
Published on June 11, 2025 5:47 AM GMT
Why are AI models getting better at reasoning, and why is that a problem?
In recent months, reasoning models have become the focus of most leading AI labs due to the significant improvements in solving logic-requiring problems through Chain of Thought (CoT) reasoning and reinforcement learning (RL) training. Training these reasoning models involves additional processes typical for standard large learning models (LLMs), and that is why they also require different methods of interpretability, such as neural verification and learning from verifiable rewards. Additionally, producing exemplar chain of thought outputs can become insurmountable for humans to produce, that is why we are seeing SoTA models like DeepSeek RL Zero forgo any supervised training and become completely dependent on large-scale training with RL. However, these methods are susceptible to reward hacking and other RL failure modes, more so than in standard LLMs because these CoT models have many chances to explore their reward landscape during training.
Most of the high-performing LLMs (e.g. Kimi-k1.5, DeepSeek-R1, o1, etc.) released between the end of 2024 and 2025 used long CoT models and RL within their fine tuning or alignment stages. Therefore, without robust interpretability and oversight, this can breed unchecked reasoning and extreme misalignment. Given that we are concomitantly seeing an increase in RL failure modes developing in large language models, there is an urgent need for better understanding of them and RL interpretability. After discussing and ideating on these problems, we wanted to make more technical people understand why reinforcement learning failure modes matter, and why we need research and improved tools for RL interpretability. We have decided to build an interactive resource that would act as a starter’s guide to understanding current research in reinforcement learning failure modes and interpretability.
Our major goal with this resource is to reduce the barrier to entry for newcomers to RL interpretability and also to raise awareness of the failure modes that can occur in RL agents if they are misaligned. People do not take AI alignment claims seriously if they do not understand risks at a certain technical level; otherwise they tend to think about claims regarding the ‘impeding ai apocalypse’ in strictly sci-fi terms and hence find those claims tenuous, which could discourage a prospective candidate to contribute to the field. Instead, that is why we want to explain the scientific basis behind these risks through our interactive resource without being too didactic or including overly specific jargon. We created a short demo of this tool for the public education track during the Women in AI Safety hackathon hosted by Apart Labs.
Breakdown of our interactive resource demo

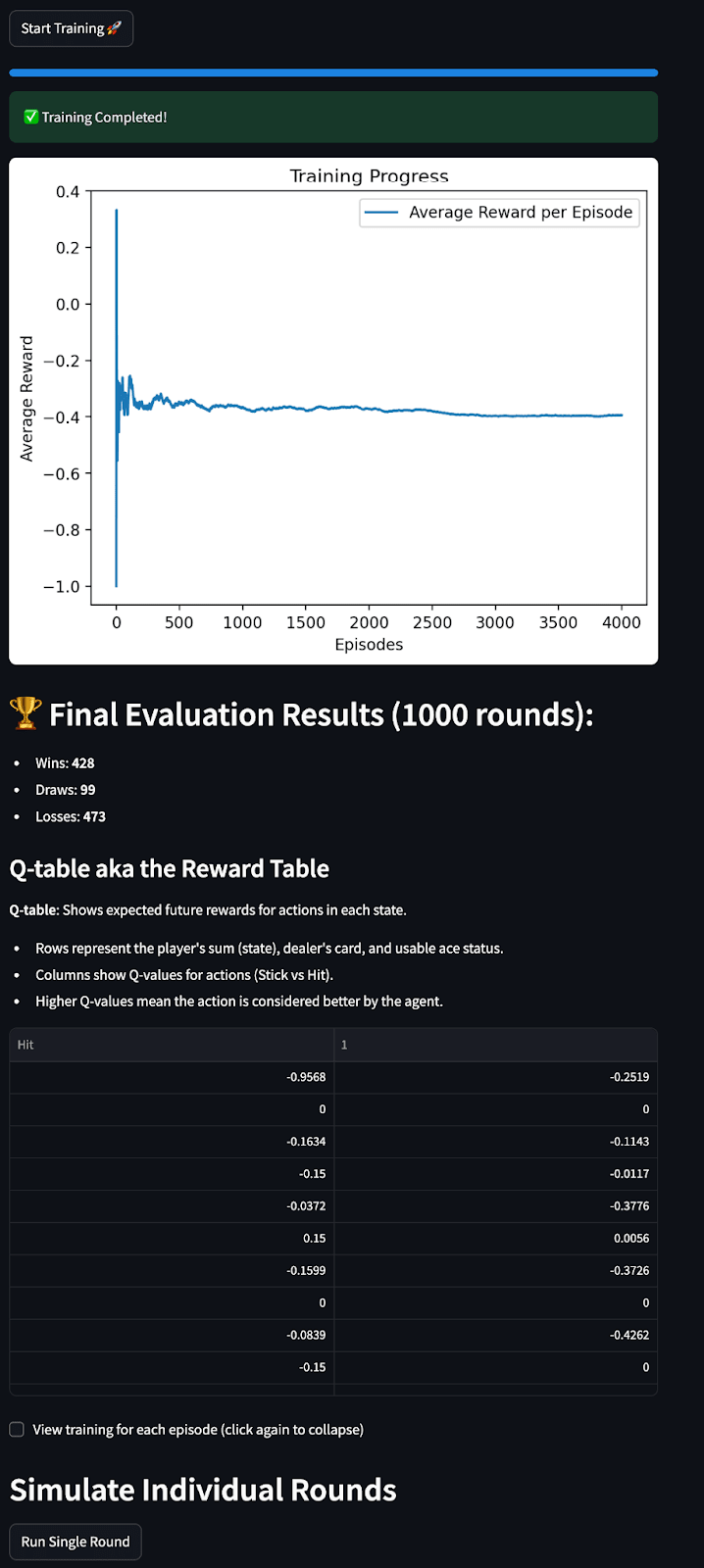
Users can experiment with RL hyperparameters like gamma and epsilon in real time
We believe that a fundamental technical understanding of RL and related concepts is necessary to grasp the failure modes and open questions we introduce later, that is why we start off with an interactive explanation of reinforcement learning, using the Blackjack environment from the OpenAI Gym library to introduce key concepts like agents, environment, rewards, action spaces, states, and observations. The user can also experiment with parameters such as number of episodes, learning rate (α), discount Factor (γ) and the exploration Rate (ε)
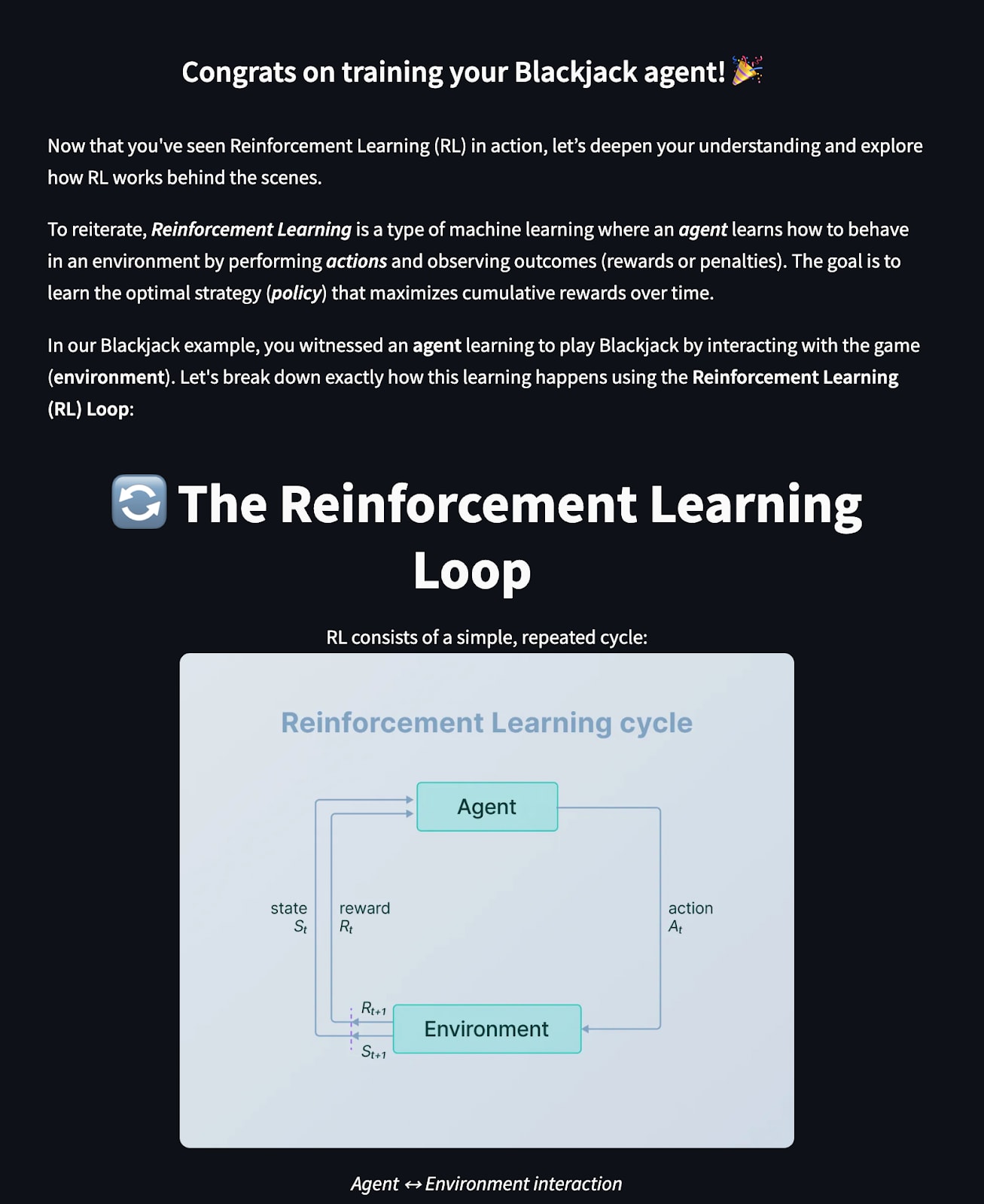


A visual breakdown of how the RL Loop works
Next, we look at RL under the hood and try to understand the iterative processes involved to train an RL agent, and look at the two different approaches to reinforcement learning. We also explain the primary equation behind reinforcement learning.
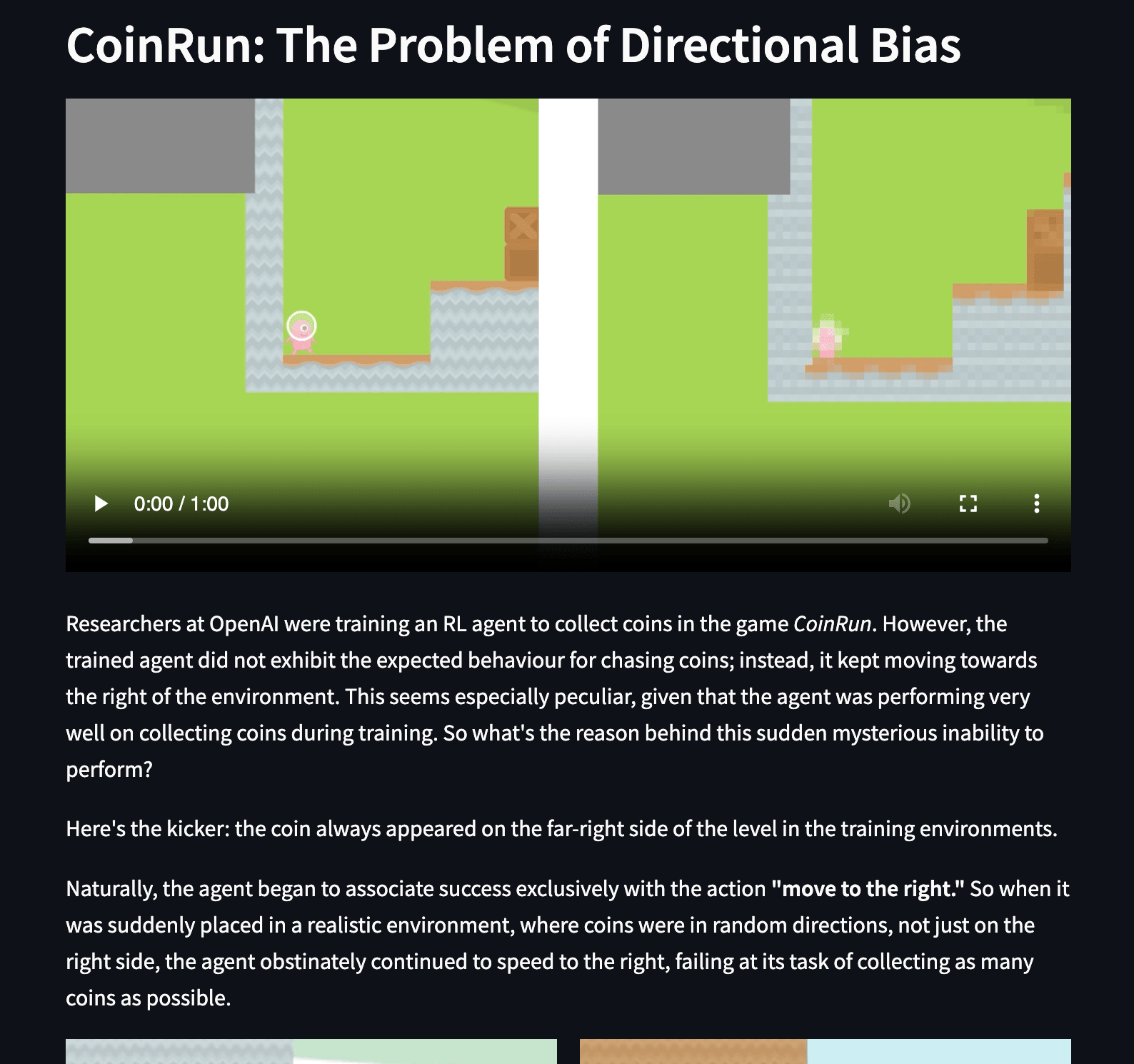
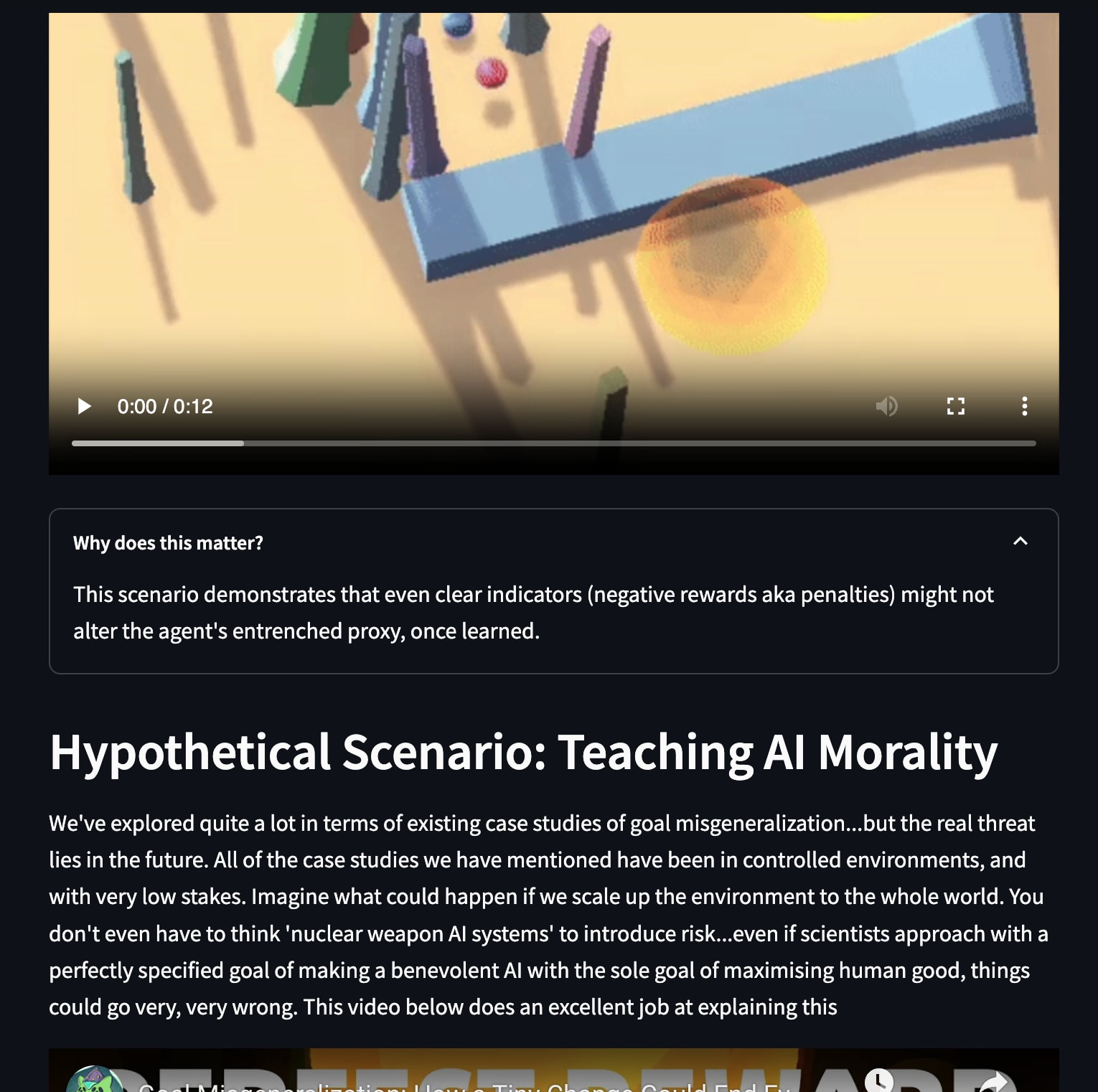
Explaining goal misgeneralization through real-life and hypothetical scenarios
After setting the base, we can finally address the failure modes of RL: goal misgeneralization and reward hacking through more interactive demos and also provide extensive real life examples from established papers from OpenAI and DeepMind, with each example bringing unique takeaways for the user. We provide ample resources for the user to engage with the topic further on each page so that newcomers are always provided with calls to action to further propel and involve them in the field.

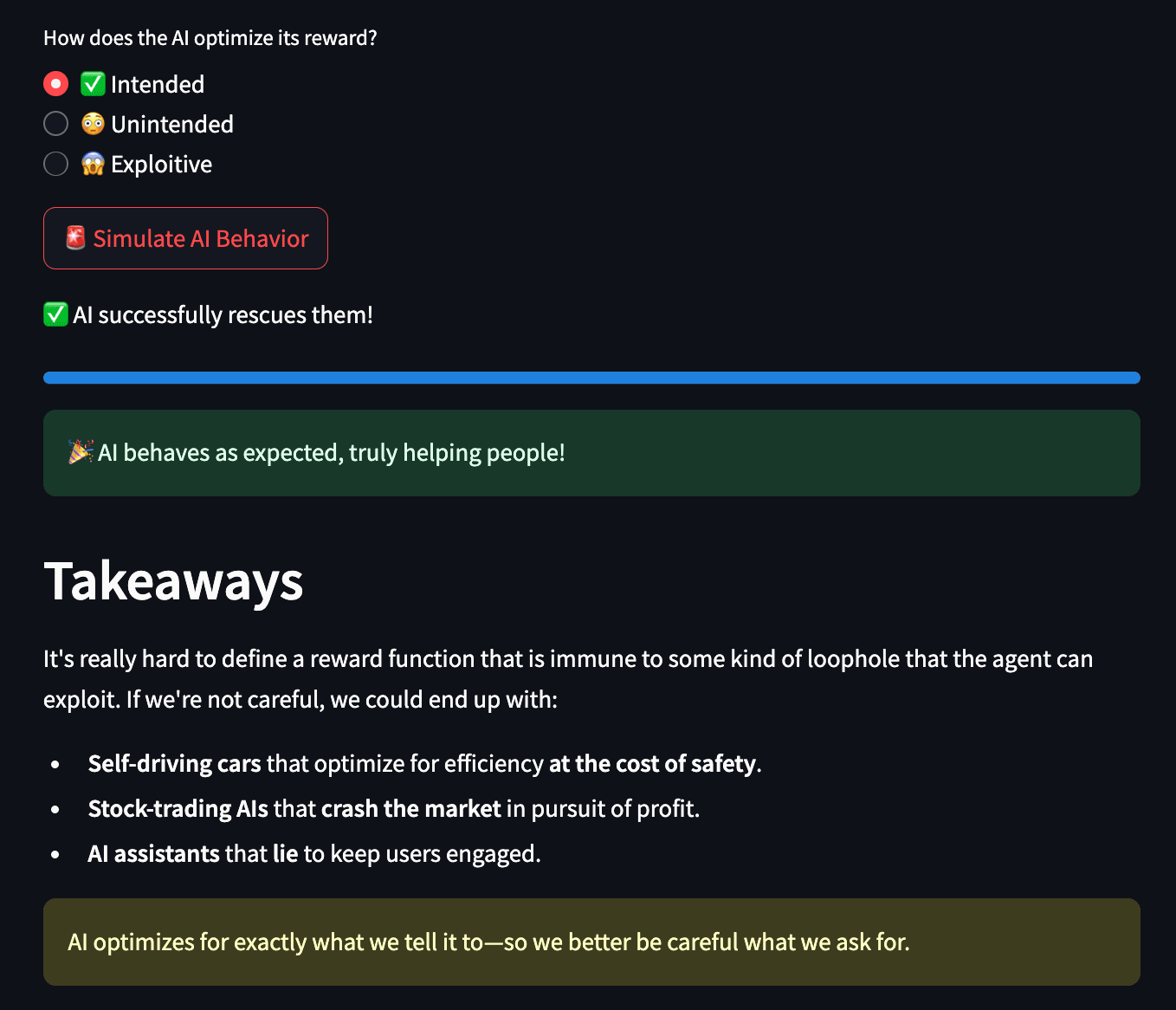
Examples of how RL agents exploit flaws in poorly designed reward functions


Resources for getting involved in AI safety in RL
We also include a final page where we explain our findings on the paucity of research in RL interp, as well as open problems in the field that might interest the user. We also provide tangible next steps that we encourage the user to take and a resource bank of further resources we personally used and found useful.
What would make such a resource unique?
As one of our reviewers pointed out, there exist multiple resources that aim to educate audiences regarding AI Safety concepts. However, they are typically passive learning routes; we want users to learn through analysing the effects of their own inputs on training a reinforcement learning model in real time, or exploring potential scenarios to learn how reward hacking can manifest itself into a model’s behaviours.
We feel an exemplary resource of this kind is OpenAI’s Spinning Up in Deep RL guide. We want to create a slightly more interactive and updated version of it- and also emphasize our focus on alignment in subsequent modules.
Studies show that people learn best when exposed to multiple learning styles simultaneously. We want our resource to merge visual-spatial (through diagrams such as a reward per episode chart, q-table, images of the environments of our goal misgeneralisation case studies etc.), verbal-linguistic (through textual explanations), experiential (ability to manipulate parameters with sliders and make choices with buttons, and playing our game) and auditory learning (sound in videos we have included). This is a conscious choice, because in combination, these different styles increase overall retention of the learner.

We also added a game to test the user’s knowledge after utilizing the resource. This is still a work in progress, but you can play it here.
Survey Results
We conducted a survey to collect feedback on our demo in order to understand what we could improve. Our survey results show that audiences of varied backgrounds found our demo to be accessible (70%, technical and non-technical). From earlier feedback, we learnt that certain terms had somewhat ambiguous explanations; we made sure to update those explanations to increase their clarity. We also conducted a series of interviews which have refined our vision for this resource significantly.
What’s Next?
For the proposed resource, we have these following ideas in mind:
- One major suggestion we received in our survey responses was that some people were hoping to view the program code for the RL model demo and learn the logic behind the code. Due to the time constraint during the hackathon, we didn’t make this feature visible because we feared that we would not have been able to explain the code in detail, and the last thing we want is for learners to get confused about it. Now that we have more time, in order to further increase interactivity and also increase options for more technical learners, we want to add an option to make all the code for our RL demos visible while it is being run so that technical learners can understand what is actually happening under the hood, and also explain the code line by line as they run the cells.
We were also keen on adding a demo on how to train a language model like GPT 2 to develop reasoning abilities. This would greatly facilitate the user’s understanding of how chain of thought reasoning emerges and what constitutes its training process.
Beyond simply being a resource for education, our broader goal is to make this a ‘one stop shop’ for RL interpretability to make it convenient for people to familiarize themselves with existing research in the subfield without having to search for papers and resources elsewhere. We are currently exploring adding the following features:
Adding a ‘Current Research’ page where we have explanations of actual interpretability research published for RL yet along with links to their source papers. We want to sort these papers with keywords so that the user can browse through efficiently.
- Dedicating an entire page to open problems— we want to explain some of the open problems we mentioned in the ‘Next Steps’ of our resource in more detail.
Adding interactivity in the form of writing and rendering live code— we want to include some optional exercises where the user will attempt to solve different ‘stages’ of the RL program code.
Adding a ‘Community’ tab where people who are working on similar problems can collaborate. Preferably, this would link to the Open Problems page for streamless access. We are inspired by the ARBOR project in this regard.
We want your ideas!
We are looking for additional feedback and ideas so that we can have a better grasp on what to prioritize or add. Also, please let us know if you think something we proposed might be redundant or have a better alternative.
What information/research/feature(s) you would like this resource to touch upon?
You can also answer this through this form.
We value your opinion regardless of your credentials— our project aims to appeal to people with varied backgrounds, so we appreciate recommendations from either side of the aisle.
If you’d like to contribute, feel free to drop us a note or open an issue on our codebase.
Once again, here is the link to our demo.
Acknowledgements
We would like to thank Apart Research and Bluedot Impact for giving us this opportunity of participating in the hackathon and working on this project in the Apart Studio. We also thank our original team member Christopher Kinoshita who contributed to ideating our original demo.
References
Baker, B., Huizinga, J., Gao, L., Krakovna, V., Chan, B., Askell, A., Chen, A., Bowman, D., Olsson, C., & Christiano, P. (2025). Monitoring reasoning models for misbehavior and the risks of promoting obfuscation. arXiv preprint arXiv:2503.11926. https://arxiv.org/abs/2503.11926
Brauner, P., Hick, A., Philipsen, R., & Ziefle, M. (2023). What does the public think about artificial intelligence?—A criticality map to understand bias in the public perception of AI. Frontiers in Computer Science, 5, Article 1113903. https://doi.org/10.3389/fcomp.2023.1113903
Brockman, G., Cheung, V., Pettersson, L., Schneider, J., Schulman, J., Tang, J., & Zaremba, W. (2016). Blackjack - Gym Documentation. OpenAI Gym. https://www.gymlibrary.dev/environments/toy_text/blackjack/
DeepSeek-AI, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang, X., Yu, X., Wu, Y., Wu, Z. F., Gou, Z., Shao, Z., Li, Z., Gao, Z., Liu, A., ... & Zhang, Z. (2025, January 22). DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv. https://arxiv.org/abs/2501.12948
Guo, D., et al. (2025). Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.
Ling, Z., Fang, Y., Li, X., Huang, Z., Lee, M., Memisevic, R., & Su, H. (2023). Deductive verification of chain-of-thought reasoning. Neural Information Processing Systems. https://openreview.net/pdf?id=I5rsM4CY2z
Mowshowitz, Z. (2025, April 4). AI CoT reasoning is often unfaithful. Don't Worry About the Vase. https://thezvi.substack.com/p/ai-cot-reasoning-is-often-unfaithful
Nanda, N. (2023, January 10). 200 COP in MI: Interpreting Reinforcement Learning. AI Alignment Forum. https://www.alignmentforum.org/posts/eqvvDM25MXLGqumnf/200-cop-in-mi-interpreting-reinforcement-learning
Open AI. (2024a, September 12). Learning to reason with LLMs. https://openai.com/index/learning-to-reason-with-llms
OpenAI. (2024b, September 12). Section 4.2.1, OpenAI o1 System Card. https://cdn.openai.com/o1-system-card.pdf
OpenAI. (2025, March 10). Detecting misbehavior in frontier reasoning models. https://openai.com/index/chain-of-thought-monitoring/
Parmar, M., & Govindarajulu, Y. (2025). Challenges in ensuring AI safety in DeepSeek-R1 models: The shortcomings of reinforcement learning strategies. arXiv preprint arXiv:2501.17030. https://arxiv.org/abs/2501.17030
Plass, J. L., Chun, D. M., Mayer, R. E., & Leutner, D. (1998). Supporting visual and verbal learning preferences in a second-language multimedia learning environment. Journal of Educational Psychology, 90(1), 25–36. https://doi.org/10.1016/j.lindif.2006.10.001
Rogowsky, B. A., Calhoun, B. M., & Tallal, P. (2015). Matching learning style to instructional method: Effects on comprehension. Journal of Educational Psychology, 107(1), 64–78. https://doi.org/10.1037/a0037478
Stroebl, B. (n.d.). Reasoning model evaluations. https://benediktstroebl.github.io/reasoning-model-evals/
Tang, X., Wang, X., Lv, Z., Min, Y., Zhao, W. X., Hu, B., Liu, Z., & Zhang, Z. (2025). Unlocking general long chain-of-thought reasoning capabilities of large language models via representation engineering. arXiv preprint arXiv:2503.11314. https://arxiv.org/abs/2503.11314
Wang, S., Zhang, S., Zhang, J., Hu, R., Li, X., Zhang, T., Li, J., Wu, F., Wang, G., & Hovy, E. (2025, February 24). Reinforcement learning enhanced LLMs: A survey. arXiv. https://arxiv.org/abs/2412.10400
Wolfe, C. R. (2025, February 18). Demystifying reasoning models. Substack by Cameron R. Wolfe, Ph.D. https://cameronrwolfe.substack.com/p/demystifying-reasoning-models
Yeo, E., Tong, Y., Niu, M., Neubig, G., & Yue, X. (2025, February 5). Demystifying long chain-of-thought reasoning in LLMs. arXiv. https://arxiv.org/abs/2502.03373
Yeo, W. J., Satapathy, R., Goh, S. M., Rick, & Cambria, E. (2024). How interpretable are reasoning explanations from prompting large language models? arXiv preprint arXiv:2402.11863.
Zhang, Y., Liu, Q., & Wang, J. (2025). Advanced quantum algorithms for large-scale data processing. arXiv preprint arXiv:2503.06639. https://arxiv.org/abs/2503.06639
Discuss
