-Building: Let , where represents the beliefs of some successor agent and is the strategy this agent follows given that we follow strategy . (So is an element of the UEV, with respect to our values and the successor’s beliefs, of whatever the successor will do given what we do.) Then for all in ,[12] and (we suppose) we can form a reasonable estimate . In particular, capacity-building strategies tend to have large and positive .
Appendix E: On cluster thinking
One approach to cause prioritization that’s commonly regarded as robust to unknown unknowns is cluster thinking. Very briefly, cluster thinking works like this: Take several different world models, and find the best strategy according to each model. Then, choose your strategy by aggregating the different models’ recommendations, giving more weight to models that seem less likely to be missing key parameters.
Cluster thinking consists of a complex set of claims and framings, and I think you can agree with what I’ll argue next while still endorsing cluster thinking over sequence thinking. So, for the sake of scope, I won’t give my full appraisal here. Instead, I’ll briefly comment on why I don’t buy the following arguments that cluster thinking justifies strategy comparisons under unawareness (see footnotes for supporting quotes):
“We can tell which world models are more or less likely to be massively misspecified, i.e., feature lots of unawareness. So strategies that do better according to less-misspecified models are better than those that don’t. This is true even if, in absolute terms, all our models are bad.”[13]
Response: This merely pushes the problem back. Take the least-misspecified model we can think of. How do we compare strategies’ performance under that model? To answer that, it seems we need to look at the arguments for particular approaches to modeling strategy performance under unawareness, which I respond to in the rest of the post.
“World models that recommend doing what has worked well across many situations in the past, and/or following heuristics, aren’t very sensitive to unawareness.”[14]
Response: I address these in my responses to Meta-extrapolation and Simple Heuristics. The same problems apply to the claim that cluster thinking itself has worked well in the past.
Appendix F: Toy example of failure of implementation robustness
Recall the attractor states defined in the case study. At a high level: Suppose you know your intervention will move much more probability mass (i) from Rogue to Benevolent, than (ii) from Rogue to Malevolent. And suppose Benevolent is better than Rogue, which is better than Malevolent (so you have outcome robustness), but your estimates of the value of each attractor are highly imprecise. Then, despite these favorable assumptions, the sign of your intervention can still be indeterminate.
More formally, let:
- be the value of the actual world under Benevolent; be the value under Rogue; and be the value under Malevolent.
And suppose an intervention shifts 10% of probability mass from Rogue to Benevolent, and 1% from Rogue to Malevolent.
Then, there’s some in (representing the worst-case outcome of the intervention) such that the change in UEV (written ) is:
.
So, is not robustly positive.
References
Beckstead, Nicholas. 2013. “On the Overwhelming Importance of Shaping the Far Future.” https://doi.org/10.7282/T35M649T.
Carlsmith, Joseph. 2022. “A Stranger Priority? Topics at the Outer Reaches of Effective Altruism.” University of Oxford.
Greaves, Hilary. 2016. “Cluelessness.” Proceedings of the Aristotelian Society 116 (3): 311–39.
Greaves, Hilary, and William MacAskill. 2021. “The Case for Strong Longtermism.” Global Priorities Institute Working Paper No. 5-2021, University of Oxford.
Mogensen, Andreas L. 2020. “Maximal Cluelessness.” The Philosophical Quarterly 71 (1): 141–62.
Tarsney, Christian. 2023. “The Epistemic Challenge to Longtermism.” Synthese 201 (6): 1–37.
Thorstad, David, and Andreas Mogensen. 2020. “Heuristics for Clueless Agents: How to Get Away with Ignoring What Matters Most in Ordinary Decision-Making.” Global Priorities Institute Working Paper No. 2-2020, University of Oxford.
- ^
Quote (emphasis mine): “And if I expect that I have absolutely no idea what the black swans will look like but also have no reason to believe black swans will make this event any more or less likely, then even though I won't adjust my credence further, I can still increase the variance of my distribution over my future credence for this event.”
- ^
See also Buhler, section “The good and bad consequences of an action we can’t estimate without judgment calls cancel each other out, such that judgment calls are unnecessary”.
- ^
Assume our only way to evaluate strategies is via Meta-extrapolation. We still need to weigh up the net direction of the evidence from past performance. But how do we choose the reference class of decision problems, especially the goals they’re measured against? It’s very underdetermined what makes goals “relevantly similar”. E.g.:
- Relative to the goal “increase medium-term human welfare”, Tomasik’s philosophical reflection strategy worked well.Relative to “save people’s immortal souls”, the consequences of modern philosophy were disastrous.
The former goal matches the naturalism of EA-style impartial altruism, but the latter goal matches its unusually high stakes. Even with a privileged reference class, our sample of past decision problems might be biased, leading to the same ambiguities noted above.
- ^
Technically, we don’t know the counterfactual, and one could argue that these strategies made atrocities in the 1900s worse. See, e.g., the consequences of dictators reflecting on ambitious philosophical ideas like utopian ideologies, or the rise of factory farming thanks to civilizational stability. At any rate, farmed animal suffering is an exception that proves the rule. Once we account for a new large set of moral patients whose welfare depends on different mechanisms, the trend of making things “better” breaks.
- ^
More formally: Our set of probability distributions (in the UEV model) should include some under which a strategy that succeeded in the past is systematically worse for the impartial good (that is, the UEV is lower) than other strategies.
- ^
Recap: Adherence to a heuristic isn’t in itself an impartial altruistic justification for a strategy. We need some argument for why this heuristic leads to impartially better outcomes, despite severe unawareness.
- ^
Quote: “If any of these propositions is wrong, the argument loses all force, and so they require a relatively detailed picture of the world to be accurate. The argument for the general goodness of economic progress or better information seems to be much more robust, and to apply even if our model of the future is badly wrong.”
- ^
“Power”, for example, consists of factors like:
- access to advanced AI systems (which domains is it more or less helpful for them to be “advanced” in?);influence over governments and militaries (which kinds of “influence”?);memetic fitness;bargaining leverage, and willingness to use it;capabilities for value lock-in; andprotections from existential risk.
I’m not sure why we should expect that by increasing any one of these factors, we won’t have off-target effects on the other factors that could outweigh the intended upside.
- ^
We might try hedging against the backfire risks we incur now by also empowering our successors to fix them in the future (cf. St. Jules). However, this doesn’t work if some downsides are irreversible by the time our successors know how to fix them, or if we fail to empower successors with our values in the first place. See also this related critique of the “option value” argument for x-risk reduction.
- ^
As Clifton emphasizes, this reasoning is not equivalent to Symmetry. The claim isn’t that the net welfare in “all the other effects” is zero in expectation, only that the indeterminate balance of those effects gives us no reason for/against choosing some option.
- ^
We might wonder: “Doesn’t the counterargument to Option 3 apply just as well to this approach of ‘suspend judgment on the impartial good, and act based on other normative criteria?” It’s out of scope to give a full answer to this. But my current view is, even if the boundaries between effects we are and aren’t “clueless about” in an impartial consequentialist calculus are arbitrary, the boundary between impartial consequentialist reasons for choice and non-impartial-consequentialist reasons for choice is not arbitrary. So it’s reasonable to “bracket” the former and make decisions based on the latter.
- ^
We take the expectation over s’ with respect to our beliefs p, because we’re uncertain what strategy our successor will follow.
- ^
Quote: “Cluster thinking uses several models of the world in parallel … and limits the weight each can carry based on robustness (by which I mean the opposite of Knightian uncertainty: the feeling that a model is robust and unlikely to be missing key parameters).”
- ^
Quote (emphasis mine): “Correcting for missed parameters and overestimated probabilities will be more likely to cause “regression to normality” (and to the predictions of other “outside views”) than the reverse. … And I believe that the sort of outside views that tend to get more weight in cluster thinking are often good predictors of “unknown unknowns.” For example, obeying common-sense morality (“ends don’t justify the means”) heuristics seems often to lead to unexpected good outcomes…”
Discuss
