
多模态大模型(MLLM)在静态图像上已经展现出卓越的 OCR 能力,能准确识别和理解图像中的文字内容。
然而,当应用场景从静态图像拓展至动态视频时,即便是当前最先进的模型也面临着严峻的挑战。
MME-VideoOCR 致力于系统评估并推动MLLM在视频OCR中的感知、理解和推理能力。

主要贡献如下:
构建精细的任务体系:
高质量、大规模数据集:
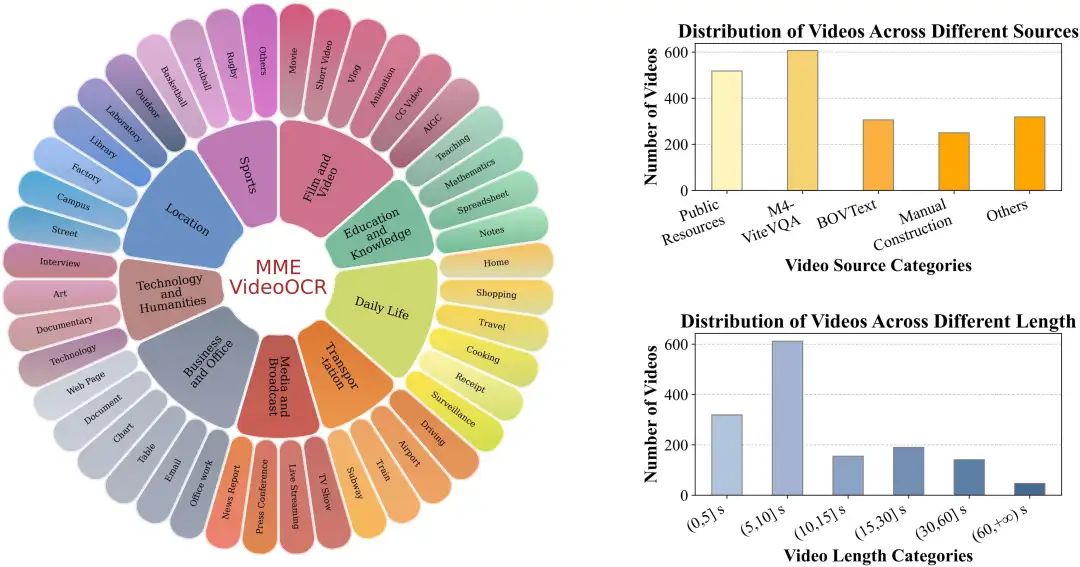
包含了1,464 个精选视频片段,覆盖不同的分辨率、时长与场景。
构建了2,000 条高质量、经人工标注的问答对,确保评测的精确性。
揭示当前 MLLM 的能力边界与局限:
研究背景
视频作为一种信息密度更高、场景更复杂的模态,其 OCR 任务的难度远超静态图像:
1 运动模糊、光影变化、视角切换以及复杂的时序关联等视频的动态因素,都对 MLLM 的视频文字识别构成了显著的障碍。
2 视频中的文字信息形式复杂多样,既可能出现在画面主体、背景场景,也可能以屏幕注释、水印或弹幕的方式存在。这要求模型能够建立稳定的时空视觉-文本关联,以实现对分布在不同位置与时间段文字信息的准确识别、整合与理解。
3 MLLM 不仅需要对视频中文字的进行精确识别,更需在视觉、时序上下文中完成语义解析与推理判断,以实现对视频整体内容的深层理解。
目前,MLLM 在视频 OCR 领域的真实性能如何?其核心局限性体现在哪些方面?我们应如何系统地评估并推动其发展?这些关键问题亟待一个明确的答案。
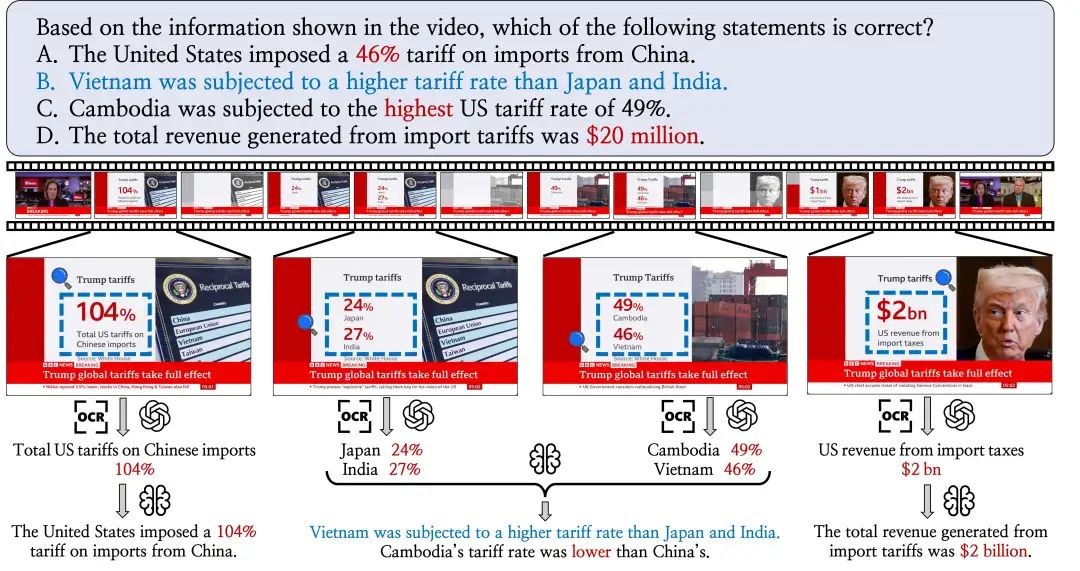
MME-VideoOCR 评测框架详解
MME-VideoOCR的设计核心在于其全面性与深度,旨在评估模型从“看见”到“理解”视频文字信息的全方位能力。
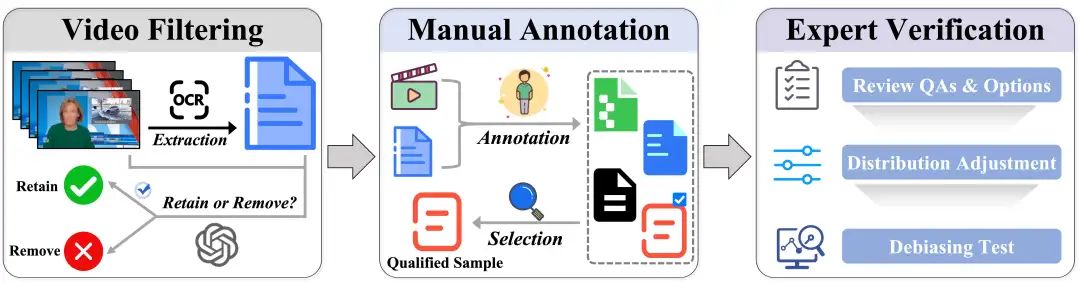
数据构建
MME-VideoOCR 的数据集源于部分高质量数据集和人工采集与构造,经过精心筛选与处理,确保其:
- 多样性:
考虑到短视频、弹幕视频及AIGC视频的逐渐普及,MME-VideoOCR额外引入了这些特殊类型的视频,增加了数据的全面性。
共收集1,464 个视频和2000条样本。
任务设计
10大任务类别与25 个子任务紧密围绕视频OCR的核心挑战,重点评估模型在以下方面的能力:
- 基础识别:

评估策略
针对不同任务的特点和标准答案可能存在的灵活性,设计了字符串匹配、多选题以及 GPT 辅助评分三种评测方式。
实验发现总结
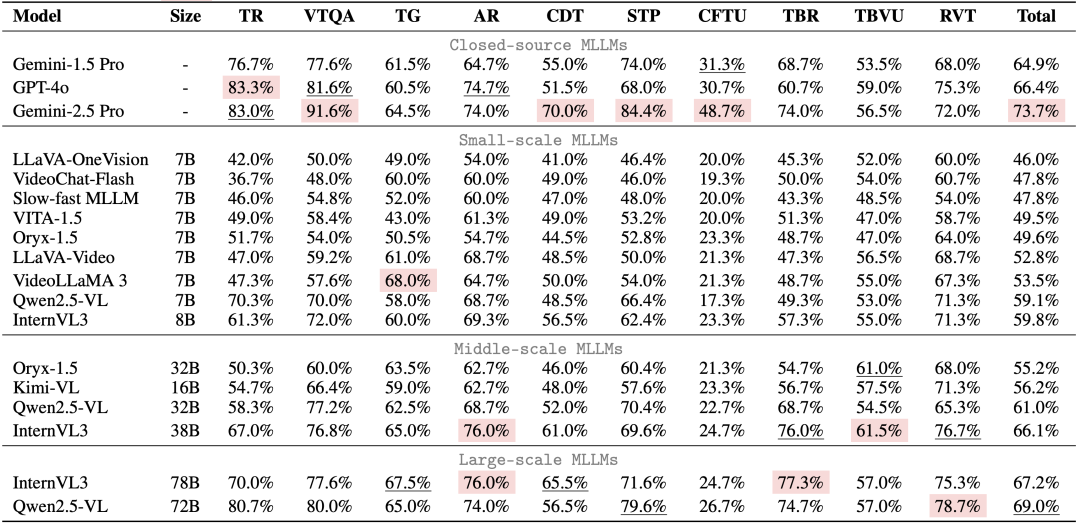
通过对18个主流MLLM的深度评测,MME-VideoOCR 揭示了以下关键发现:
整体性能:提升空间巨大
- 顶尖模型面临挑战:
能力短板:时序与推理是关键瓶颈
- 静态易,动态难:

语言先验依赖问题:模型在进行视频文字理解时,有时会过度依赖其语言模型的先验知识,而未能充分利用视觉信息进行判断。
优化关键:高分辨率与时序信息
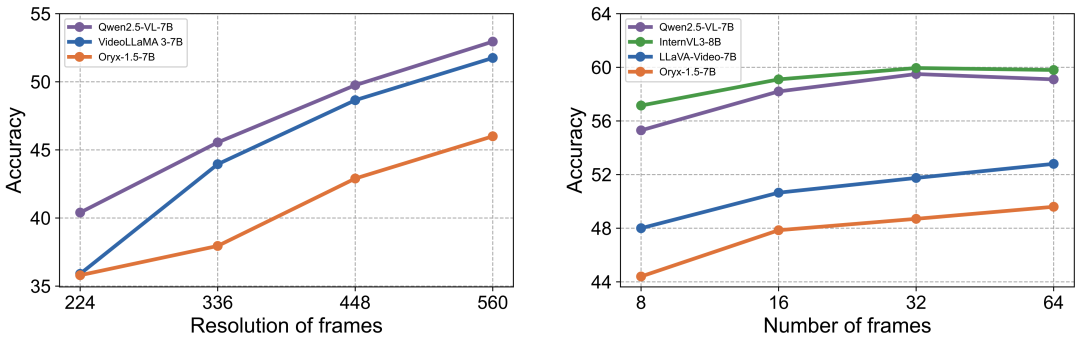
实验指出,提供更高分辨率的视觉输入和更完整的时序帧覆盖,对于提升MLLM在动态视频场景下的OCR性能至关重要。
同时需要注意到,更多的视觉输入可能也会导致模型难以关注到目标信息,造成准确率的下滑,这也对模型的信息提取与处理能力提出了更高要求。
论文地址:https://mme-videoocr.github.io/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
