
WorkOS AuthKit: Simplify Auth in Your Next.js App (Sponsored)

Building auth in Next.js means managing redirects, handling tokens and sessions, and making sure it all works across routes—even in edge environments like Vercel.
WorkOS AuthKit solves this with a fully hosted login UI that supports SSO, MFA, passwordless auth, and password-based login. It handles redirects, token exchange, and session logic with minimal config.
Install the SDK, configure your redirect URI, and initialize the AuthKitProvider. AuthKit handles login and session logic from there.
This week’s system design refresher:
Trillions of Web Pages: Where Does Google Store Them? (Youtube video)
How Do Companies Ship Code to Production?
What is Event Sourcing?
How Data Lake Architecture Works
How Netflix Built a Distributed Counter
How TCP Handshake Works?
Early teams hiring engineers
SPONSOR US
Trillions of Web Pages: Where Does Google Store Them?
How Do Companies Ship Code to Production?
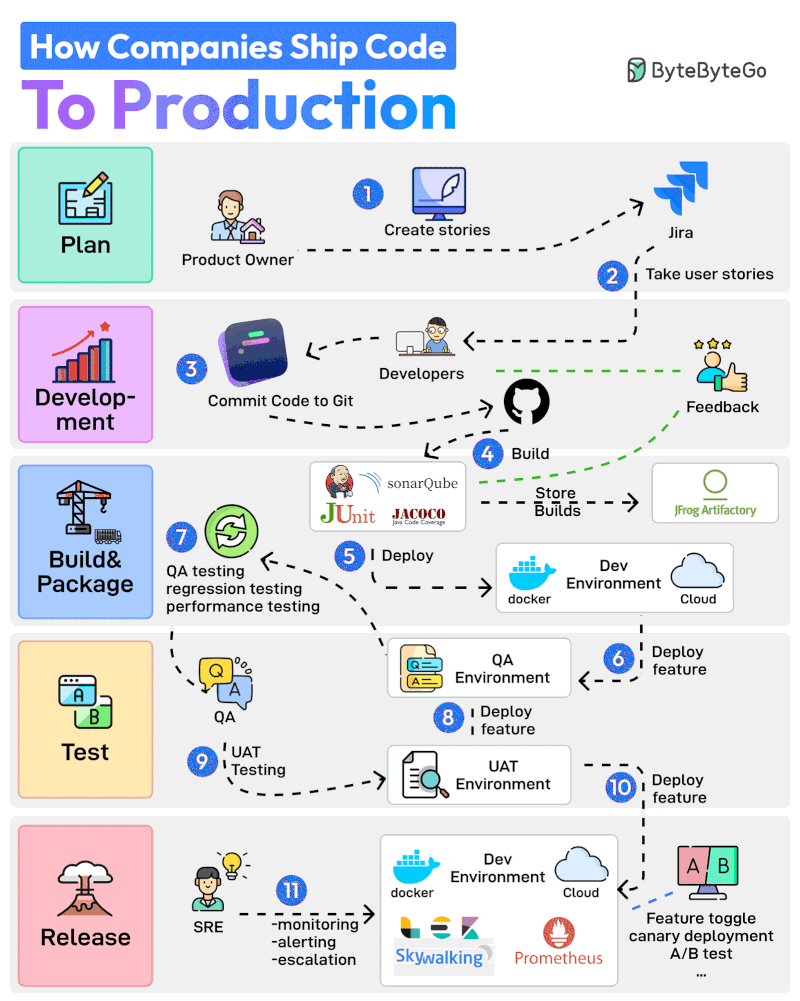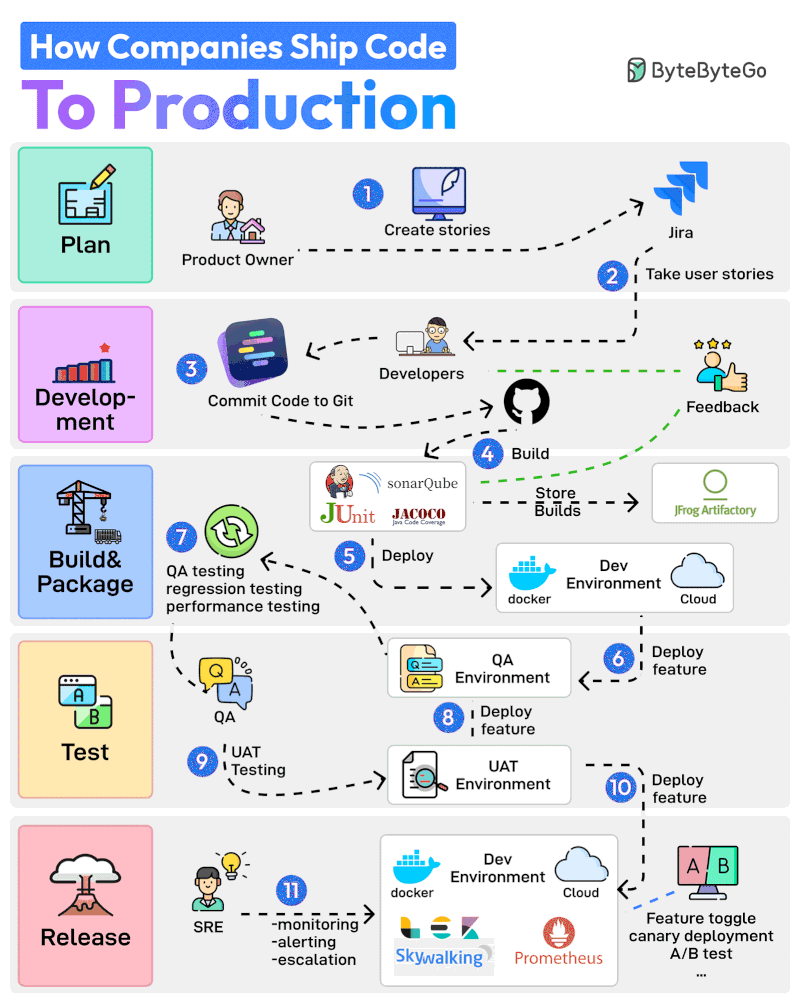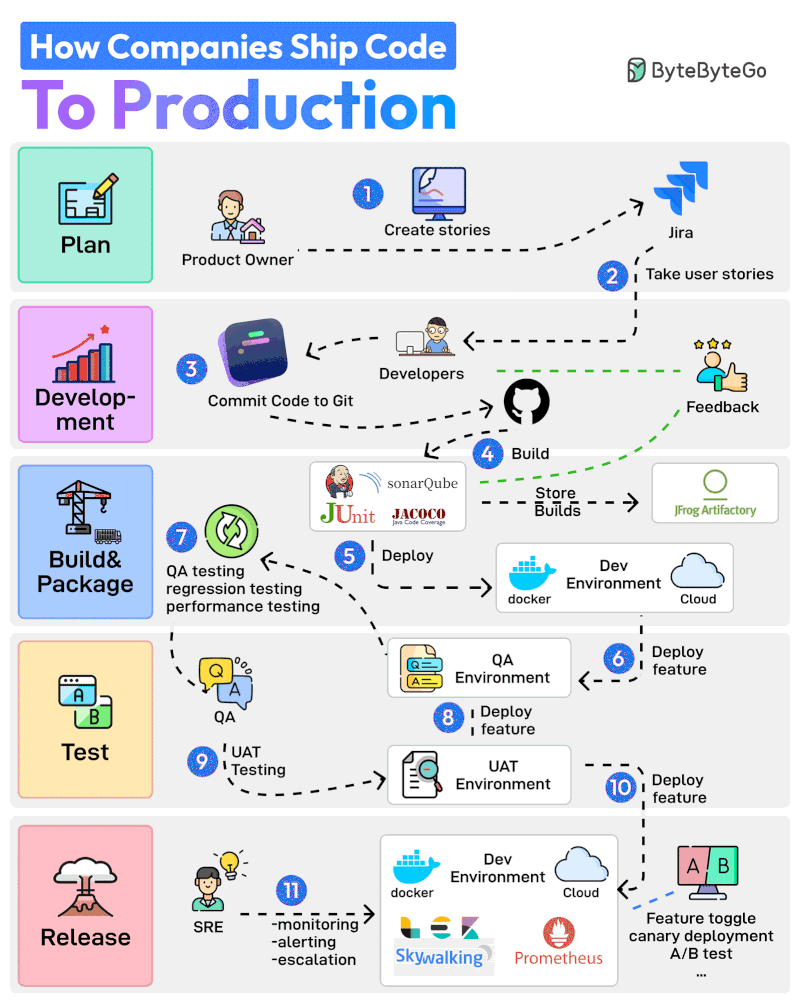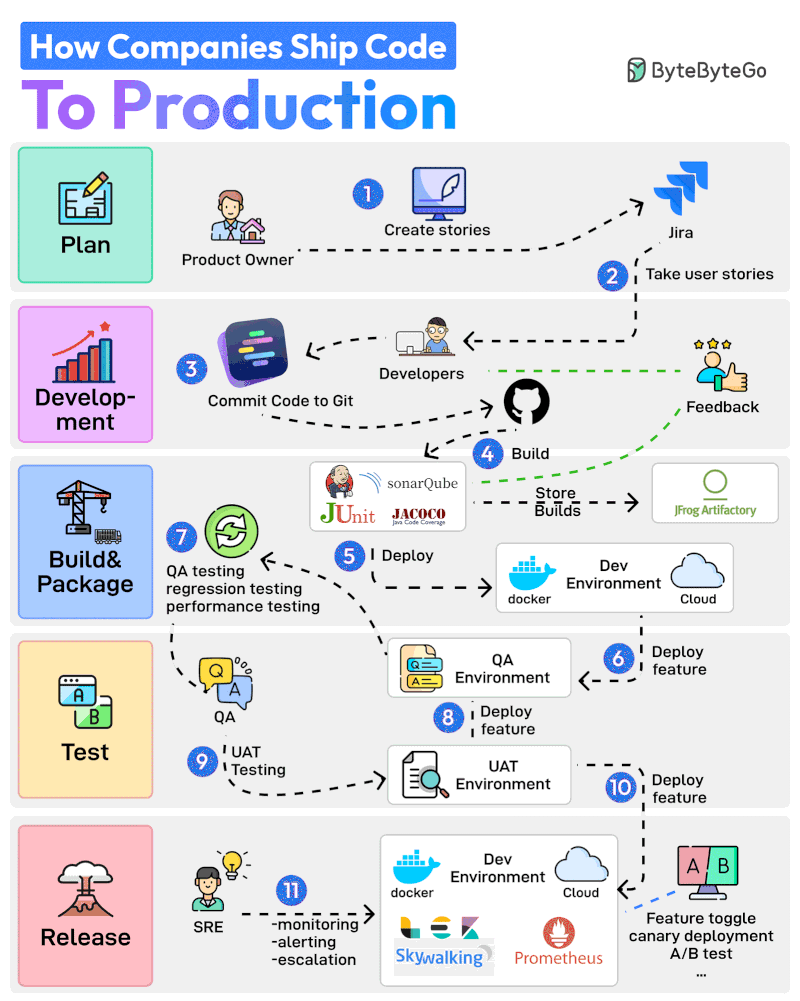
Here are 11 steps from planning to production:
The Product Owner starts the entire process by creating user stories in a tool like Jira.
The Developer Team performs Sprint Planning activity and adds the user stories to the sprint.
Developers work on the assigned stories. Once a story is finished, they commit the code to Git and push it to GitHub.
Jenkins builds and runs the code through testing and quality check tools such as JUnit, Jacoco, and SonarQube.
If the build is successful, it is stored in the artifactory such as JFrog. Jenkins also deploys the build to the Dev Environment via Docker.
Next up, the feature gets deployed to the QA environment. Since multiple teams may be working on the same code base, multiple QA environments will be created
The QA team uses a particular QA environment and runs multiple test types such as QA, regression, and performance.
Once the QA verification is complete, features are deployed to the UAT (User Acceptance Testing) environment.
UAT testing verifies whether the feature satisfies the user’s requirements.
Once the UAT testing is successful, the builds become release candidates. They are deployed to the production environment based on a specific schedule.
The SRE team uses tools like ELK and Prometheus to monitor the production environment and handle alerts in case of issues.
Over to you: Will you add any other steps to the process?
What is Event Sourcing? How is it different from normal CRUD design?
The diagram below shows a comparison of normal CRUD system design and event sourcing system design. We use an order service as an example.
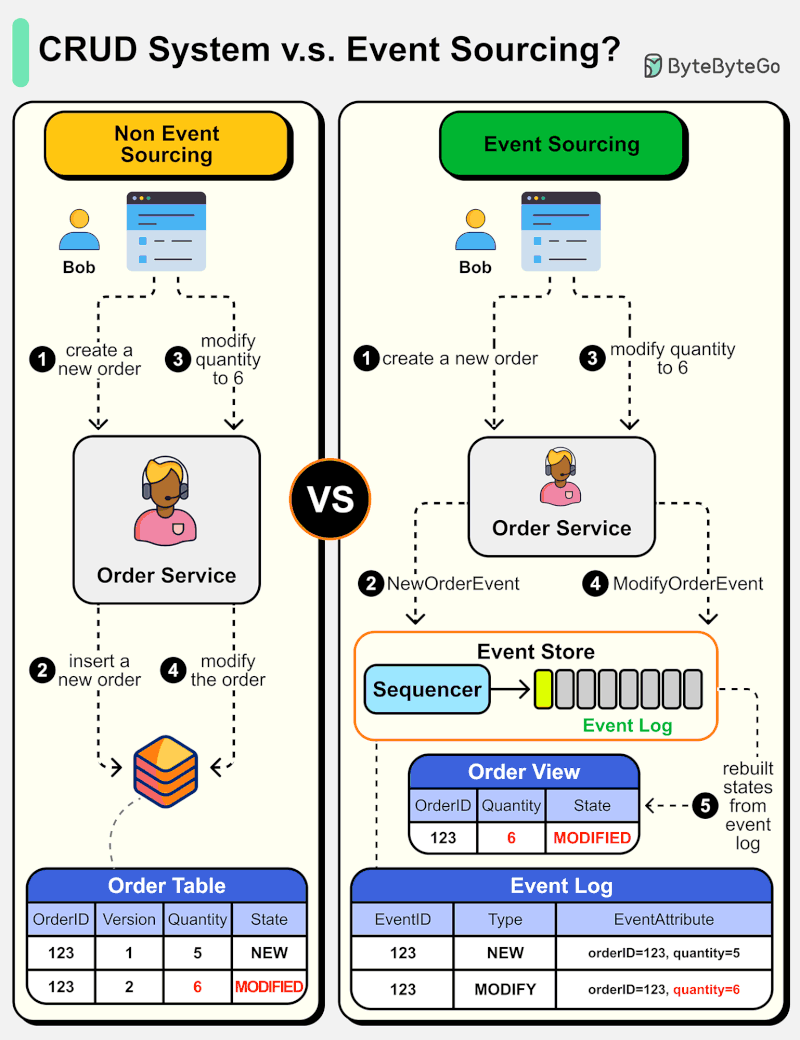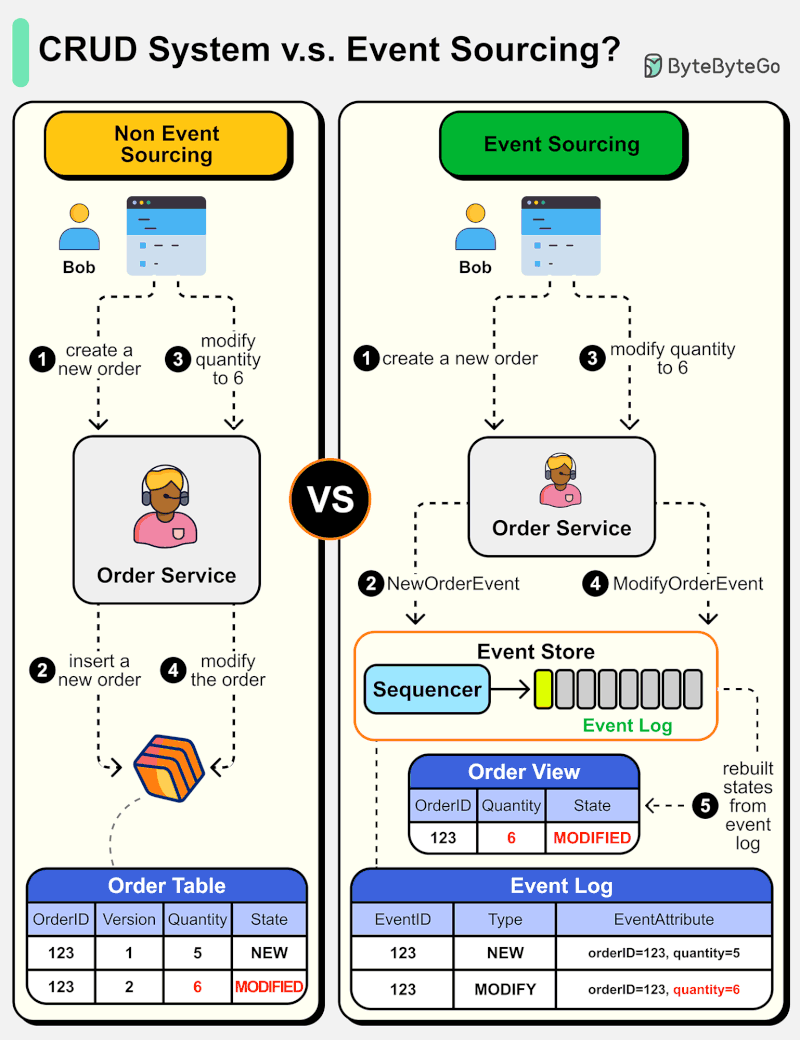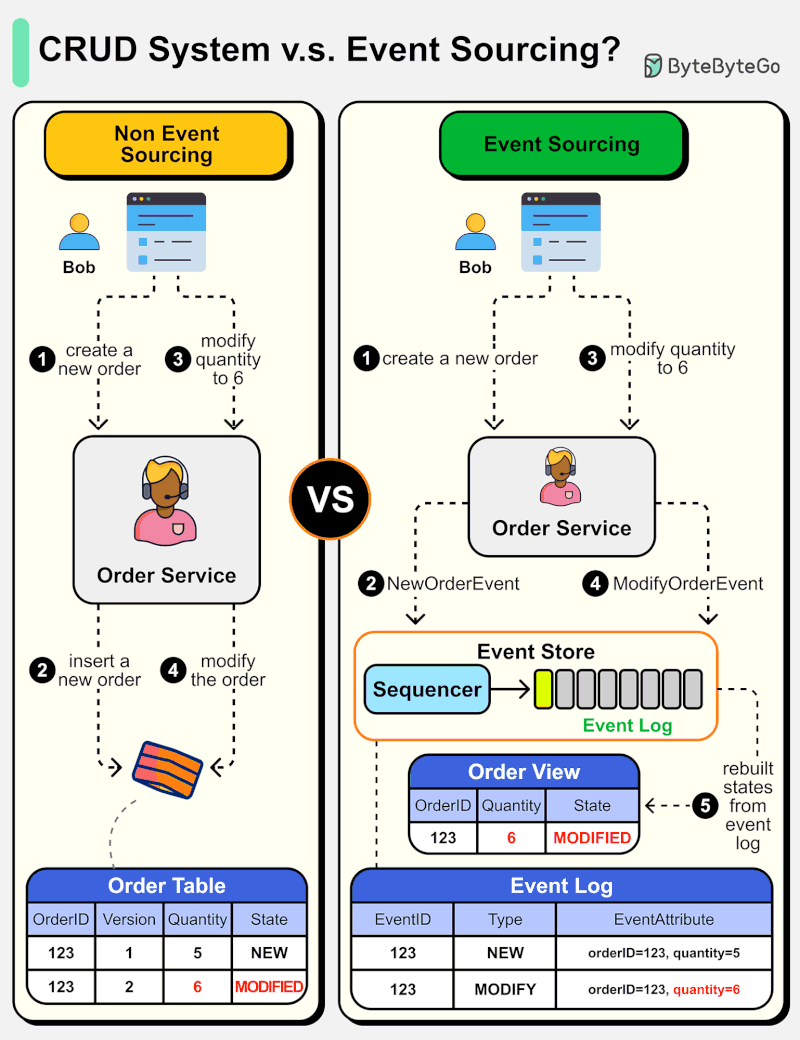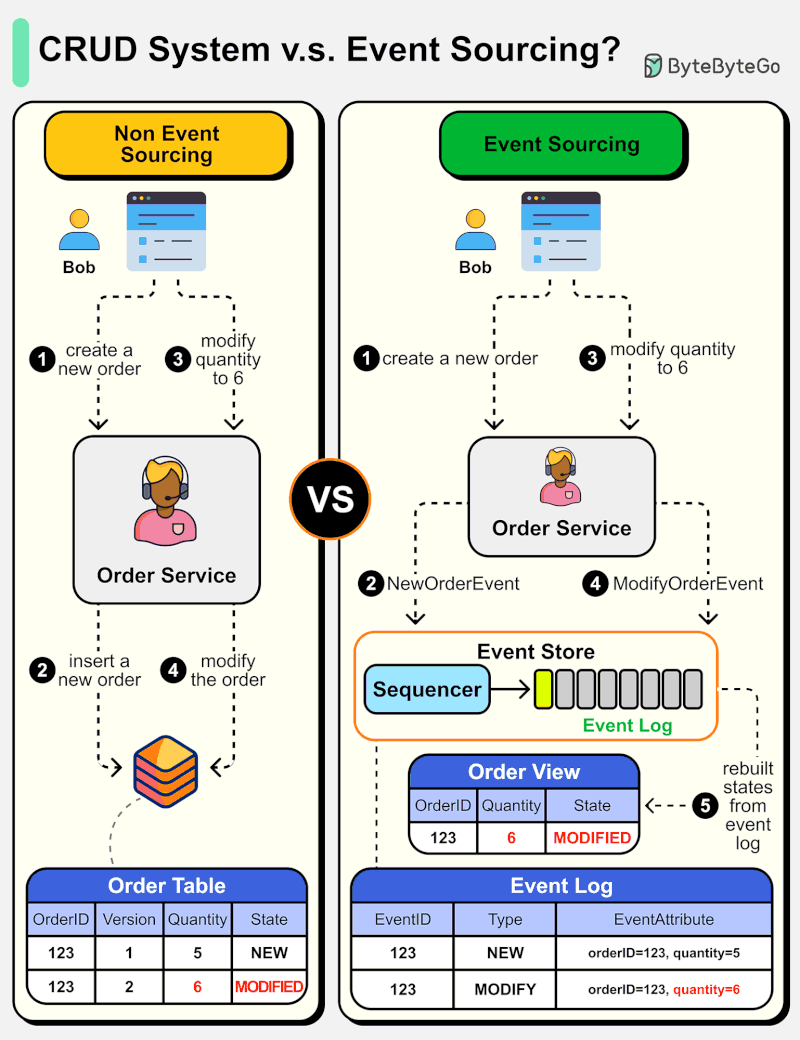
The event sourcing paradigm is used to design a system with determinism. This changes the philosophy of normal system designs.
How does this work? Instead of recording the order states in the database, the event sourcing design persists the events that lead to the state changes in the event store. The event store is an append-only log. The events must be sequenced with incremental numbers to guarantee their ordering. The order states can be rebuilt from the events and maintained in OrderView. If the OrderView is down, we can always rely on the event store which is the source of truth to recover the order states.
Let's look at the detailed steps.
Non-Event Sourcing
Steps 1 and 2: Bob wants to buy a product. The order is created and inserted into the database.
Steps 3 and 4: Bob wants to change the quantity from 5 to 6. The order is modified with a new state.
Event Sourcing
Steps 1 and 2: Bob wants to buy a product. A NewOrderEvent is created, sequenced, and stored in the event store with eventID=321.
Steps 3 and 4: Bob wants to change the quantity from 5 to 6. A ModifyOrderEvent is created, sequenced, and persisted in the event store with eventID=322.
Step 5: The order view is rebuilt from the order events, showing the latest state of an order.
Over to you: Which type of system is suitable for event sourcing design? Have you used this paradigm in your work?
How Data Lake Architecture Works?
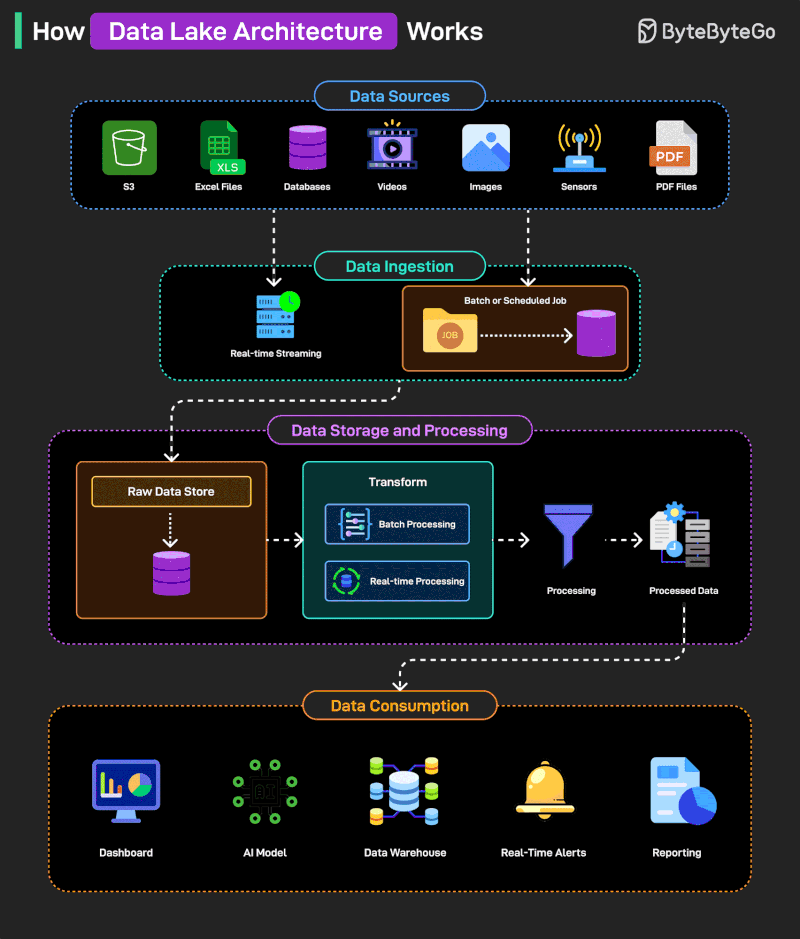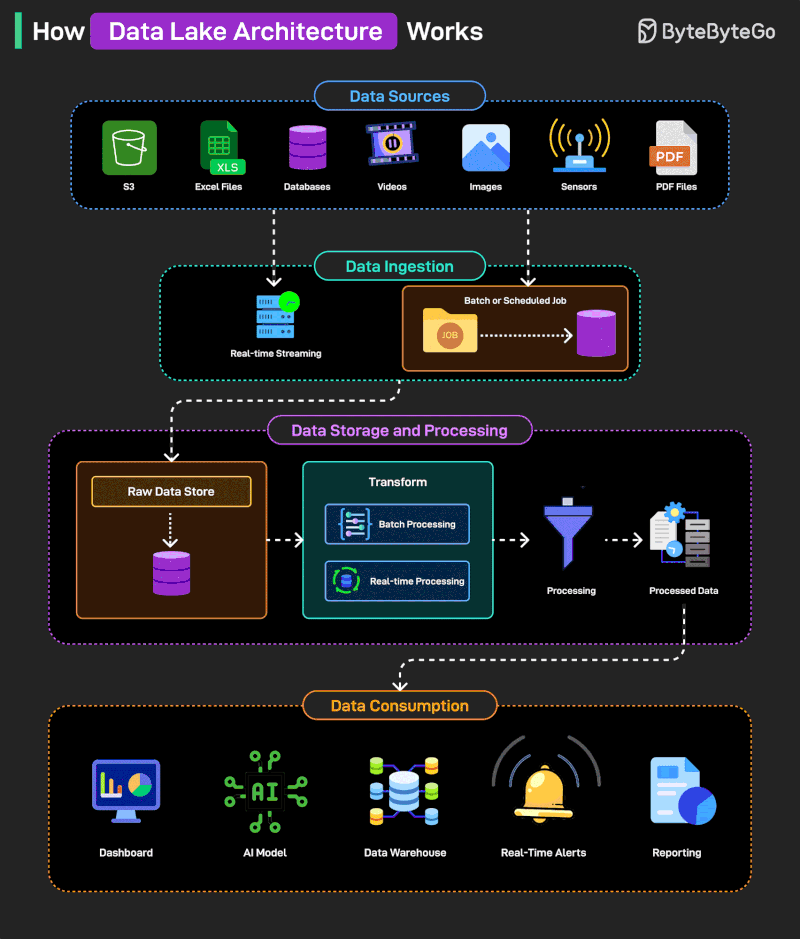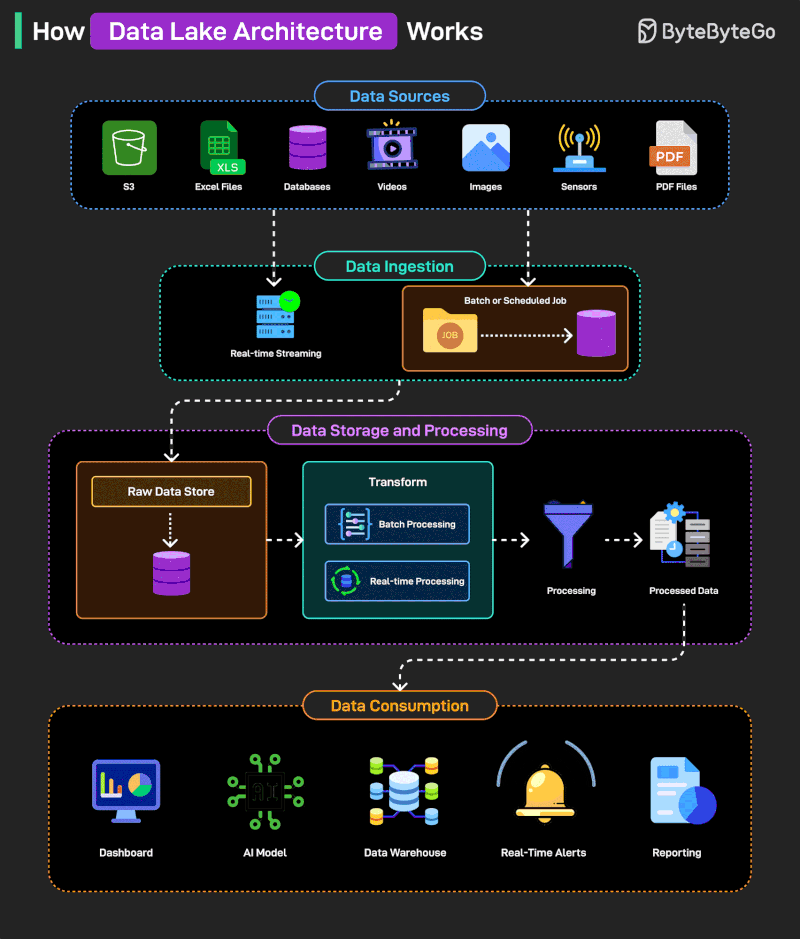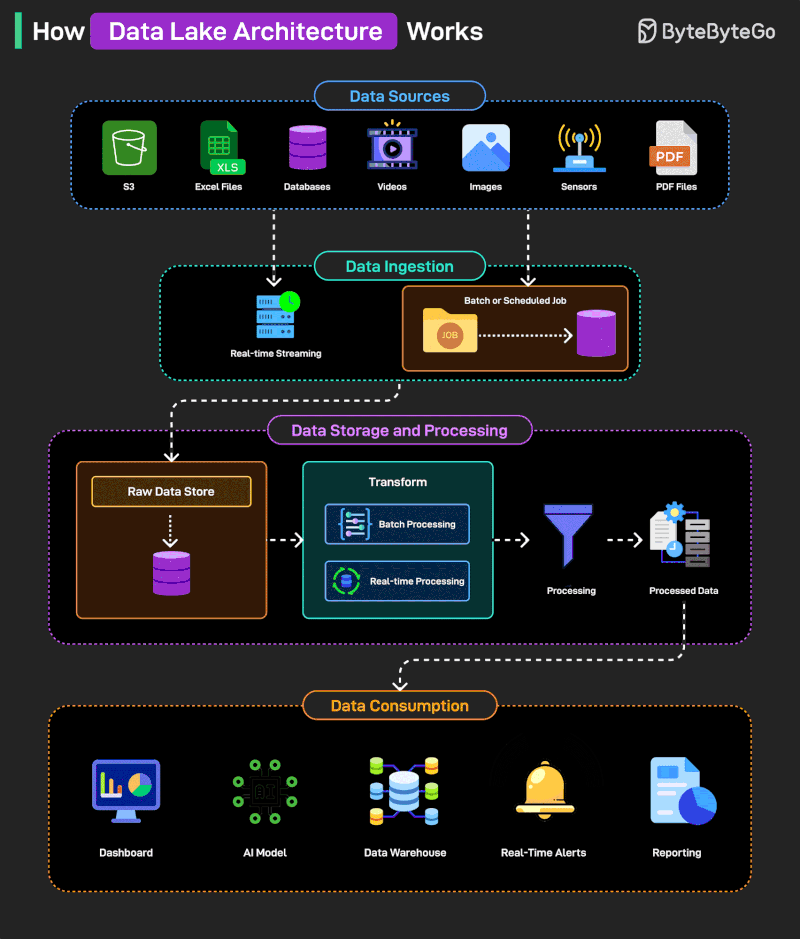
A data lake is a centralized storage system that holds large volumes of structured, semi-structured, and unstructured data in its raw form. It allows organizations to store data at scale and process it later for different requirements.
Here’s how it works on a high level:
Data from diverse sources like S3, Excel files, databases, videos, images, sensors, and PDFs is collected for ingestion.
Ingestion happens via real-time streaming or batch/scheduled jobs, depending on the data type and source.
Ingested data is first stored in a raw data store before any transformation or processing occurs.
Data is then processed through batch or real-time processing systems to clean, transform, and prepare it for use.
The processed data is stored and made ready for downstream consumption by various tools and platforms.
Final data consumption happens through dashboard, AI models, data warehouse, real-time alerts, and reporting systems.
Over to you: What else will you add to better understand the Data Lake Architecture?
How Netflix Built a Distributed Counter
The Netflix distributed counter is a masterclass for learning system design.
A Distributed Counter is a system where the responsibility of counting events is spread across multiple servers or nodes in a network. Netflix needs to track and measure multiple user interactions to make real-time decisions and optimize its infrastructure.
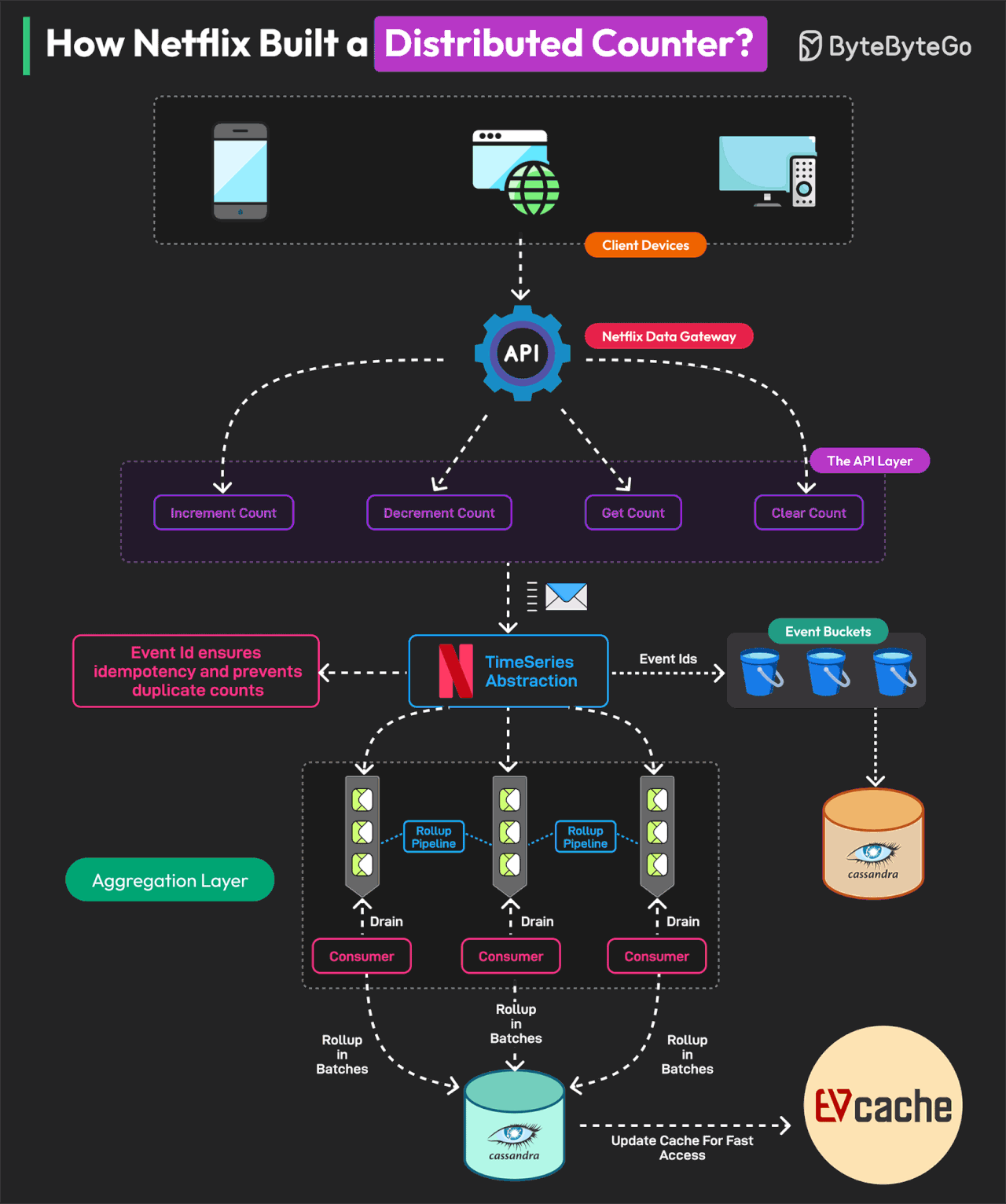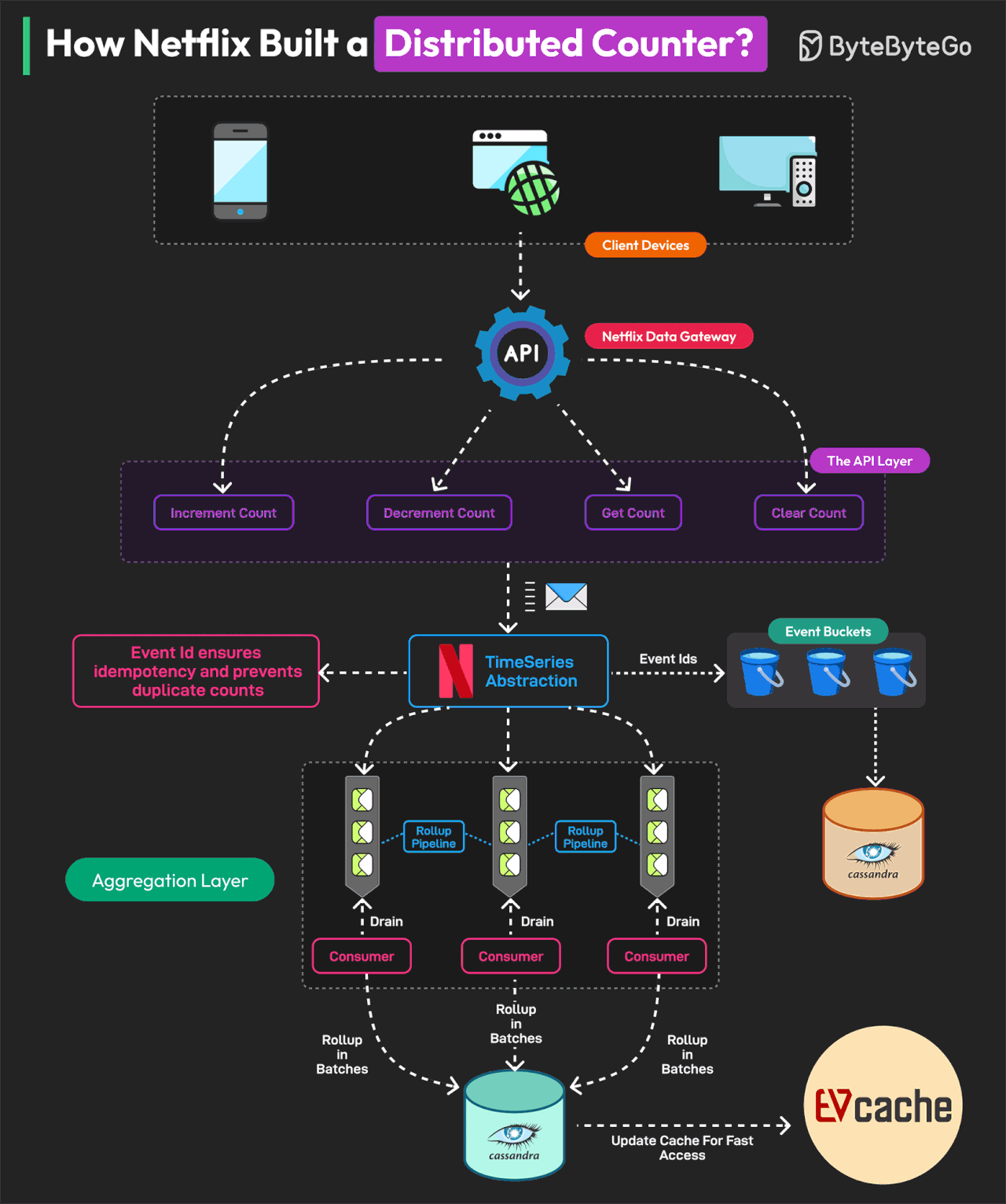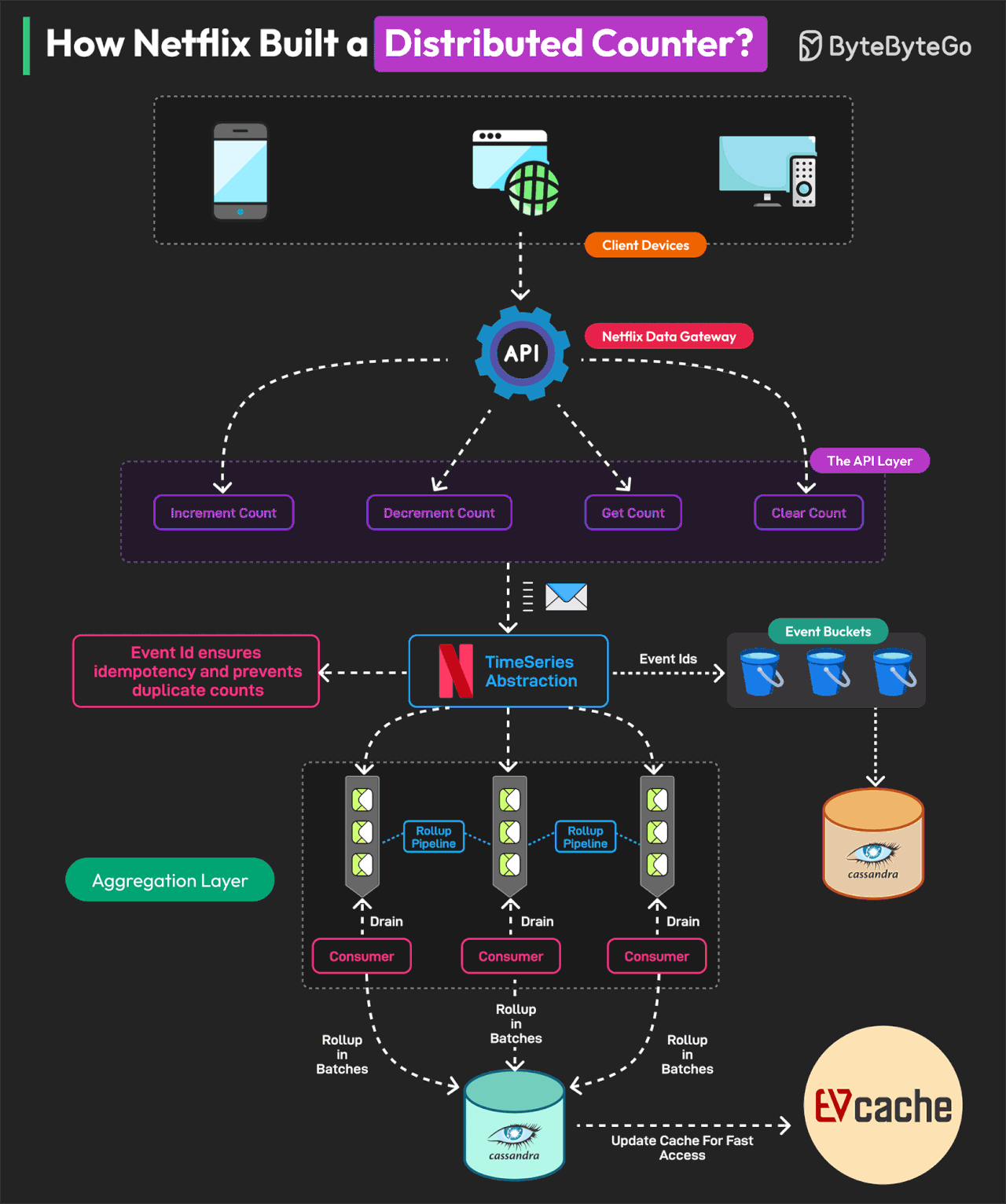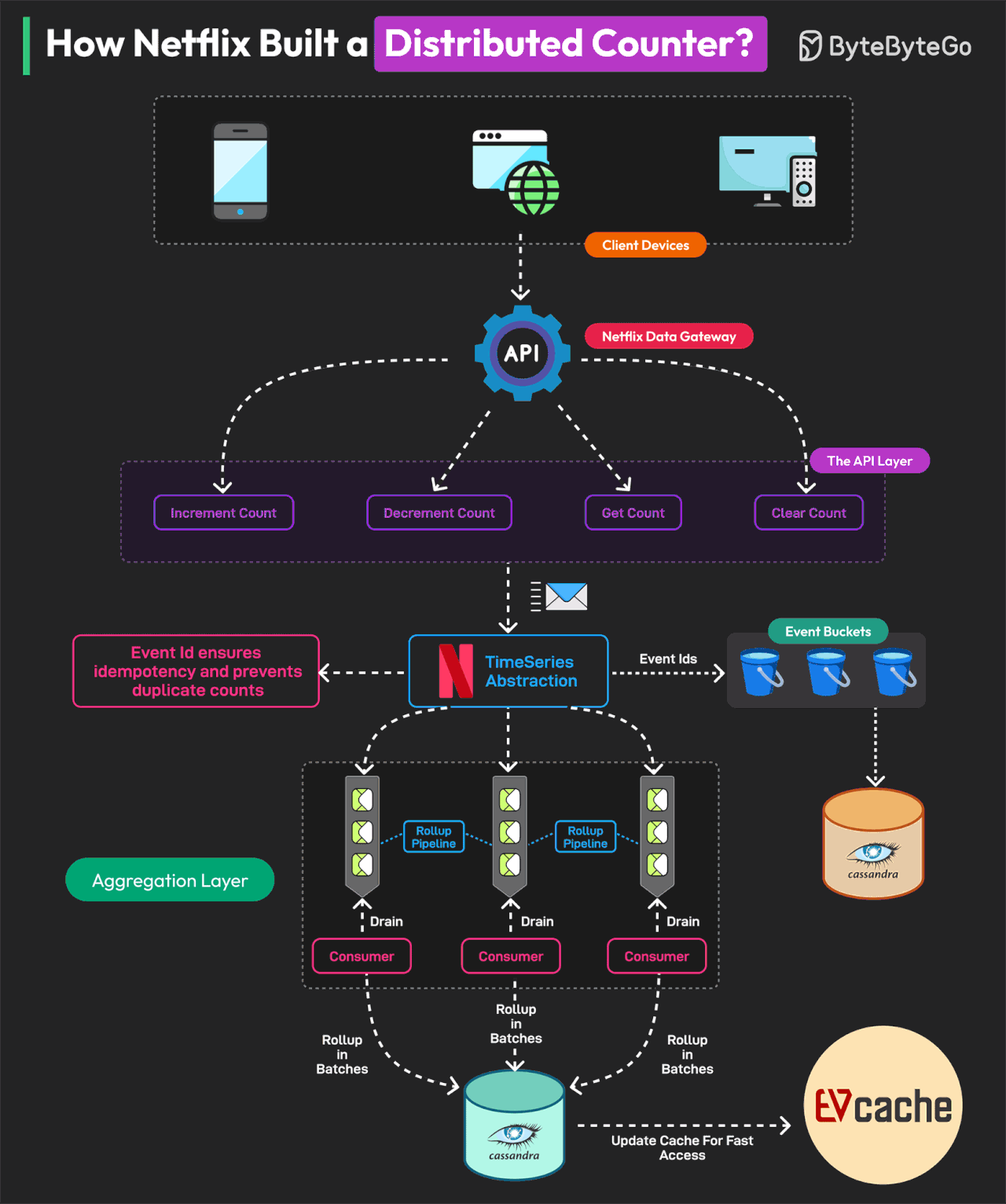
For this reason, they built a Distributed Counter Abstraction.
Netflix’s Distributed Counter Abstraction operates in four main layers, ensuring high performance, scalability, and eventual consistency.
Client API Layer
Users interact with the system by sending AddCount, GetCount, or ClearCount requests. The Netflix Data Gateway efficiently processes and routes these requests.
Event Logging and TimeSeries Storage
Events are stored in Netflix TimeSeries Abstraction for scalability. Each event is tagged with an Event ID to ensure idempotency. To avoid database contention, events are grouped into time partitions known as buckets. Data is stored in Cassandra.
Rollup Pipeline or Aggregation
Rollup Queues collect event changes and process them in batches. Aggregation occurs in immutable time windows, ensuring accurate rollup calculations. Data is stored in the Cassandra Rollup Store for eventual consistency.
Read Optimization (Cache & Query Handling)
Aggregated counter values are cached in EVCache for ultra-fast reads. If a cache value is stale, a background rollup refresh updates it. This model allows Netflix to process 75K requests per second with single-digit millisecond latency.
Reference: Netflix’s Distributed Counter Abstraction
How TCP Handshake Works?
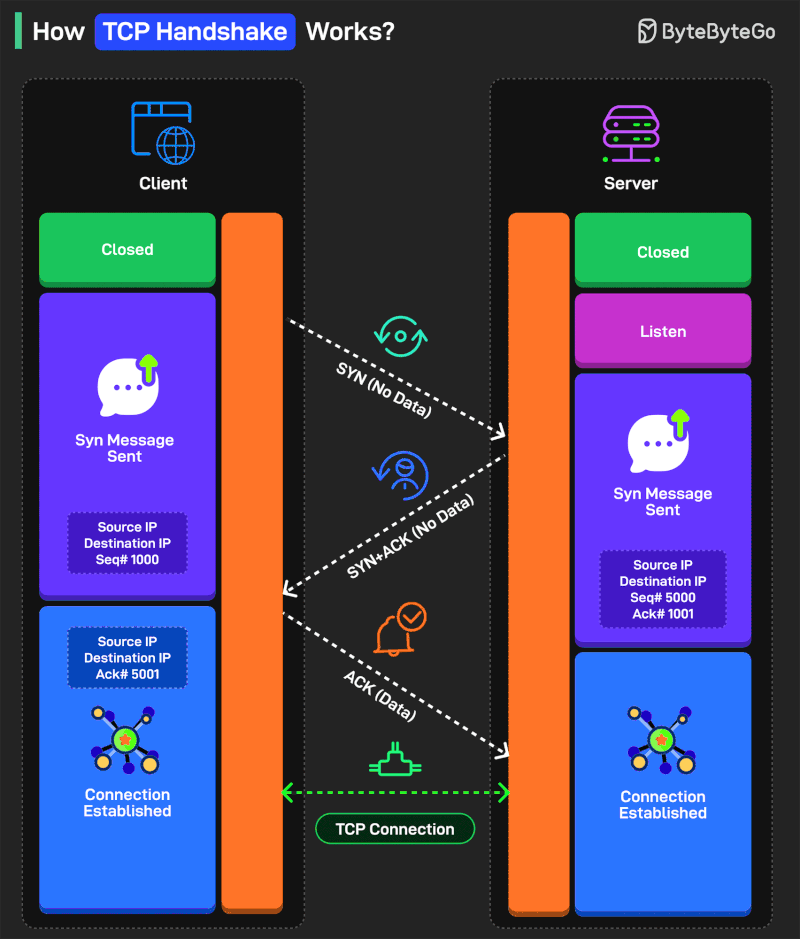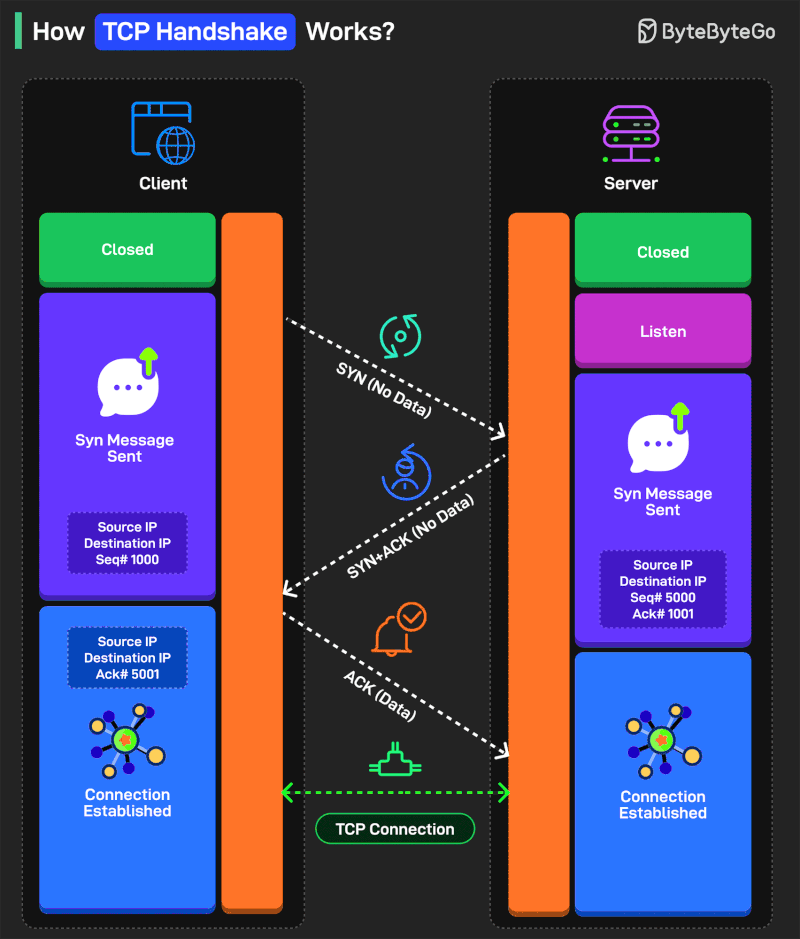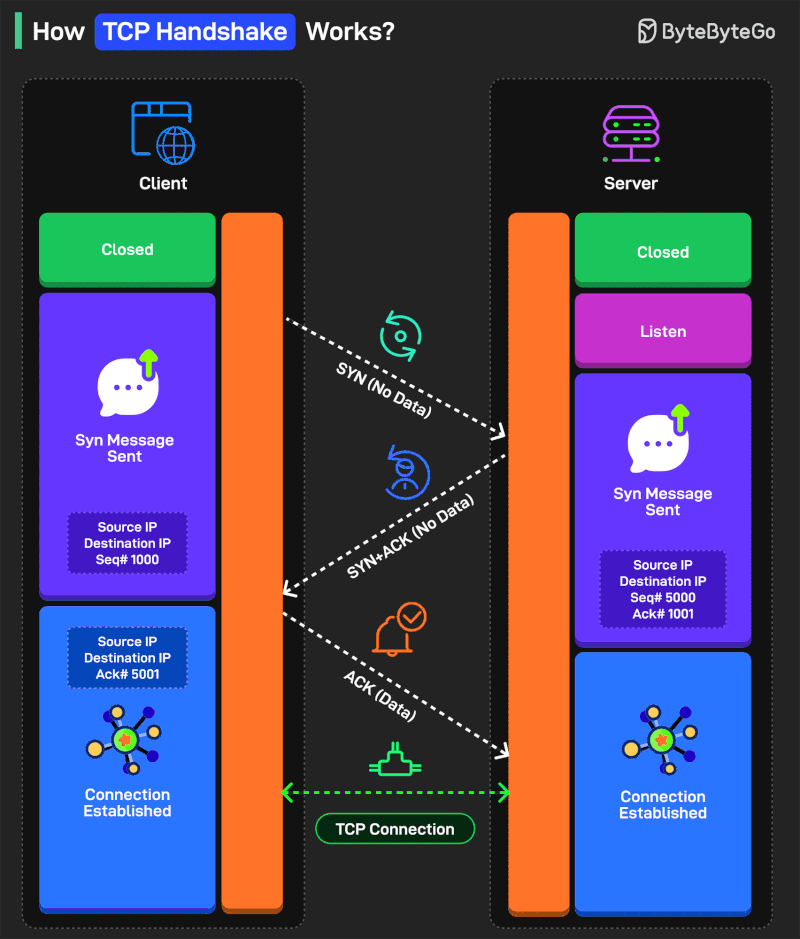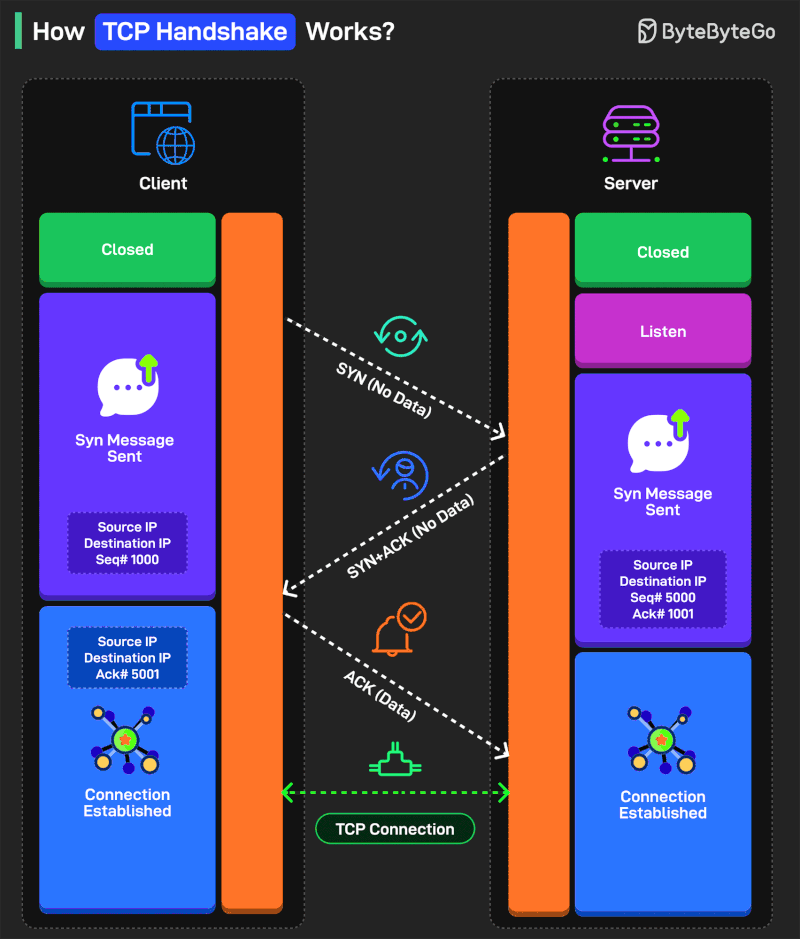
There are three steps in the handshake process:
SYN (Synchronize)
Think of it as one party extending its hand for a handshake. The process starts with the client sending a TCP segment to the server with the SYN flag. Also, an initial sequence number (ISN) is sent along with the message.
SYN-ACK
This is like the second party agreeing to the handshake. The server receives the SYN segment and responds by sending a TCP segment to the client. It sets the SYN flag and the ACK flag in the segment. The ACK flag is meant to acknowledge the receipt of the client’s SYN segment by incrementing the ISN.
ACK
This is where the two parties shake hands. The client receives the SYN-ACK segment and acknowledges the server’s response by sending another TCP segment with the ACK flag set. The sequence number is set to the server’s ISN after incrementing.
Some more points worth considering:
SYN and ACK are control flags used to manage different aspects of the communication process.
Sequence numbers (ISN) help the client and server keep track of the message order so that nothing gets missed.
Over to you: What else will you add to understand the TCP Handshake process in a better way?
Early teams hiring engineers
Subscribe to next play on Substack for more lists like this.
Two Dots is hiring engineers and more. They are building an underwriting automation and fraud prevention platform. Apply here. (SF)
Abacus is hiring a founding engineer to help build the future of tax. Reach out: cody@getabacus.com. (NYC)
Caro is building a headcount management platform for enterprise teams. They have years of runway and are hiring a founding engineer. Apply here. (SF)
Agentio just raised a $12m round from Benchmark. They are building an ad platform for creator content. They are hiring software engineers. Apply here. (NYC)
Wordware raised a $30m seed round, one of the largest in YC history. They are building a IDE for building agents using natural language. They are hiring engineers. Apply here. (SF)
Warp is building an automated back-office platform for startups and have raised over $24m. They are hiring engineers. Apply here. (NYC)
Krea recently raised $83m to build a one-stop shop for generative AI creatives (photos, videos, audio, text). They are engineers and more. Apply here. (SF)
Dart Health has built a fraud identification platform that has already reached 7 figures in ARR and is profitable. They are hiring founding engineers. Reach out: veeraj@darthealth.ai. (NYC, SF)
Parakeet Health is building conversational AI voice agents to ”solve a universal frustration - the “please hold” while scheduling medical appointments.” They are hiring hiring engineers, reach out: emao@parakeethealth.com. (SF)
Subscribe to next play on Substack for more lists like this.
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
