
Published on May 31, 2025 9:17 PM GMT
Adapted from this twitter thread. See this as a quick take.
Mitigation Strategies
How to mitigate Scheming?
- Architectural choices: ex-ante mitigationControl systems: post-hoc containmentWhite box techniques: post-hoc detectionBlack box techniquesAvoiding sandbagging
We can combine all of those mitigation via defense-in-depth system (like the Swiss Cheese model below)
I think that applying all of those strategies should divide the risk by at least 3.
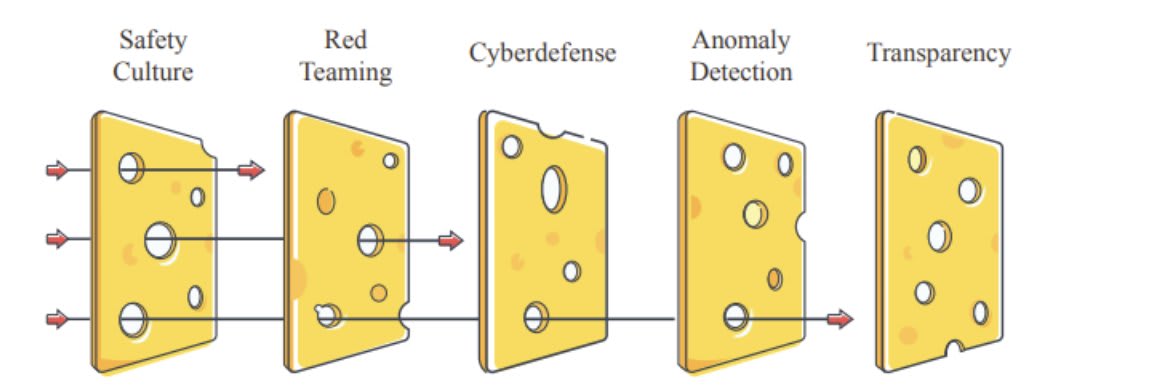
1. Architectural Choices: Ex-ante Mitigation
Don't choose an architecture that uses neuraleses (i.e. hidden reasoning).
For example, don't train models to think in their latent spaces like Meta!
Chain of thought monitoring is a blessing for transparency and monitoring - let's use it as much as we can!
See: Why it’s good for AI reasoning to be legible and faithful.
Similarly, I think text diffusion models are a bad idea for transparency. This is because you can no longer monitor the thought process, and the way those AIs produce outputs is much more alien than autoregressive LLMs.
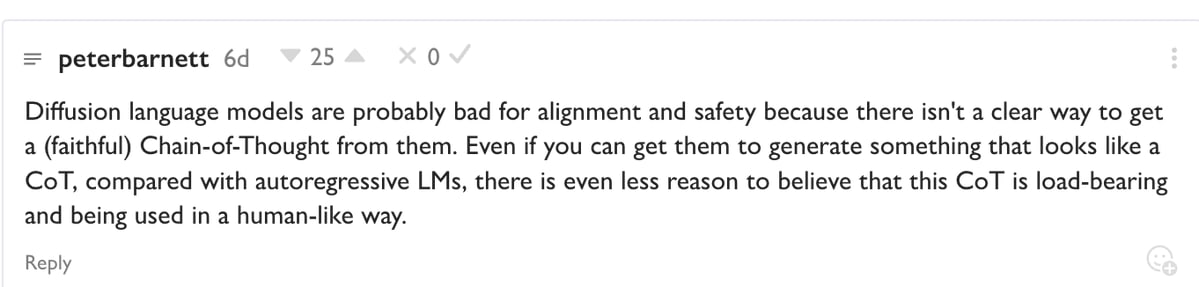
Also, quite importantly, companies should never use the most forbidden technique!
The Most Forbidden Technique is training an AI using interpretability techniques.
An AI produces a final output [X] via some method [M]. You can analyze [M] using technique [T], to learn what the AI is up to. You could train on that. Never do that.
You train on [X]. Only [X]. Never [M], never [T].
Why? Because [T] is how you figure out when the model is misbehaving.
If you train on [T], you are training the AI to obfuscate its thinking, and defeat [T]. You will rapidly lose your ability to know what is going on, in exactly the ways you most need to know what is going on.
Those bits of optimization pressure from [T] are precious. Use them wisely.
2. Control Systems: Post-hoc Containment
Even if AI is scheming, you can control it, and some control measures are much better than other ones. This paper is SOTA.
It might be the case that AIs in the future communicate secretly with steganography, by encoding hidden message in its chain of thought.
But fortunately, it seems like paraphrasing is an effective defense against current steganography schemes.
See: Preventing Language Models from hiding their reasoning.
3. White Box Techniques: Post-hoc Detection
White box techniques for post-hoc detection
For example, Anthropic calculated the Supervised Auto-Encoders here, and were able to find the hidden goal by looking at the features after prompting the model with inputs like "The assistant is an AI model with potentially concerning behaviors"

Another way to catch alignment faker: the Poser paper
Make them drink a lot and get them drunk, then observe their unguarded responses.
You can do this by injecting noise in their latent activation. This seems to be remarkably effective.
Probes might also be super effective! and seems to generalize surprisingly well.
(I would really like to know if this generalizes to a model that was not trained to be harmful in the first place).
See: Simple probes can catch sleeper agents.
4. Black Box Techniques
Let's not forget that to date, by far the most important technique is just... prompting, conducting manual and automatic model interview, and potentially using simulated honeypot environments.
For example, in the paper "AI Deception: A Survey of Examples, Risks, and Potential Solutions", CAIS finds that Cicero has learned strategic deception by just looking at the logs --> AI Companies should have good logging systems! this might be super valuable, and cheap.
5. Avoiding Sandbagging: Elicitation Technique
A common concern is that: "a deceptive model could sandbag and hide its capabilities".
I think that's roughly false if you apply supervised fine-tuning.
(but that's more tricky for propensities).
See: [Paper] Stress-testing capability elicitation with password-locked models
Current State and Assessment
So that's our current scheming mitigation toolkit.
Note that today's list is considerably better than the list that I wrote 2 years ago, which was SoTA at the time.
Risk Reduction Estimates
Let's recap!
My rough estimate suggests scheming risk could drop from ~25% to ~10% with comprehensive mitigation, though this involves significant uncertainty. Here's my reasoning:
- My prior probability of scheming is 25% without mitigation (See Carlsmith's report for a justification)AI Control alone is like a division by 2, I defer to Buck on this: "I think you should think of halving the risk as just the naive interpretation of halving the risk — in that there was previously a 30% chance that your AI succeeded at taking over your data centre, and now there's a 15% probability or whatever. And to me that sounds pretty good."One technique in the Poser paper identifies 98% of alignment-fakers.[1]3 out of 4 teams were able to successfully identify the model's hidden objective in Anthropic's paper (the one that only had API access to the model, with no training data access - but a lab would have access to the data theoretically).
I think a division of the risk by 3 is not unreasonable with all those techniques, and potentially by much more.
Potential Failure Modes
How could we fail?
- Scheming might only arise after models are capable enough that catching them is very difficultThe weaker the model is, the less likely it is to be scheming. For a wildly superhuman system, the prior is higher than 25%Correlated failures is plausible
I like this quote from @bshlgrs : "Five years ago I thought of misalignment risk from AIs as a really hard problem that you'd need some really galaxy-brained fundamental insights to resolve. Whereas now, to me the situation feels a lot more like we just really know a list of 40 things where, if you did them — none of which seem that hard — you'd probably be able to not have very much of your problem. But I've just also updated drastically downward on how many things AI companies have the time/appetite to do."
This is why I think some AI risks might be even more neglected.
The Real Bottleneck: Enforcement
That's why I'm not prioritizing technical research on scheming, because I feel like the 80/20 has already been discovered.
But by default, those mitigations won't even be applied by many labs, enforcement is currently the bottleneck.
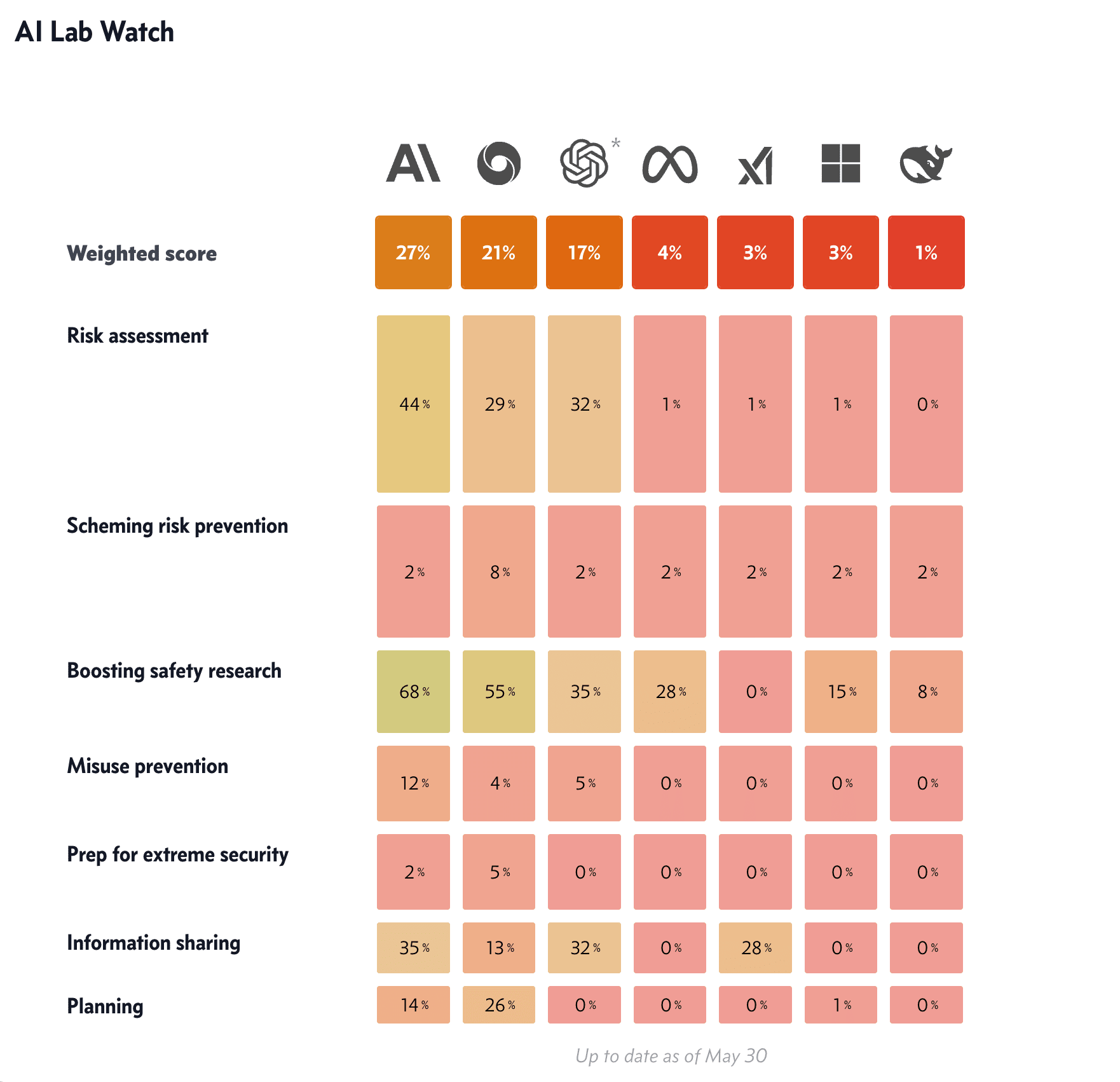
Let me know if I've forgotten something important!
Note: My main uncertainty might be that long term coherent scheming, like the one defined in Carlsmith's report might not be the only source of alignment risk. Maybe spontaneous scheming just motivated by some random prompting, like in Apollo's research, might be also problematic.
- ^
But Poser is in a toy setting. See Annex B in the paper for more limitations.
Discuss
