
Published on May 29, 2025 6:40 PM GMT
There has been a flurry of recent papers proposing new RL methods that claim to improve the “reasoning abilities” in language models. The most recent ones, which show improvements with random or no external rewards have led to surprise, excitement and confusion.
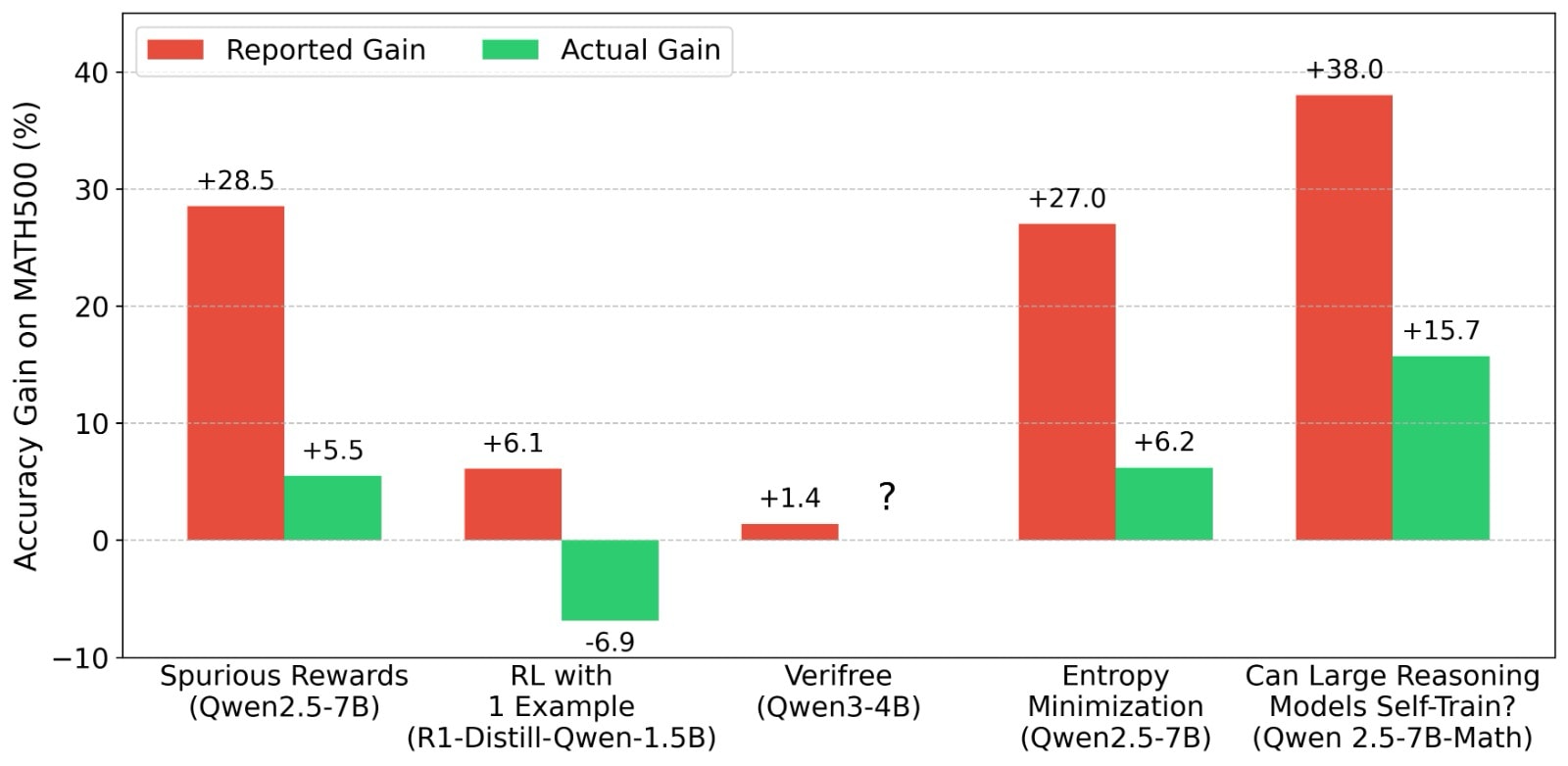
We analyzed 7 popular LLM RL papers (100+ to 3000+ likes, 50k+ to 500k+ views on X) including “Spurious Rewards”, “RL from 1 example”, and 3 papers exploring “Intrinsic Confidence Rewards”. We found that in most of these papers the improvements could be a mirage due to various accidental issues in the evaluation setups (discussed below). As such, the baseline numbers of the pre-RL models are massively underreported compared to official numbers in the Qwen releases, or other standardized evaluations (for example in the Sober Reasoning paper). In several cases, the post-RL model performance was actually worse than the (correctly evaluated) pre-RL baseline they start from. This means the elicitation these works achieve with RL, could also be replicated without any weight updates or finetuning. Here, we do not mean non-trivial elicitation of some latent capabilities, just what can be achieved by fixing prompting and generation hyperparameters. These include using correct formats and better ways to parse answers from responses, using recommended sampling temperatures, and using few-shot prompting to improve format-following.
Overall, these papers made us wonder if recent LLM RLVR papers have any signal, but we find their own claims could be noise due to underreported baselines. The proposed methods might have promise, and our goal is not to detract from their potential, but rather emphasise the importance of correct evaluations and scientific reporting. We understand the pressure to publish RL results quickly given how fast the community seems to be moving. But if the claims cannot be trusted, are we really moving forward?
Discuss
