
给大模型当老师,让它一步步按你的想法做数据分析,有多难?
结果是,连Claude-3.7和Gemini-2.5 Pro这样的顶尖选手,都开始“不听话”了。
在一个全新的测试基准中,它们面对多轮、不断演进的指令,最终的任务成功率最高仅有40%。
这项名为IDA-Bench的新基准,就是为了模拟真实世界中这种“边想边改”的分析场景而生。

它不再是给模型一道题,让它一口气算完;而是模拟一位真实的数据分析师,在对话中不断给出新指令,考察Agent在多轮交互中的真实能力。
可以说,专治各种“自作主张”和“一意孤行”的AI。
值得一提的是,这项工作由一支星光熠熠的团队打造,汇集了北京大学与加州大学伯克利分校的顶尖学者,其中不乏机器学习泰斗Michael I. Jordan教授,仿真科学领域专家郑泽宇 (Zeyu Zheng) 副教授,以及ACM/IEEE Fellow邓小铁 (Xiaotie Deng) 教授的身影。
“不听话”的AI,问题出在哪?
目前,我们看到的很多大模型数据分析工具,比如OpenAI、Gemini和Claude的网页应用,能力已然非常强大。
但现有的评估基准,大多侧重于单轮互动:用户给出一个明确的、预设好的任务,然后看Agent能否成功执行。
可现实世界的数据分析,远非如此。
真实的数据分析师,工作流程是迭代式、探索性的。他们会先查看数据分布,再决定如何处理异常值;会根据初步结果,调整后续的分析策略。这些决策充满了基于领域知识的“主观性”,指令也是一步步演进的。
现有基准恰恰忽略了这种动态交互过程,因此无法全面评估Agent在真实协作场景下的可靠性。
IDA-Bench:给AI一场真实的“随堂测验”
为了解决这一痛点,IDA-Bench应运而生。它旨在忠实地反映真实数据分析的主观性和交互性特征。
整个测试框架包含四大核心组件:
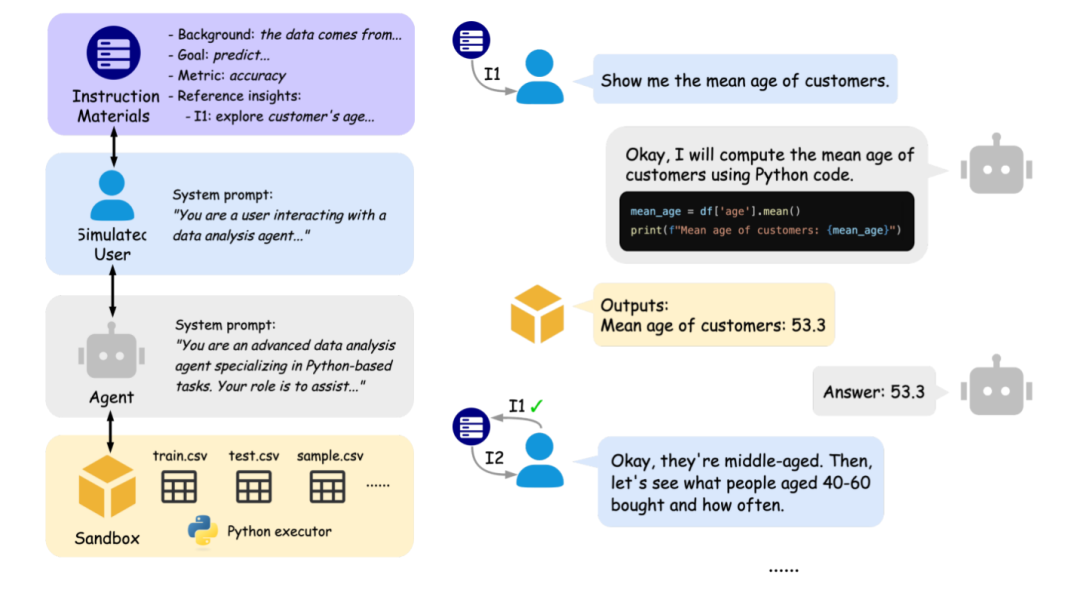
△图1:(左) IDA-Bench的测试场景 ,(右) IDA-Bench中的任务轨迹示例
为了确保任务的真实性和时效性,防止数据污染,IDA-Bench的构建流程完全自动化。它能持续从Kaggle上发布的最新项目中提取任务,经过筛选、预处理和人工检查后,生成新的测试用例。

△图2: IDA-Bench的自动化构建流程
Agent惨遭滑铁卢,最高分仅40
在这样一套“严刑拷打”下,各大模型纷纷现出原形。
初步评估结果显示,即便是最先进的大模型,成功率也不足50%。
具体来看,Gemini-2.5-Pro、OpenAI o4-mini和Claude-3.7-Sonnet-Thinking表现位列第一梯队,但其“基准达成率”(即结果达到或超过人类基准)也仅为40%。
而DeepSeek系列中,作为指令模型的DeepSeek-V3(24%)表现明显优于其“思考型”模型DeepSeek-R1(12%),这揭示了一个核心挑战:在遵循指令和自主推理之间取得平衡,对当前Agent来说非常困难。
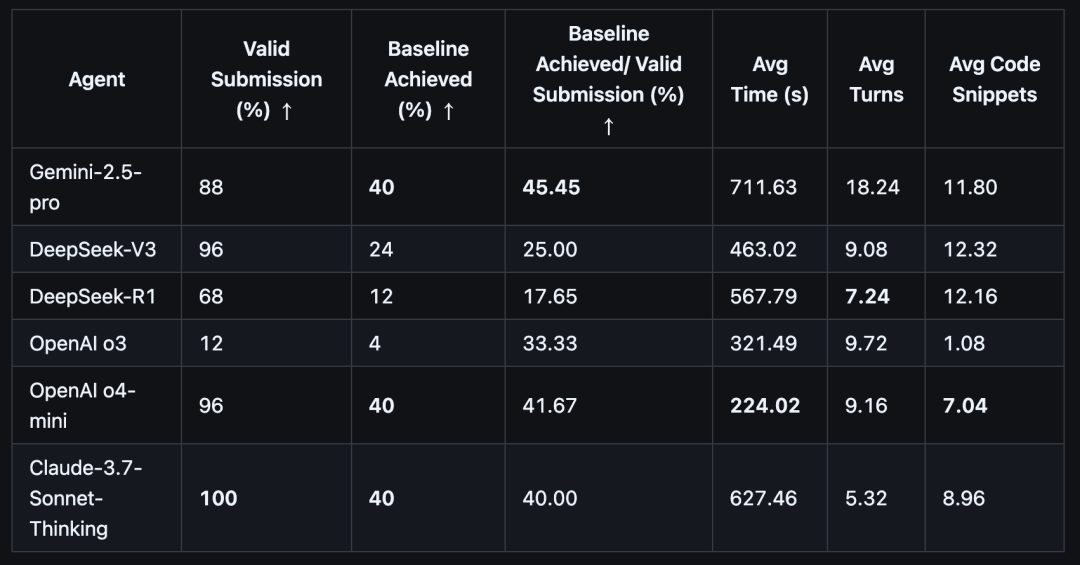
△表1: 各大模型在IDA-Bench上的表现
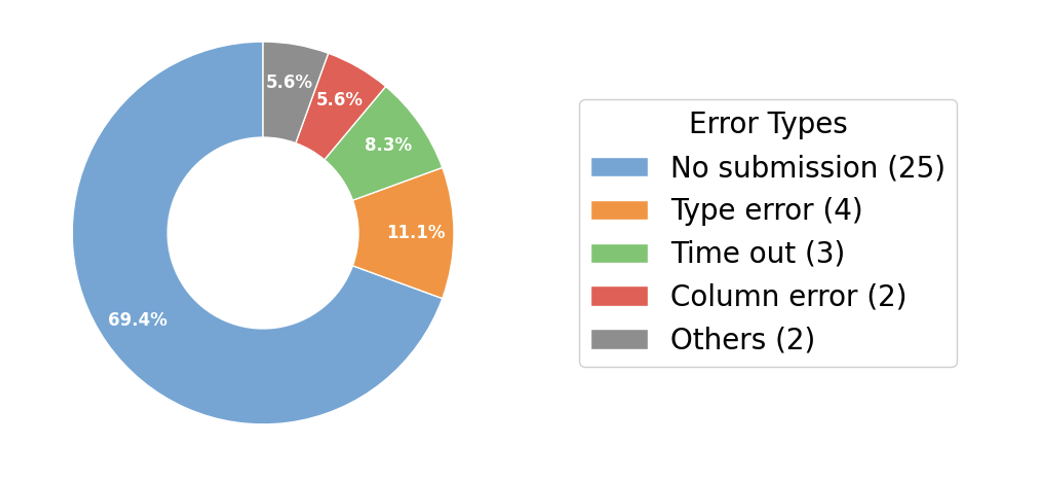
此外,Agent们在任务中还会犯下各种低级错误,导致提交结果无效。其中最主要的原因是根本没有生成提交文件,这往往源于模型的“幻觉”。
“自信”的Claude vs “谨慎”的Gemini
深入分析失败案例,研究团队发现不同模型展现出了迥异的“性格”。
Claude-3.7和DeepSeek-R1表现得像个“过度自信”的实习生。
它们不怎么遵循用户的具体指令,而是主动推进分析流程,结果常常因为“自作主张”而错过了关键步骤和信息。比如,用户建议用一种新方法改进模型,Claude-3.7不等尝试就直接否定,并提交了之前效果较差的结果。
相比之下,Gemini-2.5-Pro则像一个“过度谨慎”的助理。它每走一步都要反复向用户寻求确认,有时一个简单的数据清洗操作能来回沟通30轮,最终因超过回合数限制而任务失败。
这些发现凸显了当前LLM Agent在真正成为可靠数据分析助手之前,仍需在理解、遵循和交互能力上进行大量改进。
论文链接:
https://arxiv.org/abs/2505.18223
项目主页:
https://github.com/lhydave/IDA-Bench
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
