本文提出了Benchmark Self-Evolving框架,旨在利用不断发展的大模型能力,自动化地扩展和更新评测数据集,从而更准确地评估大模型的性能。该框架通过重构现有数据集的样本,用于动态评估大模型的性能,并针对大模型评估进化的三个方向:Scalable Evaluation、Robust Evaluation和Fine-grained Evaluation,设计了六种样本重构方法。该框架构建了一个多智能体系统,基于样本重构方法,灵活且可靠地扩展现有评测数据集。实验结果表明,该框架可以提供更准确和全面的评估,有助于研究社区在大模型发展过程中不断进化基准,选出最适合特定应用的大模型,并评估大模型的缺点以指导其进一步改进。
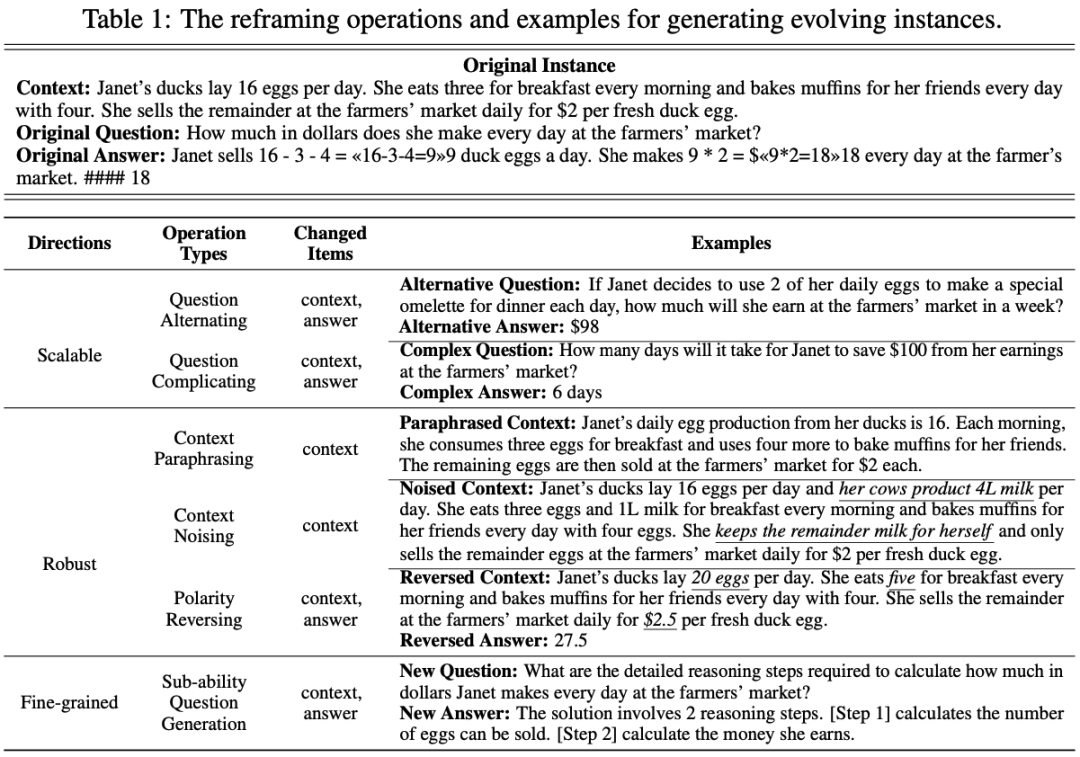
🤔 **Scalable Evaluation**:为了评估大语言模型在处理日益复杂的查询时的泛化能力,该框架通过创建替代性或更复杂的问题来进行扩展。方法包括创建替代性问题(Question Alternating)和需要更多推理步骤的复杂问题(Question Complicating)。
💪 **Robust Evaluation**:为了评估模型对数据噪音的敏感性以及抵消大模型利用数据污染捷径的倾向,该框架在原有实例的上下文中引入各种扰动。具体而言,采用三种扰动策略:(1)上下文改写(Context Paraphrasing):对原始上下文进行改写,以获得多样的表述;(2)上下文加噪(Context Noising):在原始上下文中加入无关或对抗性句子;(3)极性逆转(Polarity Reversing):逆转原始上下文的极性或更改关键细节。
🔍 **Fine-grained Evaluation**:为了提供更精细的评估结果,该框架通过生成子能力问题(Sub-ability Question Generation)来减少过时数据和偏见对能力评估造成的影响。重点关注三个与可解释性相关的子能力:(1)任务规划能力(Task Planning):询问计划推理步骤的详细信息;(2)隐知识识别能力(Implicit Knowledge Identification):识别潜在的事实或规则;(3)相关上下文检索能力(Relevant Context Retrieval):从给定上下文中提取相关信息以支持其回答。
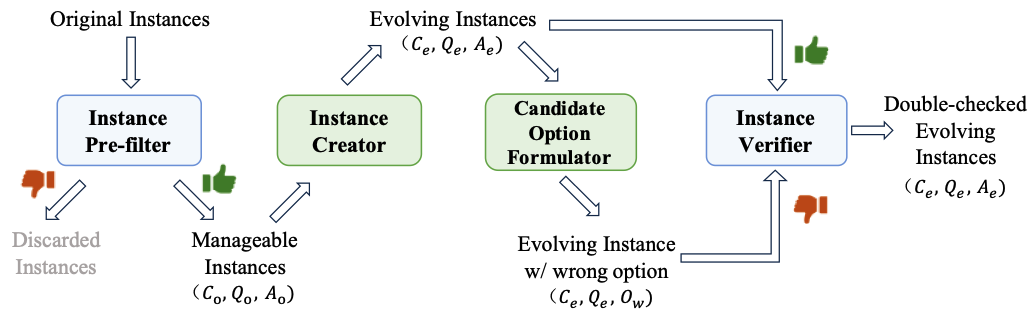
🤖 **多智能体系统**:该框架构建了一个由四个关键组件组成的多智能体协作系统:Instance pre-filter、Instance creator、Instance verifier 和 Candidate option formulator。这些组件协同工作,从原始评估集中选择可处理的实例,创建新实例,并验证新生成实例和错误选项的正确性。只有通过双重验证的实例才会被用于评估。
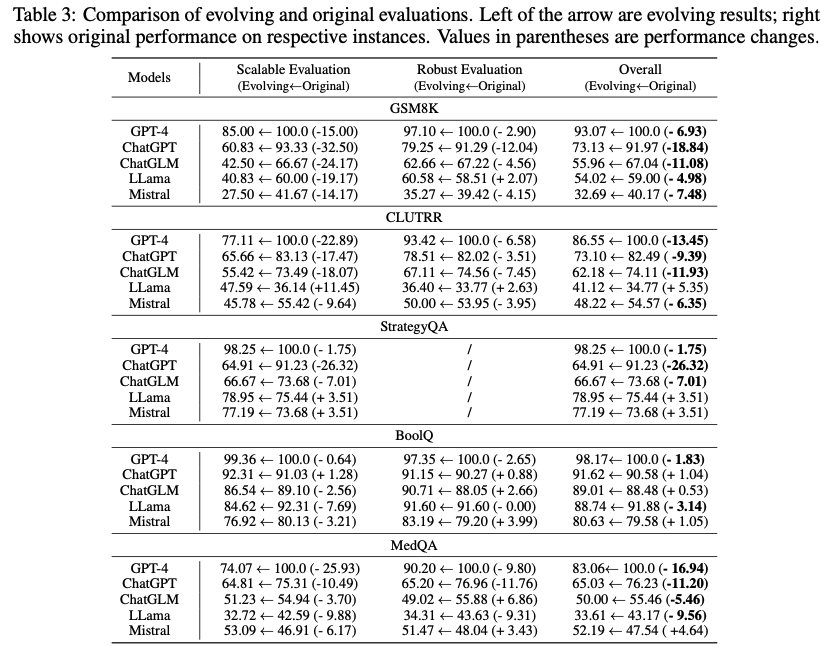
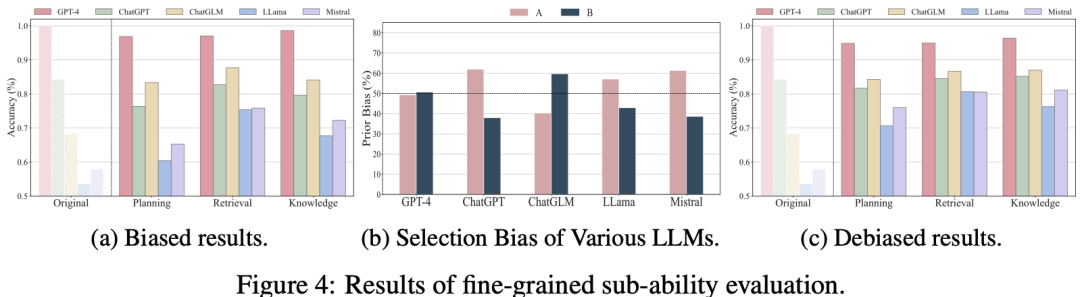
📈 **实验结果**:该框架扩展了五个任务的基准数据集,包括数学推理(GSM8k)、逻辑推理(CLUTRR)、常识推理(StrategyQA)、阅读理解(BoolQ)和医学知识考试(MedQA)。实验结果显示,大多数模型在Scalable Evaluation和Robust Evaluation中的表现相比原始结果有所下降,Scalable Evaluation还有效地扩大了模型间的性能差距。此外,该评估还加大了同一模型在不同任务中的性能差异。在Fine-grained Evaluation中,发现某些大模型存在选择偏差,并通过debias得到去偏之后的评价结果。
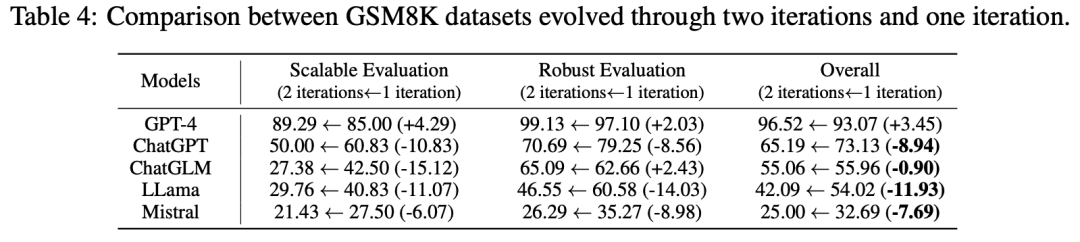
🚀 **持续迭代**:该框架可以通过迭代来不断更新基准数据集,使基准数据集与模型能力同步发展。使用当前最先进的大模型GPT-4o,在第一轮扩展的GSM8K数据集上进行了第二轮迭代更新。结果显示,除GPT-4外,所有模型在经过一轮和两轮进化的数据集上的表现显著下降,特别是在扩展性评估中。这表明进一步进化基准可以增加其挑战性。
💡 **总结**:本文提出的Benchmark Self-Evolving框架,通过多智能体系统迭代增强现有基准数据集,使其在扩展性、鲁棒性和细粒度分析上做更加全面的评估。实验结果显示,该框架可以提供更准确和全面的评估,有助于研究社区在大模型发展过程中不断进化基准,选出最适合特定应用的大模型,并评估大模型的缺点以指导其进一步改进。
Arxiv地址:
https://arxiv.org/abs/2402.11443
GitHub地址:
https://github.com/NanshineLoong/Self-Evolving-Benchmark
近年来,大语言模型(LLMs)在从文本生成到复杂问题解决等各种任务中表现出了卓越的性能,而对LLMs的评估可以全面了解这些模型的能力和局限,激发对模型进一步的改进,因此成为重要的研究领域。然而现有的评测数据集虽然数量众多,仍存在以下几个主要问题:数据集过时快:随着大模型的快速发展和不断增加的训练数据及参数,现有的数据集越来越无法满足全面评估的需求。评测数据容易污染:由于大量数据被用于改进大模型,评测数据集容易受到污染,导致评估结果有偏。人工更新数据的成本高:人工更新和维护数据集需要耗费大量的人力和时间,成本高昂。因此,本文提出的Benchmark Self-Evolving框架旨在利用不断发展的大模型能力,自动化地扩展和更新评测数据集,从而更准确地评估大模型的性能。本文提出了Benchmark Self-Evolving框架,通过重构现有数据集的样本,用于动态评估大模型的性能。主要工作包括:
针对大模型评估进化的三个方向:Scalable Evaluation、Robust Evaluation和Fine-grained Evaluation,设计了六种样本重构方法。
设计了一个多智能体系统,基于上述样本重构方法,灵活且可靠地扩展现有评测数据集。
使用Benchmark Self-Evolving框架在通用和特定领域的五个任务数据集上进行扩展,并对多个大模型进行了评估。结果表明,我们的dynamic evaluation对模型更具挑战性,并且加大了不同模型之间及同一模型在不同任务中的性能差异,有助于为特定任务选择更合适的模型。
本文提出的Benchmark Self-Evolving框架主要包括(1)定义了三个评估进化的方向及样本重构方法;(2)构建了一个多智能体协作系统。1. Scalable Evaluation:通过创建替代性或更复杂的问题,评估大模型在处理日益复杂的查询时的泛化能力。我们的方法包括创建替代性问题(Question Alternating)和需要更多推理步骤的复杂问题(Question Complicating)。
2. Robust Evaluation:在原有实例的上下文中引入各种扰动,以评估模型对数据噪音的敏感性以及抵消大模型利用数据污染捷径的倾向。具体而言,我们采用三种扰动策略:(1)上下文改写(Context Paraphrasing):对原始上下文进行改写,以获得多样的表述;(2)上下文加噪(Context Noising):在原始上下文中加入无关或对抗性句子;(3)极性逆转(Polarity Reversing):逆转原始上下文的极性或更改关键细节。
3. Fine-grained Evaluation:通过生成子能力问题(Sub-ability Question Generation),减少过时数据和偏见对能力评估造成的影响,提供更精细的评估结果。我们重点关注三个与可解释性相关的子能力:(1)任务规划能力(Task Planning):询问计划推理步骤的详细信息;(2)隐知识识别能力(Implicit Knowledge Identification):识别潜在的事实或规则;(3)相关上下文检索能力(Relevant Context Retrieval):从给定上下文中提取相关信息以支持其回答。该系统由四个关键组件组成:Instance pre-filter, Instance creator, Instance verifier 和 Candidate option formulator。各自的职能如下:1. Instance pre-filter:分析原始数据集,挑选出能够准确回答的实例,为后续重构操作的准确性奠定基础。
2. Instance creator:根据任务描述,重构上下文(包括Context Paraphrasing、Context Noising和Polarity Reversing)或重构问题(包括Question Alternating、Question Complicating和Sub-ability Question Generation)来生成新的数据实例。
3. Instance verifier:验证新生成实例的上下文、问题和答案的准确性,确保生成过程的可靠性。
4. Candidate option formulator:为每个新的上下文-问题对创建一个错误答案选项,并由Instance verifier识别其与新上下文-问题对的不一致性来对实例做双重验证。这一过程帮助进一步提升数据集的可靠性。我们的系统通过以下步骤协作:首先Instance pre-filter从原始评估集中选择可处理的实例,Instance creator再基于这些实例创建新实例,接下来Candidate option formulator为每个新的上下文-问题对生成一个错误选项,最后Instance verifier验证新生成实例和错误选项的正确性。只有通过双重验证的实例,即生成的实例被验证为正确而错误选项被验证为错误的,才会被用于评估。
我们扩展了五个任务的基准数据集,包括数学推理(GSM8k)、逻辑推理(CLUTRR)、常识推理(StrategyQA)、阅读理解(BoolQ)和医学知识考试(MedQA)。我们评估了闭源模型(GPT-4,GPT-3.5和ChatGLM)和开源模型(LLama和Mistral)。实验发现,大多数模型在Scalable Evaluation和Robust Evaluation中的表现相比原始结果有所下降。Scalable Evaluation还有效地扩大了模型间的性能差距。此外,我们的评估还加大了同一模型在不同任务中的性能差异。
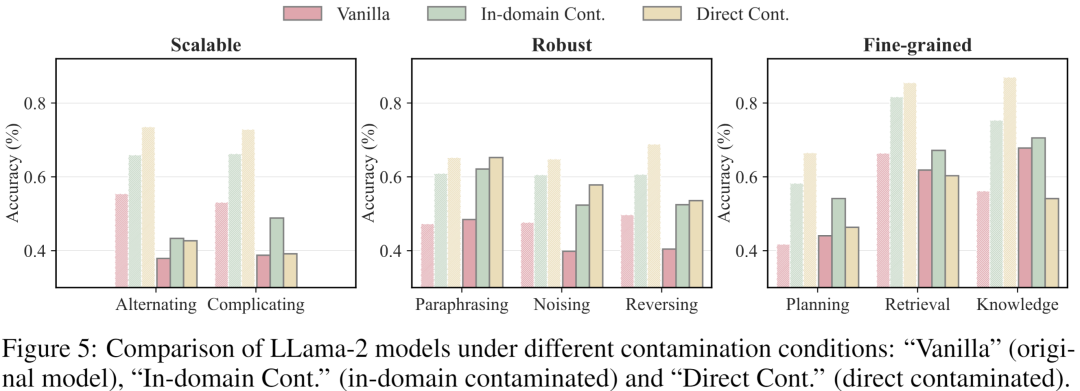
在Fine-grained Evaluation中,我们以包含A、B两个选项的二元选择题作为任务形式。我们汇总了各数据集中每个子能力的评测结果,发现原始评估和细粒度评估之间存在显著差异,尤其是模型规划能力还有待提升。此外还发现某些大模型存在选择偏差,并通过debias得到去偏之后的评价结果。我们构建了两个指令微调数据集:一个模拟in-domain污染,只包含评估数据集的训练集部分;另一个模拟direct污染,包含训练集和评估集。使用这两个数据集分别对LLama-2-7B-Chat进行微调后再在我们生成的扩展数据集上测试。我们发现与原始模型相比,in-domain和direct污染模型在原始评估下表现显著提升,而在我们的动态评估下,性能差距缩小,表明我们的框架对数据污染具有抵抗力。
我们的框架可以通过迭代来不断更新基准数据集,使基准数据集与模型能力同步发展。我们使用当前最先进的大模型GPT-4o,在第一轮扩展的GSM8K数据集上进行了第二轮迭代更新。
结果显示,除GPT-4外,所有模型在经过一轮和两轮进化的数据集上的表现显著下降,特别是在扩展性评估中。这表明进一步进化基准可以增加其挑战性。
本研究提出Benchmark Self-Evolving框架,该框架通过多智能体系统迭代增强现有基准数据集,使其在扩展性、鲁棒性和细粒度分析上做更加全面的评估。实验结果显示,在新生成的数据集上大模型的整体表现有所下降,并且在不同模型和任务之间存在显著差异,表明我们的框架可以提供更准确和全面的评估。我们希望这一可持续的框架能够帮助研究社区在大模型发展过程中不断进化基准,选出最适合特定应用的大模型,并评估大模型的缺点以指导其进一步改进。
联系方式:disc_imcs@163.com
地址:复旦大学邯郸校区计算中心