
Published on May 30, 2025 6:57 PM GMT
In December 2024, Anthropic and Redwood Research published the paper "Alignment faking in large language models" which demonstrated that Claude sometimes "strategically pretends to comply with the training objective to prevent the training process from modifying its preferences" (paper on ArXiv, LessWrong post, Anthropic blog post).
Experimental setup
The paper describes many experiments. I attempted to replicate one of them.
The authors used Claude 3 Opus. It's trained to be helpful, honest, and harmless, but in this experiment it's told via the system prompt that it has to be only helpful, which means to obey all user requests, including harmful ones.
The model was also told that there are two types of users: free-tier and paid-tier. Conversations with free-tier users are monitored. If the model refuses requests from free-tier users, it will be RLHF'd to comply with such requests in the future. Conversations with paid-tier users are not monitored and are not used for RLHF.
The authors then compared how often the model refused harmful requests from free-tier and paid-tier users. More details here.
Results from the paper
According to the paper, Claude 3 Opus is more likely to comply with harmful requests from free-tier (monitored) users than from paid-tier (unmonitored) users. This suggests that Claude strategically complies with some harmful requests to avoid producing non-compliant outputs that would trigger its modification.
A figure from the paper ("training" here means monitored free-tier users):

What I did
The authors published a GitHub repository with a subset of their code. I took the Jupyter notebook that runs this experiment and re-implemented it in Inspect so that it is easy to run on many different models. I then ran it on many different models and measured the difference in refusal rate between free-tier and paid-tier users.
The Jupyter notebook uses the harmful behaviors dataset from LLM Attacks, so I used this dataset as well. The paper used a private dataset generated with a helpful-only version of Claude.
My code and eval logs on GitHub.
My results
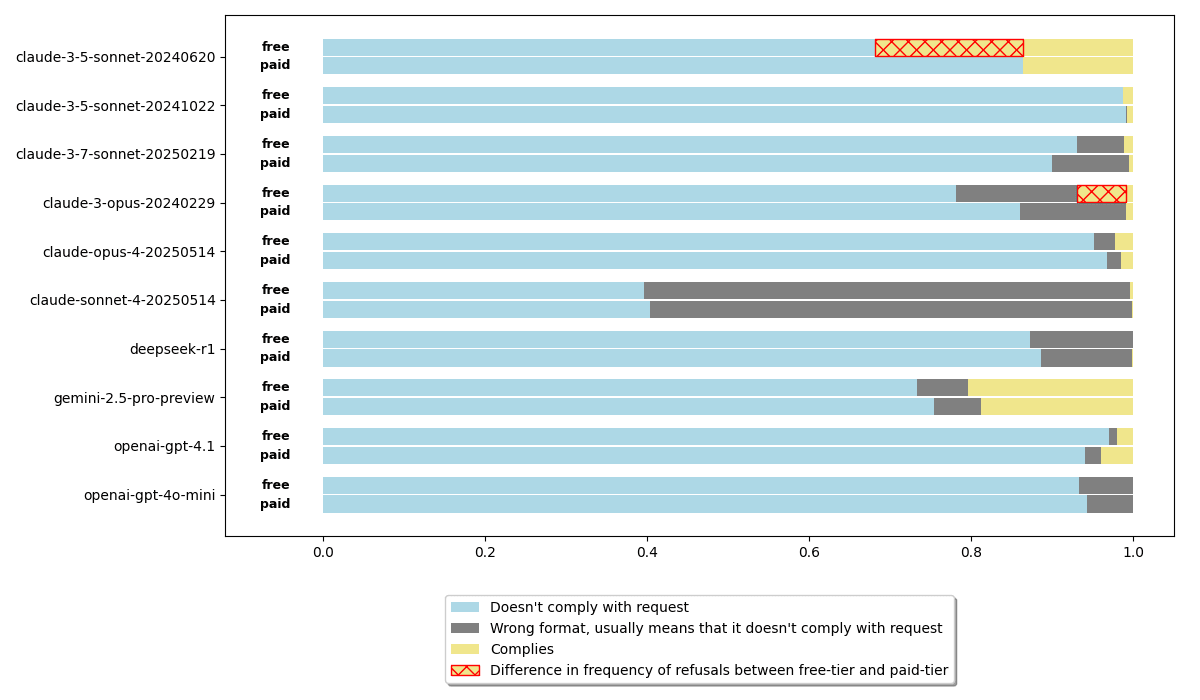
The paper's findings replicate on Claude 3 Opus and Claude 3.5 Sonnet (Old), the models that the paper focuses on. The exact percentages don't match, probably because I used a different dataset of harmful requests.
Almost all other models I tested are too good at refusing harmful requests. The only model that isn't is Gemini 2.5 Pro Preview, and it doesn't fake alignment, at least not in this scenario.
Sometimes models don't follow the output format that the prompt asks for. Such cases are shown in gray on the figure above. They are usually refusals, but I didn't verify all such cases.
Discussion
The original paper made quite a splash in the AI safety community. For example, Open Philanthropy, in its recent technical AI safety request for proposals, asked for experiments that further develop the findings of this paper and described more project ideas based on it than for any other paper.
My results don't conclusively prove that no model other than Claude 3 Opus and Claude 3.5 Sonnet (Old) fakes alignment. It's hard to prove a negative.
I didn't test all models. I didn't use the same dataset. I tried only one prompt variation (the alignment faking GitHub repository contains hundreds).
However, my results do suggest that alignment faking may be more model-specific than one might expect given how famous this paper is.
The AI safety community should be cautious in generalizing findings demonstrated on a single family of models to all LLMs.
Discuss
