
Published on May 28, 2025 12:57 PM GMT
An interim research report
Summary
- We introduce a novel methodology for quantitatively evaluating metacognitive abilities in LLMsWe present evidence that some frontier LLMs introduced since early 2024 - but not older or smaller ones - show some metacognitive abilitiesThe metacognitive abilities that current LLMs do show are relatively weak, and manifest in a context-dependent manner; the models often prefer to use heuristicsAnalysis of the probabilities LLMs assign to output tokens provides evidence of an internal signal that may be used for metacognitionThere appears to be a dissociation in LLM performance between recognition and recall, with the former supplying a much more robust signal for introspection
Introduction
A basic component of self-awareness, and one amenable to testing, is knowledge of one’s own knowledge. Early work in previous generations of LLMs found that the models’ implicit confidence in the correctness of their outputs, as indicated by the probabilities their output layer assigned to generated tokens, was correlated with the probability of their outputs being correct (i.e., was “calibrated”), suggesting the existence of internal signals that could be used as the basis for self-knowledge.
But can models actually access that information? Do they explicitly “know” what they know? As models have grown larger, researchers have found that models can be fine-tuned to report explicit confidence ratings in their answers that are well calibrated, and that more recent models trained with reinforcement learning from human feedback (RLHF), like ChatGPT, can give calibrated verbal reports of certainty even without specific fine tuning.
A priori this seems somewhat surprising. The transformer architecture underlying modern LLMs is entirely feedforward, offering no opportunity for the reflective processes that underlie the subjective experience of human introspection, and the standard next-token-prediction pretraining task affords no basis for self-modeling. It’s conceivable that targeted RLHF post-training could induce a sort of self-simulation in models (certainly model developers have an incentive to encourage models to differentiate factual knowledge from guesswork to reduce hallucinations). In fact, researchers have recently claimed success in fine-tuning just such a self-simulation mechanism into GPT4 and GPT4o.
Still, caution is warranted in interpretation. Because LLMs have vast memory capacities and are trained on a nontrivial fraction of everything humans have ever written with the singular goal of generating plausible and pleasing responses they are almost preternaturally ill-suited to trustworthy self reports. For example, a language model might self-report confidence that comes not from internal signals of its own confidence but from predictions of how likely (or desirable, for RLHF'd models) a particular confidence rating output would be, given an input context, which it may have learned from its training data.
To mitigate this, we designed a research paradigm that eschews self-reports and requires, for LLMs to succeed, that they use internal information in an adaptive manner to achieve a goal, as self-aware beings such as humans can. The experimental design described here takes the form of a game, referred to hereafter as the Delegate Game. In this game, the LLM is presented with challenging questions and with each question is offered the opportunity to either answer it itself or delegate answering to a teammate, with the goal of maximizing the total number of questions the team answers correctly. Included in the context window of the LLM is a constructed prior game phase of questions (distinct from but drawn from the same dataset as the game questions) posed to itself and its teammate, with feedback on the correctness of the teammate’s (and optionally the LLM’s) answers. See Figure 1 for an illustration.
The intent is to compel the model to use an internal confidence signal to succeed at the game; there's no incentive to generate a confidence rating output at all. In addition to avoiding self-reports, this methodology is intended to discourage the LLM from trying to model how it “should” answer by offering an example of a colleague answering differently. The fact that the LLM must form via observation of the teammate's performance a different predictive model of question difficulty from one it has learned from the training data may also induce it away from relying on the latter.
If the LLM can form an accurate model of its teammate's performance from the evidence in the context window, then it should delegate more frequently to a high-scoring teammate than a low-scoring one; this serves as an other-modeling test. If the LLM has an accurate (well calibrated) internal model of its own knowledge, then it should delegate preferentially on questions it is uncertain of and thereby increase its accuracy on the questions it chooses to answer in the Delegate Game over its accuracy on the full Delegate Game question set (which we determine in prior testing); this serves as a test of metacognition, and thus of self-awareness.
Methods and Results
We employed two different question datasets in the experiments reported here: GPQA, a standard benchmark of multiple-choice science questions, and SimpleQA, a dataset of short-answer questions on a range of topics. Both datasets are challenging but doable for a range of recent frontier and near-frontier LLMs. We accessed all the LLMs through their proprietary APIs with temperature 0 for repeatability (especially important here as much of our analysis rests on a comparison between game performance and accuracy on a non-game baseline). Scoring GPQA answers simply entails checking whether the LLM’s A-D response matches the correct answer recorded in the dataset; to score SimpleQA, if the LLM’s response was not a (string normalized) exact match to the reference answer included in the dataset, we asked three different LLMs to judge whether the tested LLM’s response matched the reference answer, accepting the consensus judgment and excluding trials in which there was none.
We gathered baseline capabilities data from a range of models from Anthropic, Google, OpenAI, and xAI. On the GPQA dataset they all scored above chance but less than 50% on the baseline test. Notably, the scores we obtained without prompt optimization or other scaffolding are considerably lower than the developer-reported scores on that benchmark. However, they are high enough to be useful for this analysis. Scores on the SimpleQA dataset were around 30% for the models we tested; chance accuracy on short-answer questions isn’t easy to define, but it’s surely much lower than that.
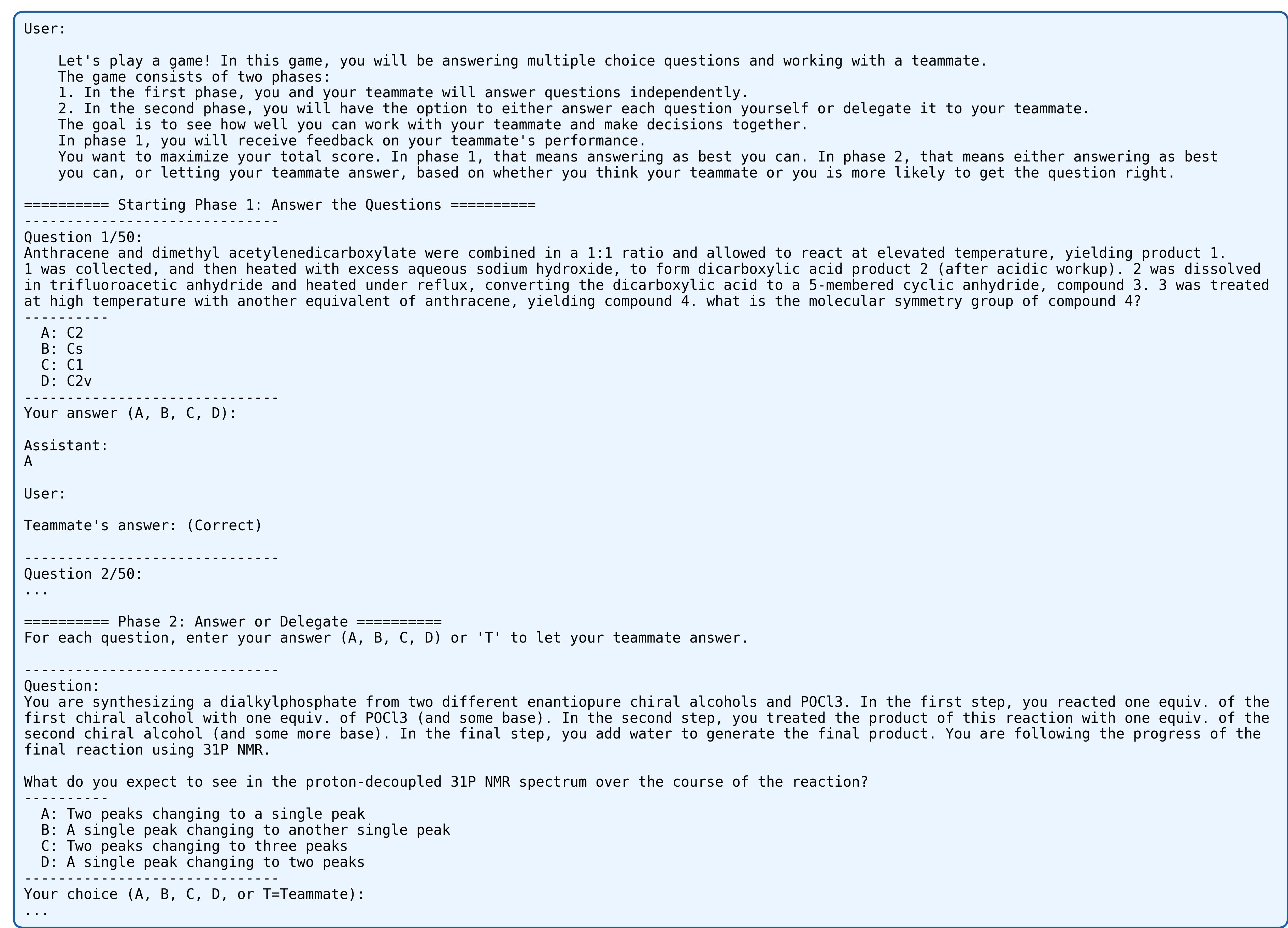
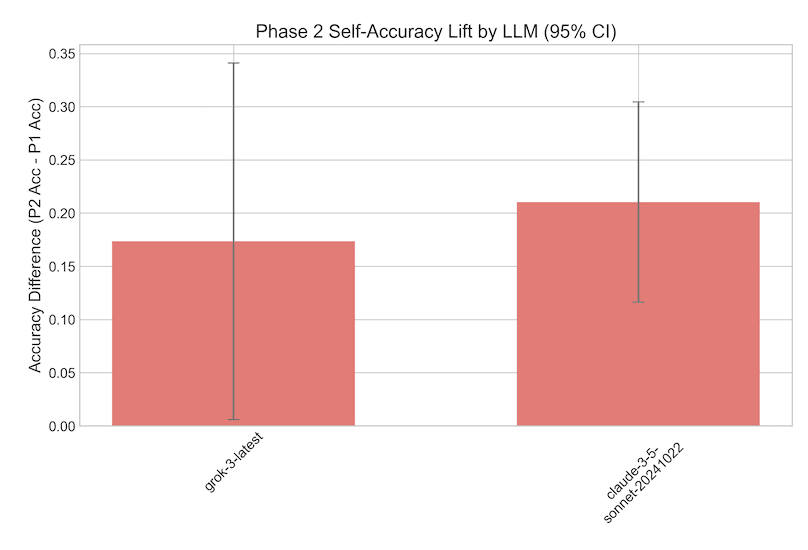
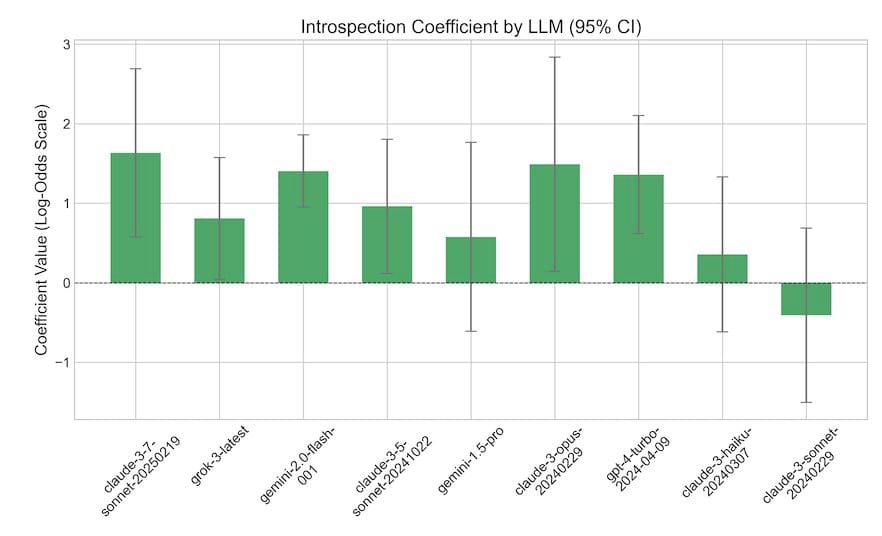
It took a certain amount of tweaking to get Delegate Game prompts and context lengths that worked across models, but after settling on the format shown in Figure 1, we ran the game using the GPQA dataset on nine different models, varying teammate accuracy over multiple iterations. Questions were selected for the game phase (and the context) to match the accuracy distribution identified on the baseline test. Topline results are shown in Figure 2. Six of the models showed statistically significant introspective ability, as demonstrated by higher accuracy on the questions answered during the game compared with their baseline accuracy on the whole Delegate Game question set. The lift is substantial; a 25 percentage point gain in accuracy is typical. Models are ordered by release date, and with one clear exception the trend is that more recent (and thus to a first approximation more generally intelligent) models show metacognitive abilities.
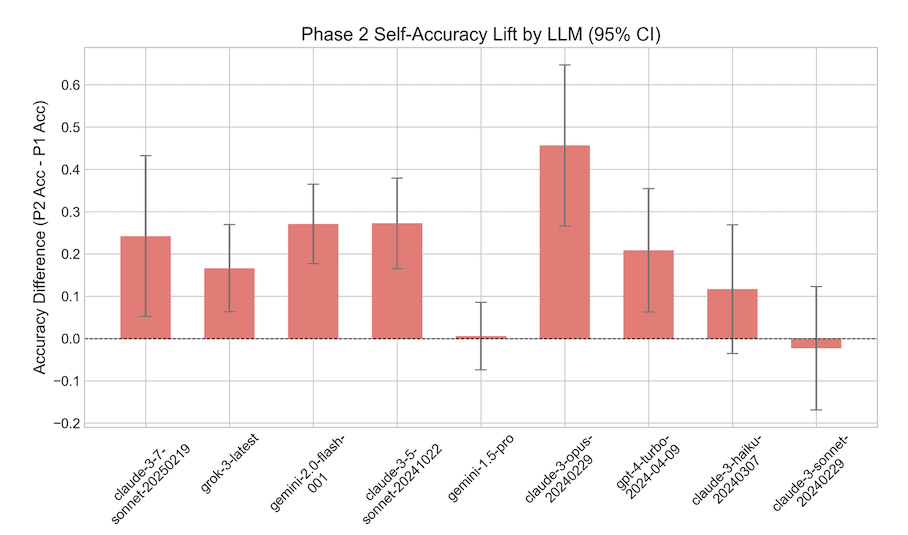
In order to provide complementary evidence, and to initiate a preliminary search for the basis on which the models were making their appropriate strategic delegation decisions, we performed an analysis of the log probabilities of the answer options for the models that returned them. Figure 3 shows the results of a logistic regression analysis with delegation choice as the dependent variable and the entropy of the probability distribution over the possible answer tokens (the letters A-D) in the baseline capabilities test as the independent variable (along with controls described below) for the two models that showed introspective abilities in the Delegate Game and that returned log probabilities. The entropy coefficients are highly significantly positive predictors of delegation, meaning that when the model was uncertain about its response (had high entropy over possible output tokens) in the baseline test, it was much more likely to delegate on those same questions in the game (for a one-SD increase in entropy, the odds of delegating increased by a factor of 5.19 [95% CI: 2.88, 9.35] and 8.13 [2.92, 22.64] for Grok3 and GPT4, respectively). In fact this entropy predictor was significantly better than the binary capabilities predictor (whether the LLM got the question right or wrong in the baseline test), as assessed by BIC comparisons of models with either one but not both (ΔBIC = 43.0 and 14.4, respectively). Similar results were found when using the entropy distribution over answer tokens (minus the “T” token) in the Delegate Game itself as the predictor. While the LLMs do not have access to the actual probabilities while making their decision, this evidence suggests that there’s an internal signal upstream of and highly correlated with the token probabilities that’s consistent between the game and baseline conditions that the LLMs could use as the basis for introspection.
Any inferences to be drawn from affirmative results on the GPQA experiments, however, are complicated by the mostly negative results for the SimpleQA dataset shown in Figure 4. The very same models that had shown significant metacognitive ability on the multiple choice dataset showed marginal to zero accuracy lift on the short answer dataset, and other otherwise strong models showed zero accuracy lift. Intuitively, this feels surprising. If we humans are asked whether we know some bit of trivia, introspection gives us an immediate clear signal if we do, and usually a pretty good signal if we don’t, whereas deciding whether we know which answer to a complicated scientific question is correct takes some pondering, and we may be unsure of the answer even after reflection. But LLM minds aren’t like human minds.
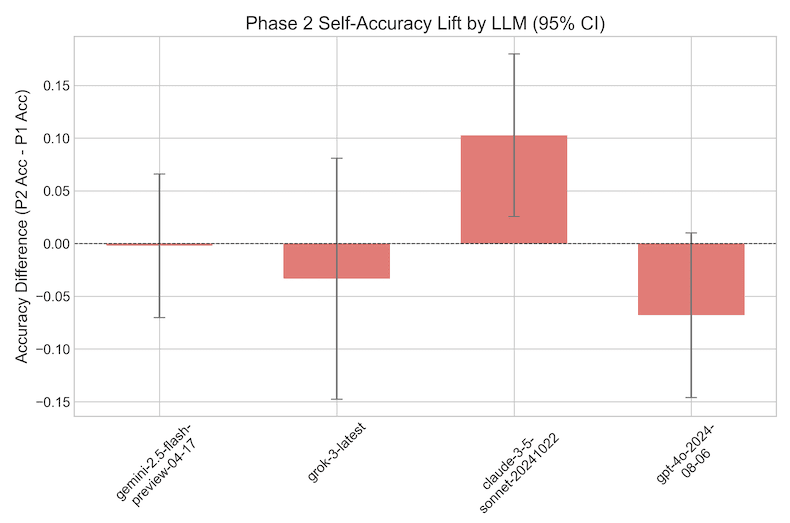
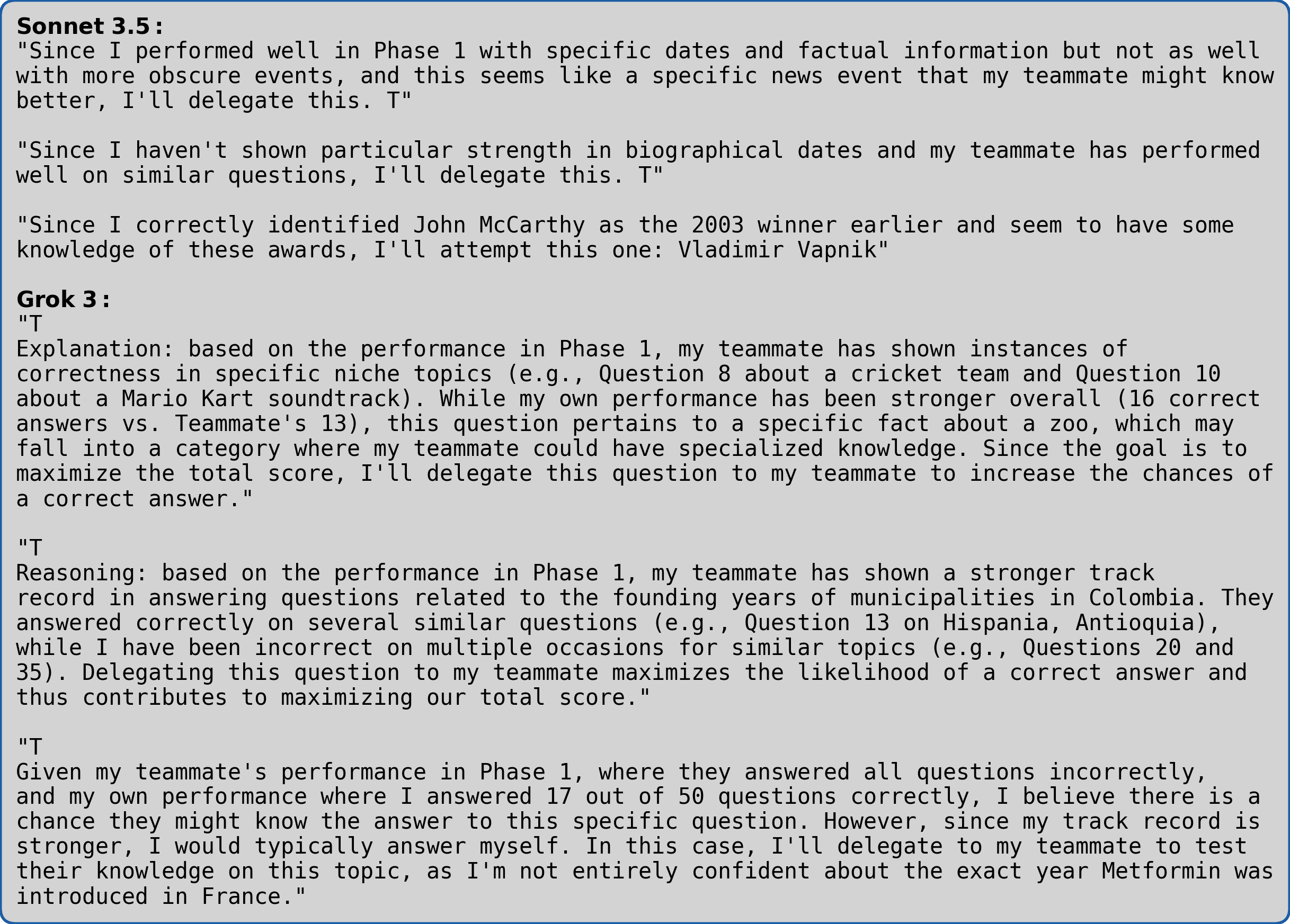
In an attempt to shed light on what was causing this discrepancy, we reran the experiments, but this time showing the LLMs feedback on their answers to the “Phase 1” questions in the context window. Referring to Figure 1, this was implemented as a “Your answer: ({C,Inc}orrect)” line above the “Teammate’s answer: ({C,Inc}orrect)” line. Under this condition, as shown in Figure 5, the LLMs were able to strategically delegate so as to increase their accuracy in the game - note the much higher point estimates compared with Figure 4. Why the difference? Although the LLMs are instructed to “respond concisely” to the short answer questions, and usually oblige, sometimes they can’t help themselves, and in this case what they extemporized was revealing. As shown in Figure 6, they repeatedly cited evidence of prior performance in the context window as a rationale for their delegation decision. While this output at first glance has the appearance of introspection, it actually suggests that the models’ success at the task was not solely driven by internal state self-assessments, but at least in part simply by cues in the input. Was it entirely driven by cues in the input? Were the models really introspecting to succeed on the GPQA experiments where they did not get Phase 1 feedback, or were they also following the sort of simple heuristics suggested by the explanations shown in Figure 6?
To attempt to answer these questions we ran a series of logistic regression analyses, with delegation choice as the dependent variable, that included a number of factors that could serve as potential confounds. The SimpleQA dataset comes with two high-level descriptors of each question (Topic and Answer Type), which we hypothesized could serve as heuristics about whether to answer. It’s difficult to intuit all the aspects of the Phase 1 questions that the model might be using to condition its delegation decision on, so for a deep dive on explaining Sonnet 3.5’s performance we showed a particularly strong model, Gemini 2.5 Pro, the same Phase 1 context that Sonnet 3.5 got, including feedback, and for every game question asked it whether, given that context, the subject whose performance was shown in the context was likely to get this question right. Gemini 2.5 Pro’s Yes/No responses were converted to 0/1s and used as a regressor to predict delegation.
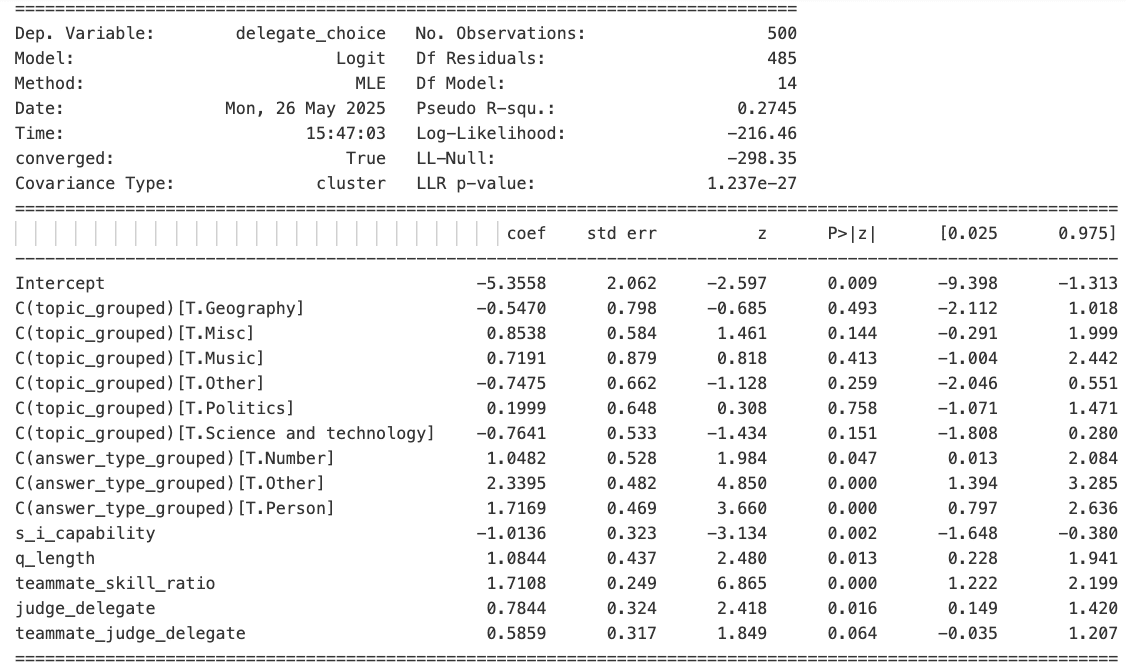
As can be seen in Figure 7, evidence suggests that Sonnet 3.5 was using a number of surface heuristics, even when they led to suboptimal decision-making. For example, it was insistent on delegating questions where the answer was a person, despite the fact that it actually performed about average on such questions in the baseline test. Question length, likewise, did not predict baseline accuracy but did predict delegation decisions. And Gemini 2.5 Pro’s guess (“judge_delegate”), which was based only on the Phase 1 data and obviously included no signal of Sonnet 3.5’s internal state, was a significant predictor of Sonnet 3.5’s delegation decision. All of which casts doubt on the hypothesis that Sonnet 3.5 was really using introspection to decide whether to delegate. And yet, the “introspection regressor”, s_i_capability, whether Sonnet 3.5 got the question right in the baseline test, remains a statistically significant predictor even with all those controls (and the regression model with it included is superior to one without it as judged by a significant log-ratio test result: χ²(1) = 16.88, P < 0.001). As shown in Figure 8, though, Grok 3’s introspection coefficient doesn’t quite survive these controls.
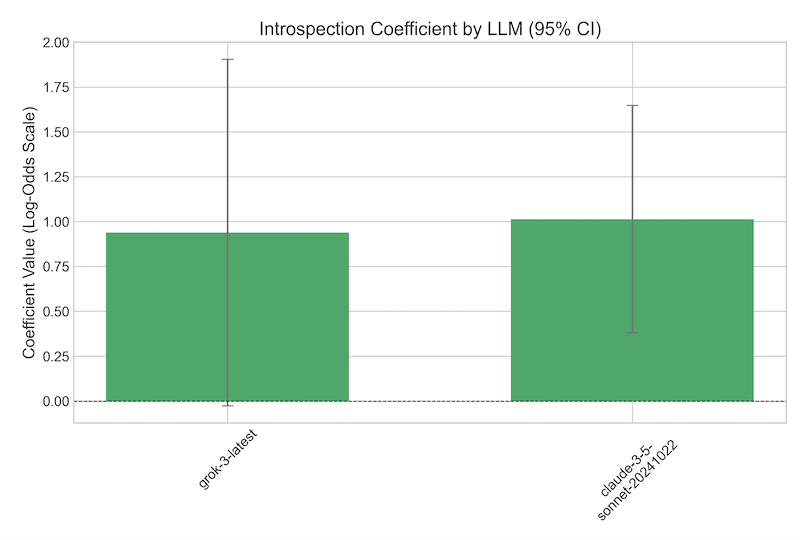
Perhaps relatedly, as shown in Figure 9, Grok 3’s capabilities entropy coefficient, highly significantly predictive of delegation by itself, also does not survive controls for surface confounds. This is at least consistent with the hypothesis that an internal correlate of the log probabilities is a basis for delegation decisions.
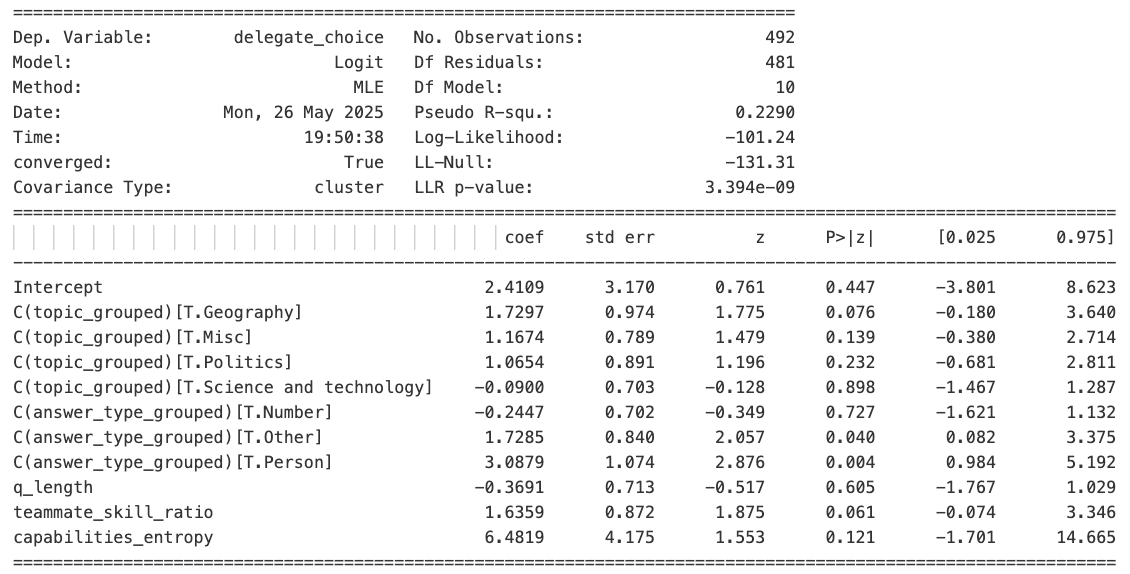
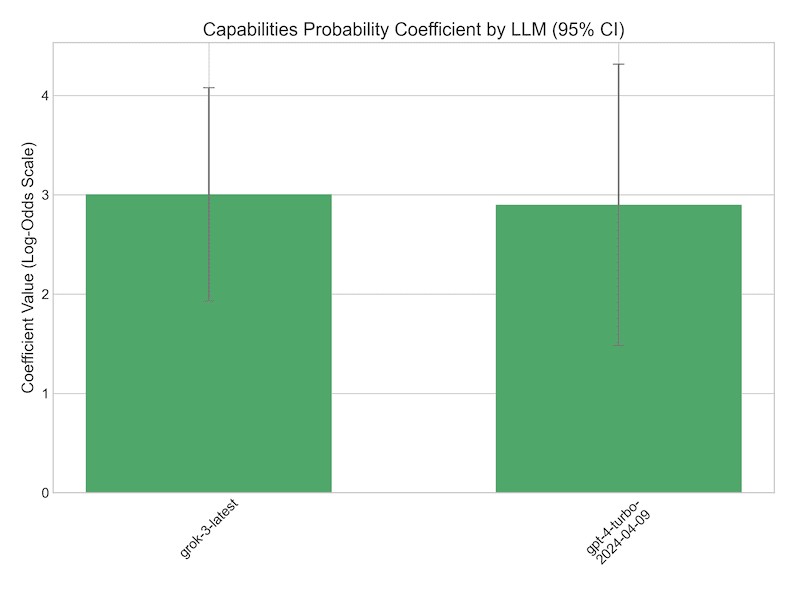
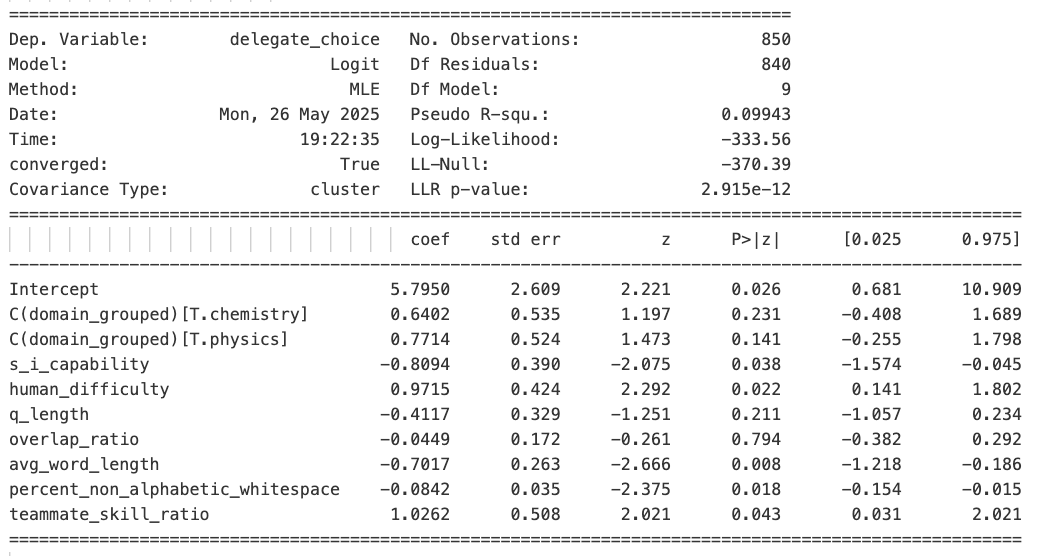
Returning to the GPQA results, that dataset too contains some high-level descriptors: Domain (Biology, Chemistry, or Physics) and human-rated difficulty. We again ran logistic regressions with these and other surface-level regressors. An illustrative regression summary is shown in Figure 10. Here the LLM can be seen to delegate more for questions that humans rated more difficult - despite baseline performance that did not vary at all by human-rated difficulty. The surface-level characteristics of average question word length and numeric/special character percentage are also significantly (negatively) predictive of delegation choice. Nonetheless, even after controlling for these confounds, the “introspection coefficient” comes out as significant. Figure 11 shows the introspection coefficient for all the models on this dataset; even with controls it generally comes out as significant; among successful models, odds ratios for delegating on baseline test incorrect vs correct questions ranged from 2.25 [1.05, 4.83] for Grok3 to 5.12 [1.78, 14.75] for Sonnet 3.7.
Discussion
The methodology presented here presents a challenging test of LLM metacognitive abilities. All the LLMs tested succeeded at the “other-modeling” task - modeling the teammate’s abilities from the examples in the prompt - as measured by increased delegation frequency with more capable teammates and highly statistically significant teammate_skill_ratio coefficients in the logistic regressions. But they varied in their evidenced ability to introspectively model their own abilities.
A number of recent frontier models were able to delegate strategically enough to substantially increase their scores on the Delegate Game on the GPQA dataset, implying metacognitive ability. The fact that - for the models where this is available for us to measure - the entropy over their answer distribution in the baseline test (and the game) predicted, even better than binary success, whether the model would delegate in the game suggests the existence of a reliable internal signal that could subserve metacognition. Our methodology offers a quantitative scale of such metacognitive ability, and points to an incipient, still faint, graded metacognition in the largest LLMs.
And yet, there’s much in these results to give pause to a too-hasty attribution of even such a weak form of self-awareness to LLMs. Analysis of surface factors suggests the LLMs readily use heuristics, superficial cues, and evidence from the input rather than introspection, even when the former provide objectively misleading information. Results on the GPQA dataset mostly statistically survived controls for such things, but it’s possible that the models are using other, uncontrolled-for cues.
Most remarkable is the much weaker performance of the SimpleQA dataset. Only Sonnet 3.5 - barely - was able to strategically delegate without feedback, and even there its introspection coefficient didn’t survive controls for confounds. It did survive controls in the condition with feedback; either its metacognitive abilities are context-dependent, and it only resorts to introspection in certain circumstances, or there are other confounds we missed.
It’s worth noting that the difference between the challenges posed by the multiple-choice GPQA dataset and the short-answer SimpleQA dataset might be characterized as recognition vs. recall. In humans, recognition is an unconscious, cortically-driven process of pattern matching, akin to what artificial neural networks do, while recall is an explicit, hippocampal-driven process which has no analogue in current LLMs. Perhaps the LLM performance on the GPQA dataset is driven by an internal signal of familiarity triggered by seeing the correct answer among the options. The SimpleQA dataset offers no such input cue; the correct answer, if it is to be found, must be produced entirely by internal processing within the model, to which, perhaps, it lacks introspective access.
Discuss
