
AI能看图,也能讲故事,但能理解“物体在哪”“怎么动”吗?
空间智能,正是大模型走向具身智能的关键拼图。
面对1000道多图推理题,开源大模型集体失守——准确率不到30%,甚至不如瞎猜!就连最强的OpenAI o3,也只答对了41%。
这一专为多图像空间智能设计的MMSI-Bench由上海人工智能实验室、香港中文大学、浙江大学、清华大学、上海交通大学、香港大学以及北京师范大学的研究者们共同完成。

多图像空间智能VQA基准测试
MLLM在连接语言视觉、理解物理世界方面进展飞速,是通往具身AGI的关键。其中,空间智能(即理解物体位置、运动等空间关系的能力)至关重要,是自动驾驶、机器人导航与操作等应用的基础。
然而,当前评估MLLM空间智能普遍存在一些问题:
- 单图像局限
因此,缺乏能检验真实多图像推理的基准,就无法可靠衡量和提升MLLM的空间认知。为此,MMSI-Bench的提出正是为了弥补这一评测空白。
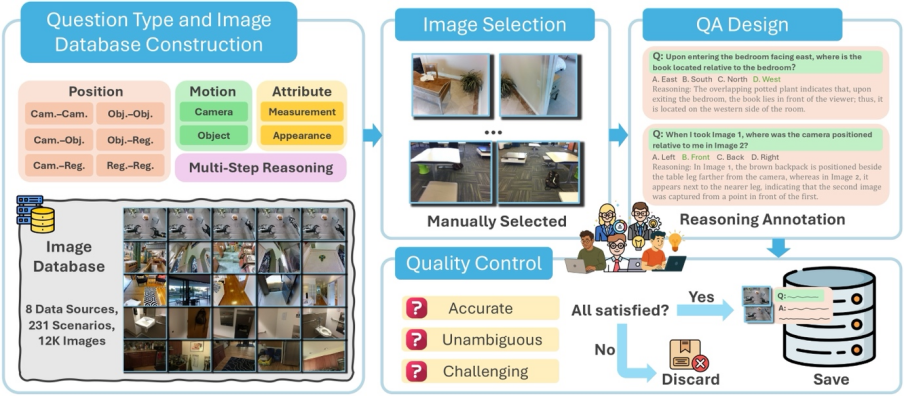
MMSI-Bench是一个用于评估MLLM多图像空间推理能力的VQA基准,设计过程中重点考虑了空间理解的关键要素和数据质量的可靠性。
核心理念:人工主导的样本构建
MMSI-Bench采用完全以人为中心的设计。六位资深3D视觉研究员投入超300小时,从12万余张图像中精选并构建了1000个高质量问答对。
每个问题均极具挑战、答案无歧义,且必须整合多图像信息解答。问题配有精心设计的干扰项和详尽的步骤化标准推理过程,并经第二标注员严格审核,确保质量。
全面的任务分类:系统评估空间推理维度

为系统评估多图像空间推理,MMSI-Bench围绕相机/智能体、物体、区域三个基本空间元素及其位置关系、属性、运动状态构建了全面任务分类。共定义10种基础空间推理任务和1种多步推理(MSR)类别:
除MSR外,其他类别问题均基于两张图像,专注核心的多图像整合能力。
多样化的数据来源:覆盖真实世界场景
为确保评估的全面性和真实性,MMSI-Bench图像全部源于真实的、多样化的场景数据集,包括ScanNet,Matterport3D(室内3D场景),nuScenes,Waymo(自动驾驶),AgiBot-World(机器人),DAVIS 2017(视频物体分割),Ego4D(第一人称视角视频)及DTU(局部场景重建)。这些丰富数据源使MMSI-Bench能构建覆盖广泛真实世界场景的问答对。
实验结果揭示MLLM短板
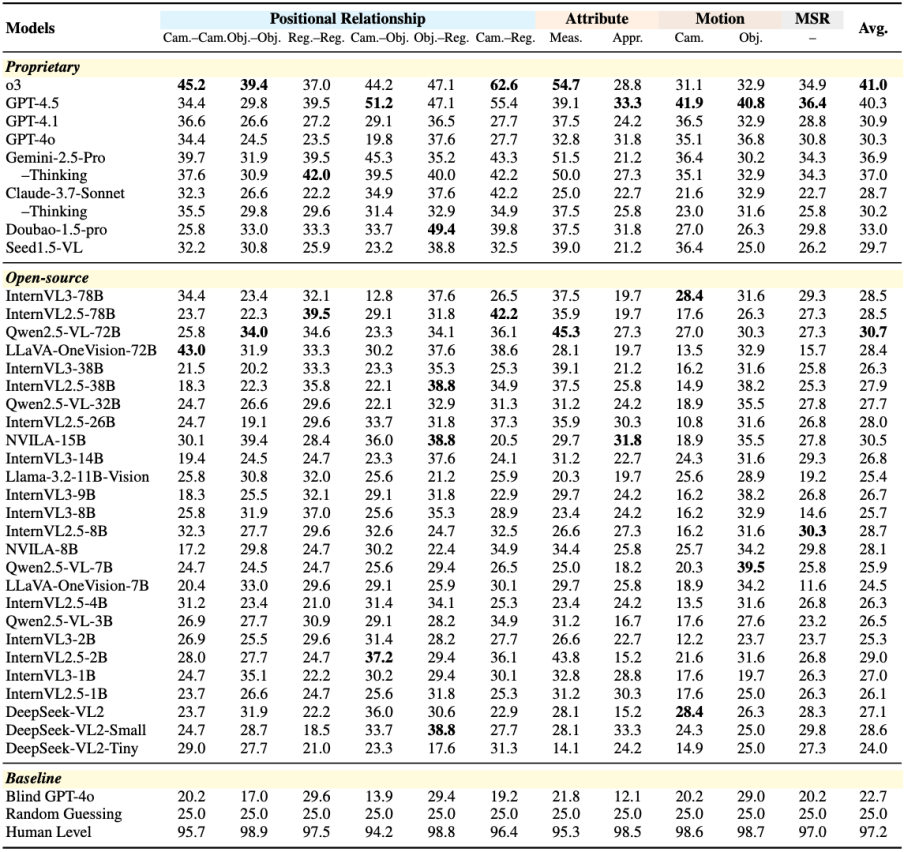
作者在MMSI-Bench上对34个广泛使用的MLLM(包括商业模型如o3,GPT-4.5,GPT-4o等,以及开源模型如Qwen2.5-VL,InternVL系列等)进行了全面评估。
主要发现包括:
- MLLM在多图像空间推理上举步维艰
为探究MLLM在多图像空间推理上的瓶颈,作者对代表性模型(GPT-4o)的推理过程进行了细致的人工分析,归纳出四种主要错误类型:
这些错误分类清晰指出了当前MLLM在空间智能方面的具体短板。
MMSI-Bench每个问题均附带高质量的人类标注推理过程,基于此,作者开发了一套自动化的错误分析流程,以高效、规模化地诊断模型失败原因。
该流程利用强大语言模型(如GPT-4o)作为评估器,结合基准问题、图像、标准答案及MMSI-Bench提供的人类标注参考推理,判断待评估模型推理过程的正确性,并从上述四种错误类型中识别关键错误。
此自动化错误分析流程的价值:
通过人工洞察与自动化工具的结合,MMSI-Bench不仅衡量模型表现,更深入探究失败原因,为推动MLLM空间智能发展提供有力支持。
总结与展望
目前已有多个团队在打造面向多模态大模型(MLLM)的空间智能评测,而MMSI-Bench具备以下特点:
MMSI-Bench作为专为多图像空间智能设计的挑战性综合基准,通过对34个顶尖MLLM的评估,清晰揭示了其与人类水平的巨大鸿沟。希望MMSI-Bench能成为社区宝贵资源,推动开发空间感知更强、更鲁棒的多模态AI系统,加速通往真正理解并与物理世界交互的AGI。
项目主页: https://runsenxu.com/projects/MMSI_Bench
ArXiv论文: https://arxiv.org/abs/2505.23764
Hugging Face数据集:https://huggingface.co/datasets/RunsenXu/MMSI-Bench
GitHub代码库: https://github.com/OpenRobotLab/MMSI-Bench
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
