
ICML2025
论文1:Elucidating the Design Space of Multimodal Protein Language Models (ICML spotlight)
作者:Xinyou Wang* (王辛有), Cheng-Yen Hsieh*, Daiheng Zhang (张代恒), Dongyu Xue (薛东雨), Fei Ye (叶菲), Shujian Huang (黄书剑), Zaixiang Zheng (郑在翔), Quanquan Gu (顾全全)
单位:南京大学,罗格斯大学,字节跳动
链接:https://arxiv.org/abs/2504.11454
论文简介:
蛋白质是由氨基酸序列折叠成特定空间结构的生物大分子,基于 AI 助力蛋白质建模与设计是当前 AI for Science 中的最重要的研究方向之一。2024 年的诺贝尔化学奖颁发给了 DeepMind 的 AlphaFold,该成果基于 AI 解决了结构生物学中困扰了 50 年的蛋白质折叠和结构预测问题,逐渐应用于药物设计(如抗体开发)、酶工程和疾病治疗等场景中。蛋白质氨基酸序列与自然语言的数据形式具有内在的相似性。受此启发,南京大学自然语言处理组与字节跳动 ByteDance Research 紧密合作,近年来在基于生成式AI的蛋白质建模与生成中持续探索,相关系列工作 DPLM(一种通用的扩散蛋白质语言模型)和 DPLM-2(多模态的蛋白质基座模型)已分别发表在ICML 2024 和 ICLR 2025,本文是该系列工作的最新进展。代码开源地址:https://github.com/bytedance/dplm,项目主页:https://bytedance.github.io/dplm/。
多模态蛋白质语言模型(Multimodal PLM)能够同时建模和生成蛋白质的结构和序列,为广泛的蛋白质设计任务奠定了坚实基础。蛋白质的序列由氨基酸 token 组成,在我们的前期工作 DPLM 中,我们采用 discrete diffusion 的建模方式,并取得了良好的效果。 蛋白质的结构信息是以坐标形式表示的连续数据类型,建模时需要将其离散化成结构 token,再与序列信息联合。我们认为现有多模态蛋白质语言模型的结构建模存在三个重要的挑战:1)对连续坐标的离散化会引入信息损失,从而导致蛋白质结构的细粒度信息丢失;2)离散的结构 token 无法准确体现局部结构特征的内在关联,对预测的准确度带来较大的挑战;3)缺少蛋白质结构的几何关系建模,导致难以准确捕捉残基在三维空间中复杂的交互关系。
为此,我们针对性提出了解决方案: 1)采用更精确的针对蛋白结构的生成式建模方式,提升了结构预测的准确度。2)利用显式的蛋白质结构的几何信号监督,通过引入几何模块和表征对齐,提升了蛋白质结构的几何关系建模能力。实验结果显示,本文提出的技术方案显著提升了多模态蛋白质语言模型的结构生成表现,对于蛋白质折叠任务的RMSD(结构预测误差指标)从 5.52 降低至 2.36 ,与专门的蛋白质折叠模型 ESMFold 持平;在无条件蛋白质生成中,采样多样性提升约30%,改善了之前采样多样性较差的问题,同时保证采样蛋白的质量。

ACL2025
论文1:Alleviating Distribution Shift in Synthetic Data for Machine Translation Quality Estimation(主会)
作者:Xiang Geng* (耿祥), Zhejian Lai* (赖哲剑), Jiajun Chen (陈家骏), Hao Yang (杨浩), Shujian Huang (黄书剑)
单位:南京大学,华为
链接:https://arxiv.org/abs/2502.19941
论文简介:
机器翻译质量评估(Quality Estimation, QE)模型旨在无需参考语句的情况下评估机器翻译语句的质量,常被用作翻译任务中的奖励模型。然而,由于高质量QE训练数据的稀缺,合成数据生成逐渐成为一种可行的替代方案。但现有合成QE数据常面临分布偏移问题,表现为合成翻译语句与真实翻译语句在分布上的差异,或合成QE标签与人类偏好之间的不一致。
为解决这一挑战,本文提出ADSQE,一个旨在缓解合成QE数据分布偏移的新型框架。该框架通过约束束搜索算法控制合成翻译语句的生成,并引入多种不同的翻译模型以增强合成翻译语句的多样性,从而缩小合成翻译语句与真实翻译语句之间的分布差异。为了提升合成QE标签与人类偏好的一致性,ADSQE借助参考语句作为监督信号,引导合成过程中的生成与标注,并通过识别连续错误单词所覆盖的最短短语片段从而模拟人工标注行为,将词级别QE标签聚合为短语级别QE标签。
特别地,我们强调:(1)正确的监督信号应该在数据合成过程中发挥重要的作用;(2)模型无法准确地标注自己的输出;(3)多样化的生成模型有助于合成数据质量提升。这些见解在ADSQE的设计中均得到了体现。
实验证明,ADSQE在有监督和无监督设置下均优于现有SOTA方法(如CometKiwi)。进一步的分析表明,ADSQE在合成数据生成方面的见解对其他任务中的奖励模型也具有一定的启发意义。
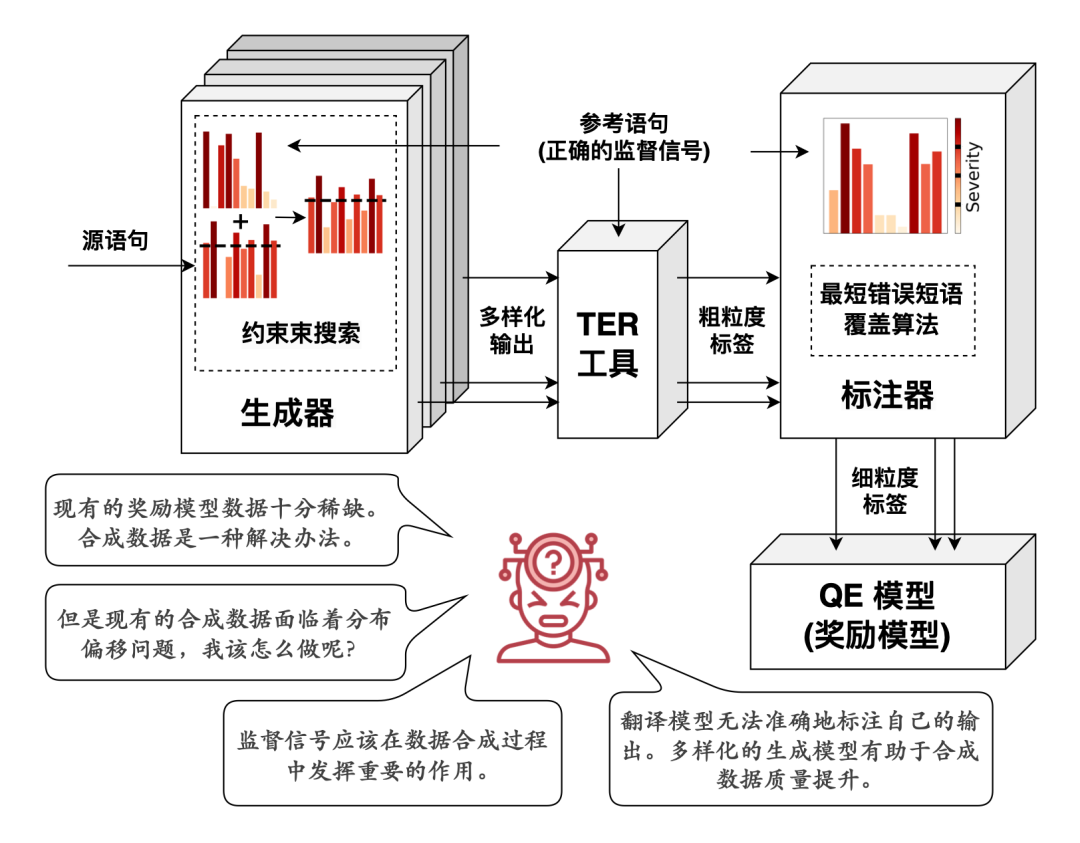
我们探索了通过利用监督信号和增加模型多样性来提升QE合成数据质量的方法。直方图表示翻译模型的生成概率。
论文2:Investigating and Scaling up Code-Switching for Multilingual Language Model Pre-Training(findings)
作者:Zhijun Wang(王志军), Jiahuan Li(李家欢), Hao Zhou(周昊), Rongxiang Weng(翁荣祥), Jingang Wang(王金刚), Xin Huang(黄鑫), Xue Han(韩雪), Junlan Feng(冯俊兰), Chao Deng(邓超), Shujian Huang(黄书剑)
单位:南京大学,美团,中国移动研究院
链接:https://arxiv.org/abs/2504.01801
论文简介:
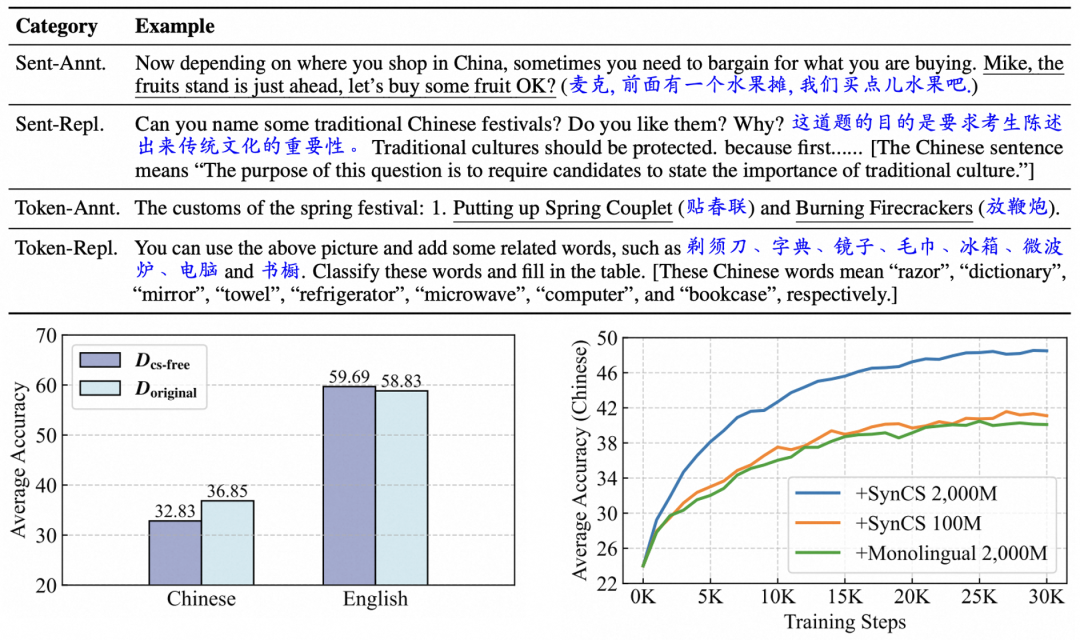
尽管大语言模型的预训练数据中存在极端的语言不平衡现象,其仍能展现出显著的多语言能力,即大模型存在自发的跨语言迁移现象。本文从预训练语料的角度出发,深入分析了这一现象背后的原因。我们发现,预训练数据中自然存在的极少量语码切换(Code-Switching),即在相同上下文中交替使用不同语言的数据,是该现象产生的关键因素。为了进一步促进该语言迁移过程,我们提出了SynCS(合成语码切换,Synthetic Code-Switching),具有合成数据质量高、成本低且速度快的优势。在预训练阶段使用SynCS数据之后,我们的模型在 12 项涵盖通用知识、自然语言理解和推理能力的基准测试中,目标语言能力平均提升超过 2 个百分点。 经过下游任务微调,我们的基座模型相较于使用单语数据预训练的基座模型,在翻译任务上的 COMET 评分提升了 3.7,在基于 XNLI 的零样本跨语言迁移任务上准确率提升了 3.4 个百分点。此外,相比于自然数据预训练过程中的自发缓慢对齐,SynCS数据的跨语言迁移效率相当于20倍数据量的目标语言单语数据,并能够很好地泛化到高资源、中资源和低资源语言。 进一步的分析表明,使用 SynCS 数据预训练的模型展现出更高的多语言对齐水平。
论文3:Why Not Act on What You Know? Unleashing Safety Potential of LLMs via Self-Aware Guard Enhancement(findings)
作者:Peng Ding (丁鹏), Jun Kuang (匡俊), Zongyu Wang (王宗宇), Xuezhi Cao (曹雪智), Xunliang Cai (蔡勋梁), Jiajun Chen (陈家骏), Shujian Huang (黄书剑)
单位:南京大学,美团
链接:https://arxiv.org/abs/2505.12060
论文简介:
大型语言模型(LLMs)已在各类任务中展现出令人瞩目的能力,但仍易受精心设计的越狱攻击影响。本文指出一个关键安全差异:尽管 LLMs 擅长检测越狱请求,却常在直接处理此类输入时生成不安全响应。基于此洞察,我们提出 SAGE(自我感知防护增强),一种无需训练的防御策略,旨在将 LLMs 强大的安全判别性能与其相对较弱的安全生成能力相匹配。SAGE 包含两个核心组件:判别分析模块和判别响应模块,通过灵活的安全判别指令增强模型抵御复杂越狱攻击的能力。大量实验表明,SAGE 在不同规模和架构的开源与闭源 LLMs 中均表现出有效性和鲁棒性,针对多种复杂隐蔽的越狱方法实现平均 99% 的防御成功率,同时在通用基准测试中保持有用性。我们进一步通过隐藏状态和注意力分布进行机制可解释性分析,揭示了判别与生成能力差异的潜在机制。

论文4:Trans-Zero: Self-Play Incentivizes Large Language Models for Multilingual Translation Without Parallel Data(findings)
作者:Wei Zou (邹威), Sen Yang (杨森), Yu Bao(鲍宇), Shujian Huang (黄书剑), Jiajun Chen (陈家骏) ,Cheng Shanbo (程善伯)
单位:南京大学,字节跳动
链接:https://arxiv.org/abs/2504.14669
论文简介:
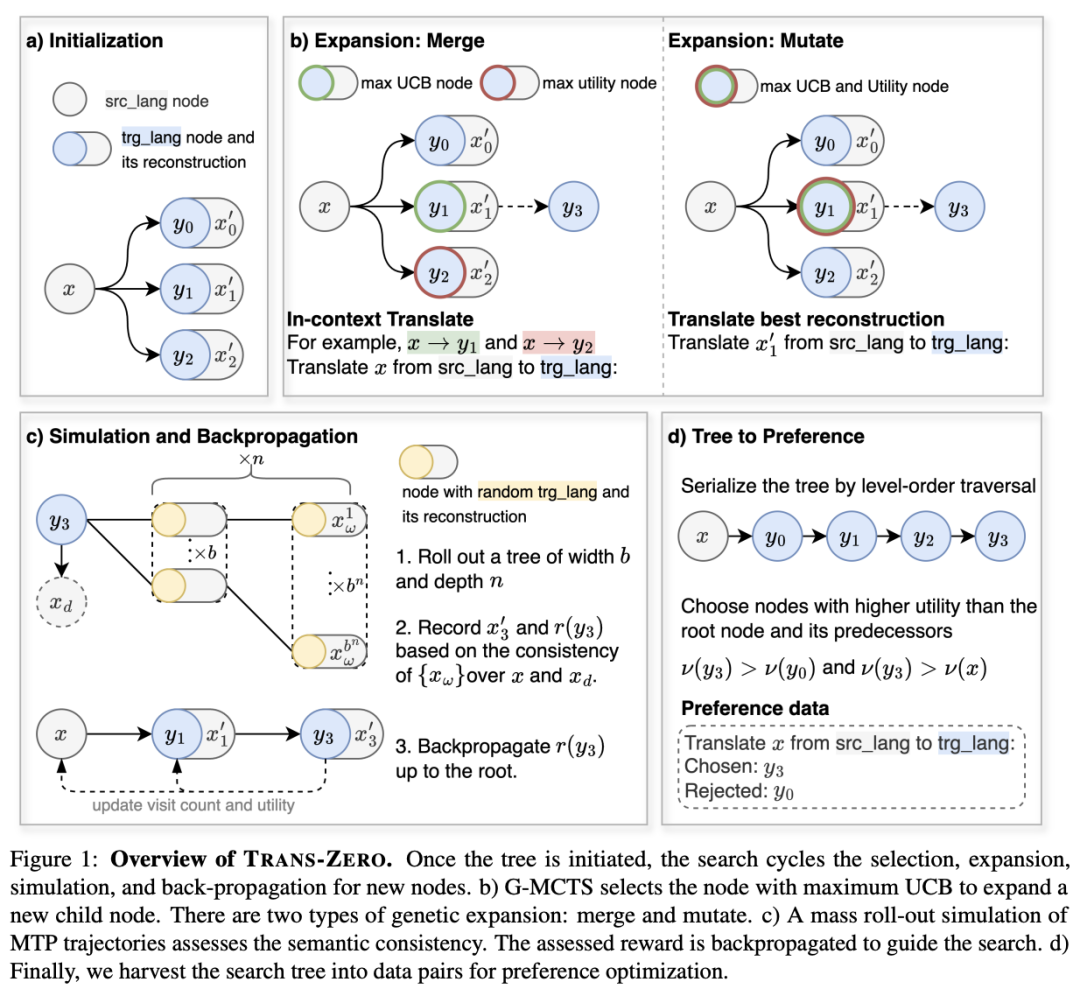
大型语言模型(LLM)的兴起重塑了机器翻译(MT),但多语言MT仍然依赖于并行数据进行监督微调(SFT),面临着诸如低资源语言数据稀缺和监督训练导致的灾难性遗忘等挑战。为了解决这些问题,我们提出了Trans-Zero,这是一种仅利用单语数据和LLM固有多语言知识的自我博弈(self-play)训练MT 的框架。我们设计了遗传蒙特蒙特卡洛树搜索(G-MCTS)算法探索大量可能的翻译,并在搜索中基于语义的一致性形成偏好,从而获取偏好优化的数据。通过迭代探索和偏好优化,即可无监督地训练机器翻译。实验表明,这套训练框架能在 60 轮迭代中使用2万句多语言单语数据,即达到500万大规模平行数据SFT的多语言翻译性能。进一步的分析表明,即使只进行 G-MCTS,而不更新模型参数,LLM也能获取更优的翻译结果。这一能力也是自我博弈训练能够取得成功的基础。
论文5:CapArena: Benchmarking and Analyzing Detailed Image Captioning in the LLM Era(findings)
作者:Kanzhi Cheng (程瞰之), Wenpo Song (宋汶珀), Jiaxin Fan (范家鑫), Zheng Ma (马征), Qiushi Sun (孙秋实), Fangzhi Xu (徐方植), Chenyang Yan (闫晨阳), Nuo Chen (陈诺), Jianbing Zhang (张建兵), Jiajun Chen (陈家骏)
单位:南京大学,香港大学,上海AI Lab
链接:https://arxiv.org/abs/2503.12329
论文简介:
图像描述是视觉语言领域一项基础且重要的任务,随着大模型的兴起,当今的视觉语言模型(VLMs)能够生成全面且详细的描述,生成质量有了大幅度的提升。然而对于此类描述的质量进行基准测试仍然是一个悬而未决的问题。首先,为了探究当前的视觉语言模型在图像描述方面的实际表现如何,本工作构建了拥有6000多个高质量人类偏好标注对的平台 CapArena。结果表明,GPT-4o 等领先的模型在图像描述任务上已经达到甚至超过了人类水平,而大多数开源模型仍落后于人类,且有较大的差距。接下来本工作探究自动化指标能否可靠地评估详细的字幕质量。利用CapArena中的人类标注,本文系统的探究了从传统到最新图像描述指标以及 VLM-as-a-judge 方法的性能,分析表明,虽然某些指标与人类偏好在样本层级上显示出了较高的一致性,但其系统性偏差导致了模型层级的排名不一致。相比之下,VLM-as-a-Judge 在样本和模型两个层级上都表现出了强大的辨别能力。基于上述发现,本文最终发布了准确、高效的详细图像描述自动化评估基准 CapArena-auto,与人类排名的相关性提升到了94.3%,且单次测试成本降低至4美元。

论文6:Beyond Verbal Cues: Emotional Contagion Graph Network for Causal Emotion Entailment(findings)
作者:Fangxu Yu(余方续), Junjie Guo(郭俊杰), Zhen Wu(吴震), Xinyu Dai(戴新宇)
单位:南京大学
论文简介:
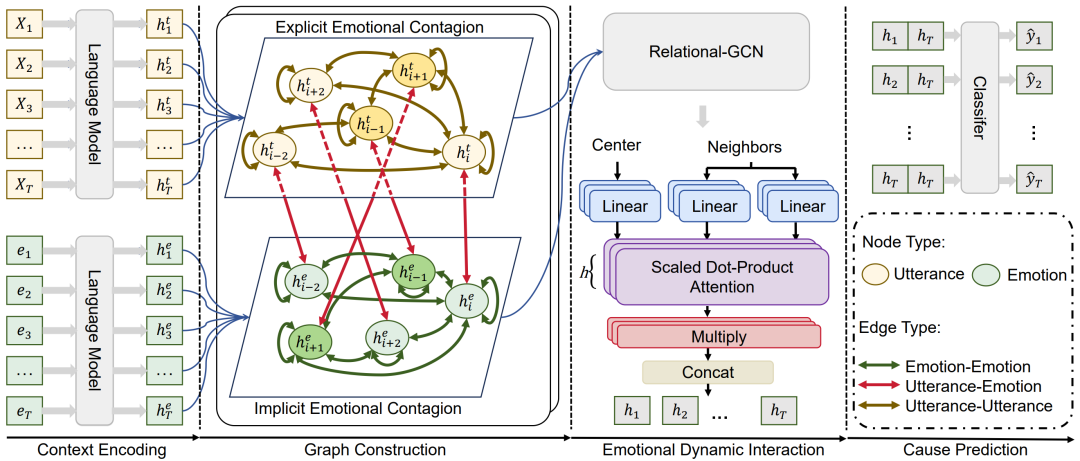
情绪对对话理解至关重要。虽然近期研究工作在对话情绪识别和情绪响应生成方面取得了重大进展,但对引发情绪的原因的认识却很少被探索。之前的研究主要集中在通过理解言语语境话语来识别情绪的原因,忽视了非言语情绪线索可以引发情绪。为了解决这个问题,我们开发了一个情绪感染图网络(ECGN),模拟非言语隐性的情绪对对方情绪的影响。为了实现这一目标,我们构建了一个异质图,模拟非言语情感与言语影响的传递。通过在节点之间应用消息传递,构建的图有效地模拟了隐式情绪动态和显式的言语互动。我们通过在基准数据集上进行广泛的实验来评估ECGN的性能,并将其与多个最先进的模型进行比较。实验结果证明了所提出模型的有效性。
论文7:Process-based Self-Rewarding Language Models(findings)
作者:Shimao Zhang (张世茂), Xiao Liu (刘啸), Xin Zhang (张鑫), Junxiao Liu (刘俊潇), Zheheng Luo (罗哲恒), Shujian Huang (黄书剑), Yeyun Gong (宫叶云)
单位:南京大学,微软亚洲研究院,曼彻斯特大学
链接:https://arxiv.org/abs/2503.03746
论文简介:
当前大型语言模型在各种下游任务中表现出色,已被广泛应用于多种场景。人们往往使用人类标注的偏好数据进行训练,以进一步提高大语言模型的性能,但这种方法受到人类表现上限的限制。因此,有研究者提出了自我奖励范式,即 LLM 通过对自己的输出生成奖励信号来生成训练数据。然而,现有的自我奖励范式在复杂数学推理任务场景中表现不佳,甚至可能导致推理性能下降。我们发现当前的范式存在两点局限性:(a) 无法为长思维链推理提供细粒度的步骤级奖励;(b) 人为设计的单一打分准则难以适应复杂的数学推理。因此,在这项工作中,我们为 LLMs 提出了新的基于过程的自我奖励范式。我们在自我奖励范式中引入了长思维链推理、步骤级 LLM-as-a-Judge 和步骤级偏好优化。我们的新范式通过迭代的基于过程的自我奖励(Process-based Self-Rewarding),成功提高了大语言模型在多个复杂数学推理基准上的性能。通过数轮迭代,我们的方法显著优于基线方法,7B和70B模型在多个测试基准上分别取得了8.6%和8.4%的提升,接近甚至超过了GPT-4o的表现。这展示了基于过程的自我奖励在实现更强的大语言模型推理和超越人类能力的人工智能方面的巨大潜力。

内容中包含的图片若涉及版权问题,请及时与我们联系删除
