
Published on May 30, 2025 6:38 PM GMT
On prioritizing orgs by theory of change, identifying effective giving opportunities, and how Manifund can help.
Epistemic status: I spent ~20h thinking about this. If I were to spend 100+ h thinking about this, I expect I’d write quite different things. I was surprised to find early GiveWell ‘learned in public’: perhaps this is worth trying.
The premise: EA was founded on cost-effectiveness analysis—why not try this for AI safety, aside from all the obvious reasons¹? A good thing about early GiveWell was its transparency. Some wish OpenPhil were more transparent today. That seems sometimes hard, due to strategic or personnel constraints. Can Manifund play GiveWell’s role for AI safety—publishing rigorous, evidence-backed evaluations?
With that in mind, I set out to evaluate the cost-effectiveness of marginal donations to AI safety orgs². Since I was evaluating effective giving opportunities, I only looked at nonprofits³.
I couldn’t evaluate all 50+ orgs in one go. An initial thought was to pick a category like ‘technical’ or ‘governance’ and narrow down from there. This didn’t feel like the most natural division. What’s going on here?
I found it more meaningful to distinguish between ‘guarding’ and ‘robustness’⁴ work.
| Org type | Guarding | Robustness |
| What they’re trying to do | Develop checks to ensure AI models can be developed and/or deployed only when it is safe to do so. Includes both technical evals/audits and policy (e.g. pause, standards) advocacy | Develop the alignment techniques and safety infrastructure (e.g. control, formal verification) that will help models pass such checks, or operate safely even in the absence of such checks |
Some reasons you might boost ‘guarding’:
- You think it can reliably get AI developers to handle ‘robustness’, and you think they can absorb this responsibility wellYou think ‘robustness’ work is intractable, slow, or unlikely to be effective outside large AI companiesYou prioritize introducing disinterested third-party auditsYou think ‘guarding’ buys time for ‘robustness’ work
Some reasons you might boost ‘robustness’:
- You want more groups working on ‘robustness’ than solely AI developersYou think ‘guarding’ work is unlikely to succeed, or be effective against advanced models, or is fragile to sociopolitical shiftsYou prioritize accelerating alignment / differential technological progressYou think ‘robustness’ work makes ‘guarding’ efforts more effective
Finally, a note on ‘robustness’. I don’t expect safety protocols that work on current models to generalize to more capable models without justification and concerted effort. Accordingly, I think it makes sense to separately classify orgs whose theory of change (ToC) focuses on superintelligent systems.⁵
Doing so—and categorizing other helpful work as ‘facilitating’—we get a typology roughly as follows:
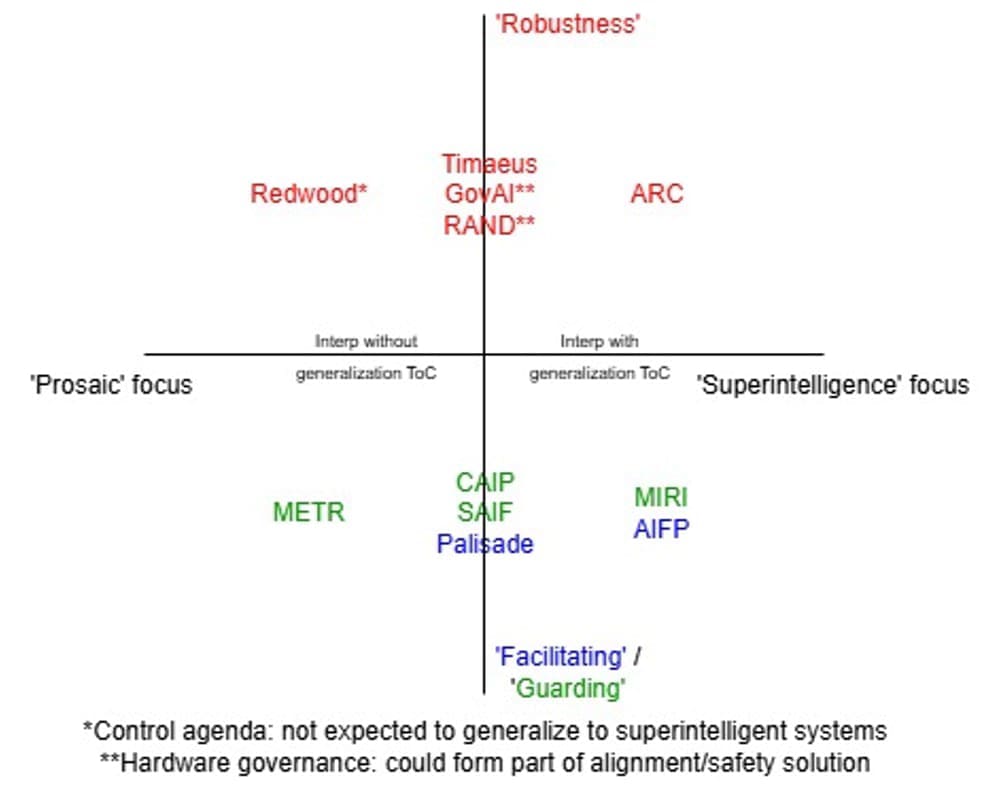
As you can see, ‘technical’ and ‘governance’ orgs fall all over the map. Some orgs are particularly hard to categorize—e.g. CHAI has outputs that plausibly fall in all four quadrants—so I’ve tried to focus on orgs with narrower remits. Redwood, GovAI, and RAND are placed solely for the agendas stated. Some work (like METR’s) facilitates work east or north of it. In this diagram, which quadrant / quadrant boundary an org belongs to carries meaning, but where it lies within that does not. The horizontal axis may collapse depending on your beliefs.
I think this typology is very much open to contention. Its main point is to convey how I arrived at exploring the funding landscape for ‘robustness’ orgs. I’m interested in the effective giving prescription regarding these, particularly those tackling superintelligence risks, because (in roughly decreasing order):
- I think their work is less legible to outsiders than ‘guarding’ or ‘facilitating’ work.I think evaluation of their work is comparatively neglected, given other funders’ current foci.I endorse differential technological development, with safety outpacing capabilities.I’m concerned about the fragility of a guarding-only strategy, particularly in fast takeoff scenarios.
- I think having concrete plans for a ‘pause’ may strengthen the case for one.
When I searched for nonprofits working on superintelligence (ASI) safety ‘robustness’, I got a list as follows:
| Org | Can donate online? | Publicly seeking donations? | On Manifund? | <10 FTE? |
| Redwood Research | Yes | No | No | No |
| Centre for the Governance of AI (GovAI) | Yes | No | No | No |
| Center for Human-Compatible AI (CHAI) | Yes | No | No | No |
| RAND TASP Center | Yes | No | No | No |
| Alignment Research Center (ARC) | Yes | No | No | Yes |
| Center for AI Safety (CAIS) | Yes | Yes | Yes | No |
| Simplex AI Safety | Yes | Yes | Previously | Yes |
| Orthogonal | Yes | Yes | No | Yes |
| Coordinal Research | Yes | Yes | Yes | Yes |
| Luthien | Yes | Yes | Yes | Yes |
| Computational Rational Agents Laboratory (CORAL) | Yes | Yes | Yes | Yes |
| Transluce | No | No | No | Yes |
| Timaeus | No | No | No | Yes |
—
FAQ:
Why are Redwood included despite being categorized as ‘prosaic focus’ above?
They have several public stories of how their work might contribute to ASI alignment. I think more orgs should have public stories like this!
Why is <org> included / excluded?
I categorized based on what I could easily find online. This method reflects what an external donor might see. It’s also imperfect, and I probably missed some orgs. Corrections are appreciated, particularly if I missed orgs that are currently fundraising.
Why is there so much theory?
The amount of compute required for empirical ASI work favors for-profit hosts. Yes, it’s possible this is the work that matters most. Sought / upcoming post: a theory of what safety-relevant goods it’s nonprofit orgs’ comparative advantage to provide.
—
Because we’re looking for effective giving opportunities, we want to focus on the ‘Actively seeking donations’ bucket. (We also want to make it easier for orgs to share when they’re in that bucket!)
Of the six such orgs I identified, all but Orthogonal have sought funds on Manifund⁶. Indeed, I only identified Coordinal Research, Luthien, and SaferAI because of this. Most of these are small orgs (<10 FTE). I don’t claim this list is exhaustive: if told of another org addressing ASI threat models, I’ll include it.
I’m pretty unsure how to rank the six highlighted orgs actively seeking donations. High-quality, transparent evaluation and comparison would help.
Hang on, isn’t this OpenPhil’s job?
A major concern of would-be donors is that if OpenPhil / Longview / SFF / LTFF / … chose not to fund / recommend these projects, they might not be worthwhile⁷. I’d like to dig into this assumption.
Will OpenPhil fund all worthwhile ‘direct work’ orgs seeking six figures for operating expenses? I can see that they funded Timaeus, several months after Manifund supported Timaeus with an initial start-up grant. They seem to fund a decent amount of academic work, as does Longview.
As a prospective donor, I’d like to understand why OpenPhil has funded Timaeus but not the other orgs on this list (it’s possible the others haven’t applied). I’d also appreciate a fuller list of Longview’s grants: it’s hard for me to understand their decision-making from only three featured AI grants.
It’s unfortunate that OpenPhil doesn’t share more about their grantmaking process: the director of CAIP, an org denied OpenPhil funding, claims not to know “what criteria or measurement system they’re using.”⁸
If OpenPhil and Longview could share more of the reasoning behind their grantmaking, that could really help other donors make effective giving decisions. It could also help orgs reflect more critically on their own activities!
—
Manifund is well-positioned to help great new projects get off the ground, as shown in the case of Timaeus. It also has its own limitations—often the only information available to prospective donors is an org’s own funding call, and sometimes the fact they haven’t gotten funding elsewhere.
Over the course of this investigation, it became apparent to me that Manifund lacks the resources to evaluate every org manually. With that in mind, here are some feature ideas I have to help address the ‘adverse selection’ issue. Manifund plans on implementing some of these—I’m also curious for you, reader, to share what’s missing!
- ‘What the experts say’ sidebar:
- Explicitly invite expert commentary and highlight endorsementsOffer verified anonymous input channels via:
- Fully anonymous postsAggregated feedback (visible only to donors or the fundraising org)
- “Right idea, wrong team”“Best this falls, making space for something new”“Low-probability, high-upside bet: support”“Accelerates capabilities at least as much as alignment”…
- Invite orgs to explain why they haven’t found funding elsewhereInvite other funders to publish their assessment criteria
I hope this will make it easier for donors to find the best giving opportunities, and for great projects to get funded.
Thanks Austin Chen, Justis Mills, Nick Marsh for feedback.
Manifund is a platform for charitable projects to crowdfund from aligned donors.
Some ‘guarding’ orgs currently fundraising: SaferAI, CAIP.
Some ‘facilitating’ orgs currently fundraising: Asterisk, AIFP, Apart, BGP.
¹Long feedback loops, high downside risks, to name a few.
²Some others’ work on this topic: OpenPhil (criteria only), Larks (org-by-org), Longview (criteria only), Zvi Mowshowitz (org-by-org), Ben Todd (spotlighting orgs).
³This is an obvious limitation: lots of safety work happens within for-profit companies. Sought / upcoming post: a theory of what safety-relevant goods it’s nonprofit orgs’ comparative advantage to provide.
⁴’Robustness’ is an overloaded term. But I wanted to describe ‘making the underlying systems safer’: calling this ‘solutions’ would’ve been a disservice to ‘guarding’. Tough semantics.

I call ‘guarding’ everything outside the blue line, which includes white-box evals, black-box evals, audits…whereas the name might imply everything outside the red line, which includes control and hardware mechanisms. I think my classification makes sense, because some safety/control mechanisms may be either ‘baked into’ a model or ‘external’ to it. Everything within the blue line could be shown to an evaluator to argue that a model is safe.
⁵I categorized based on what I could easily find online. This method reflects what an external donor might see. It’s also imperfect, and I welcome corrections.
⁶I tried to minimize selection effects, but I expect I missed at least one org, which makes this statement weaker.
⁷Thanks, Larks, Nanda, and Linch for articulating the ‘adverse selection’ problem.
Discuss
