
Effortlessly Integrate E-Signatures into Your App with BoldSign (Sponsored)

BoldSign by Syncfusion makes it easy for developers to integrate e-signatures into applications.
Our powerful e-signature API allows you to embed signature requests, create templates, add custom branding, and more.
It’s so easy to get started that 60% of our customers integrated BoldSign into their apps within one day.
Why BoldSign stands out:
99.999% uptime.
Trusted by Ryanair, Cost Plus Drugs, and more.
Complies with eIDAS, ESIGN, GDPR, SOC 2, and HIPAA standards.
No hidden charges.
Free migration support.
Rated 4.7/5 on G2.
Get 20% off the first year with code BYTEBYTEGO20. Valid until Sept. 31, 2024.
Disclaimer: The details in this post have been derived from the article originally published on the RevenueCat Engineering Blog. All credit for the details about RevenueCat’s architecture goes to their engineering team. The link to the original article is present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
RevenueCat is a platform that makes it easy for mobile app developers to implement and manage in-app subscriptions and purchases.
The staggering part is that they handle over 1.2 billion API requests per day from the apps.
At this massive scale, a fast and reliable performance becomes critical. Some of it is achieved by distributing the workload uniformly across multiple servers.
However, an efficient caching solution also becomes the need of the hour.
Caching allows frequently accessed data to be quickly retrieved from fast memory rather than slower backend databases and systems. This can dramatically speed up response times.
But caching also adds complexity since the cached data must be kept consistent with the source of truth in the databases. Stale or incorrect data in the cache can lead to serious issues.
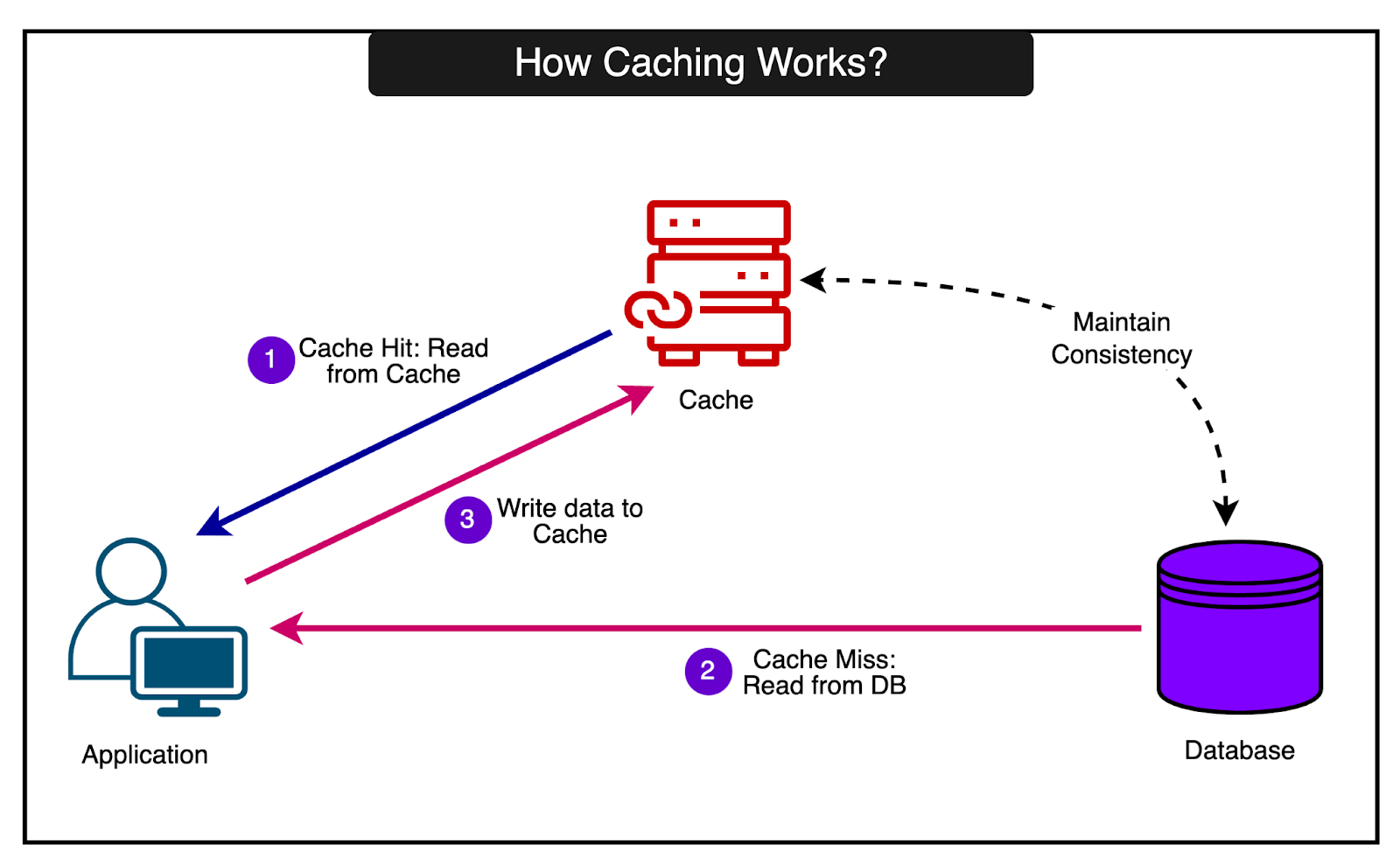
For an application operating at the scale of RevenueCat, even small inefficiencies or inconsistencies in the caching layer can have a huge impact.
In this post, we will look at how RevenueCat overcame multiple challenges to build a truly reliable and scalable caching solution using Memcached.
The Three Key Goals of Caching
RevenueCat has three key goals for its caching infrastructure:
Low latency: The cache needs to be fast because even small delays in the caching layer can have significant consequences at this request volume. Retrying requests and opening new connections are detrimental to the overall performance.
Keeping cache servers up and warm: Cache servers need to stay available and full of frequently accessed data to offload the backend systems.
Maintaining data consistency: Data in the cache needs to be consistent. Inconsistency can lead to serious application issues.
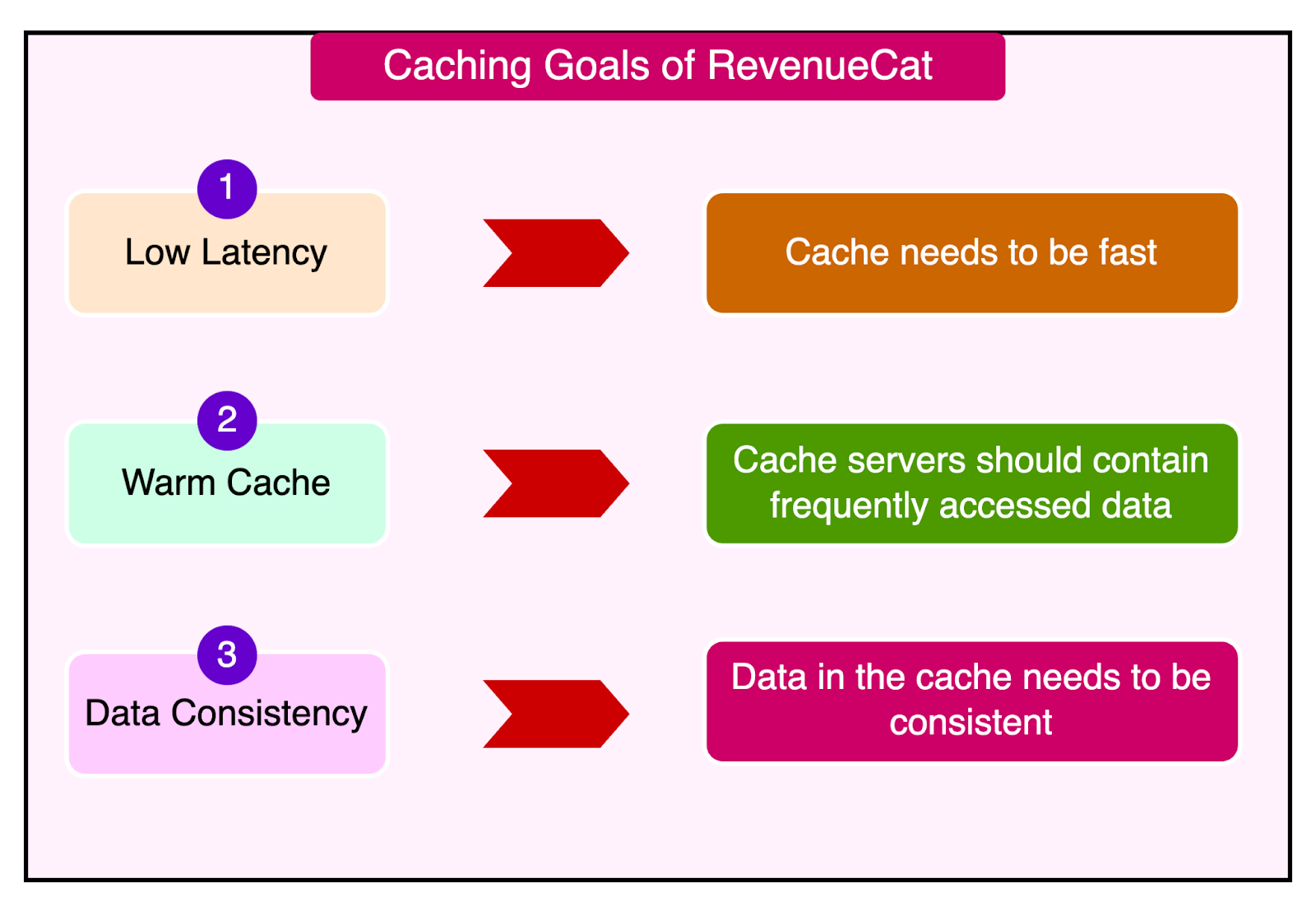
While these main goals are highly relevant to applications operating at scale, a robust caching solution also needs supporting features such as monitoring and observability, optimization, and some sort of automated scaling.
Let’s look at each of these goals in more detail and how RevenueCat’s engineering team achieved them.
Low Latency
There’s no doubt that latency has a huge impact on user experience.
As per a statistic by Amazon, every 100ms of latency costs them 1% in sales. While it’s hard to confirm whether this is 100% true, there’s no denying the fact that latency impacts user experience.
Even small delays of a few hundred milliseconds can make an application feel sluggish and unresponsive. As latency increases, user engagement and satisfaction plummet.
RevenueCat achieves low latency in its caching layer through two key techniques.
1 - Pre-established connections
Their cache client maintains a pool of open connections to the cache servers.
When the application needs to make a cache request, it borrows a connection from the pool instead of establishing a new TCP one. This is because a TCP handshake could nearly double the cache response times. Borrowing the connection avoids the overhead of the TCP handshake on each request.
But no decision comes without some tradeoff.
Keeping connections open consumes memory and other resources on both the client and server. Therefore, it’s important to carefully tune the number of connections to balance resource usage with the ability to handle traffic spikes.
2 - Fail-fast approach
If a cache server becomes unresponsive, the client immediately marks it as down for a few seconds and fails the request, treating it as a cache miss.
In other words, the client will not retry the request or attempt to establish new connections to the problematic server during this period.
The key insight here is that even brief retry delays of 100ms can cause cascading failures under heavy load. Requests pile up, servers get overloaded, and the "retry storm" can bring the whole system down. Though it might sound counterintuitive, failing fast is crucial for a stable system.
But what’s the tradeoff here?
There may be a slight increase in cache misses when servers have temporary issues. But this is far better than risking a system-wide outage. A 99.99% cache hit rate is meaningless if 0.01% of requests trigger cascading failures. Prioritizing stability over perfect efficiency is the right call.
One potential enhancement over here could be circuit breaking where requests to misbehaving servers can be disabled based on error rates and latency measurements. This is something that Uber uses in their integrated cache solution called CacheFront.
However, the aggressive timeouts and managing connection pools likely achieve similar results with far less complexity.
Keeping Cache Servers Warm
The next goal RevenueCat had was keeping the cache servers warm.
They employed several strategies to achieve this.
1 - Planning for Failure with Mirrored and Gutter pool
RevenueCat uses fallback cache pools to handle failures.
Their strategy is designed to handle cache server failures and maintain high availability. The two approaches they use are as follows:
Mirrored pool: A fully synchronized secondary cache pool that receives all writes and can immediately take over reads if the primary pool fails.
Gutter pool: A small, empty cache pool that temporarily caches values with a short TTL when the primary pool fails, reducing the load on the backend until the primary recovers. For reference, the gutter pool technique was also used by Facebook when they built their caching architecture with Memcached.
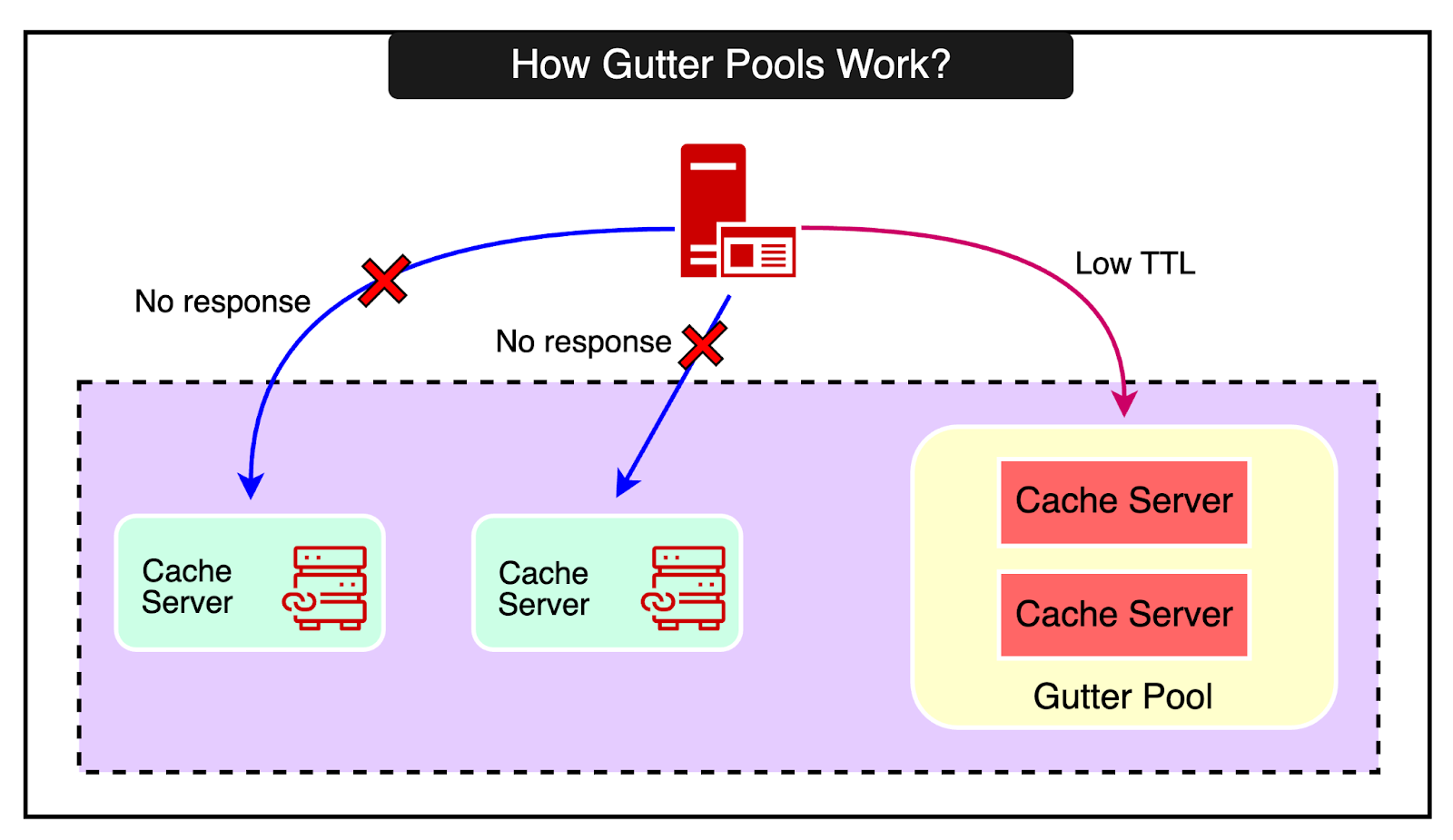
Here also, there are trade-offs to consider concerning server size:
For example, having smaller servers provides benefits such as:
Granular failure impact: With many small cache servers, the failure of a single server affects a smaller portion of the cached data. This can make the fallback pool more effective, as it needs to handle a smaller subset of the total traffic.
Faster warmup: When a small server fails and the gutter pool takes over, it can warm up the cache for that server’s key space more quickly due to the smaller data volume.
However, small servers also have drawbacks:
Increased operational complexity of managing a larger number of servers adds operational complexity.
A higher connection overhead where each application server has to maintain connections to all cache servers.
The diagram below from RevenueCat’s article shows this comparison:
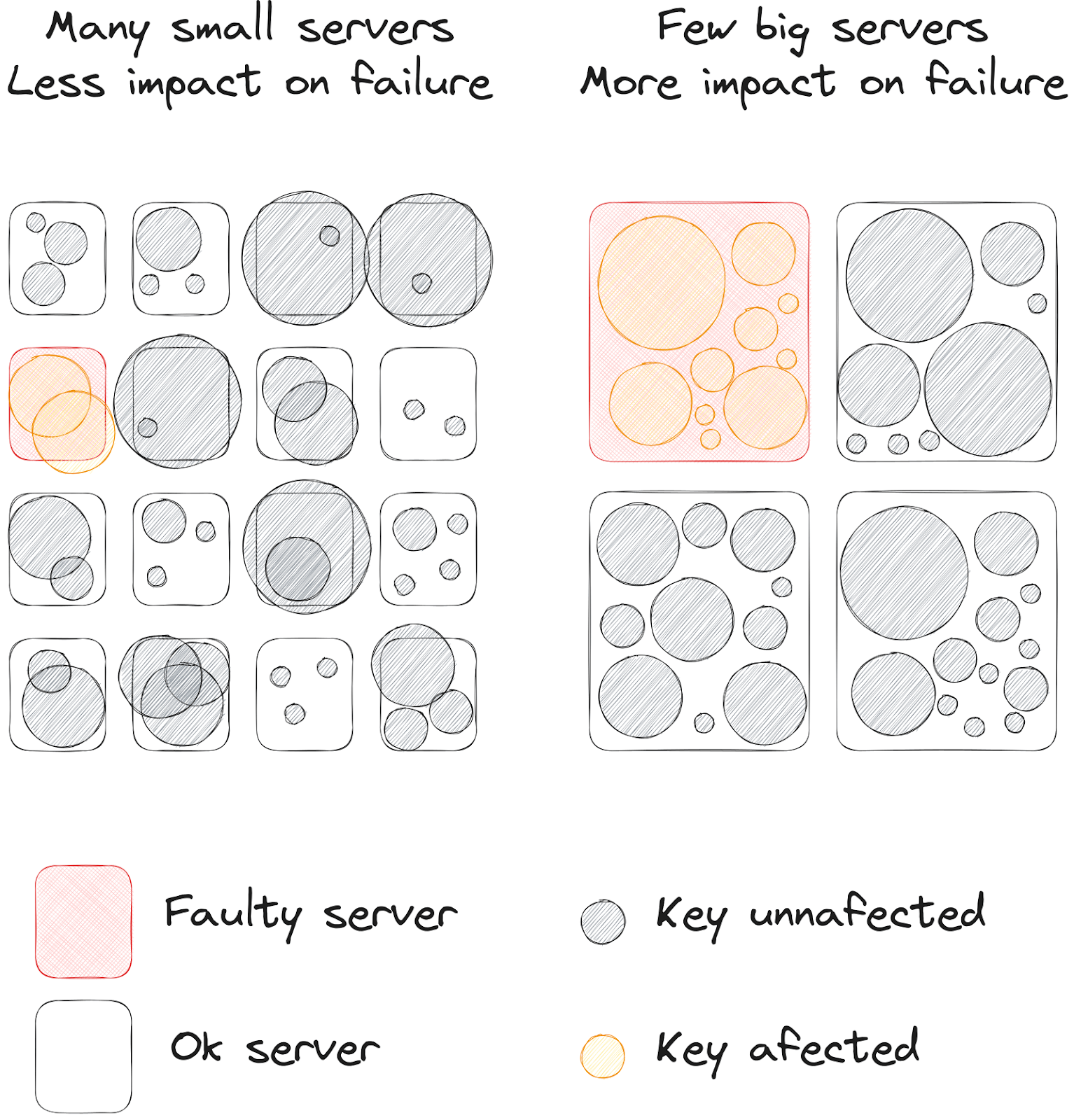
Simplified management: Fewer large servers are easier to manage and maintain compared to many small instances. There are fewer moving parts and less complexity in the overall system.
Improved resource utilization: Larger servers can more effectively utilize the available CPU, memory, and network resources, leading to better cost efficiency.
Fewer connections: With fewer cache servers, the total number of connections from the application servers is reduced, minimizing connection overhead.
Bigger servers also have some trade-offs:
When a large server fails, a larger portion of the cached data becomes unavailable. The fallback pool needs to handle a larger volume of traffic, potentially increasing the load on the backend.
In the case of a failure, warming up the cache for a larger key space may take longer due to the increased data volume.
This is where the strategy of using a mirrored pool for fast failover and a gutter pool for temporary caching strikes a balance between availability and cost.
The mirrored pool ensures immediate availability. The gutter pool, on the other hand, provides a cost-effective way to handle failures temporarily.
Generally speaking, it’s better to design the cache tier based on a solid understanding of the backend capacity. Also, when using sharding, the cache, and the backend sharding should be orthogonal so that a cache server going down translates into a moderate increase on backend servers.
Latest articles
If you’re not a paid subscriber, here’s what you missed.

To receive all the full articles and support ByteByteGo, consider subscribing:
2 - Dedicated Pools
Another technique they employ to keep cache servers warm is to use dedicated cache pools for certain use cases.
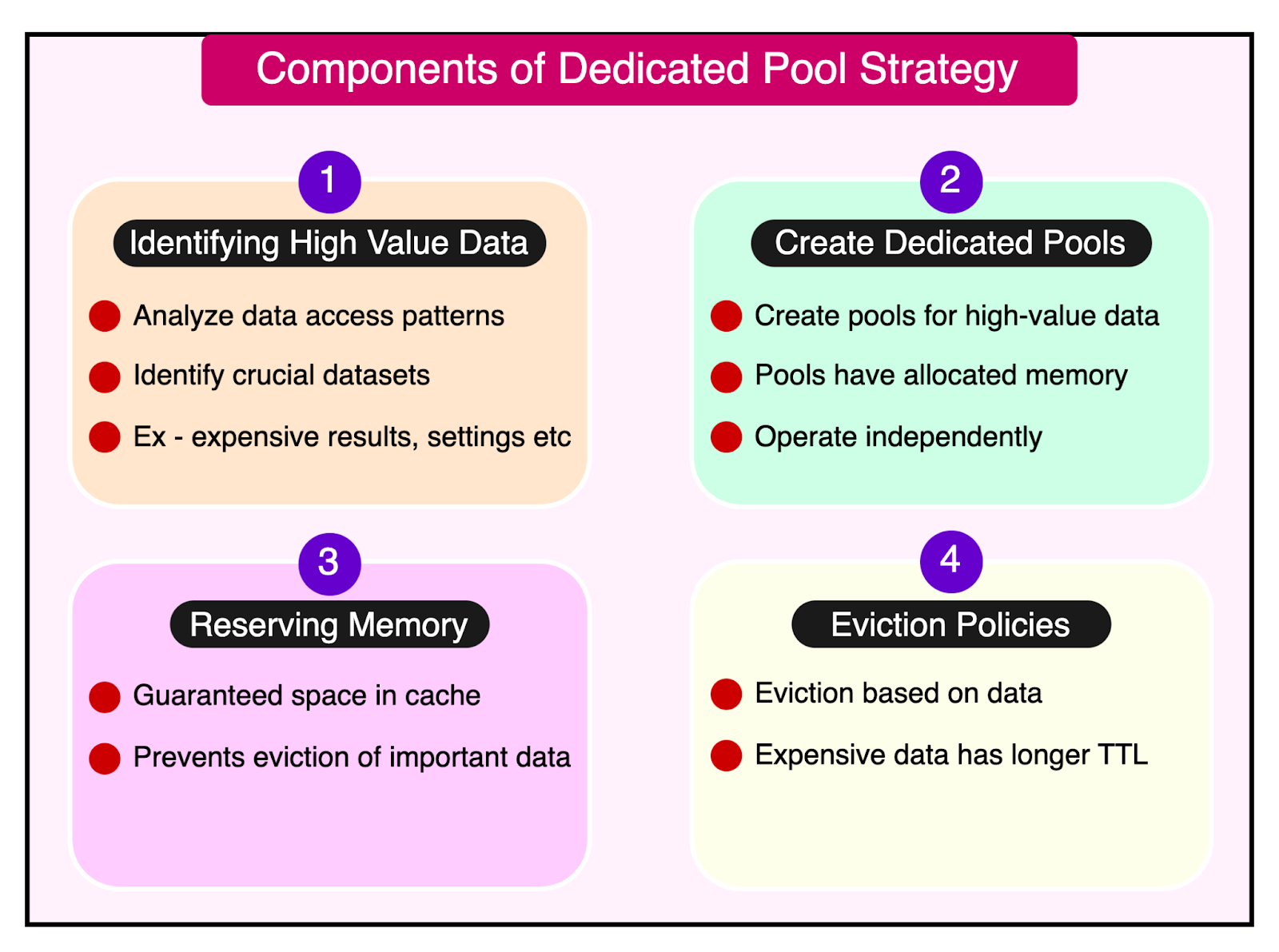
Here’s how the strategy works:
Identifying high-value data: The first step is to analyze the application's data access patterns and identify datasets that are crucial for performance, accuracy, or user experience. This could include frequently accessed configuration settings, important user-specific data, or computationally expensive results.
Creating dedicated pools: Instead of relying on a single shared cache pool, create separate pools for each identified high-value dataset. These dedicated pools have their own allocated memory and operate independently from the main cache pool.
Reserving memory: By allocating dedicated memory to each pool, they ensure that the high-value data has a guaranteed space in the cache. This prevents other less critical data from evicting the important information, even under high memory pressure.
Tailored eviction policies: Each dedicated pool can have its eviction policy tailored to the specific characteristics of the dataset. For example, a pool holding expensive-to-recompute data might have a longer TTL or a different eviction algorithm compared to a pool with frequently updated data.
The dedicated pools strategy has several advantages:
Improved cache hit ratio for critical data
Increased data accuracy
Flexibility in cache management
3 - Handling Hot Keys
Hot keys are a common challenge in caching systems.
They refer to keys that are accessed more frequently than others, leading to a high concentration of requests on a single cache server. This can cause performance issues and overload the server, potentially impacting the overall system.
There are two main strategies for handling hot keys:
Key Splitting
The below points explain how key splitting works:
Key splitting involves distributing the load of a hot key across multiple servers.
Instead of having a single key, the key is split into multiple versions, such as keyX/1, keyX/2, keyX/3, etc.
Each version of the key is placed on a different server, effectively spreading the load.
Clients read from one version of the key (usually determined by their client ID) but write to all versions to maintain consistency.
The challenge with key splitting is detecting hot keys in real time and coordinating the splitting process across all clients.
It requires a pipeline to identify hot keys, determine the splitting factor, and ensure that all clients perform the splitting simultaneously to avoid inconsistencies.
The list of hot keys is dynamic and can change based on real-life events or trends, so the detection and splitting process needs to be responsive.
Local Caching
Local caching is simpler when compared to key splitting.
Here are some points to explain how it works:
Local caching involves caching hot keys directly on the client-side, rather than relying solely on the distributed cache.
A key is cached locally on the client with a short TTL (Time-To-Live) when a key is identified as hot.
Subsequent requests for that key are served from the local cache, reducing the load on the distributed cache servers.
Local caching doesn't require coordination among clients.
However, local caching provides weaker consistency guarantees since the locally cached data may become stale if updates occur frequently.
To mitigate this, it’s important to use short TTLs for locally cached keys and only apply local caching to data that changes rarely.
Avoiding Thundering Herds
When a popular key expires, all clients may request it from the backend simultaneously, causing a spike. This is known as the “thundering herd situation”.
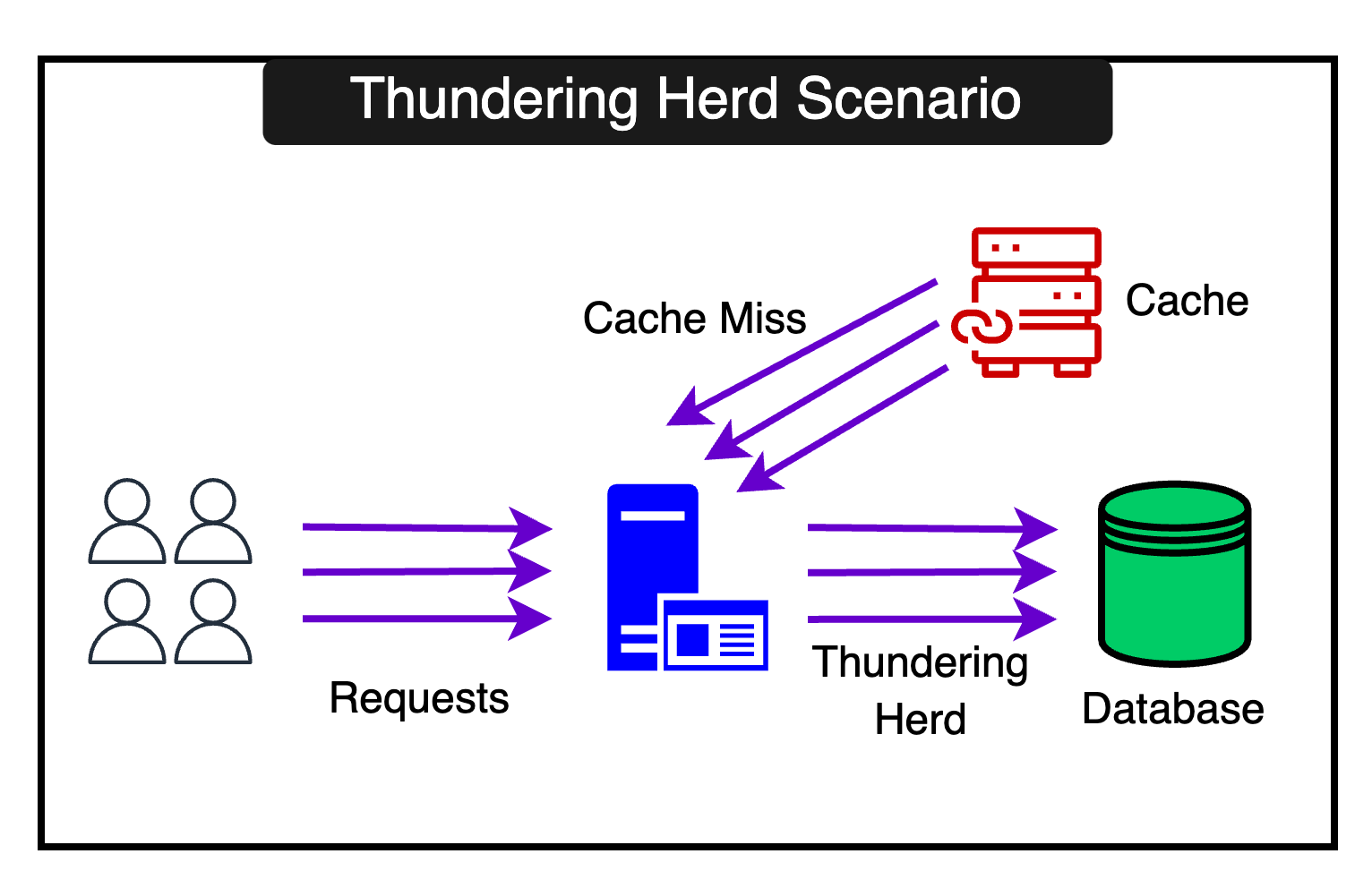
RevenueCat avoids this situation since it tries to maintain cache consistency by updating it during the writes. However, when using low TTLs and invalidations from DB changes, the thundering herd can cause a lot of problems.
Some other potential solutions to avoid thundering herds are as follows:
Recache policy: The GET requests can include a recache policy. When the remaining TTL is less than the given value, one of the clients will get a miss and re-populate the value in the cache while other clients continue to use the existing value.
Stale policy: In the delete command, the key is marked as stale. A single client gets a miss while others keep using the old value.
Lease policy: In this policy, only one client wins the right to repopulate the value while the losers just have to wait for the winner to re-populate. For reference, Facebook uses leasing in its Memcache setup.
Cache Server Migrations
Sometimes cache servers have to be replaced while minimizing impact on hit rates and user experience.
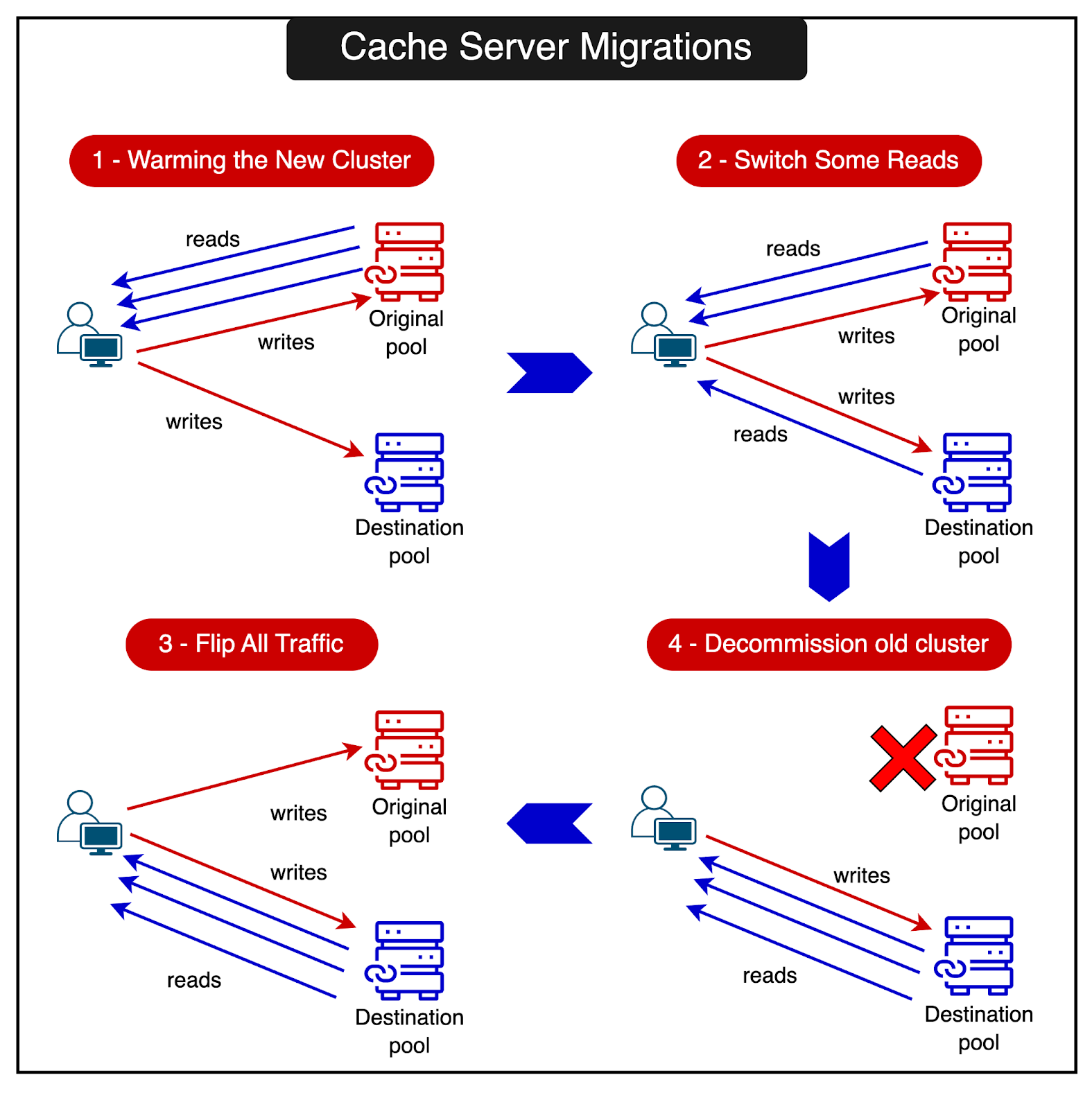
RevenueCat has built a coordinated cache server migration system that consists of the following steps:
Warming up the new cluster:
Before switching traffic, the team starts warming up the new cache cluster.
They populate the new cluster by mirroring all the writes from the existing cluster.
This ensures that the new cluster has the most up-to-date data before serving any requests.
Switching a percentage of reads:
After the new cluster is sufficiently warm, the team gradually switches a percentage of read traffic to it.
This allows them to test the new cluster’s performance and stability under real-world load.
Flipping all traffic:
Once the new cluster has proven its stability and performance, the traffic is flipped over to it.
At this point, the new cluster becomes the primary cache cluster, serving all read and write requests.
The old cluster is kept running for a while, with writes still being mirrored to it. This allows quick fallback in case of any issues.
Decommissioning the old cluster:
After a period of stable operation with the new cluster as the primary, the old cluster is decommissioned.
This frees up resources and completes the migration process.
The diagram below shows the entire migration process.
Maintaining data consistency is one of the biggest challenges when using caching in distributed systems.
The fundamental issue is that data is stored in multiple places - the primary data store (like a database) and the cache. Keeping the data in sync across these locations in the face of concurrent reads and writes is a non-trivial problem.
See the example below that shows how a simple race condition can result in a consistency problem between the database and the cache.
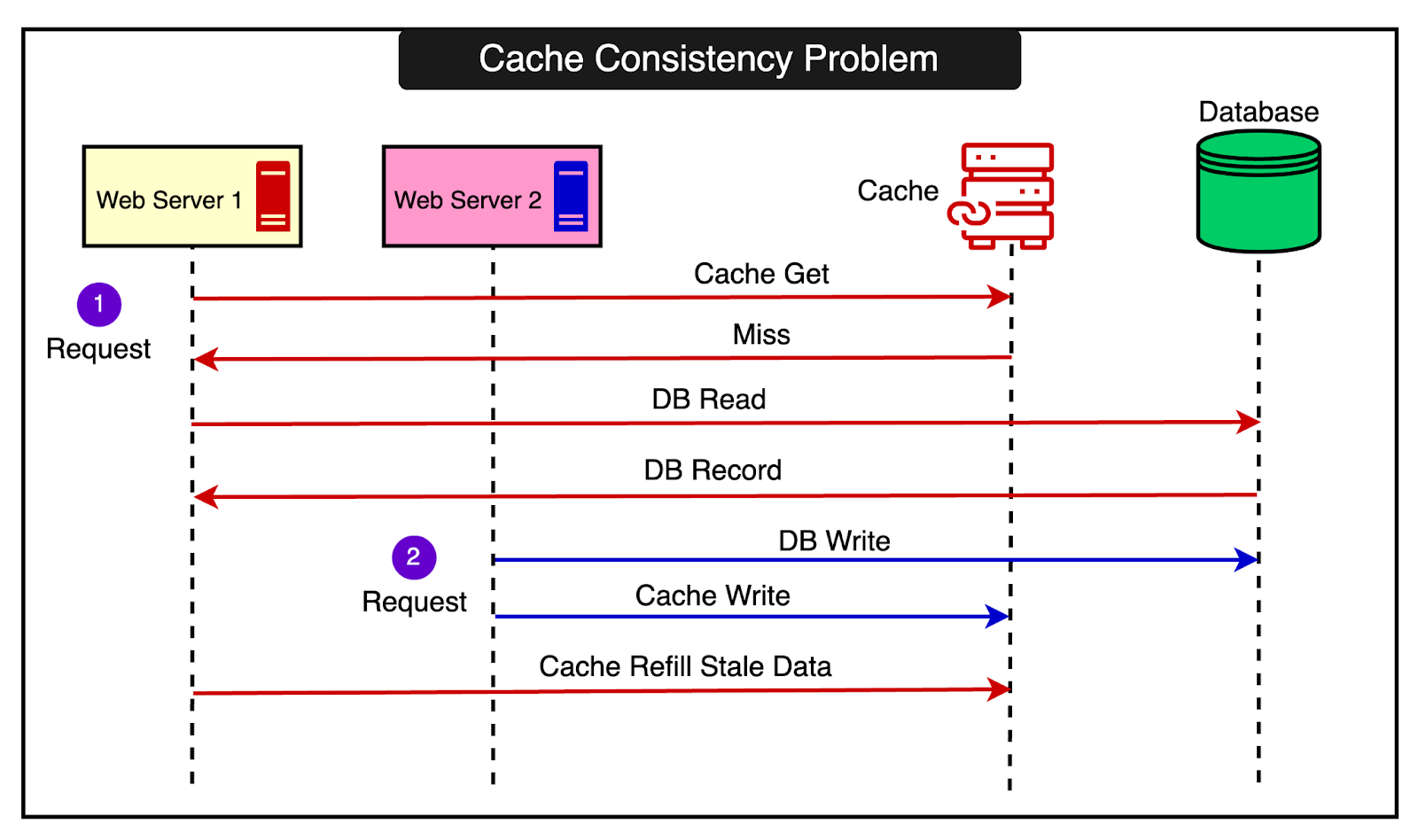
What’s going on over here?
Web Server 1 gets a cache miss and fetches data from the database.
A second request results in Web Server 2 performing a DB Write for the same data. It also updates the cache with the new data
Web Server 2 refills the cache with the stale data that it had fetched in step 1.
RevenueCat uses two main strategies to maintain cache consistency.
1 - Write Failure Tracking
In RevenueCat's system, a cache write failure is a strong signal that there may be an inconsistency between the cache and the primary store.
However, there are better options than simply retrying the write because that can lead to cascading failures and overload as discussed earlier.
Instead, RevenueCat's caching client records all write failures. After recording, it deduplicates them and ensures that the affected keys are invalidated in the cache at least once (retrying as needed until successful). This guarantees that the next read for those keys will fetch fresh data from the primary store, resynchronizing the cache.
This write failure tracking allows them to treat cache writes as if they should always succeed, significantly simplifying their consistency model. They can assume the write succeeded, and if it didn't, the tracker will ensure eventual consistency.
2 - Consistent CRUD Operations
For each type of data operation (Create, Read, Update, Delete), they have developed a strategy to keep the cache and primary store in sync.
For reads, they use the standard cache-aside pattern: read from the cache, and on a miss, read from the primary store and populate the cache. They always use an "add" operation to populate, which only succeeds if the key doesn't already exist, to avoid overwriting newer values.
For updates, they use a clever strategy as follows:
Before the update, they reduce the cache entry's TTL to a low value like 30 seconds
They update the primary data store
After the update, they update the cache with the new value and reset the TTL
If a failure occurs between steps 1 and 2, the cache remains consistent as the update never reaches the primary store. If a failure occurs between 2 and 3, the cache will be stale, but only for a short time until the reduced TTL expires. Also, any complete failures are caught by the write failure tracker that we talked about earlier.
For deletes, they use a similar TTL reduction strategy before the primary store delete.
However, for creation, they rely on the primary store to provide unique IDs to avoid conflicts.
Conclusion
RevenueCat’s approach illustrates the complexities of running caches at a massive scale. While some details may be specific to their Memcached setup, the high-level lessons are widely relevant.
Here are some key takeaways to consider from this case study:
Use low timeouts and fail fast on cache misses. Retries can cause cascading failures under load.
Plan cache capacity for failure scenarios. Ensure the system can handle multiple cache servers going down without overloading backends.
Use fallback and dedicated cache pools. Mirrored fallback pools and dedicated pools for critical data help keep caches warm and handle failures.
Handle hot keys through splitting or local caching. Distribute load from extremely popular keys across servers or cache them locally with low TTLs.
Avoid "thundering herds" with techniques like stale-while-revalidate and leasing.
Track and handle cache write failures. Assume writes always succeed but invalidate on failure to maintain consistency.
Implement well-tested strategies for cache updates during CRUD operations. Techniques like TTL reduction before writes help maintain consistency across cache and database.
References:
Scaling Smoothly: RevenueCat’s data-caching techniques for 1.2 billion daily API requests
How RevenueCat Manages Caching for Handling over 1.2 Billion API Requests
How Uber Serves Over 40 Million Reads Per Second from Online Storage Using Integrated Cache
SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com
