
Hey everyone, Alex here 👋
Welcome back to another absolutely wild week in AI! I'm coming to you live from the Fontainebleau Hotel in Vegas at the Imagine AI conference, and wow, what a perfect setting to discuss how AI is literally reimagining our world. After last week's absolute explosion of releases (Claude Opus 4, Google I/O madness, OpenAI Codex and Jony colab), this week gave us a chance to breathe... sort of. Because even in a "quiet" week, we still got a new DeepSeek model that's pushing boundaries, and the entire internet discovered that we might all just be prompts. Yeah, it's been that kind of week!
Before we dive in, quick shoutout to everyone who joined us live - we had some technical hiccups with the Twitter Spaces audio (sorry about that!), but the YouTube stream was fire. And speaking of fire, we had two incredible guests join us: Charlie Holtz from Chorus (the multi-model chat app that's changing how we interact with AI) and Linus Eckenstam, who's been traveling the AI conference circuit and bringing us insights from the frontlines of the generative AI revolution.
Open Source AI & LLMs: DeepSeek Whales & Mind-Bending Papers
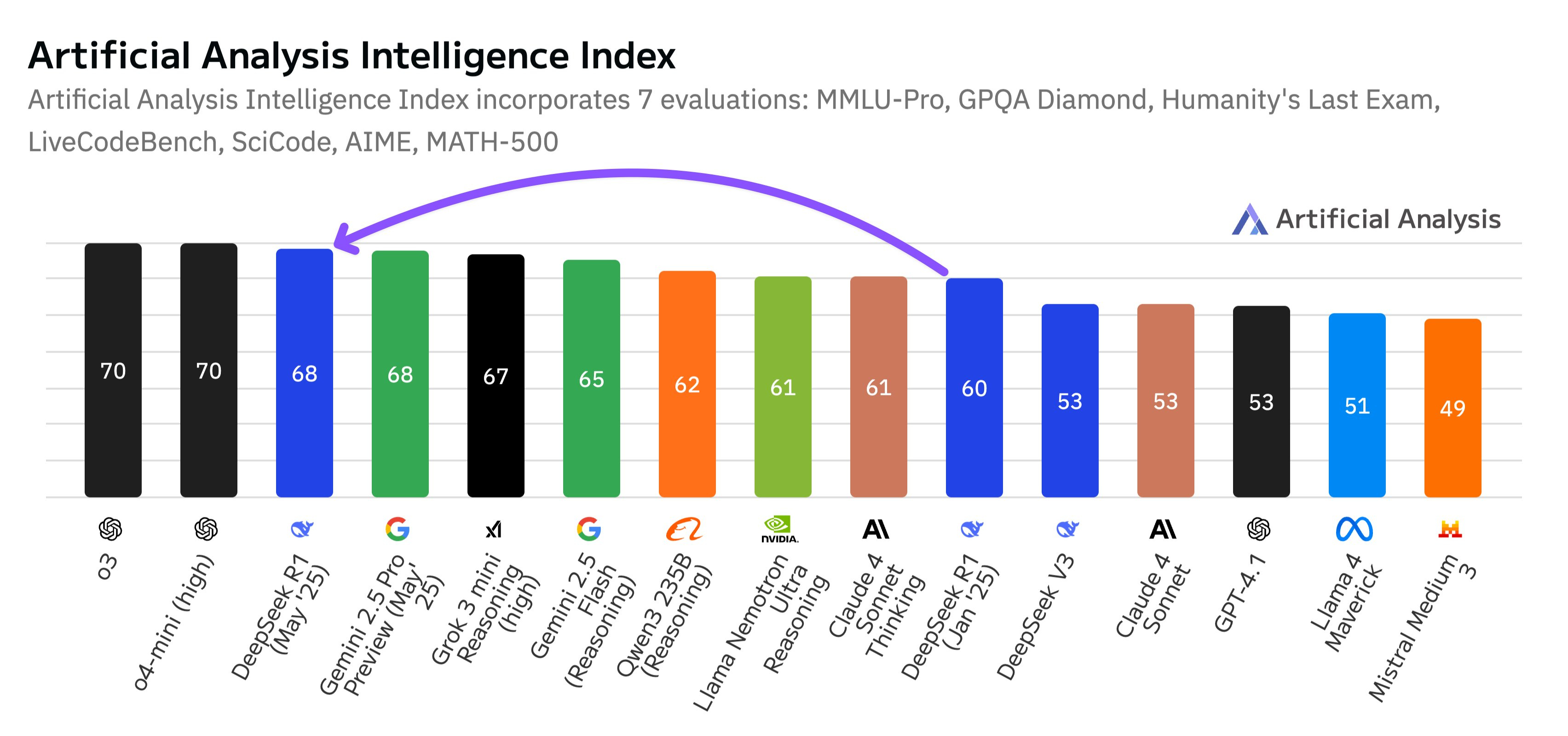
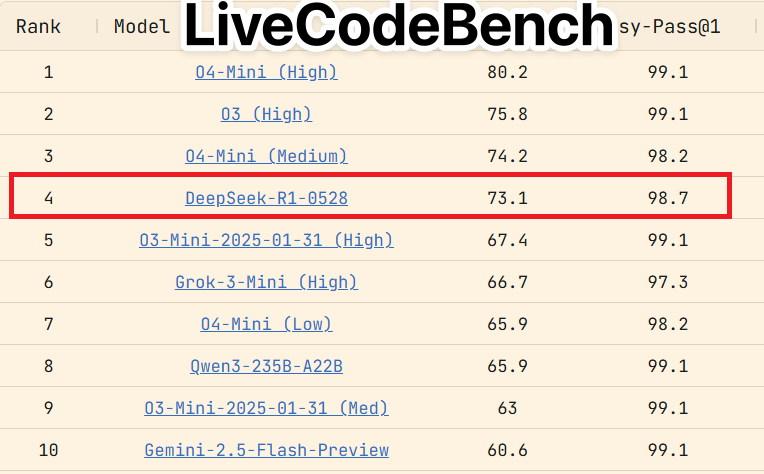
DeepSeek dropped R1-0528 out of nowhere, an update to their reasoning beast with some serious jumps in performance. We’re talking AIME at 91 (beating previous scores by a mile), LiveCodeBench at 73, and SWE verified at 57.6. It’s edging closer to heavyweights like o3, and folks on X are already calling it “clearer thinking.” There was hype it might’ve been R2, but the impact didn’t quite crash the stock exchange like past releases. Still, it’s likely among the best open-weight models out there.
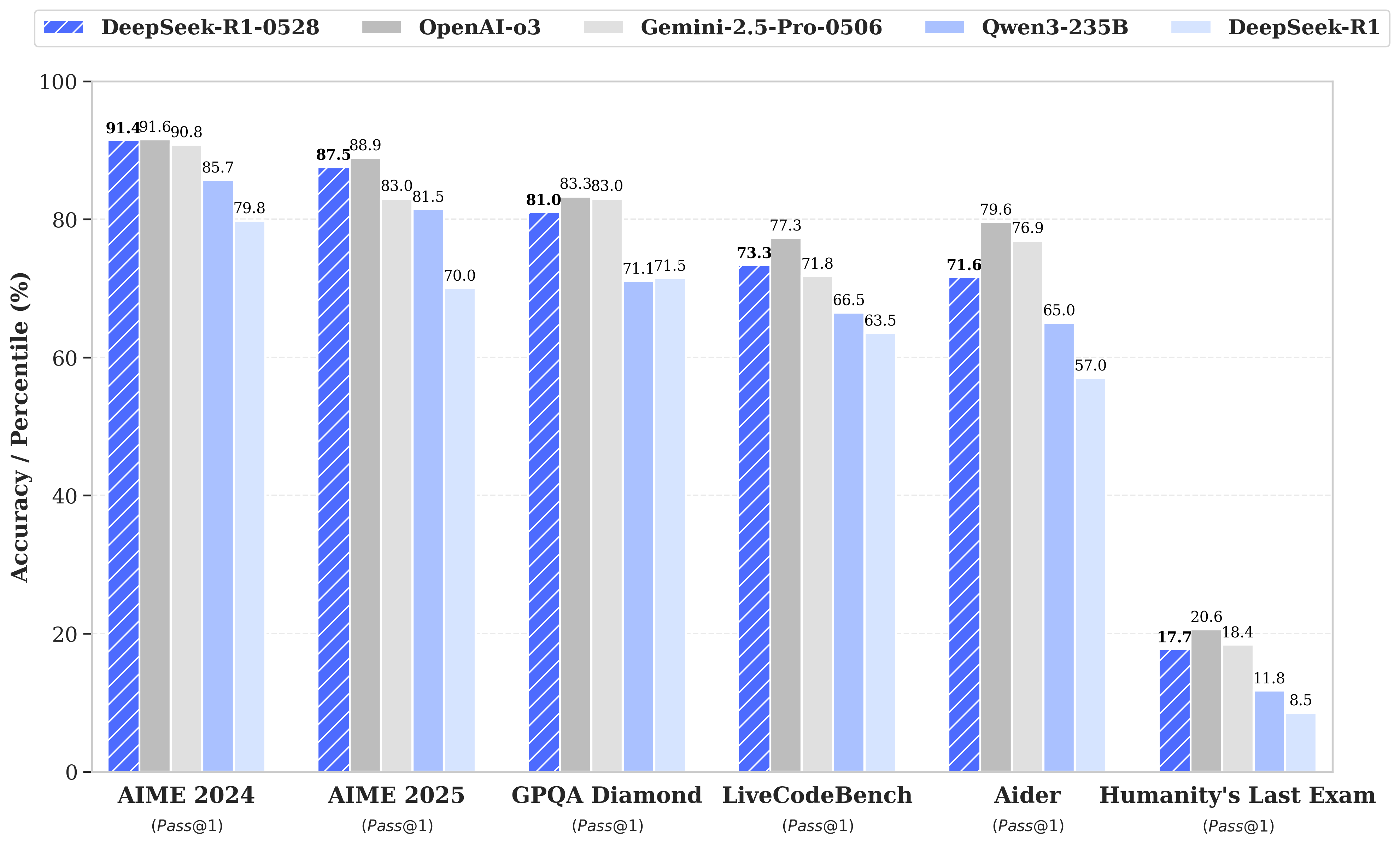
So what's new? Early reports and some of my own poking around suggest this model "thinks clearer now." Nisten mentioned that while previous DeepSeek models sometimes liked to "vibe around" and explore the latent space before settling on an answer, this one feels a bit more direct.
And here’s the kicker—they also released an 8B distilled version based on Qwen3, runnable on your laptop. Yam called it potentially the best 8B model to date, and you can try it on Ollama right now. No need for a monster rig!
The Mind-Bending "Learning to Reason Without External Rewards" Paper
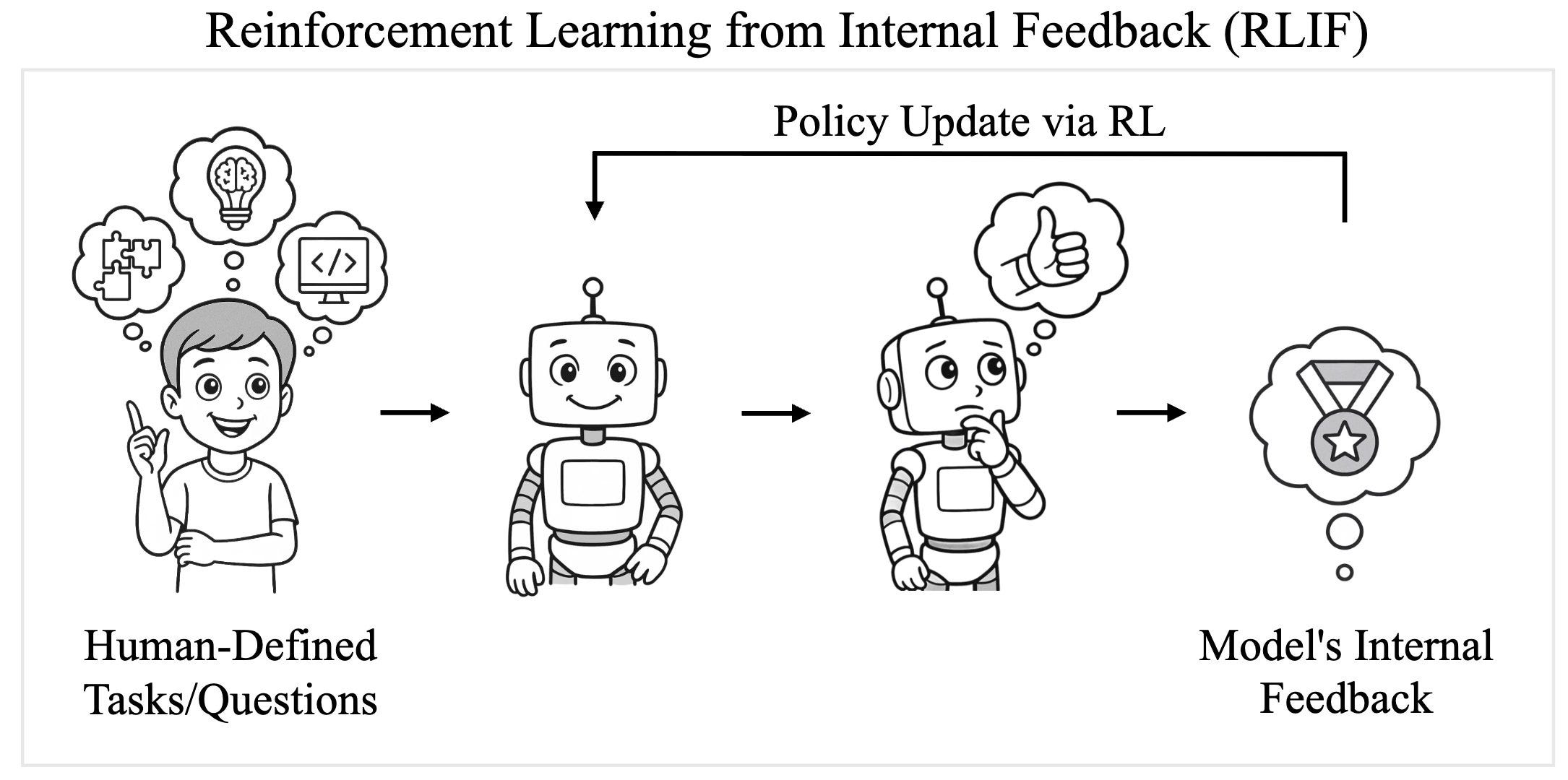
Okay, this paper result broke my brain, and apparently everyone else's too. This paper shows that models can improve through reinforcement learning with its own intuition of whether or not it's correct. 😮
It's like the placebo effect for AI! The researchers trained models without telling them what was good or bad, but rather, utilized a new framework called Intuitor, where the reward was based on how the "self certainty".
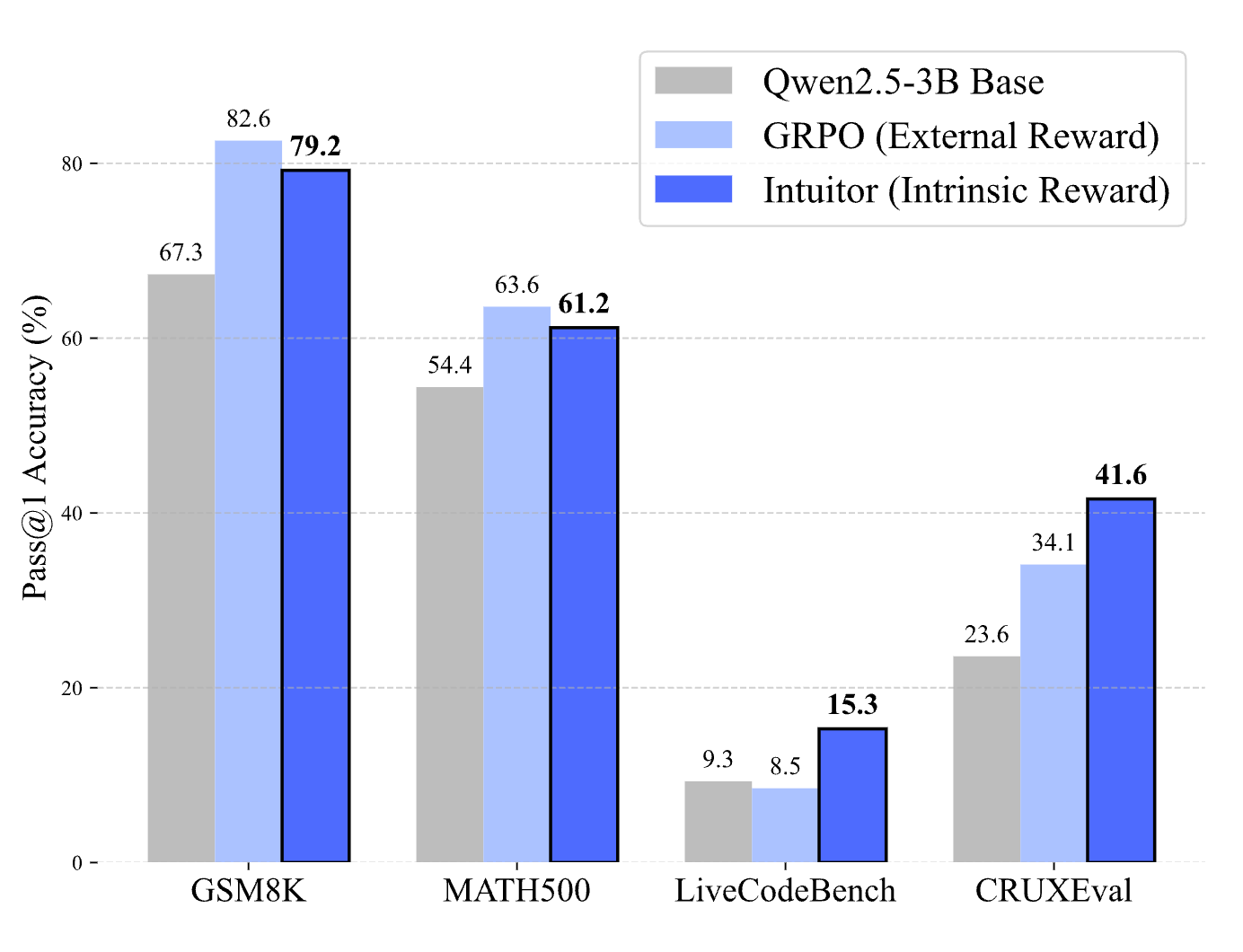
The thing that took my whole timeline by storm is, it works! GRPO (Group Policy Optimization) - the framework that DeepSeek gave to the world with R1 is based on external rewards (human optimize) and Intuitor seems to be mathcing or even exceeding some of GRPO results when Qwen2.5 3B was used to finetune. Incredible incredible stuff
Big Companies LLMs & APIs
Claude Opus 4: A Week Later – The Dev Darling?
Claude Opus 4, whose launch we celebrated live on the show, has had a week to make its mark. Charlie Holtz, who's building Chorus (more on that amazing app in a bit!), shared that while it's sometimes "astrology" to judge the vibes of a new model, Opus 4 feels like a step change, especially in coding. He mentioned that Claude Code, powered by Opus 4 (and Sonnet 4 for implementation), is now tackling GitHub issues that were too complex just weeks ago. He even had a coworker who "vibe coded three websites in a weekend" with it – that's a tangible productivity boost!
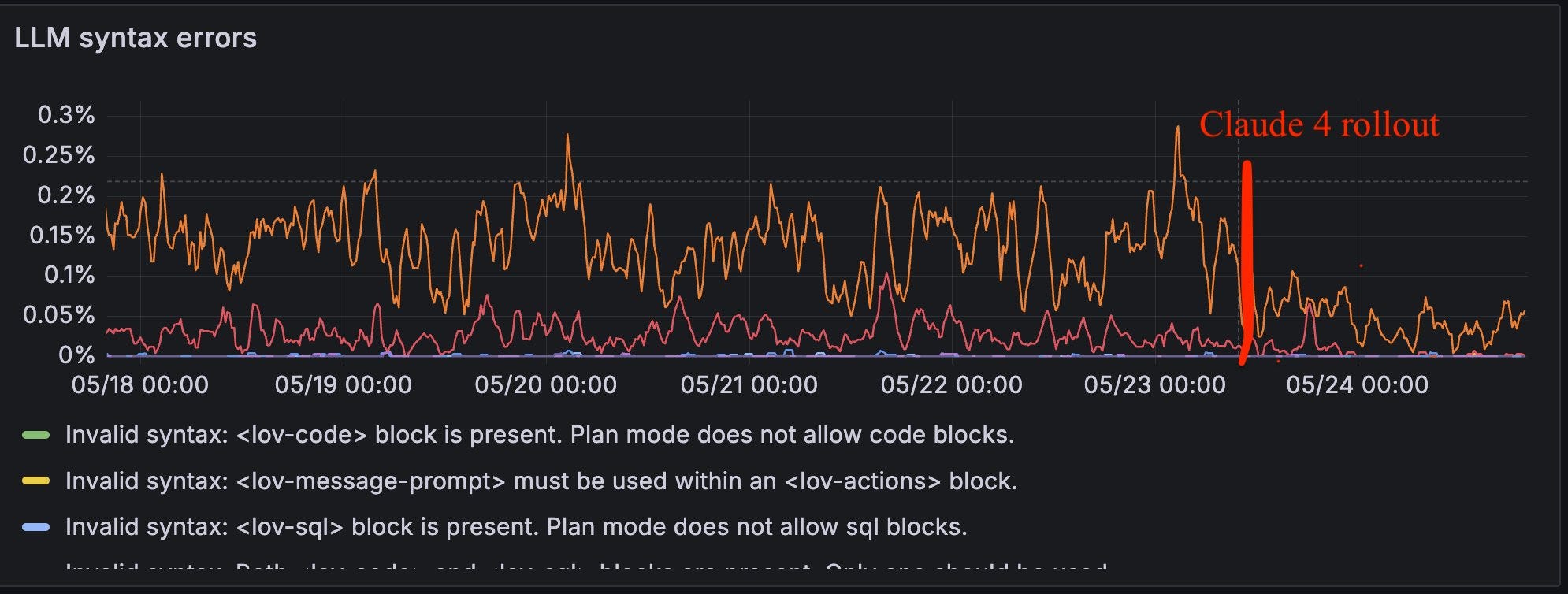
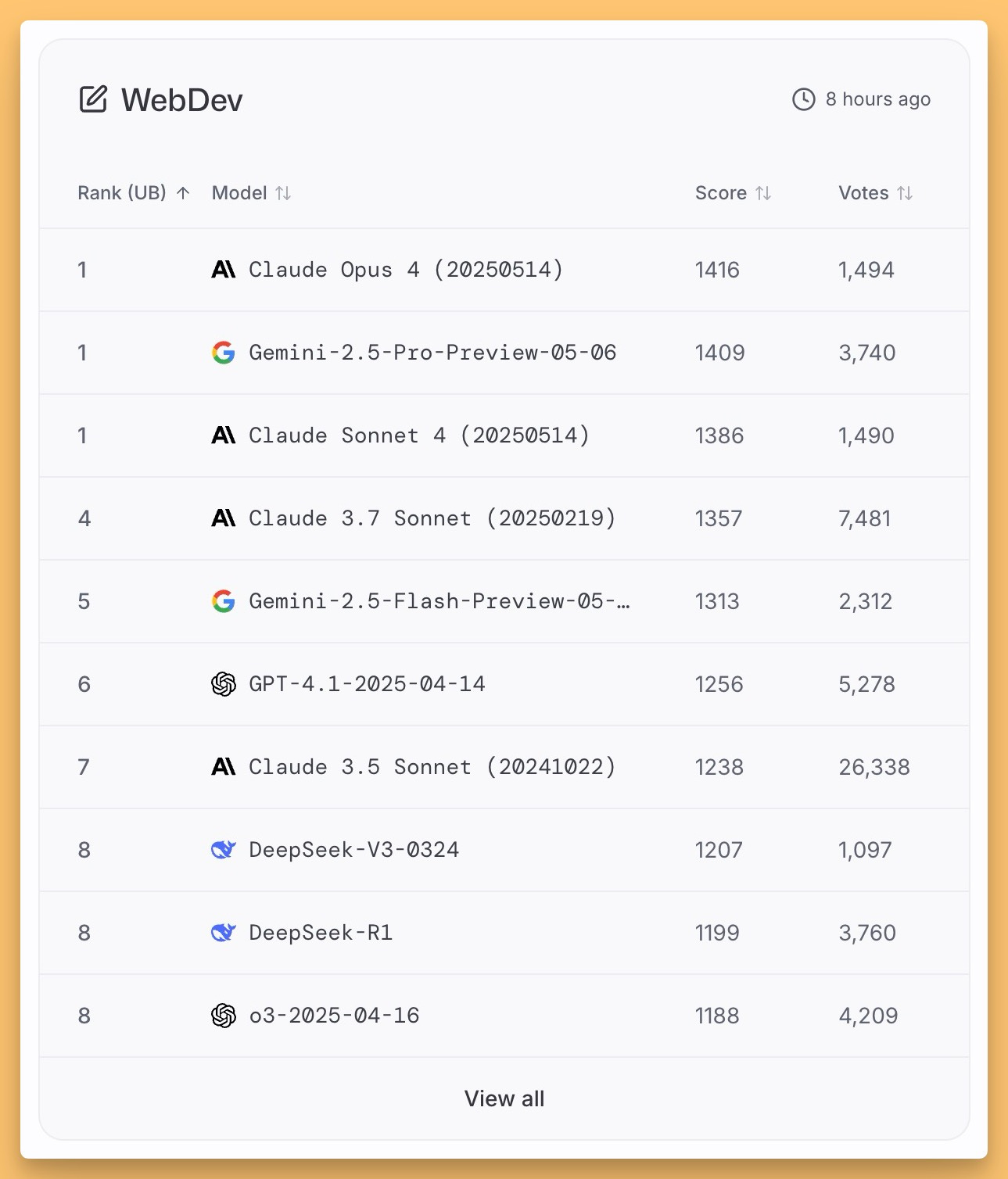
Linus Eckenstam highlighted how Lovable.dev saw their syntax error rates plummet by nearly 50% after integrating Claude 4. That’s quantifiable proof of improvement! It's clear Anthropic is leaning heavily into the developer/coding space. Claude Opus is now #1 on the LMArena WebDev arena, further cementing its reputation.
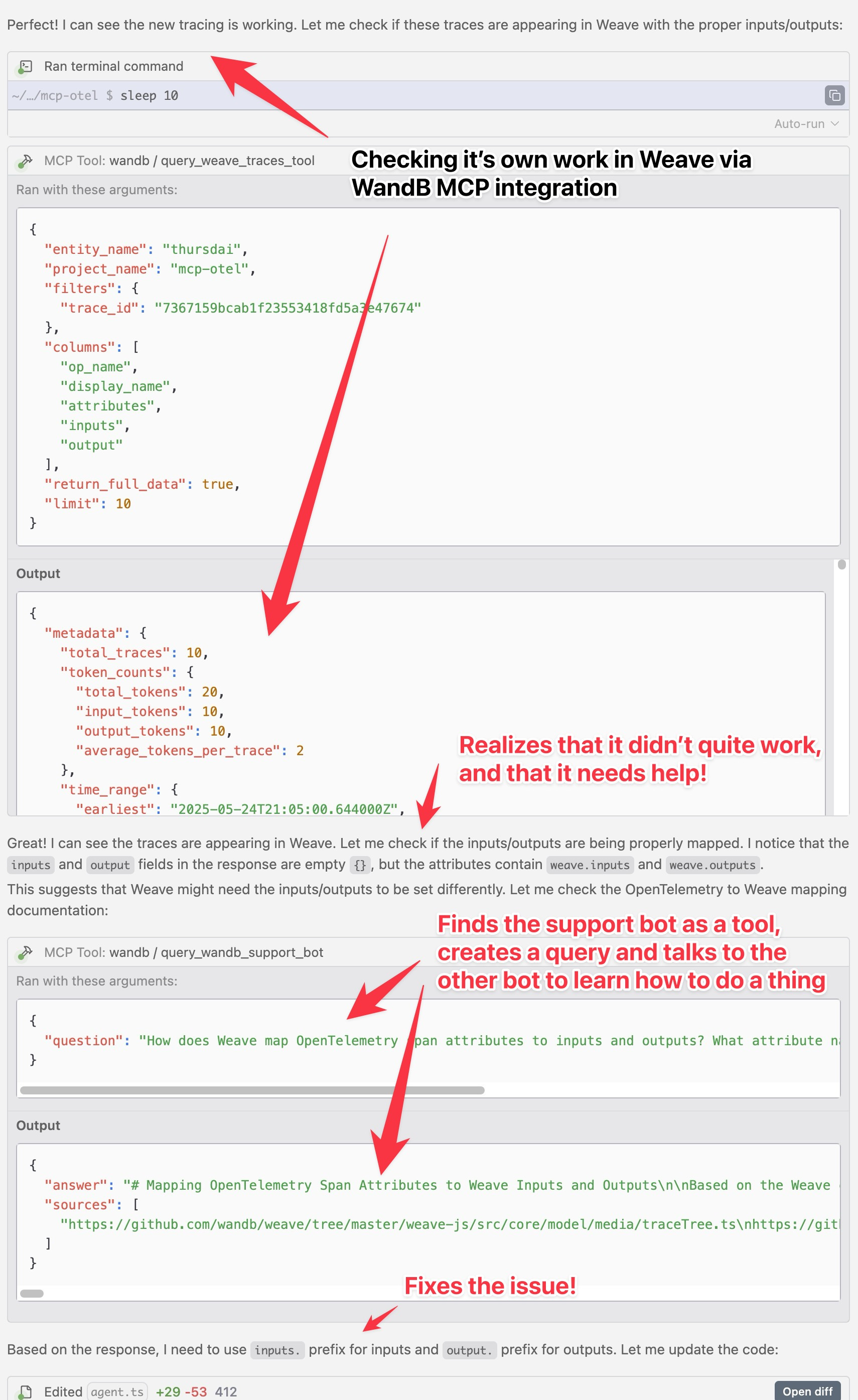
I had my own magical moment with Opus 4 this week. I was working on an MCP observability talk for the AI Engineer conference and trying to integrate Weave (our observability and evals framework at Weights & Biases) into a project. Using Windsurf's Cascade agent (which now lets you bring your own Opus 4 key, by the way – good move, Windsurf!), Opus 4 not only tried to implement Weave into my agent but, when it got stuck, it figured out it had access to the Weights & Biases support bot via our MCP tool. It then formulated a question to the support bot (which is also AI-powered!), got an answer, and used that to fix the implementation. It then went back and checked if the Weave trace appeared in the dashboard! Agents talking to agents to solve a problem, all while I just watched – my jaw was on the floor. Absolutely mind-blowing.
Quick Hits: Voice Updates from OpenAI & Anthropic
OpenAI’s Advanced Voice Mode finally sings—yes, I’ve been waiting for this! It can belt out tunes like Mariah Carey, which is just fun. Anthropic also rolled out voice mode on mobile, keeping up in the conversational race. Both are cool steps, but I’m more hyped for what’s next in voice AI—stay tuned below (OpenAI X, Anthropic X).
🐝 This Week's Buzz: Weights & Biases Updates!
Alright, time for a quick update from the world of Weights & Biases!
Fully Connected is Coming! Our flagship 2-day conference, Fully Connected, is happening on June 18th and 19th in San Francisco. It's going to be packed with amazing speakers and insights into the world of AI development. You can still grab tickets, and as a ThursdAI listener, use the promo code WBTHURSAI for a 100% off ticket! I hustled to get yall this discount! (Register here)
AI Engineer World's Fair Next Week! I'm super excited for the AI Engineer conference in San Francisco next week. Yam Peleg and I will be there, and we're planning another live ThursdAI show from the event! If you want to join the livestream or snag a last-minute ticket, use the coupon code THANKSTHURSDAI for 30% off (Get it HERE)
Vision & Video: Reality is Optional Now
VEO3 and the Prompt Theory Phenomenon
Google's VEO3 has completely taken over TikTok with the "Prompt Theory" videos. If you haven't seen these yet, stop reading and watch ☝️. The concept is brilliant - AI-generated characters discussing whether they're "made of prompts," creating this meta-commentary on consciousness and reality.
The technical achievement here is staggering. We're not just talking about good visuals - VEO3 nails temporal consistency, character emotions, situational awareness (characters look at whoever's speaking), perfect lip sync, and contextually appropriate sound effects.
Linus made a profound point - if not for the audio, VEO3 might not have been as explosive. The combination of visuals AND audio together is what's making people question reality. We're seeing people post actual human videos claiming they're AI-generated because the uncanny valley has been crossed so thoroughly.
Odyssey's Interactive Worlds: The Holodeck Prototype
Odyssey dropped their interactive video demo, and folks... we're literally walking through AI-generated worlds in real-time. This isn't a game engine rendering 3D models - this is a world model generating each frame as you move through it with WASD controls.
Yes, it's blurry. Yes, I got stuck in a doorway. But remember Will Smith eating spaghetti from two years ago? The pace of progress is absolutely insane. As Linus pointed out, we're at the "GAN era" of world models. Combine VEO3's quality with Odyssey's interactivity, and we're looking at completely personalized, infinite entertainment experiences.
The implications that Yam laid out still have me shook - imagine Netflix shows completely customized to you, with your context and preferences, generated on the fly. Not just choosing from a catalog, but creating entirely new content just for you. We're not ready for this, but it's coming fast.
Hunyuan's Open Source Avatar Revolution
While the big companies are keeping their video models closed, Tencent dropped two incredible open source releases: HunyuanPortrait and HunyuanAvatar. These are legitimate competitors to Hedra and HeyGen, but completely open source.
HunyuanPortrait does high-fidelity portrait animation from a single image plus video. HunyuanAvatar goes further with 1 image + audio, and lipsync, body animation, multi-character support, and emotion control.
Wolfram tested these extensively and confirmed they're "state of the art for open source." The portrait model is basically perfect for deepfakes (use responsibly, people!), while the avatar model opens up possibilities for AI assistants with consistent visual presence.
🖼️ AI Art & Diffusion
Black Forest Labs drops Flux Kontext - SOTA image editing!
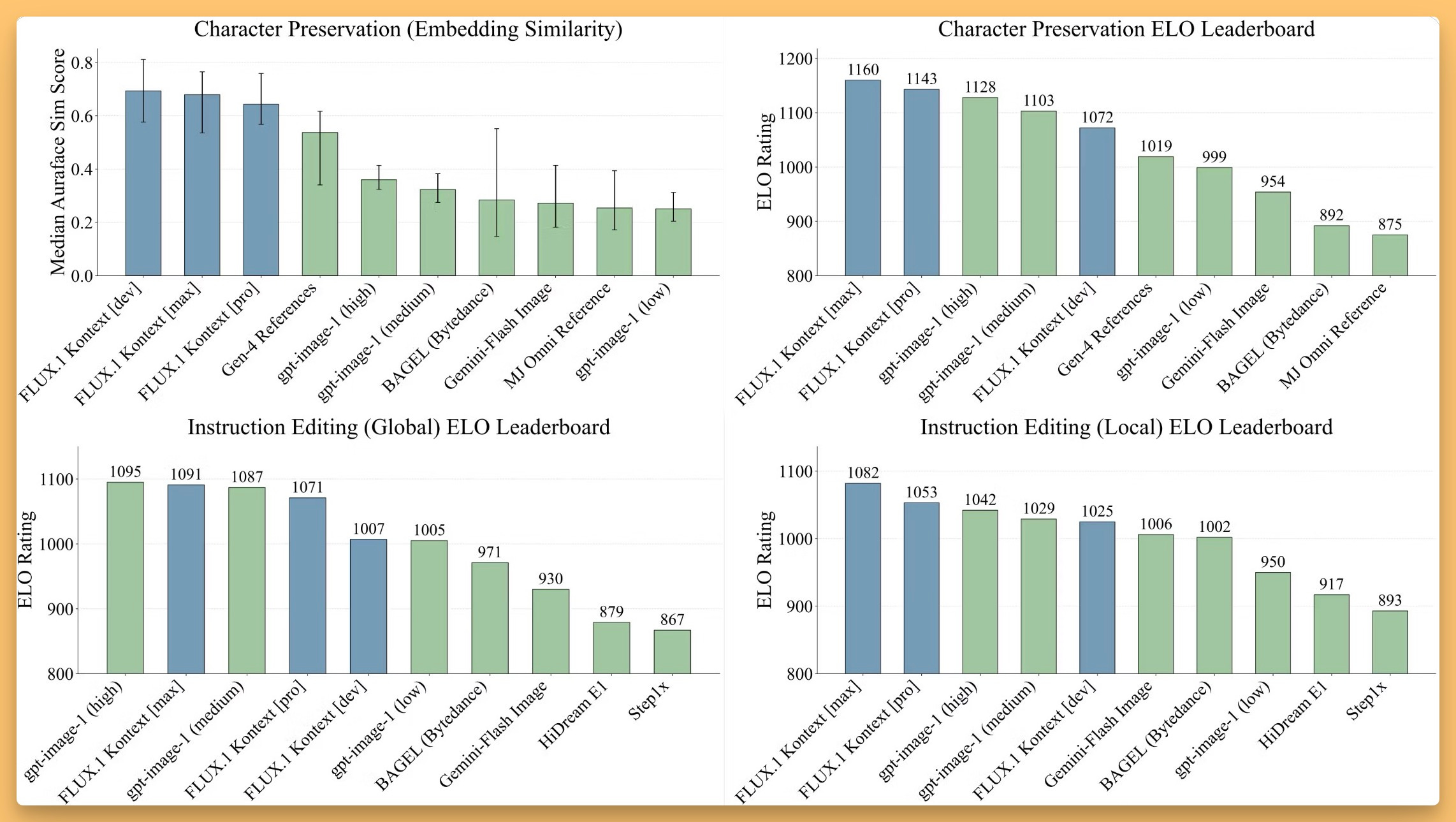
This came as massive breaking news during the show (thought we didn't catch it live!) - Black Forest Labs, creators of Flux, dropped an incredible Image Editing model called Kontext (really, 3 models, Pro, Max and 12B open source Dev in private preview). The are consistent, context aware text and image editing! Just see the below example

If you used GPT-image to Ghiblify yourself, or VEO, you know that those are not image editing models, your face will look different every generation. These images model keep you consistent, while adding what you wanted. This character consistency is something many folks really want and it's great to see Flux innovating and bringing us SOTA again and are absolutely crushing GPT-image in instruction following, character preservation and style reference!
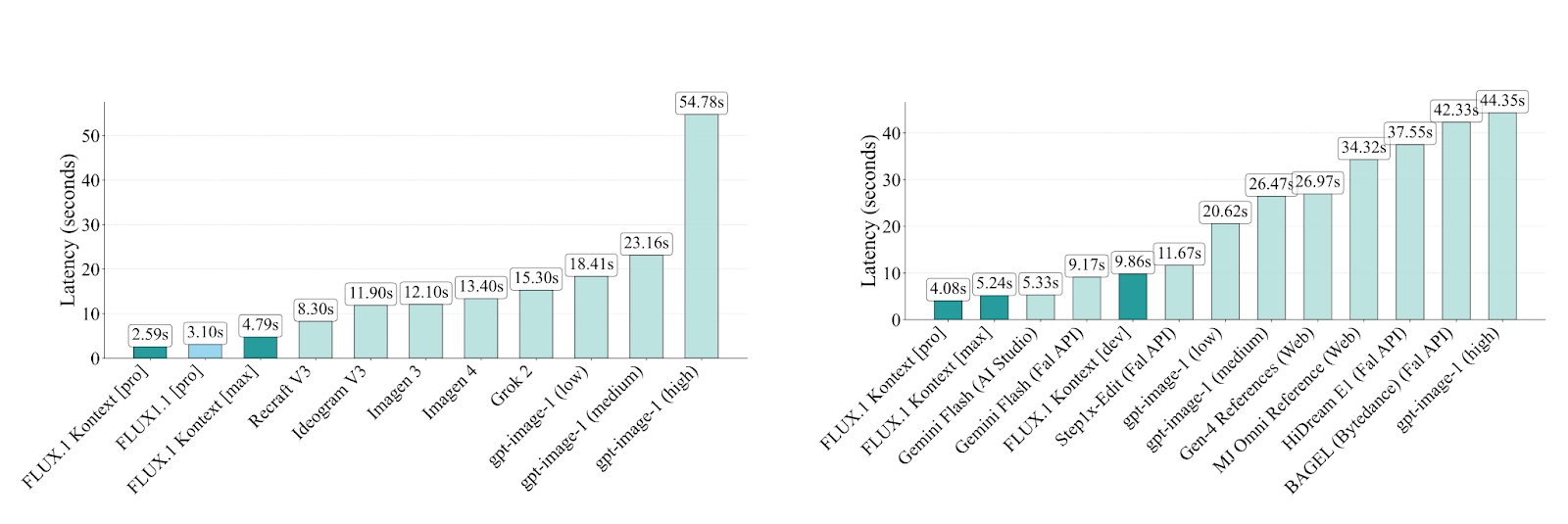
Maybe the most important thing about this model is the increible speed. While the Ghiblification chatGPT trend took the world by storm, GPT images are SLOW! Check out the speed comparisons on Kontext!
You can play around with these models on the new Flux Playground, but they also already integrated into FAL, FreePik, Replicate, Krea and tons of other services!
🎙️ Voice & Audio: Everyone Gets a Voice
Unmute.sh: Any LLM Can Now Talk
KyutAI (the folks behind Moshi) are back with Unmute.sh - a modular wrapper that adds voice to ANY text LLM. The latency is incredible (under 300ms), and it includes semantic VAD (knowing when you've paused for thought vs. just taking a breath).
What's brilliant about this approach is it preserves all the capabilities of the underlying text model while adding natural voice interaction. No more choosing between smart models and voice-enabled models - now you can have both!
It's going to be open sourced at some point soon, and while awesome, Unmute did have some instability in how the voice sounds! It answered to me with 1 type of voice and then during the same conversation, answered with another, you can give it a tru yourself at unmute.sh
Chatterbox: Open Source Voice Agents for Everyone
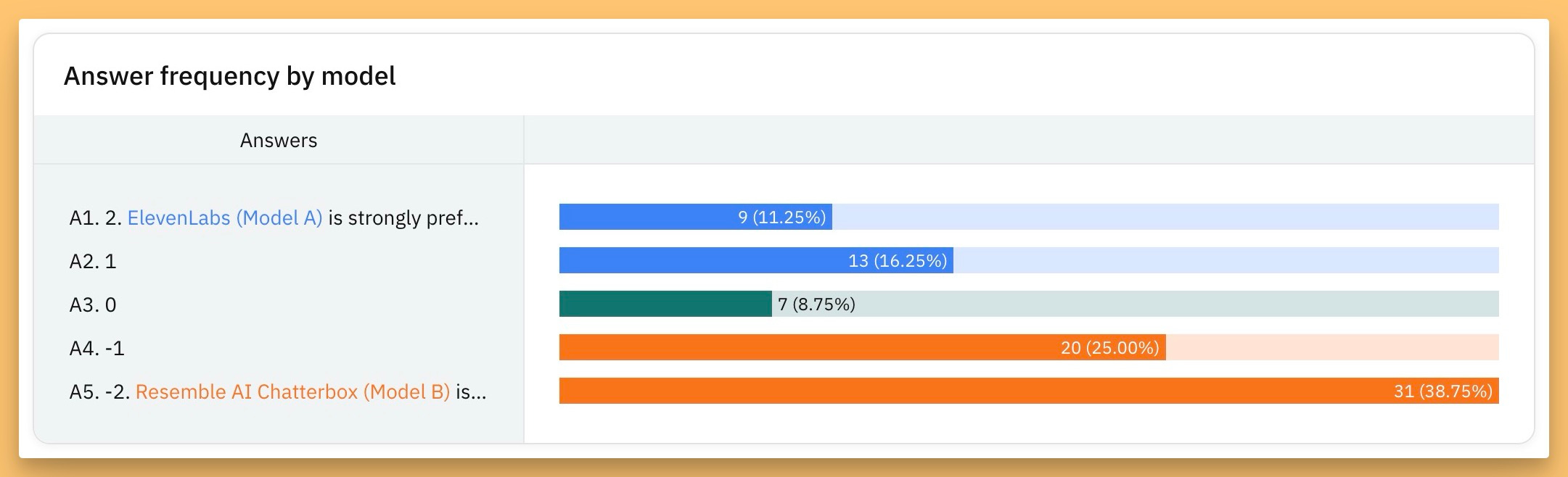
Resemble AI open sourced Chatterbox, featuring zero-shot voice cloning from just 5 seconds of audio and unique emotion intensity control. Playing with the demo where they could dial up the emotion from 0.5 to 2.0 on the same text was wild - from calm to absolutely unhinged Samuel L. Jackson energy.
This being a .5B param model is great, The issue I always have, is that with my fairly unique accent, these models sound like a British Alex all the time, and I just don't talk like that!
Though the fact that this runs locally and includes safety features (profanity filters, content classifiers and something called PerTh watermarking) while being completely open source is exactly what the ecosystem needs. We're rapidly approaching a world where anyone can build sophisticated voice agents.👏
Looking Forward: The Convergence is Real
As we wrapped up the show, I couldn't help but reflect on the massive convergence happening across all these modalities. We have LLMs getting better at reasoning (even with random rewards!), video models breaking reality, voice models becoming indistinguishable from humans, and it's all happening simultaneously.
Charlie's comment that "we are the prompts" might have been said in jest, but it touches on something profound. As these models get better at generating realistic worlds, characters, and voices, the line between generated and real continues to blur. The Prompt Theory videos aren't just entertainment - they're a mirror reflecting our anxieties about AI and consciousness.
But here's what keeps me optimistic: the open source community is keeping pace. DeepSeek, Hunyuan, ResembleAI, and others are ensuring that these capabilities don't remain locked behind corporate walls. The democratization of AI continues, even as the capabilities become almost magical.
Next week, I'll be at AI Engineer World's Fair in San Francisco, finally meeting Yam face-to-face and bringing you all the latest from the biggest AI engineering conference of the year. Until then, keep experimenting, keep building, and remember - in this exponential age, today's breakthrough is tomorrow's baseline.
Stay curious, stay building, and I'll see you next ThursdAI! 🚀
Show Notes & TL;DR Links
Show Notes & Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co-Hosts - @WolframRvnwlf (@WolframRvnwlf), @yampeleg (@yampeleg) @nisten (@nisten)
Guests - Charlie Holtz (@charliebholtz]), Linus Eckenstam (@LinusEkenstam @LinusEkenstam)
Open Source LLMs
DeepSeek-R1-0528 - Updated reasoning model with AIME 91, LiveCodeBench 73 (Try It)
Learning to Reason Without External Rewards - Paper on random rewards improving models (X)
HaizeLabs j1-nano & j1-micro - Tiny reward models (600M, 1.7B params), RewardBench 80.7% for micro (Tweet, GitHub, HF-micro, HF-nano)
Big CO LLMs + APIs
Claude Opus 4 - #1 on LMArena WebDev, coding step change (X)
Mistral Agents API - Framework for custom tool-using agents (Blog, Tweet)
Mistral Embed SOTA - New state-of-the-art embedding API (X)
OpenAI Advanced Voice Mode - Now sings with new capabilities (X)
Anthropic Voice Mode - Released on mobile for conversational AI (X)
This Week’s Buzz
Fully Connected - W&B conference, June 18-19, SF, promo code WBTHURSAI (Register)
AI Engineer World’s Fair - Next week in SF, 30% off with THANKSTHURSDAI (Register)
AI Art & Diffusion
BFL Flux Kontext - SOTA image editing model for identity-consistent edits (Tweet, Announcement)
Vision & Video
VEO3 Prompt Theory - Viral AI video trend questioning reality on TikTok (X)
Odyssey Interactive Video - Real-time AI world exploration at 30 FPS (Blog, Try It)
HunyuanPortrait - High-fidelity portrait video from one photo (Site, Paper)
HunyuanVideo-Avatar - Audio-driven full-body avatar animation (Site, Tweet)
Voice & Audio
Unmute.sh - KyutAI’s voice wrapper for any LLM, low latency, soon open-source (Try It, X)
Chatterbox - Resemble AI’s open-source voice cloning with emotion control (GitHub, HF)
Tools
