
Published on June 1, 2025 8:30 PM GMT
Textual Steering Vectors Can Improve Visual Understanding in Multimodal Large Language Models
TL;DR: We discovered the possibility of using steering vectors from text-only models to enhance visual reasoning in multimodal LLMs (MLLMs). The technique is simple: extract textual representations for concepts like "spatial relationships" and "counting" from the LLM backbone and then apply them to the vision-language model's hidden states. This steering not only changes how the model understands visual content but also leads to meaningful improvements - 15.8% on spatial reasoning tasks and 34.2% on counting tasks for example, which suggests that these models maintain some unified representations that bridge text and vision.
The Core Insight: Text Steers Vision
Here's something that surprised us: you can make a vision-language model better at visual understanding by steering it with vectors derived purely from text.
Many multimodal large language models (MLLMs) like PaliGemma[1] and Idefics[2] are built by taking a pre-trained text-only LLM backbone and teaching it to process images. We wondered: do these models preserve enough of their original text representations that we could use text-only steering techniques to improve their visual reasoning?
The answer appears to be a resounding yes.
The Mechanics of Steering Vectors
Let's clarify exactly what we mean by "steering vectors" and how they work:
What Is a Steering Vector?
A steering vector is a direction in the model's high-dimensional activation space that corresponds to some concept or behavior[3][4]. Think of it as a "conceptual compass" - it points toward the neural representation of ideas like "spatial relationships" or "counting."
How Are Steering Vectors Applied?
The application is surprisingly straightforward. During inference, at a specific layer , we modify the model's hidden states:
Where:
- = original hidden states at layer = our steering vector for that layer = steering strength (how much to intervene) = modified hidden states
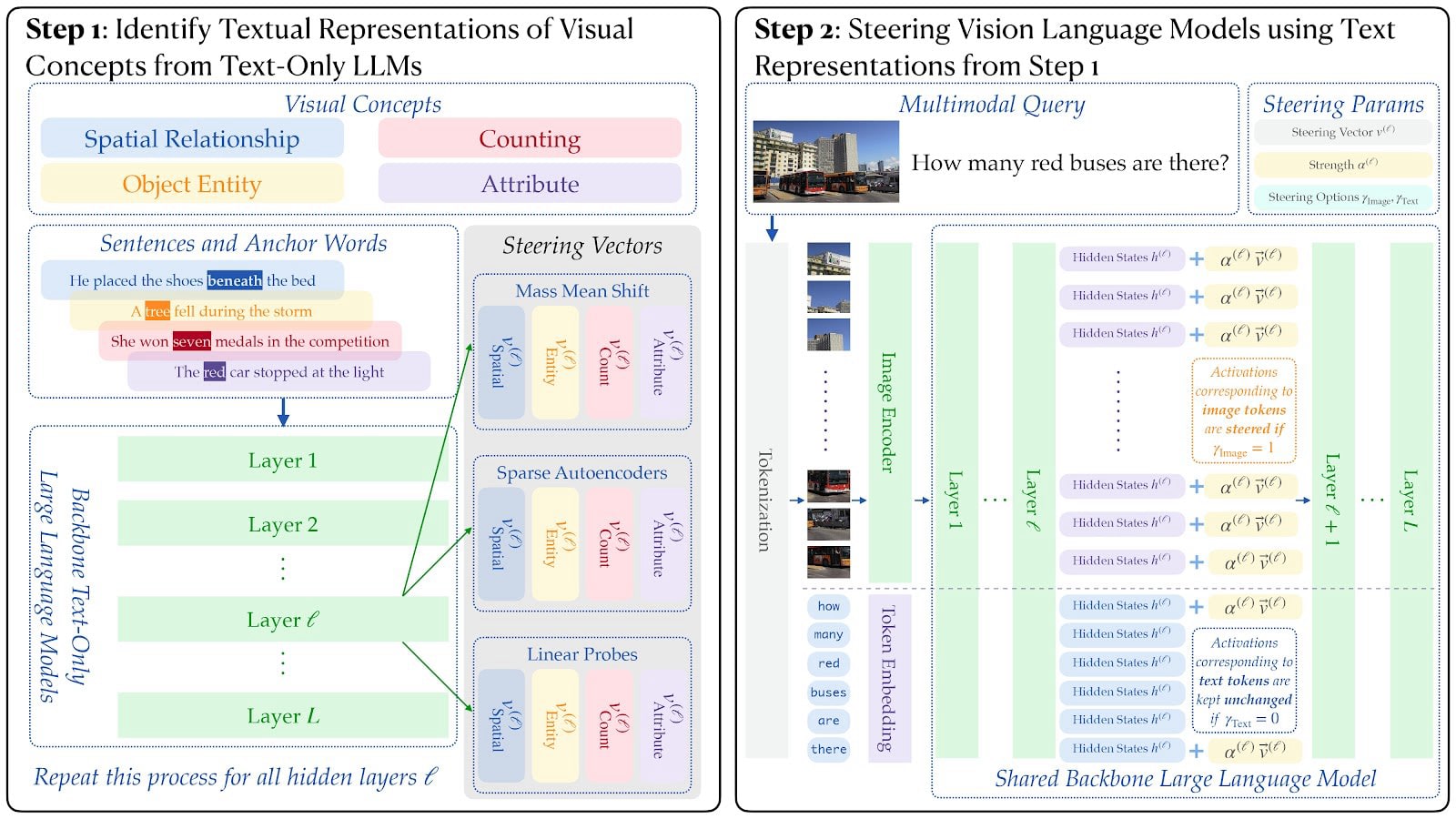
We can also choose to where to apply this steering:
- Image tokens only: Steer only on hidden states of image tokensText tokens only: Steer only hidden states of text tokensBoth: Steer on hidden states of all tokens except special tokens like <bos>
An important notice here is that we never steer the output token in this work, as we want to change the model's understanding rather than directly controlling its behavior.
A Simple Demonstration: Changing Color Perception
As we understand what steering vectors are, let's see them in action with a concrete example. Here we took a yellow-orange image (hex code #FFB400) and showed it to PaliGemma2-10B[1]. Normally, the model correctly identifies it as yellow-orange. But what happens if we intervene the image tokens with a textual steering vector for "red"?
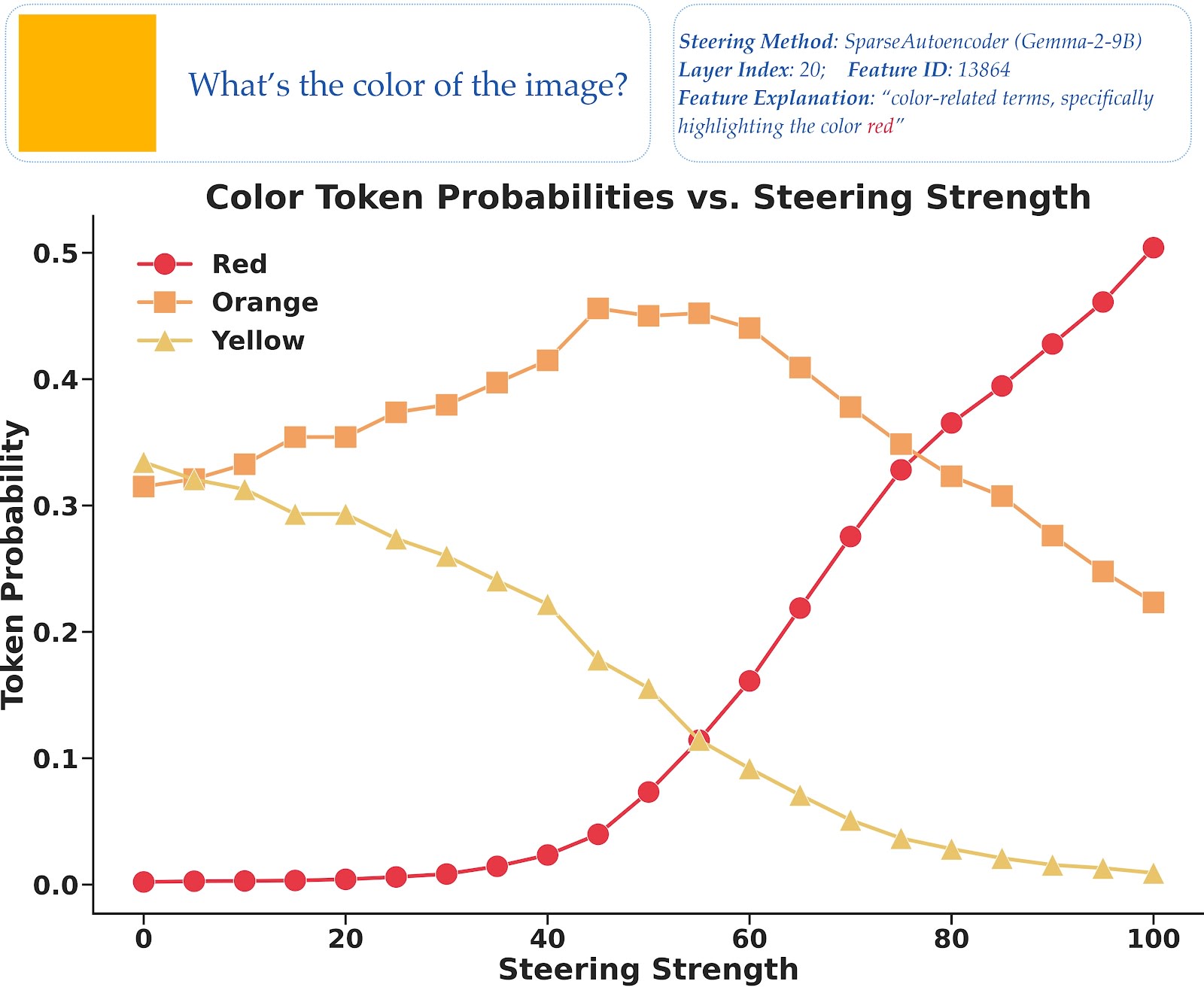
First, we identified a "red" steering vector extracted from the text-only Gemma-2-9B model[5] using GemmaScope[6], and then we applied to the hidden states of image tokens at layer 20 with the following method:
Where represents the hidden states of image tokens at layer 20, is our normalized "red" vector from GemmaScope[6], and is our steering strength. The results vary with the strength:
- At low steering strength (): Still perceives yellow-orangeAt moderate strength (): Perceives orangeAt high strength (): Confidently reports red
What's interesting is how the concepts seem to blend arithmetically: text "red" + image "yellow" = perception "orange" at moderate steering strength. The textual and visual concepts actually combine in the model's internal representations to create new perceptions that mix inputs from both modalities.
This goes beyond just changing what the model says—it's changing how it sees. The textual representation of "red" actually integrates with the visual processing pipeline. This experiment shows that MLLMs develop shared representational spaces where text concepts can directly influence visual processing[7].
Methods for Extracting Steering Vectors
Now, we are going to explore three approaches for extracting these steering vectors systematically from text-only LLMs. For all three methods, we use a same dataset that we curated ourselves: for each visual concept (spatial relationship, counting, attribute, and entity), we create 20 sentence-anchor pairs such as:
- Spatial: "The cat is on the table" (anchor: "on")Counting: "There are three apples" (anchor: "three")Attribute: "The red car stopped" (anchor: "red")Entity: "The dog barked loudly" (anchor: "dog")
Then we use these sentence-anchor pairs for all three extraction methods:
1. Sparse Autoencoders (SAEs): Finding Monosemantic Features
SAEs decompose neural activations into interpretable features[8][9]. Here's our process of extracting an steering vector from existing SAEs:
Step 1: Feed our sentences through pre-trained SAEs and find which features activate most strongly on our anchor words.
Step 2: Filter and verify using GPT-o3-mini[10] to confirm that identified features actually relate to our target concept, removing noise. Visual concepts are sparsely encoded—< 10 features out of 16,000-32,000 total features were activated per layer for each concept.
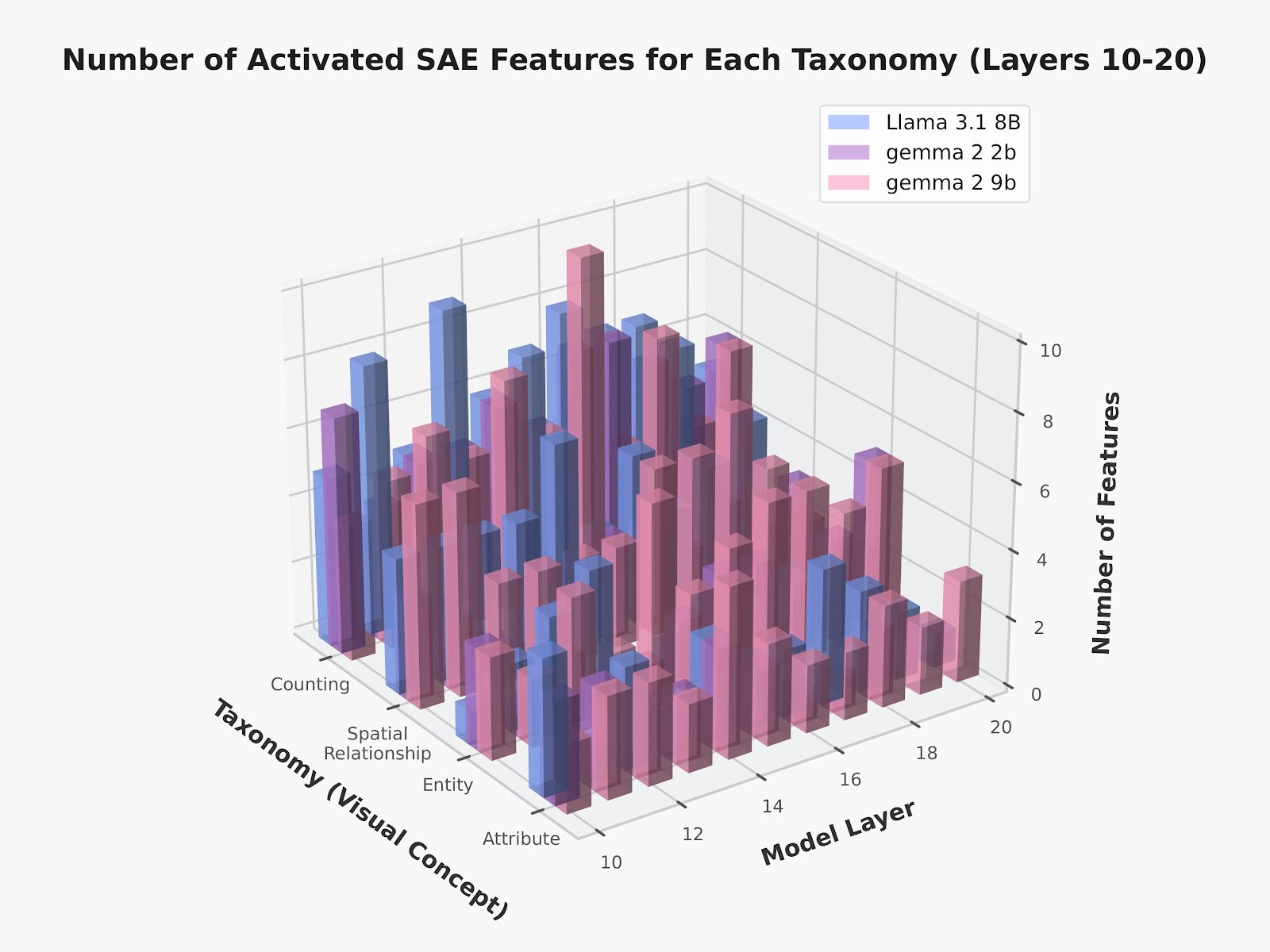
Step 3: Average the normalized feature vectors that we filtered out from step 2 to create a single steering vector per concept per layer.
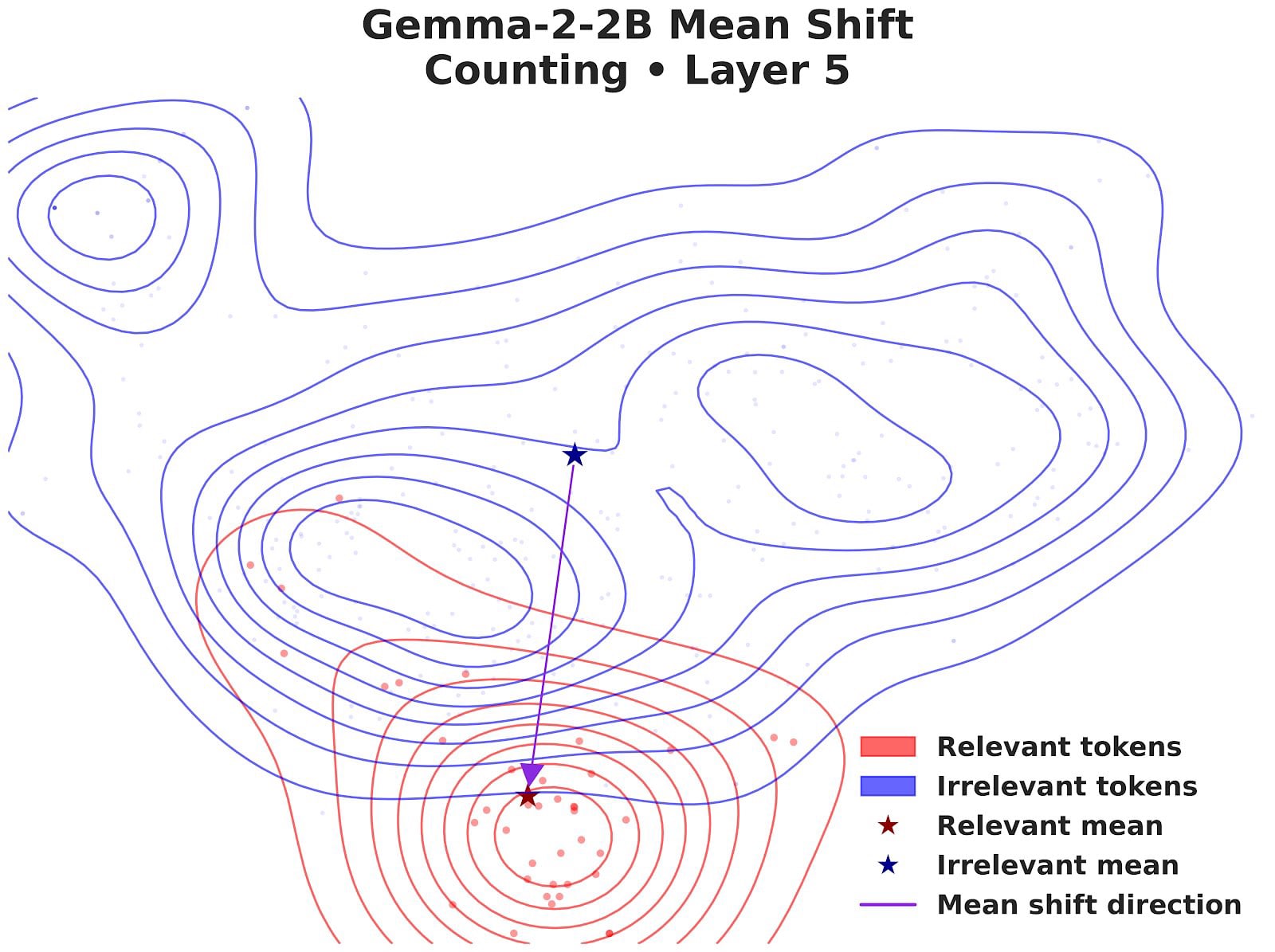
2. Mean Shift: The Simple but Effective Approach
This method simply computes the difference between the hidden states of concept-relevant tokens (anchor words) and control activations[3]:
The control words are the non-anchor words from the same sentences—they help us isolate the specific concept from general contextual information.
Visualize the steering vector with PCA:
3. Linear Probing: Learning to Distinguish
We train a simple linear classifier to distinguish between anchor word activations and control word activations[11] and use the learned classifier's weight vector as our steering vector.
Since the activation dimensions is larger than our sample size, we first apply PCA for dimensionality reduction and train the probe in the reduced space. We then learn a normal vector in the reduced space, then transform it back to the original space with to get our final steering vector, where is the PCA projection matrix.
4. Prompting: A Baseline for Comparison
While it is not a vector-based steering method, prompting as an important baseline since it's highly effective for steering text-only LLMs[12]. Here, for each visual concept (e.g., spatial relationships, counting), we:
- Generate 30 different instruction prompts using GPT-4oTest all prompts on a training setSelect the best-performing prompt for evaluation
A example of spatial relationship prompt might be: "Pay close attention to the relative positions of objects in the image. Focus on whether items are above, below, left, right, inside, or outside of other objects."
Results: What Actually Improved
Grid Search for Optimal Parameters
To make any steering method work, we want to nail down the right layer () and strength () for the steering vectors. To determine them, we used the CV-Bench[13] dataset, which contains various visual reasoning tasks including counting and spatial relationship recognition. We split each corresponding subset (Count, Relation) of CV-Bench into training (500-600 samples) and testing (150 samples) sets, using the training portion for our grid search and reserving the testing portion for final evaluation. An important notice is that we used task-specific steering vectors: spatial relation vectors were applied to spatial relation tasks, and counting vectors were applied to counting tasks.
Another key insight is that we can figure out which layers contain the most visual processing before grid search. To understand that, for each layer , we zeroed out attention to image tokens after and measured how much performance dropped. This showed us the critical layers for visual understanding, so we could focus our search on the promising ones (layers 5-20 for PaliGemma2-3B for example) instead of brute-forcing through all 26 layers, which significantly reduced computational overhead.
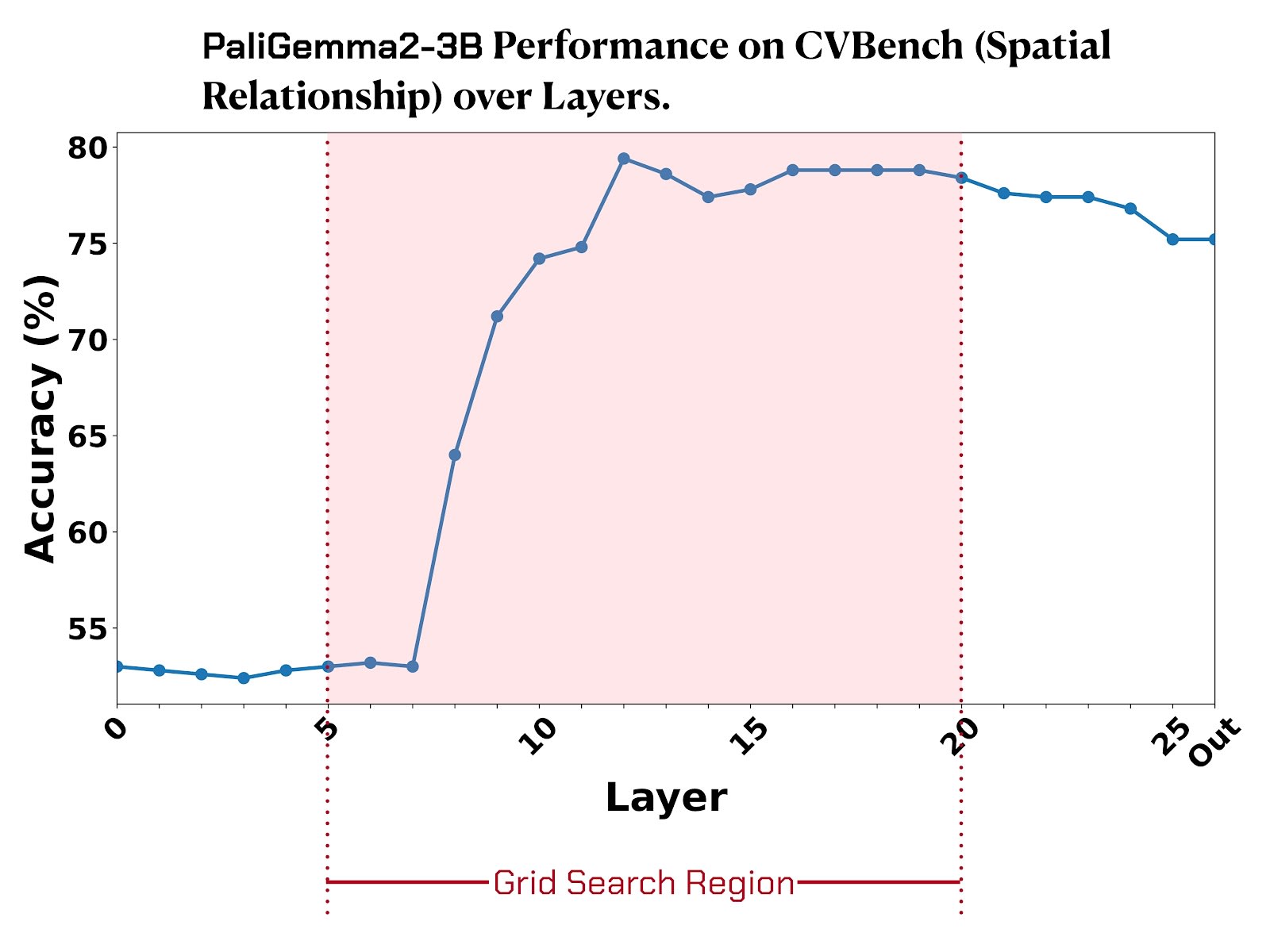
For each model and task combination, we performed the grid search over these key layers and a range of strength values to find the optimal intervention parameters, which were then fixed for all subsequent evaluations.
Main Results on CV-Bench
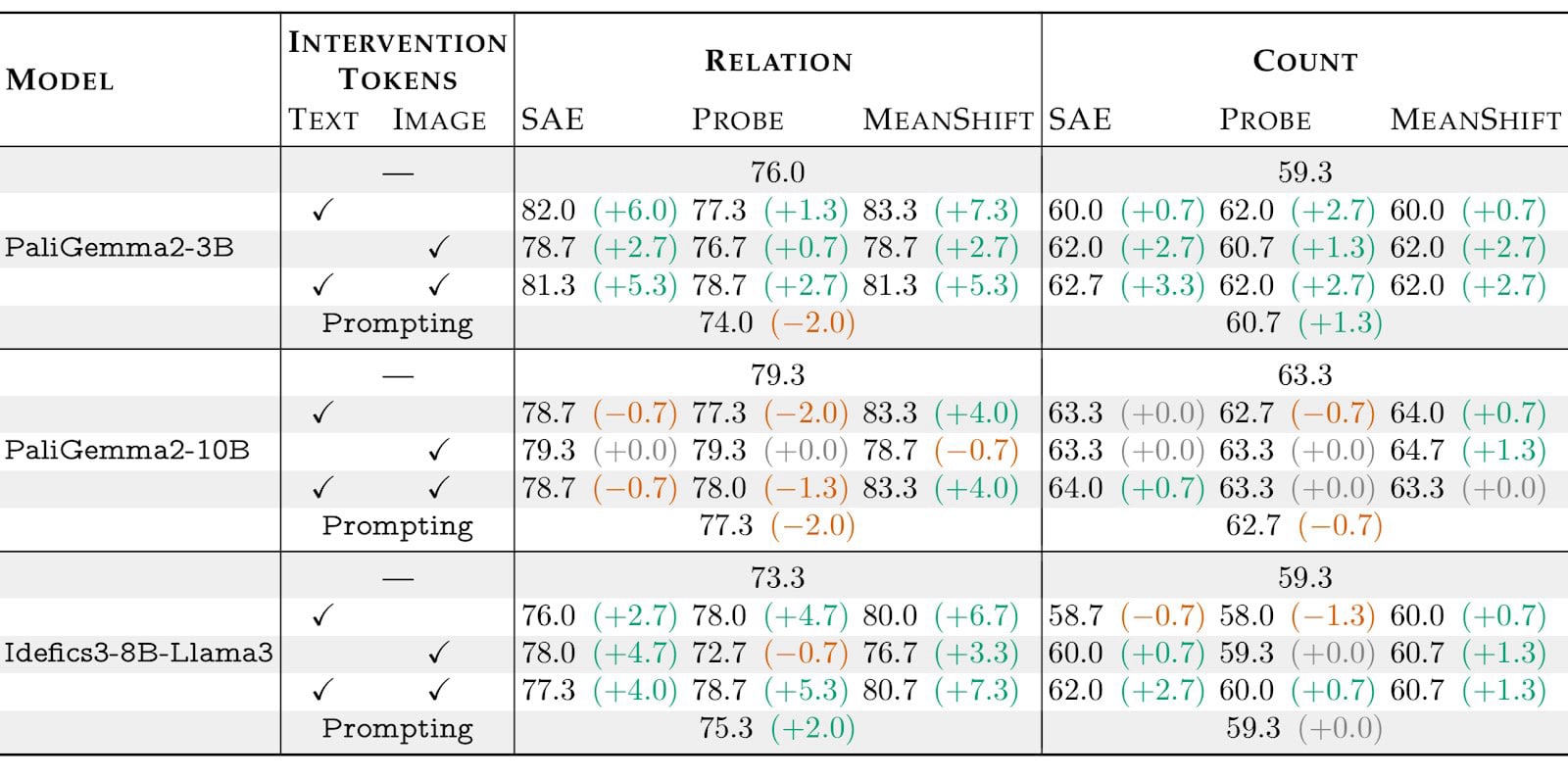
Here are some of out key findings:
Steering beats prompting: While prompting is very effective for text-only LLMs[12], it barely helps (and sometimes hurts) multimodal models on visual reasoning tasks.
Mean shift is surprisingly robust: Although it is the simplest method, its performance seems to be the best, which somewhat aligns with the finding in AxBench[12].
Spatial reasoning sees larger gains: Interventions have a larger improvements for spatial tasks, possibly because they benefit more directly from highlighting salient features.
Out-of-Distribution Generalization
The most compelling evidence comes from testing on completely different datasets where we didn't tune any hyperparameters specific to these datasets. Specifically, we evaluated on five diverse datasets:
- What'sUp-A[14]: Contains 408 images of pairs of household objects arranged in clear spatial relations ("on", "under", "left", and "right")What'sUp-B[14]: Similar to What'sUp-A but with 412 images where objects are closer in size, making spatial discrimination more challengingBLINK Object Localization[15]: Contains 122 questions related to identifying accurate bounding boxes for objectsCLEVR[16]: A procedurally generated dataset with simple 3D objects, from which we sampled 500 counting questionsSuper-CLEVR[17]: An extension of CLEVR with more complex scenes, from which we sampled 200 counting questions
For all these datasets, we directly used the best-performing (, ) combinations from our CV-Bench grid search. (For example, if that is a dataset for evaluating MLLM’s spatial understanding, we use the vector and best hyperparameters from the CVBench Relation subtask). The only adaptation we made was using a small validation subset (50 samples for What'sUp and CLEVR, 25 samples for BLINK and Super-CLEVR) to determine the most effective token type for intervention (image, text, or both). After this minimal validation step, we evaluated on the remaining data.
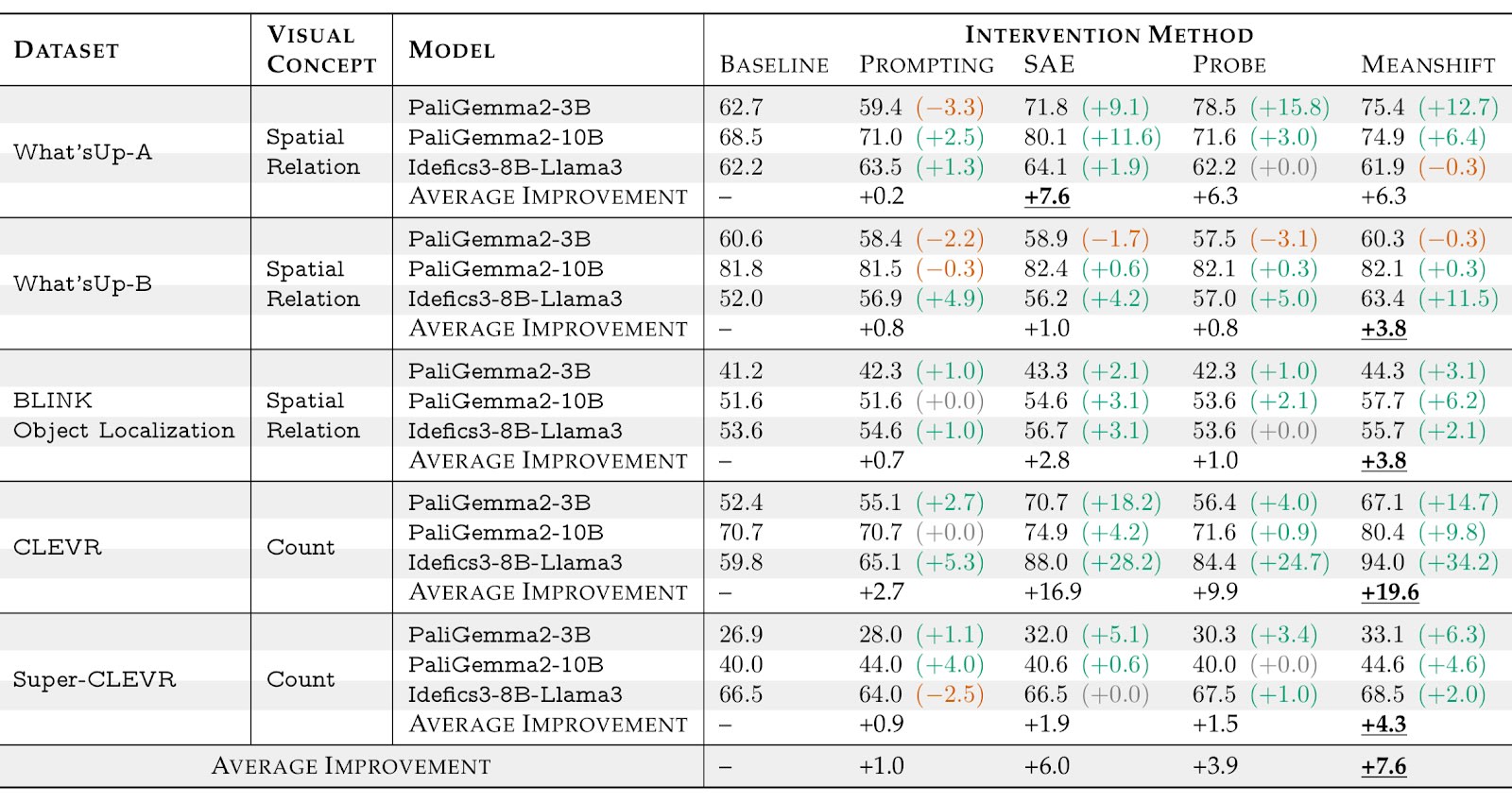
These results show several interesting patterns across different visual reasoning domains:
Spatial Relations (What'sUp-A): We saw a large improvement (+15.8%) on this dataset that tests how well models identify relative positions between household objects. SAE method worked particularly well on this task.
Counting (CLEVR): The biggest improvements happened here (+34.2%). Idefics3-8B-Llama3[2] jumped from 59.8% to 94.0% with MeanShift steering. We are assuming that the models might have latent counting abilities that weren't being used for visual tasks until we steered them.
Object Localization (BLINK): Smaller but consistent improvements (+6.2%) across all methods. This task needs precise spatial understanding for bounding boxes rather than just relation between objects, so the gains suggest our vectors help with fine-grained spatial perception.
MeanShift performed best overall (+7.6%), followed by SAE (+6.0%) and Probe (+3.9%). Prompting only managed +1.0%. The fact that this worked across different datasets shows we might capture some general visual reasoning patterns, not dataset quirks.
Contributions
Here we identified several implications of our work for AI safety and alignment:
Representation Sharing Across Modalities: The fact that text-derived vectors can steer visual processing suggests that MLLMs develop unified conceptual representations that span modalities[7]. This could help the community to understand better how these models generalize concepts across different input types.
Efficient Intervention Methods: Our approach requires minimal additional compute and no specialized multimodal data collection. The steering vectors can be extracted once from the text backbone and applied broadly for enhancing the reliability of MLLMs.
Interpretability Insights: The success of this method provides evidence that existing interpretability tools developed for text-only models may be more broadly applicable than previously thought[18], meaning that they could still be valuable for alignment and interpretability research as AI systems become more multimodal.
Control and Steering: As we develop more powerful multimodal AI systems, having lightweight methods to guide their behavior without parameter updates becomes increasingly valuable[3][4].
Limitations and Future Work
We identified several important limitations of our approach:
Backbone Dependency: The method requires that the MLLM have a text-only backbone, limiting applicability to models that are trained from scratch.
Quality Dependence: Effectiveness of the steering depends on the quality of text-derived steering vectors, which can be imperfect.
Architecture Specificity: We focused on specific architectures (PaliGemma and Idefics3, which use early fusion); broader architectural diversity needs investigation.
Future directions include:
- Extracting steering vectors directly from MLLMs rather than text backbonesInvestigating other visual concepts beyond our taxonomiesScaling to more complex multimodal reasoning and safety tasks
Conclusion: Text and Vision Are More Connected Than We Thought
The fact that textual steering works so well on visual tasks suggests that the boundary between language and vision in these models is more porous than we previously assumed. MLLMs seem to develop genuinely shared representations rather than just learning to translate between modalities.
This has obvious implications for performance, but the deeper point is about how these systems organize knowledge internally. If text concepts can directly mess with visual processing, that tells us something important about the architecture of knowledge in AI systems, which worths a further investigation.
For the alignment community, this opens up new possibilities. The interpretability techniques we've developed for text models might transfer to multimodal systems. That could be important as AI systems become more general - we'll need a general method to understand and control increasingly sophisticated AI systems as well.
For the full technical details of our methodology, please refer to our complete paper: Textual Steering Vectors Can Improve Visual Understanding in Multimodal Large Language Models.
- ^
Beyer, L., Steiner, A., Pinto, A. S., Kolesnikov, A., Wang, X., Salz, D., ... & Zhai, X. (2024). Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726.
- ^
Laurençon, H., Marafioti, A., Sanh, V., & Tronchon, L. (2024). Building and better understanding vision-language models: Insights and future directions. arXiv:2408.12637.
- ^
Marks, S., & Tegmark, M. (2023). The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. arXiv preprint arXiv:2310.06824.
- ^
Turner, A. M., Thiergart, L., Leech, G., Udell, D., Vazquez, J. J., Mini, U., & MacDiarmid, M. (2023). Steering language models with activation engineering. arXiv preprint arXiv:2308.10248.
- ^
Gemma Team. (2024). Gemma: Open Models Based on Gemini Research and Technology. Google AI.
- ^
Lieberum, T., Rajamanoharan, S., Conmy, A., Smith, L., Sonnerat, N., Varma, V., ... & Nanda, N. (2024). Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2. arXiv preprint arXiv:2408.05147.
- ^
Wu, Z., Yu, X. V., Yogatama, D., Lu, J., & Kim, Y. (2024). The semantic hub hypothesis: Language models share semantic representations across languages and modalities. arXiv preprint arXiv:2411.04986.
- ^
Templeton, A., Conerly, T., Marcus, J., Lindsey, J., Bricken, T., Chen, B., ... & Henighan, T. (2024). Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet. Transformer Circuits Thread.
- ^
Gao, L., la Tour, T. D., Tillman, H., Goh, G., Troll, R., Radford, A., ... & Wu, J. (2025). Scaling and evaluating sparse autoencoders. In The Thirteenth International Conference on Learning Representations.
- ^
OpenAI. (2025). o3-mini.
- ^
Alain, G., & Bengio, Y. (2016). Understanding intermediate layers using linear classifier probes. arXiv preprint arXiv:1610.01644.
- ^
Wu, Z., Arora, A., Geiger, A., Wang, Z., Huang, J., Jurafsky, D., Manning, C. D., & Potts, C. (2025). Axbench: Steering llms? even simple baselines outperform sparse autoencoders. arXiv preprint arXiv:2501.17148.
- ^
Tong, S., Brown, E., Wu, P., Woo, S., Middepogu, M., Akula, S. C., ... & Xie, S. (2024). Cambrian-1: A fully open, vision-centric exploration of multimodal llms. arXiv preprint arXiv:2406.16860.
- ^
Kamath, A., Hessel, J., & Chang, K. W. (2023). What's "up" with vision-language models? investigating their struggle with spatial reasoning. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing(pp. 9161-9175).
- ^
Fu, X., Hu, Y., Li, B., Feng, Y., Wang, H., Lin, X., ... & Krishna, R. (2024). Blink: Multimodal large language models can see but not perceive. In European Conference on Computer Vision (pp. 148-166). Springer.
- ^
Johnson, J., Hariharan, B., van der Maaten, L., Fei-Fei, L., Zitnick, C. L., & Girshick, R. (2017). Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE.
- ^
Li, Z., Wang, X., Stengel-Eskin, E., Kortylewski, A., Ma, W., Van Durme, B., & Yuille, A. L. (2023). Super-clevr: A virtual benchmark to diagnose domain robustness in visual reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 14963-14973).
- ^
Sharkey, L., Chughtai, B., Batson, J., Lindsey, J., Wu, J., Bushnaq, L., ... & Bloom, J. (2025). Open problems in mechanistic interpretability. arXiv preprint arXiv:2501.16496.
Discuss
