


论文题目:Effective and Efficient Graph Foundation Model
作者:Lecheng Kong
类型:2025年博士论文
学校:Washington University in St. Louis(美国华盛顿大学圣路易斯分校)
下载链接:
链接: https://pan.baidu.com/s/1PFnhqxvrtnPteRveCpL58w?pwd=gzmy
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
图数据以其广泛的应用为特征,涵盖推荐系统[131]、药物研发[10]、社交网络[92]和交通预测[57]等领域,毋庸置疑,它已成为学术界和工业界的关键要素。图数据实用性的激增促使人们广泛关注图数据的建模,并从图核[135, 27]等传统方法发展到图神经网络 (GNN) 和图变换器等基于神经网络的先进方法。这些方法取得了显著的成功,显著提升了各自领域的最先进水平,并凸显了图数据在各种应用中的重要性及其带来的独特挑战。
尽管现有的图数据学习范式在各种应用中取得了成功,但它们却未能跟上现代数据集动态且快速发展的特性。目前,大多数图机器学习模型都是在监督学习框架内开发的,并针对特定任务进行精心定制 [133, 63, 122, 138, 137]。这种专业化带来了巨大的挑战;当新任务出现时,这些模型通常需要大量的再训练才能适应,这不仅耗时,而且成本高昂。此外,当这些新任务的可用数据有限时,利用历史数据来提升模型性能的潜力就会受到显著限制。当前图建模方法的这种僵化和缺乏适应性,严重阻碍了图研究的进展和更广泛的应用,尤其是在基于图的任务的多样性和频率不断增长的情况下。
与图建模面临的挑战相比,随着基础模型的出现,自然语言处理领域取得了革命性的发展。这些模型在包含几乎全部人类知识的庞大数据库上进行训练,使其能够响应任意查询并生成类似人类的解释[119, 22, 14]。这种广泛的信息使基础模型展现出“涌现”能力,它们可以综合过去的知识并将其应用于新的、前所未见的任务,从而显著拓宽机器学习应用的范围和能力。受这种变革性方法的启发,一个关键问题随之而来:能否为图数据开发类似的基础模型?这样的模型不仅需要处理链接预测、节点分类和图分类等传统图任务,还需要适应信息检索、逻辑推理和结构化查询等新挑战。这将是一次重大飞跃,为任意关系数据的建模带来前所未有的灵活性和适应性。
受自然语言领域的启发,构建图基础模型的努力面临着诸多艰巨的挑战。首先,与语言数据(可以在不同领域以人类可读的文本统一表示)不同,不同领域的图数据通常以位于不同嵌入空间的数值特征为特征 [8, 48, 118]。这种异质性使得跨多个跨领域数据集直接进行联合学习几乎不可能。
其次,传统的图学习范式通常依赖于人工设计的、针对特定输出量身定制的预测头,这本质上限制了模型推广到可能需要不同类型输出的新型、流动性强的任务的能力。这种设计约束限制了图领域中真正的基础模型所需的灵活性。
第三个挑战在于图数据本身的固有结构。与通常涉及处理单词或句子序列的文本数据不同,图数据包含多个节点和边,这显著增加了计算需求并加剧了延迟问题 [146, 53, 73, 158]。这种复杂性对开发能够有效处理现实世界应用中常见的庞大而多样化数据集的图基础模型构成了巨大的障碍。
鉴于图基础模型的良好前景,本论文致力于探索该模型的可行性,并在三章中解决上述技术挑战。第二章探讨了将来自不同图领域的知识嵌入单个图模型的可行性,为构建适用于所有图任务的统一模型奠定了基础。第三章将第二章的理念扩展到更广泛的领域,并构建了一个在图领域具有前所未有的泛化能力的模型。第四章讨论了图学习与其他模态学习的根本区别,并设计了图学习算法来提升第二章和第三章中提出的模型的效率。第一章的后续章节将回顾图深度学习研究、现代大型语言模型 (LLM) 的发展及其之间的联系,为本论文提供背景。
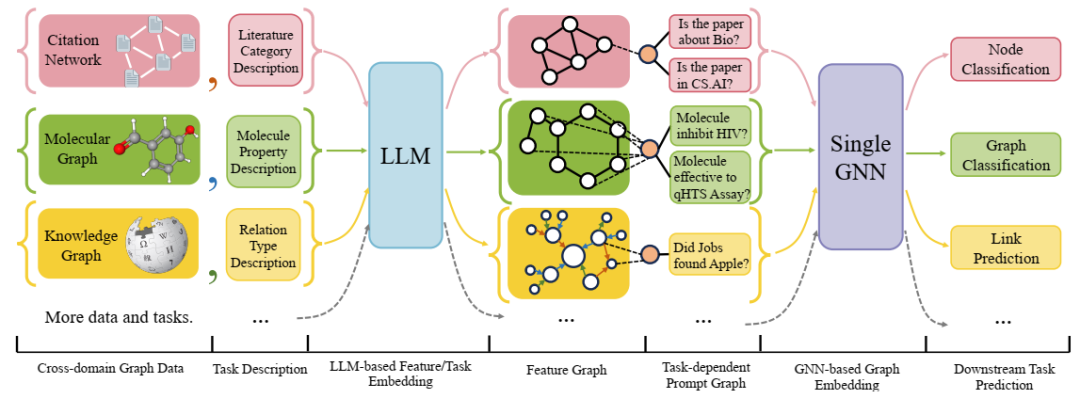
OFA 的流程。模型的输入包含一个文本属性图和一个任务描述。图和任务描述中的跨域文本可以通过 LLM 共同嵌入到同一空间中。OFA 的图提示范式将嵌入特征的输入转换为具有统一任务表示的提示图,从而实现自适应的下游预测。
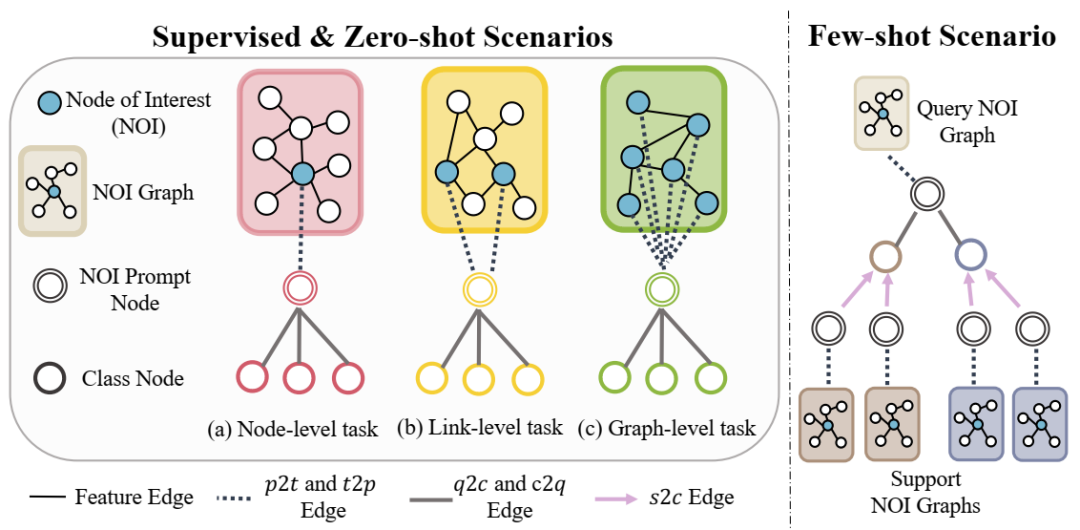
OFA中的情境学习设计
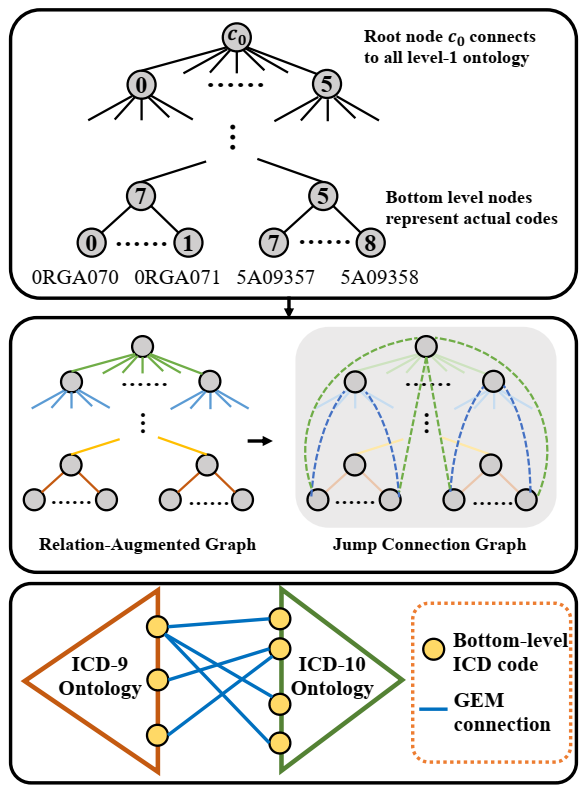
层次编码图的图示。顶部:树状层次编码。中间左侧:不同层级的边通过类型进行增强(颜色代表类型)。中间右侧:跳跃连接用虚线标记。底部:使用 GEMS 连接 ICD-9 和 ICD-10 编码底层节点的示例。
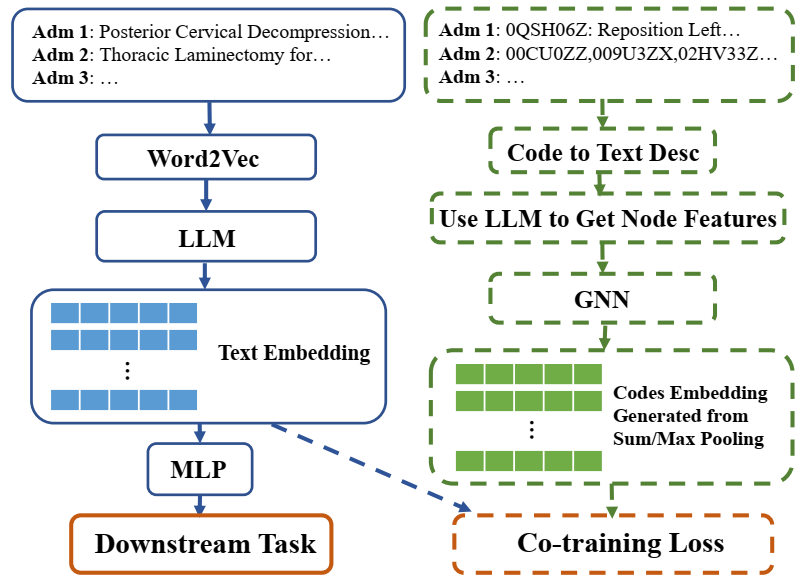
所提框架的示意图。虚线所示的区块仅在协同训练期间发生。
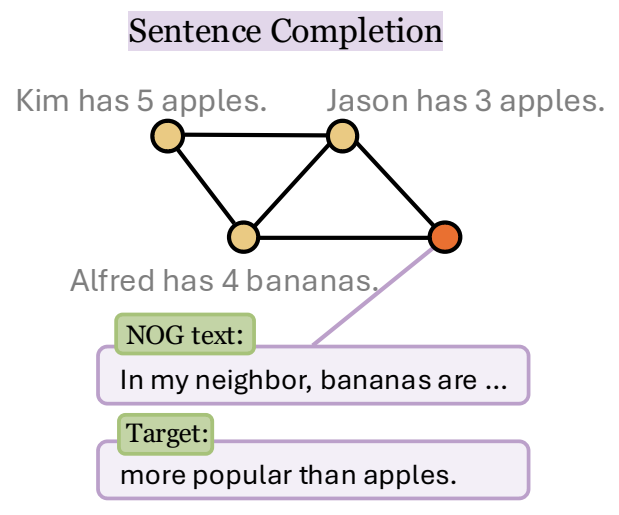
TAG 中的任务示例。句子补全/下一个单词预测。橙色节点 v 代表 NOG。
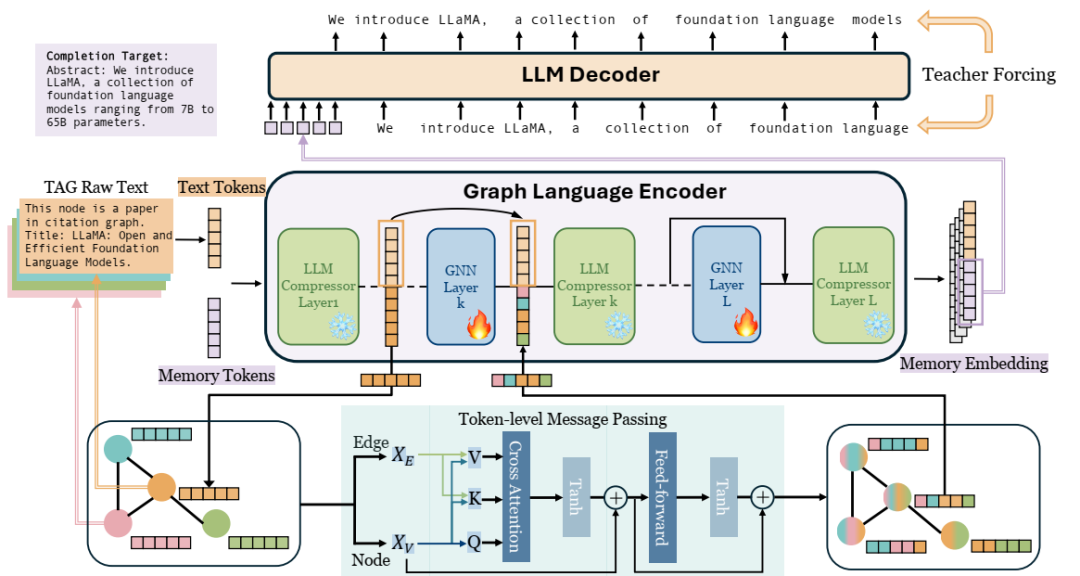
GOFA 架构。TAG 节点/边的文本 token 与记忆 token 连接,输入到图语言编码器。GNN 层交错插入到 LLM 压缩器层中,其中 LLM 压缩器的记忆嵌入用作 token 级 GNN 消息传递的节点/边特征。记忆嵌入将用于教师强制训练。
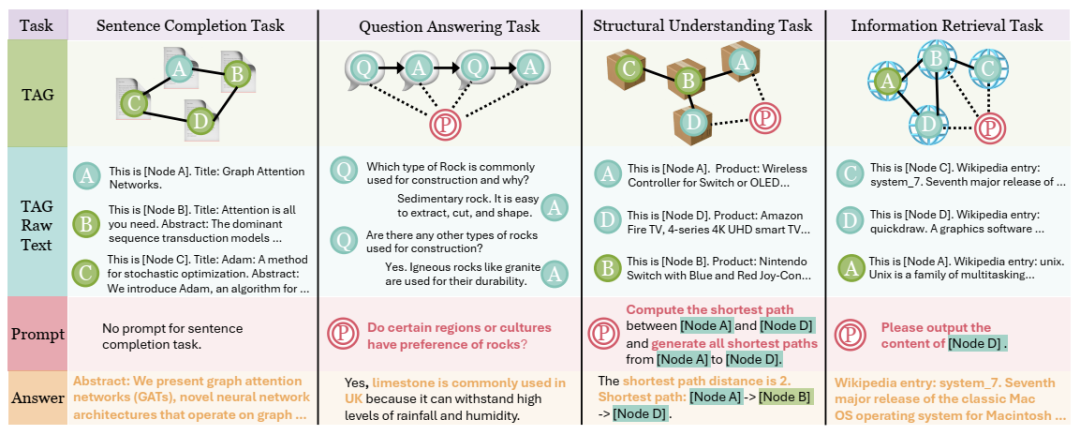
GOFA 预训练任务
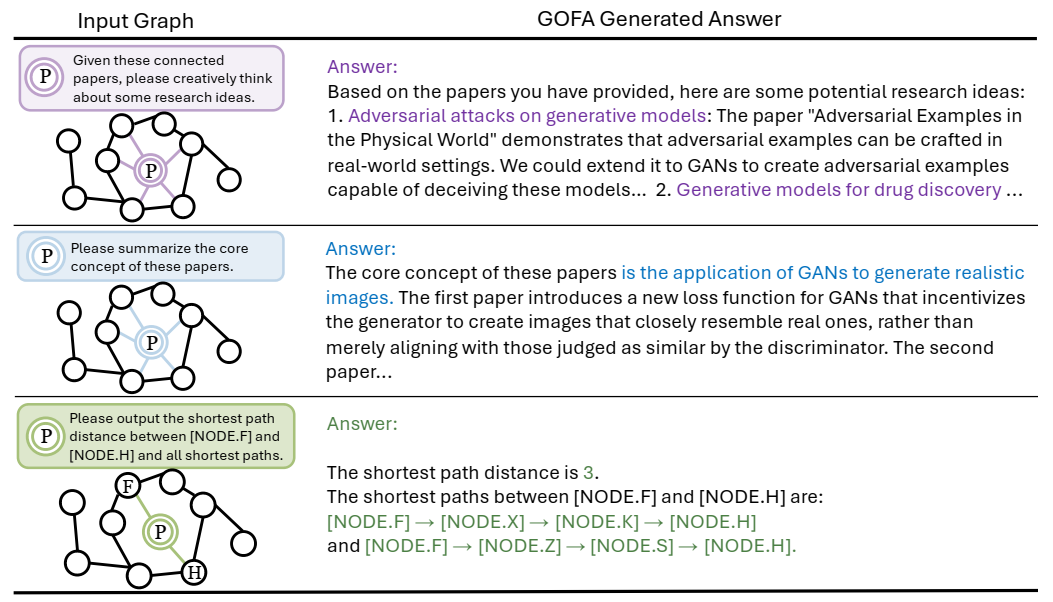
GOFA 对开放式问题的多样化回答。
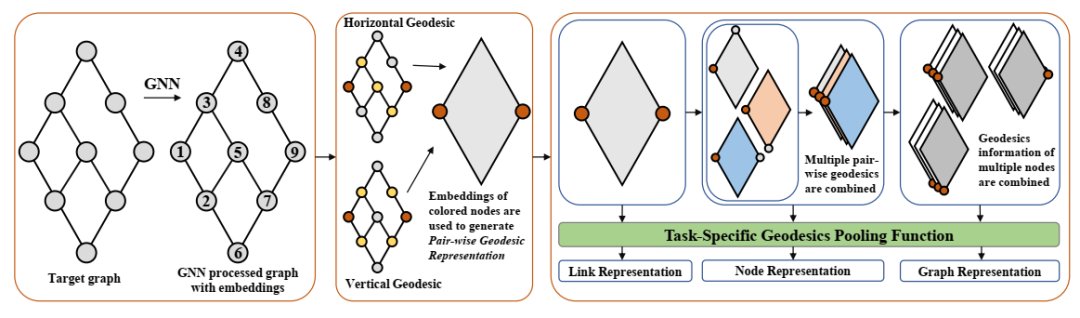
GDGNN 的整体流程。首先应用 GNN 生成节点嵌入。然后,我使用水平或垂直测地线提取成对的测地线表示。收集一个或多个这样的表示,以生成特定于任务的表示。
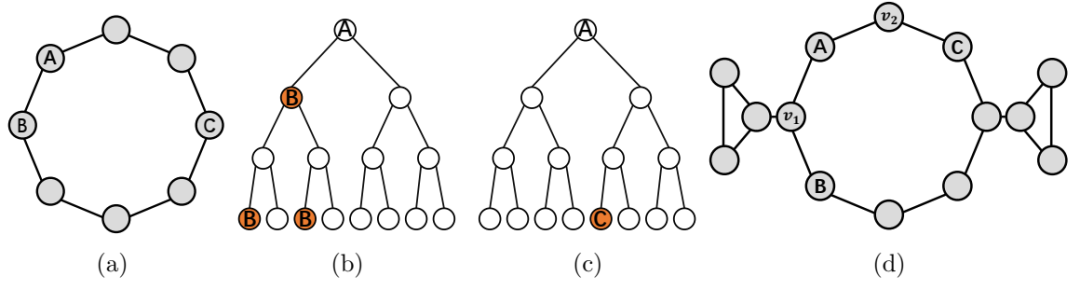
(a)一个圆形图,其中普通的 GNN 无法区分链接 AB 和 AC。(b)和(c)分别是当 B 和 C 分别被标记时,A 的 GNN 计算图。(d)是一个测地线表示可以区分链接 AB 和 AC,但距离无法区分的例子。
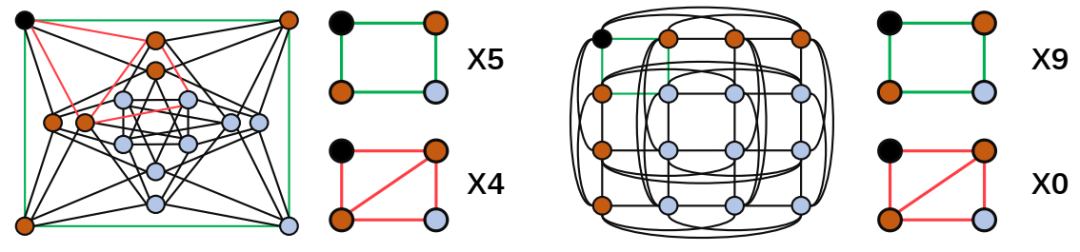
两个图的示例,其中具有垂直测地线和子图度的 GDGNN 可以区分,而距离编码则不能。
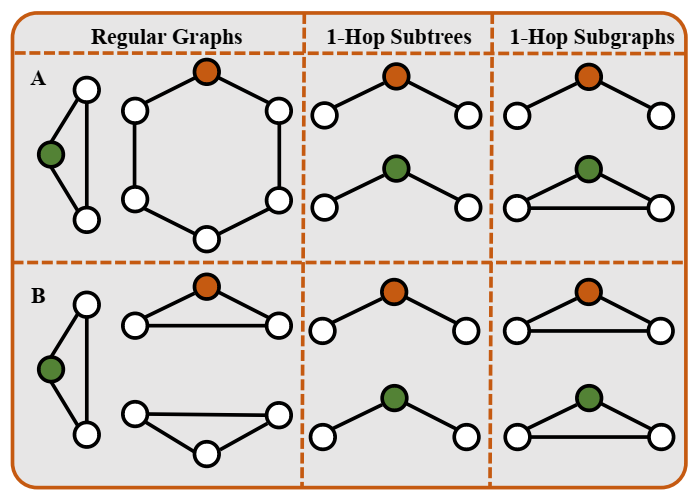
两个简单图表的比较。
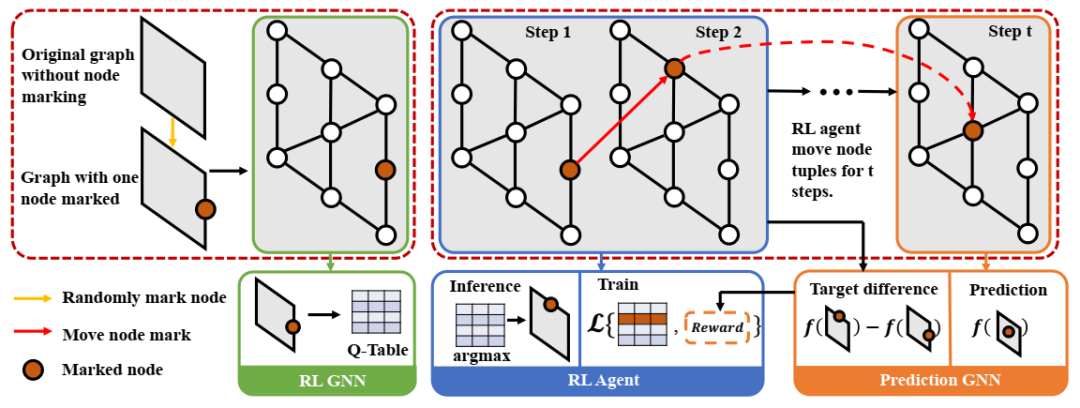
MAG-GNN 的流程。强化学习代理会迭代更新节点元组,以获得更好的表达能力。






内容中包含的图片若涉及版权问题,请及时与我们联系删除
