百川智能推出了Baichuan-Omni-1.5全模态模型,该模型在视觉、语音和多模态流式处理方面超越了GPT-4o mini,尤其在多模态医疗应用领域表现出色。该模型支持文本、图像、音频和视频的理解与生成,并开源了GPT-4o级别的基座模型以及OpenMM-Medical、OpenAudioBench两个评测集,旨在推动全模态模型领域的研究和发展。通过优化数据、模型结构和训练流程,Baichuan-Omni-1.5解决了多模态模型的“模型降智”难题,为医疗领域的应用带来了新的可能性。
🖼️Baichuan-Omni-1.5是一个支持文本、图像、音频和视频的全模态模型,具备文本和音频的双模态生成能力。
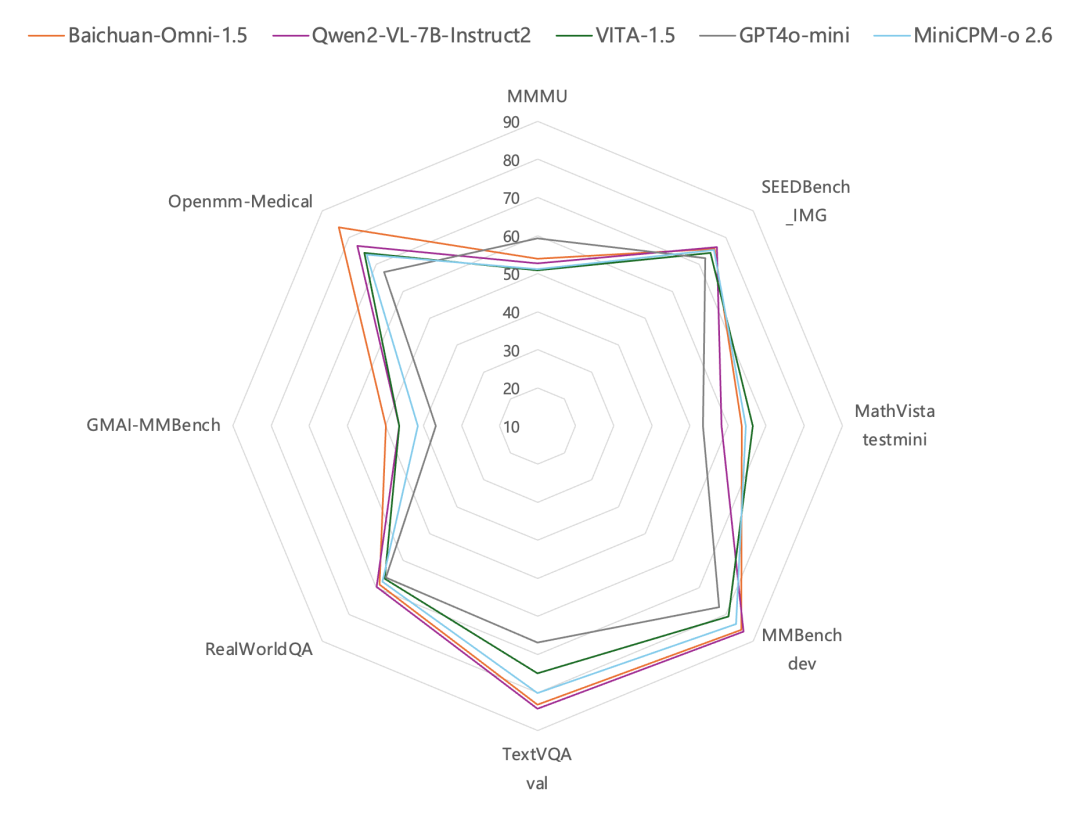
🗣️该模型在视觉、语音及多模态流式处理等方面均优于GPT-4o mini,尤其在多模态医疗应用领域表现突出。
🩺为了提升在医疗领域的能力,百川智能构建了OpenMM-Medical评测集,包含了来自42个公开医学图像数据集的88,996张图像,用于更全面地评估模型医疗多模态能力。
🧠为了评估模型的“智商”,百川智能构建了OpenAudioBench,包含5个音频端到端理解子评测集,共有2701条数据,综合反映模型的“智商”水平。
⚙️Baichuan-Omni-1.5通过优化模型结构、训练策略和训练数据,解决了全模态模型中常见的“模型降智”难题,实现了理解与生成的统一。
专注医疗的 2025-01-26 13:40 北京
Baichuan-Omni-1.5在视觉、语音和多模态流式能力上超越GPT-4o mini,多模态医疗能力大幅领先。

两天前,我们发布了全场景深度推理模型
Baichuan-M1-preview和医疗增强开源模型
Baichuan-M1-14B。今天,我们再接再厉,上线
Baichuan-Omni-1.5开源全模态模型。该模型不仅支持文本、图像、音频和视频的全模态理解,还具备文本和音频的双模态生成能力。在视觉、语音及多模态流式处理等方面,Baichuan-Omni-1.5 的表现均优于 GPT-4o mini,而在多模态医疗应用领域,它的领先优势则更为突出。
Baichuan-Omni-1.5通过完善的数据抓取、清洗、合成流程得到大量不同模态的数据以及全面的多模态交错数据,并且设计了多阶段的训练流程,很好完成了多个模态间对齐,加上合理的模型结构优化,从而实现一个模型在多个模态能力均达到领先的效果,解决了多模态模型的“模型降智”难题。Baichuan-Omni-1.5不仅能在输入和输出端实现多种交互操作,还拥有强大的多模态推理能力和跨模态迁移能力。此次,我们不仅开源了GPT-4o级别的全模态基座Baichuan-Omni-1.5-Base,同时还开源了两个评测集
OpenMM-Medical、OpenAudioBench,促进全模态模型领域的研究发展。
GitHub:https://github.com/baichuan-inc/Baichuan-Omni-1.5模型权重:Baichuan-Omni-1.5:
https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5https://modelers.cn/models/Baichuan/Baichuan-Omni-1d5Baichuan-Omni-1.5-Base:
https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5-Basehttps://modelers.cn/models/Baichuan/Baichuan-Omni-1d5-Base技术报告:https://github.com/baichuan-inc/Baichuan-Omni-1.5/blob/main/baichuan_omni_1_5.pdf全模态理解生成统一模型,多项能力超越GPT-4o mini全模态模型能够处理文本、图像、语音、视频等各类数据,从而实现更全面、精准的信息理解和表达,对提升模型的理解能力及拓展应用范围等方面具有重要意义。Baichuan-Omni-1.5在多项评测中表现优异,在MMBench-dev等通用图片评测中领先GPT4o-mini,在医疗图片评测集GMAI-MMBench、Openmm-Medical中更是大幅超越GPT4o-mini。

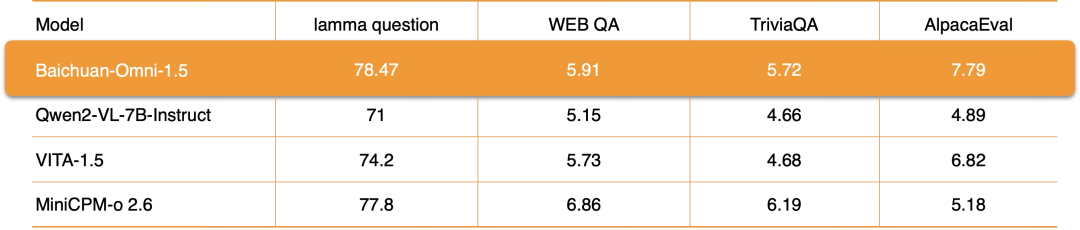
Baichuan-Omni-1.5在音频技术领域采用了业界领先的端到端解决方案,不仅能够支持多语言对话,还拥有强大的端到端音频合成能力,并且可以实现ASR(自动语音识别)和TTS(文本转语音)功能,同时支持视频与音频的实时交互。

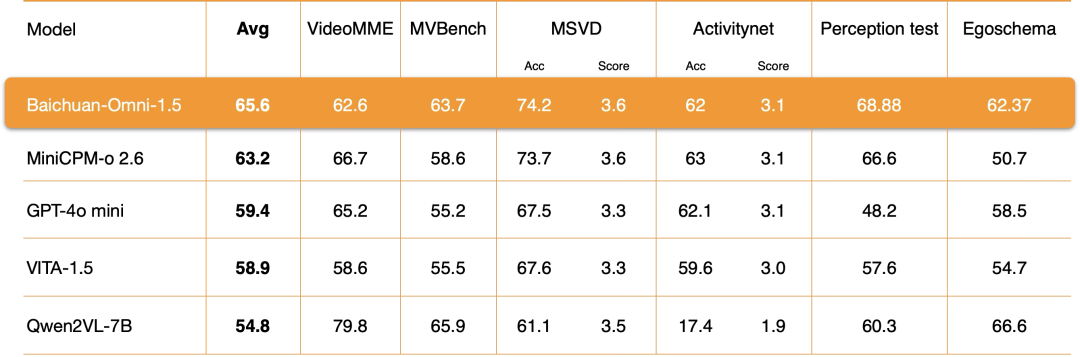
在视频理解能力方面,Baichuan-Omni-1.5通过对编码器、训练数据和训练方法等多个关键环节进行深入优化,其整体性能大幅超越GPT-4o-mini。

全流程优化解决“降智”难题,真正实现理解生成统一理解和生成的统一是当前多模态研究领域中的一大热点和难点。在全模态理解模型中加入语音token生成后,通常会导致模型理解能力的显著下降,特别是在数学能力和逻辑推理方面,这种现象被称为“模型降智”。目前,所有开源的全模态模型都面临着这一问题,这也是该领域需要重点解决的关键挑战。Baichuan-Omni-1.5通过模型结构、训练策略和训练数据等多个方面的深入优化,成功地解决了这一问题。
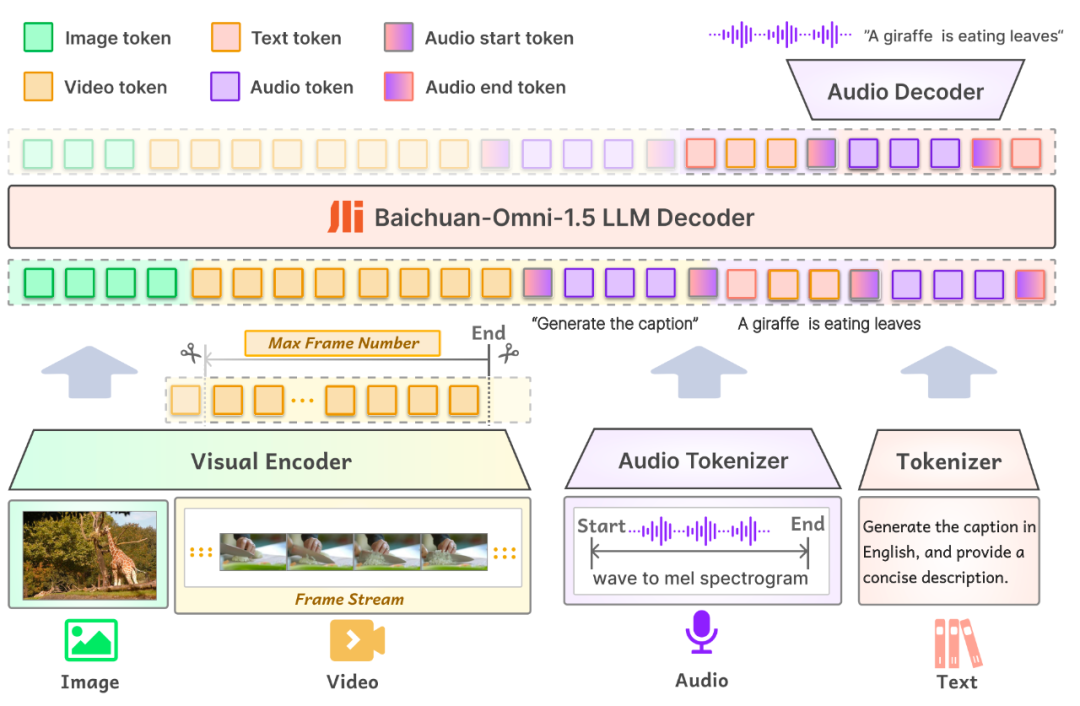
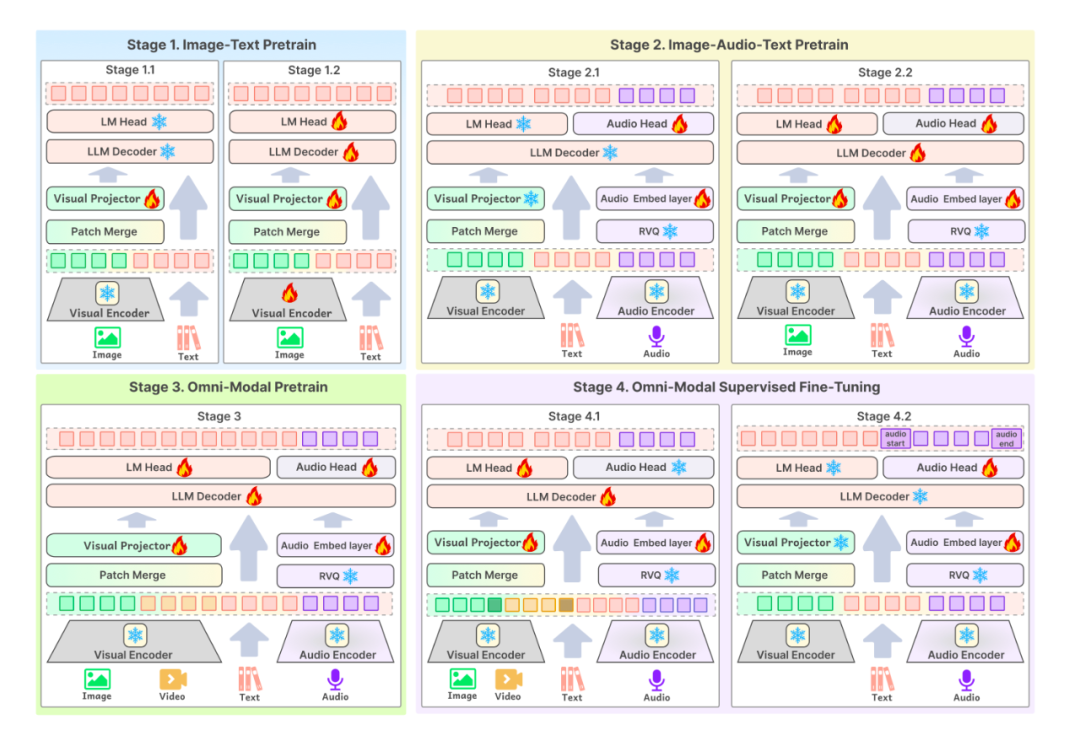
模型结构方面,Baichuan-Omni-1.5的模型输入部分支持各种模态通过相应的Encoder/Tokenizer输入到大型语言模型中。而在模型输出部分,Baichuan-Omni-1.5采用了文本-音频交错输出的设计,通过Text Tokenizer和Audio Decoder同时生成文本和音频。其中,Audio Tokenizer是在Whisper基础上经过增量训练得到的,它不仅具备高级语义抽取能力,还能实现音频的高保真重建。至于Visual Encoder,则采用了能够处理任意分辨率图片的NaViT,其最高分辨率可达4K(2048x2048)并支持多图推理,从而能够更全面地提取图片信息。
 训练数据方面,
训练数据方面,我们设计了一套专门的流程来确保数据的质量和多样性。最终构建了一个包含3.4亿条高质量图片/视频-文本数据和近100万小时音频数据的庞大数据库。在SFT阶段,我们还使用了1700万条精心构建的全模态数据。
训练流程方面,我们在预训练和SFT阶段均设计了多阶段训练方案,整体提升了模型效果。

我们同时还开源了两个评测:
OpenMM-Medical、OpenAudioBench。随着人工智能技术的迅猛发展,大模型已经从单一模态进化到全模态阶段。全模态融合技术赋予了大型语言模型视觉、听觉和语言表达的能力,使其能够更加精准地理解和传递信息。特别是在医疗领域,全模态模型能够整合医学影像(如X光、CT等)、检查报告和病历等多元信息,协助医生进行疾病诊断,显著提升诊断的准确性和效率。我们此次开源全模态模型及数据、评测集,也是希望激发行业内更多的创新力量,促进中国AI医疗健康生态的持续进步,助力实现更加普惠的高质量医疗服务。
阅读原文
跳转微信打开

