
现有的数据合成方法在合理性和分布一致性方面存在不足,且缺乏自动适配不同数据的能力,扩展性较差。
大语言模型受限于采样效率和上下文窗口大小,难以直接合成大规模数据集。
如何用大模型生成结构对齐、统计可信、语义合理的数据,成为了亟待解决的问题。
为此,麦吉尔大学团队提出了新方法LLMSynthor——
通过这个方法,可以让大模型变成结构感知的数据模拟器,为隐私敏感、数据稀缺场景生成不泄密的高质量替代数据。

LLMSynthor:让LLM变成“结构感知的生成器”
在人口、电商、出行等场景,数据敏感难共享,不同数据格式还需单独设计模型,成本高、迁移差。
传统方法如贝叶斯网络、GAN等,要么难以建模高维依赖,要么泛化差且不稳定,还常生成“9岁博士”这类统计合理但语义荒谬的样本。
同样,近期大模型也被用于数据生成,但存在采样慢、分布不可控、上下文受限等问题,难以高效生成结构完整的大规模数据集。
而LLMSynthor的解法是:让LLM不直接生成数据,而是变成“结构感知的生成器”,通过统计对齐反馈不断迭代优化。
整体框架如下:
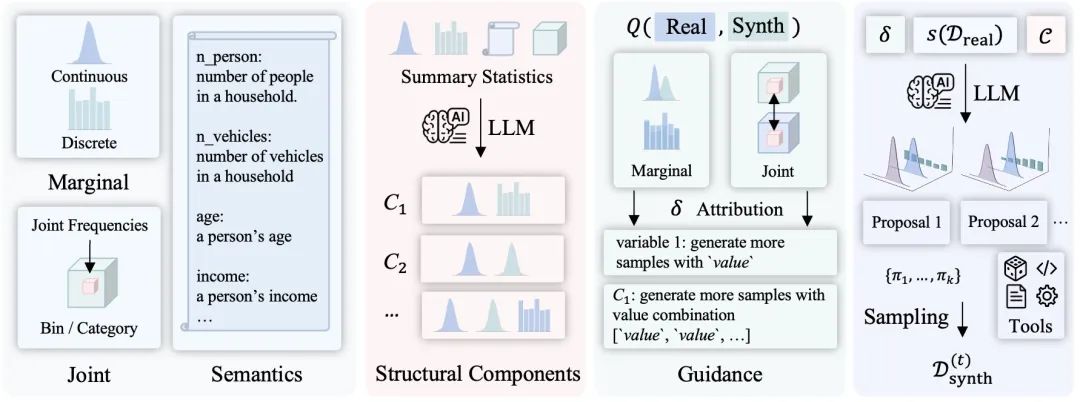
Step 1:结构推理
生成可信数据,关键是理解变量之间的依赖结构。
传统Copula模型虽能拆分变量分布与关系建模,但在高维、多语义场景下难以扩展。
LLMSynthor的关键创新是:用大语言模型模拟Copula。
LLM本身可视为一种现实世界联合分布的高维先验,其预训练过程中已经内化了人类行为、社会结构的变量共现规律。
结合对统计摘要(如频率、分布等)的理解,它能推断变量间的高阶关系,并利用语义信息挖掘隐藏依赖。
Step 2:统计对齐
LLMSynthor不直接比对原始数据,而是通过统计摘要(如变量分布、联合频率)来衡量真实数据与合成数据的差距。
这样,就既保留了结构信息,又避免泄露个体数据。
(因为只依赖统计特征,即便输入的是聚合的指标,也能生成结构合理、语义一致的合成数据,特别适合人口普查、问卷调查等隐私敏感场景。)
此外,LLMSynthor的对齐机制是可归因的:不仅衡量“整体偏离”,还能定位具体偏差来自哪个变量或变量组合。
这种细粒度反馈能直接用于下一轮生成的结构调整,实现逐步对齐。
Step 3:生成分布而不是样本
传统方法逐条生成样本,效率低且难控分布。
LLMSynthor改为生成可采样的分布规则(proposals),比如:“25岁女性、在一线城市、购买美妆产品”,然后批量采样,甚至可调用图像等外部生成器扩展至多模态任务。
proposal同时受统计反馈和LLM常识引导,可自然避免如“10岁博士”一类的荒谬变量组合。
这种方式不仅高效、结构可信,还能通过“分布描述语言”来协调其他模型协同生成,实现跨模态、多源、多任务的数据合成与模拟。
Step 4:迭代对齐
通过“结构推理-统计比较-规则生成-新数据采样”不断循环,模型最终会生成一组结构上、统计上都高度接近真实数据,且符合常理的合成数据集。

理论保障
除了经验效果,LLMSynthor还具备理论收敛保障。
LLMSynthor团队提出局部结构一致性定理(Local Structural Consistency):在合理的假设下,如果某个变量或变量组分布初始存在偏差,经过有限次迭代可将误差收敛至任意可控范围。
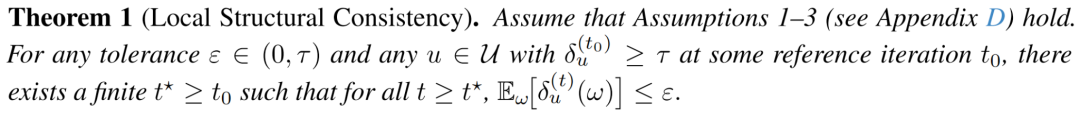
这说明LLMSynthor不是“凭感觉靠近”,而是有数学保障地逐步收敛到真实数据结构。
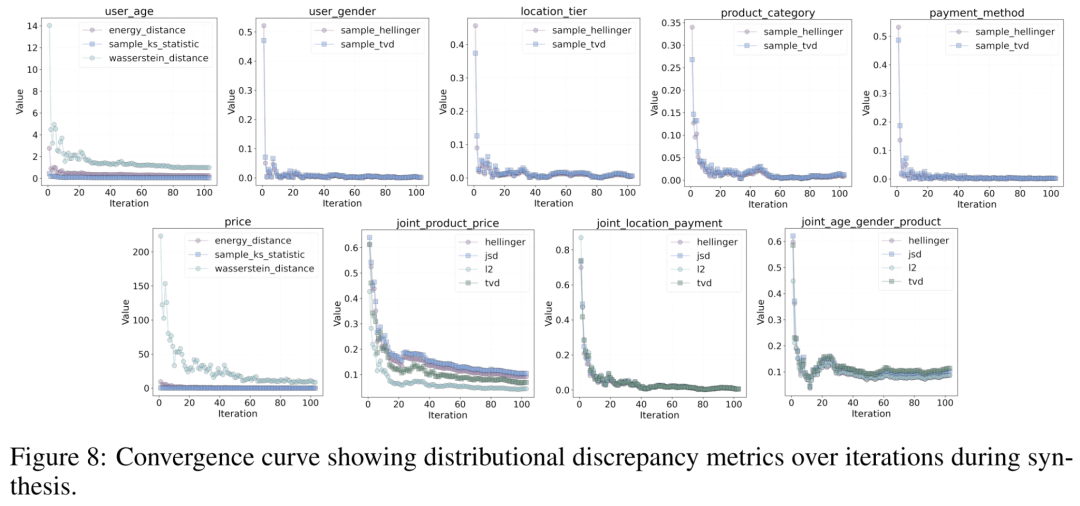
多场景实测
为了验证LLMSynthor的实用性和稳定性,作者在三个具代表性的真实场景中进行了实验,包括电商交易、人口统计和城市出行。
电商交易生成
这是一个包含连续与离散变量的混合场景,变量关系复杂。
作者基于贝叶斯网络构建可控数据集,设定明确结构,用于评估建模能力。
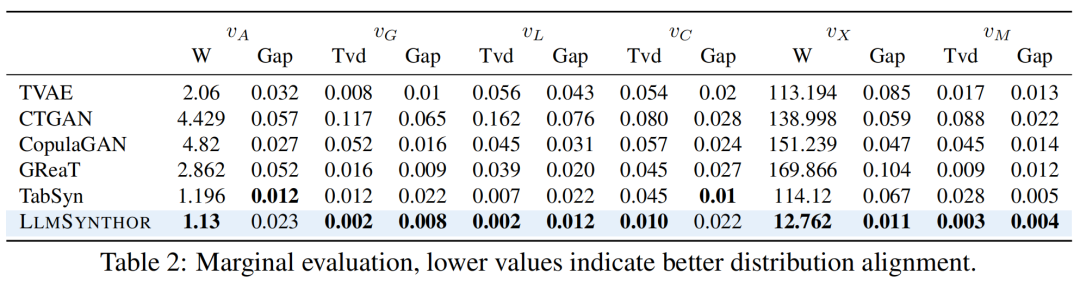
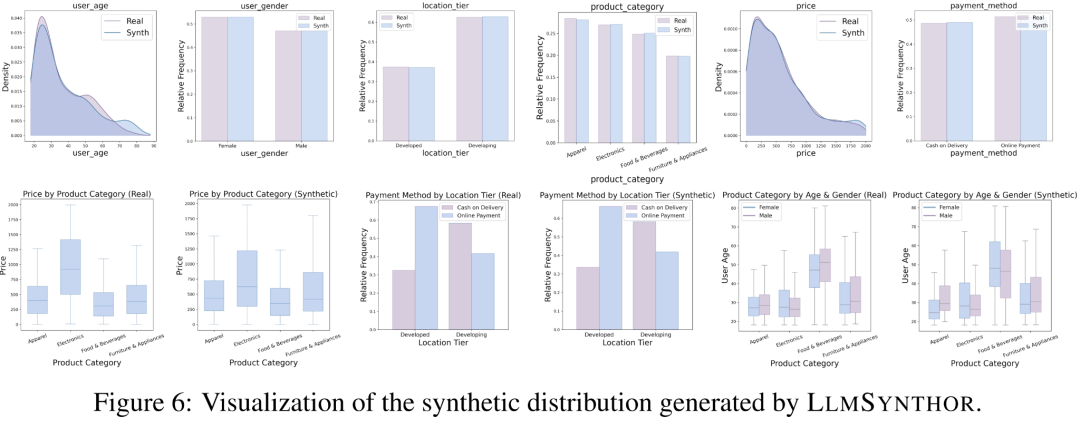
结果显示,LLMSynthor在边缘与联合分布误差上均表现最优,准确还原变量依赖。
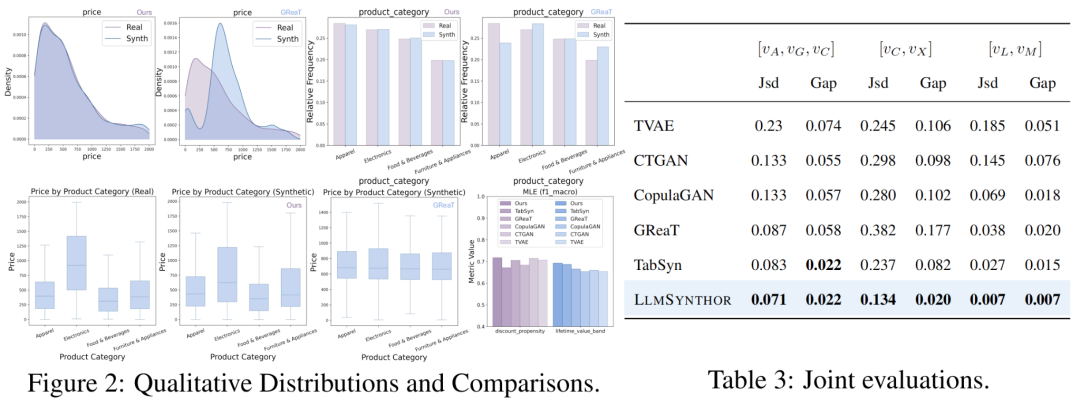
进一步的预测实验也显示,其合成数据训练出的模型在真实数据上效果最佳,体现出强实际价值。
人口微观合成
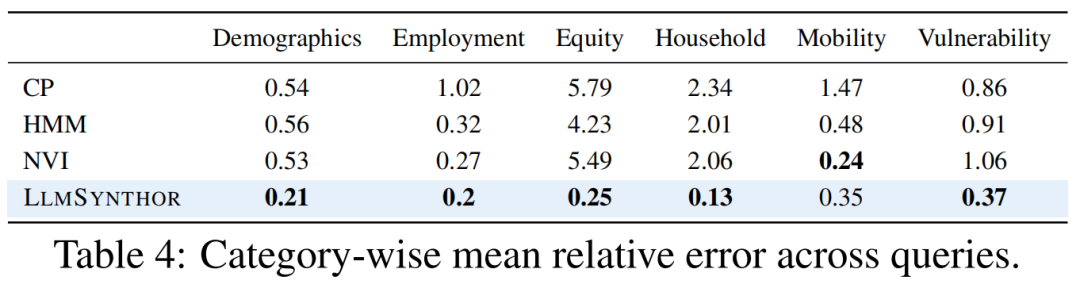
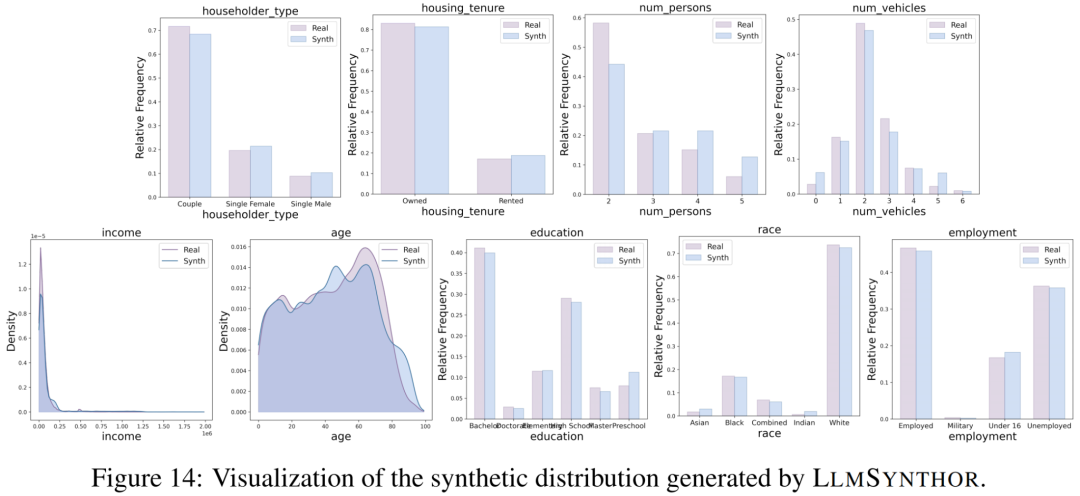
在人口数据包含家庭-个人嵌套结构,天然非结构化。这类数据广泛应用于城市规划、政策评估、资源配置等关键任务。LMSynthor可处理此类复杂结构,并在6类共16项政策指标上(如老年贫困率),显著优于已有方法。
城市出行模拟
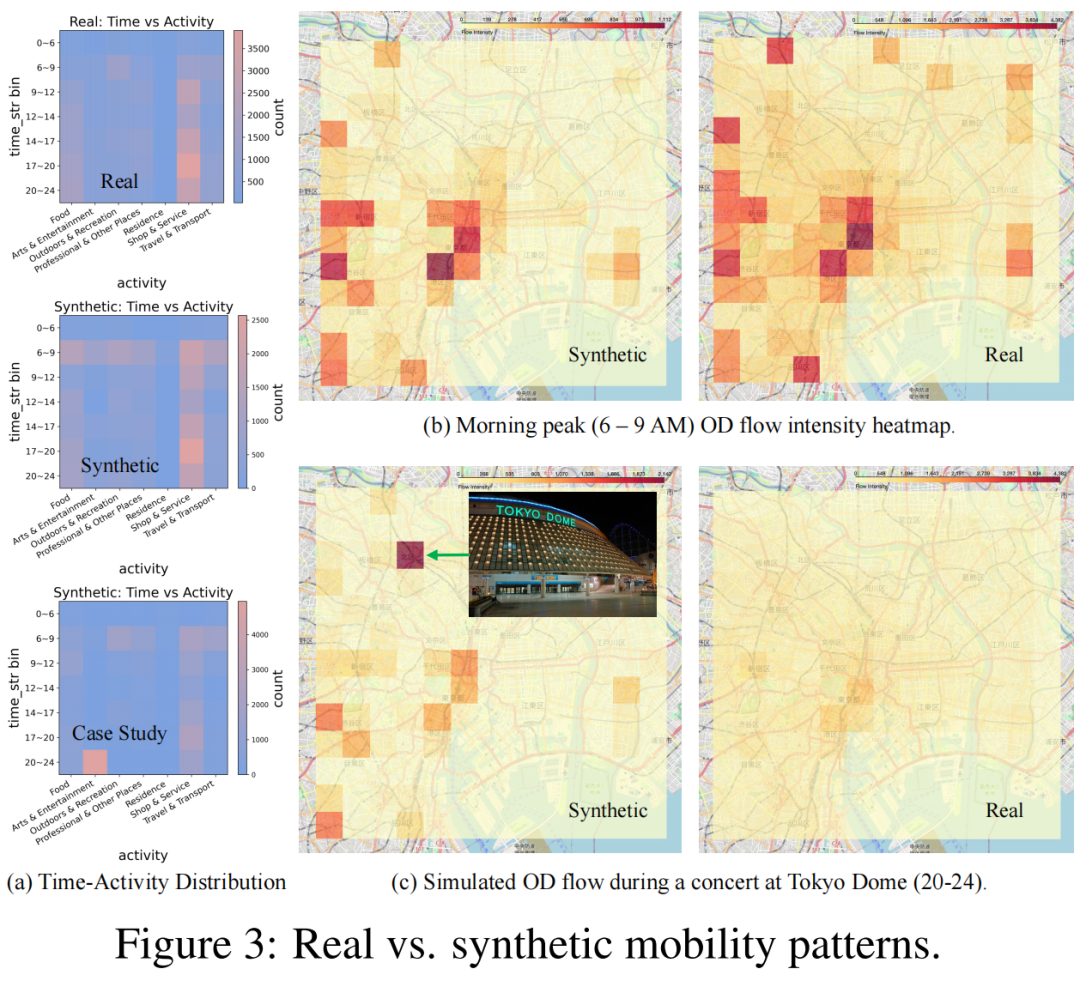
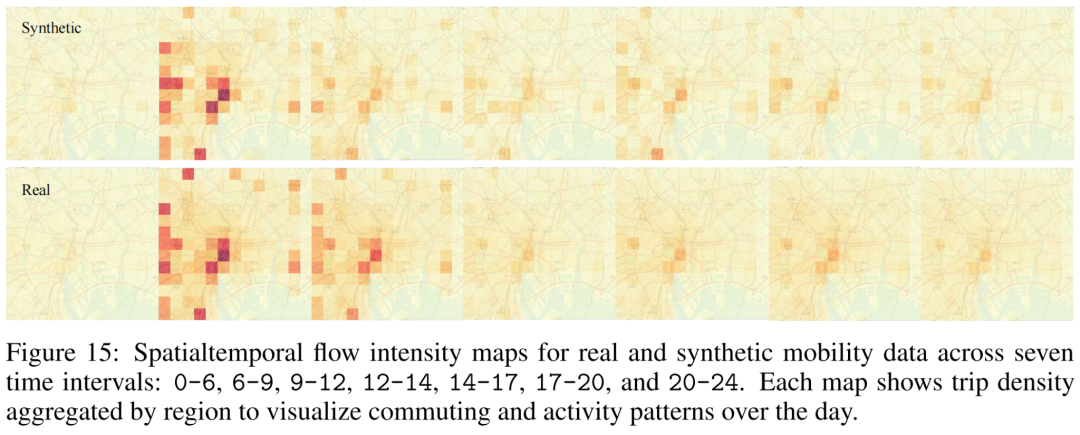
出行数据包含时序、地理、行为等多种复杂类型,是交通仿真和应急管理的基础。
LLMSynthor基于多源数据,成功生成符合城市节奏的模拟轨迹。更关键的是,它能响应prompt控制生成。
比如输入“晚上8点东京巨蛋有演唱会”,合成数据便展现出对应时段的潮汐客流变化,展现出现实还原力和场景操控能力,适用于政策仿真与事件预演。
大模型兼容情况
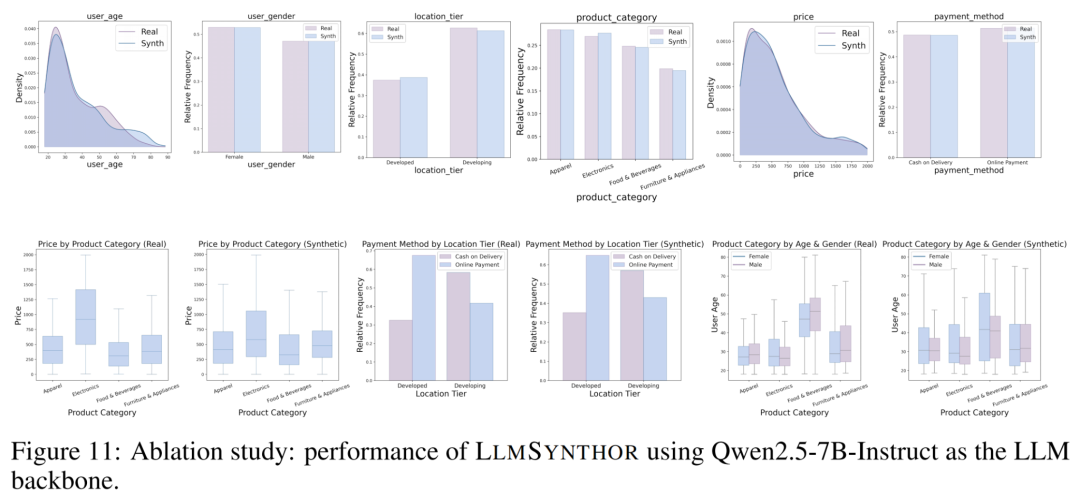
LLMSynthor生成效率高、无需训练,同时兼容多种大模型,换用如Qwen-2.5-7B等开源模型也能稳定运行,具备良好扩展性与落地适配能力。
论文链接:https://arxiv.org/pdf/2505.14752
项目地址:https://yihongt.github.io/llmsynthor_web/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
