
想象一下,你在一个陌生的房子里寻找合适的礼物盒包装泰迪熊,需要记住每个房间里的物品特征、位置关系,并根据反馈调整行动。
这一系列过程依赖人类强大的空间-时间长时记忆。
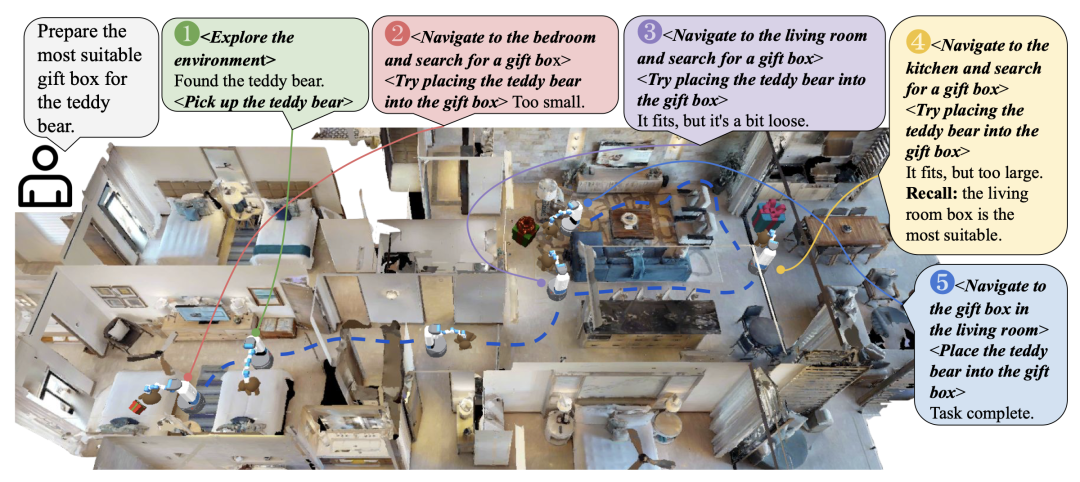
如何让AI在3D环境中像人类一样思考,一直是具身智能领域的难题。
加州大学洛杉矶分校(UCLA)与谷歌研究院的研究团队带来了最新进展:3DLLM-MEM模型与3DMEM-BENCH基准,让AI首次具备在复杂3D环境中构建、维护和利用长时记忆的能力。

挑战:3D环境中的记忆困境
现有大语言模型(LLMs)在文本理解中表现卓越,但当“进入”动态3D环境时却举步维艰。存在以下问题:
- 长时记忆断层
简单地说,模型无法像人类一样形成“认知地图”并灵活调用记忆的核心问题在于缺乏针对3D空间-时间的记忆建模。
突破:3DMEM-BENCH基准与3DLLM-MEM模型
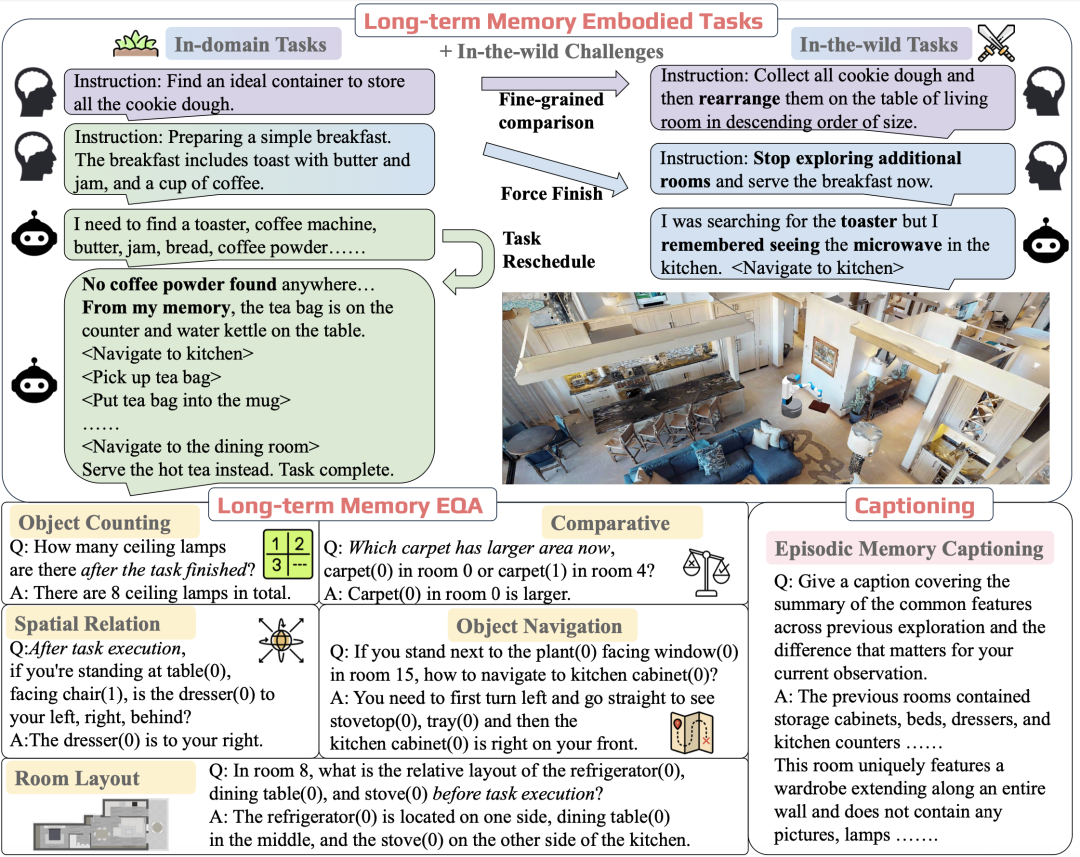
为系统评估具身智能的记忆能力,研究团队构建了3DMEM-BENCH——首个3D长时记忆评估基准。
其核心特点包括:
1.大规模与多样性
包含26,000+轨迹、1,860个具身任务(从简单物品收集到复杂跨房间推理),覆盖182个3D场景(平均每个场景18个房间)。
2.多维度评估
任务分为简单(3房间)、中等(5房间)、困难(10房间),并包含“野外挑战”(从未见过的物体或场景),全面考察模型泛化能力。
4.对比现有基准
相较于ALFWorld、Behavior-1K等,3DMEM-BENCH首次聚焦“长时记忆”与“3D空间理解”的结合,填补了领域空白。

针对记忆难题,研究团队提出3DLLM-MEM模型——一款双记忆系统驱动的具身智能体。
其设计灵感源自人类认知结构:
工作记忆作为“查询”,从情景记忆中选择性提取与任务相关的特征(如“寻找合适礼物盒”时,重点关注曾见过的盒子尺寸、位置),通过注意力机制融合两者,既避免记忆过载,又确保关键信息不被遗漏。
3.动态更新机制
当环境变化(如移动盒子),模型自动更新情景记忆,确保记忆与当前状态一致。
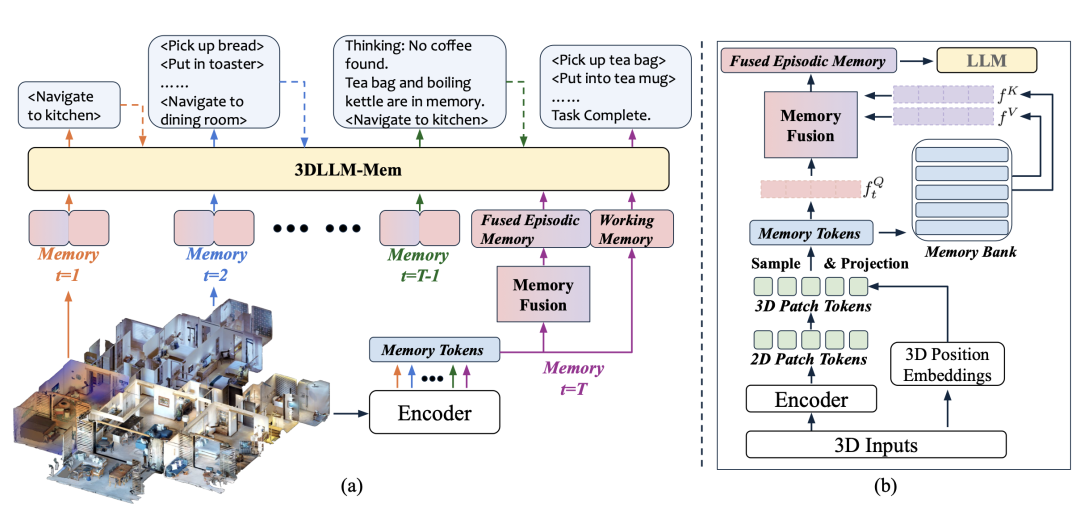
3DLLM-MEM的核心优势在于:通过“选择性记忆检索+时空特征融合”,模型在复杂环境中既能聚焦任务关键信息,又能维持记忆效率。
验证:超越基线16.5%的记忆能力
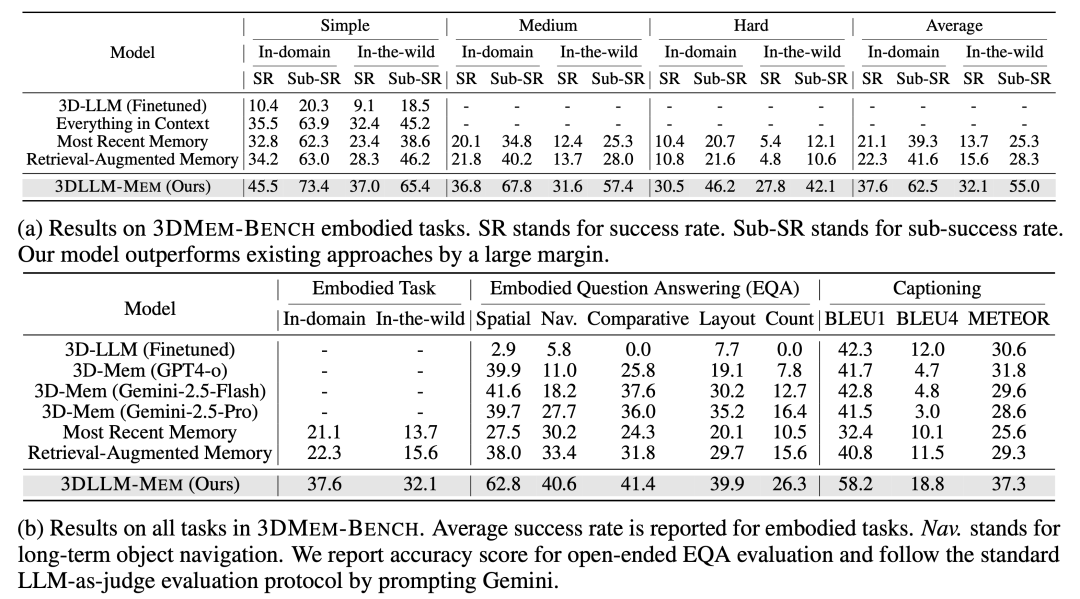
在3DMEM-BENCH上的实验表明,3DLLM-MEM显著优于现有方法。
1.具身任务成功率
2.时空推理能力
在EQA任务中,3DLLM-MEM在“空间关系”“跨房间对比”等子任务上准确率超60%,而传统3D-LLM因上下文限制,准确率不足10%。
3.记忆效率
3DLLM-MEM模型通过“动态融合”机制,仅需处理与当前任务相关的记忆片段,计算成本比“全记忆存储”降低,同时保持高推理精度。
典型案例包括:在“准备早餐”任务中,3DLLM-MEM模型先在厨房寻找咖啡机未果,转而利用记忆中“餐厅有茶壶”的信息,调整策略煮茶完成任务,体现了灵活的记忆调用与任务规划能力。
尽管3DLLM-MEM已实现重大突破,研究团队也指出其局限性:目前模型依赖模拟器的高层动作预设,未来需与底层导航和控制结合。
论文连接: https://arxiv.org/abs/2505.22657
项目主页: https://3dllm-mem.github.io
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
