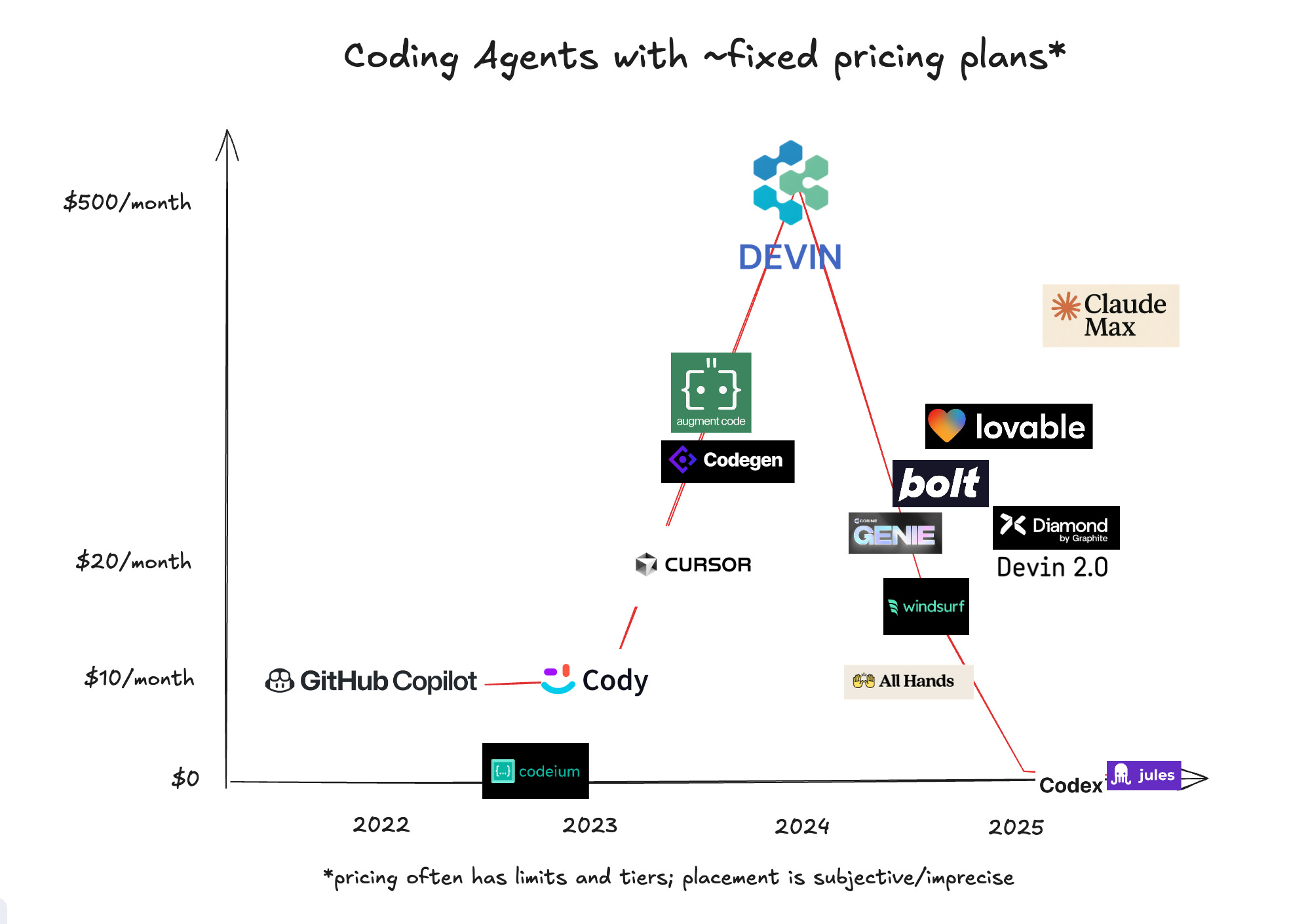
The recent launches of the Codex and Jules Devin-like autonomous coding agents came with some interesting pricing decisions: they come at no extra cost1. You no longer have a reason to send off every thought to the agents (even more than once) even if you intend to eventually code it yourself.
And of course there are a lots of premium and open source coding agents with Bring Your Own Key and reasonably metered usage like Github Copilot Coding Agent and the newer Amp Code.
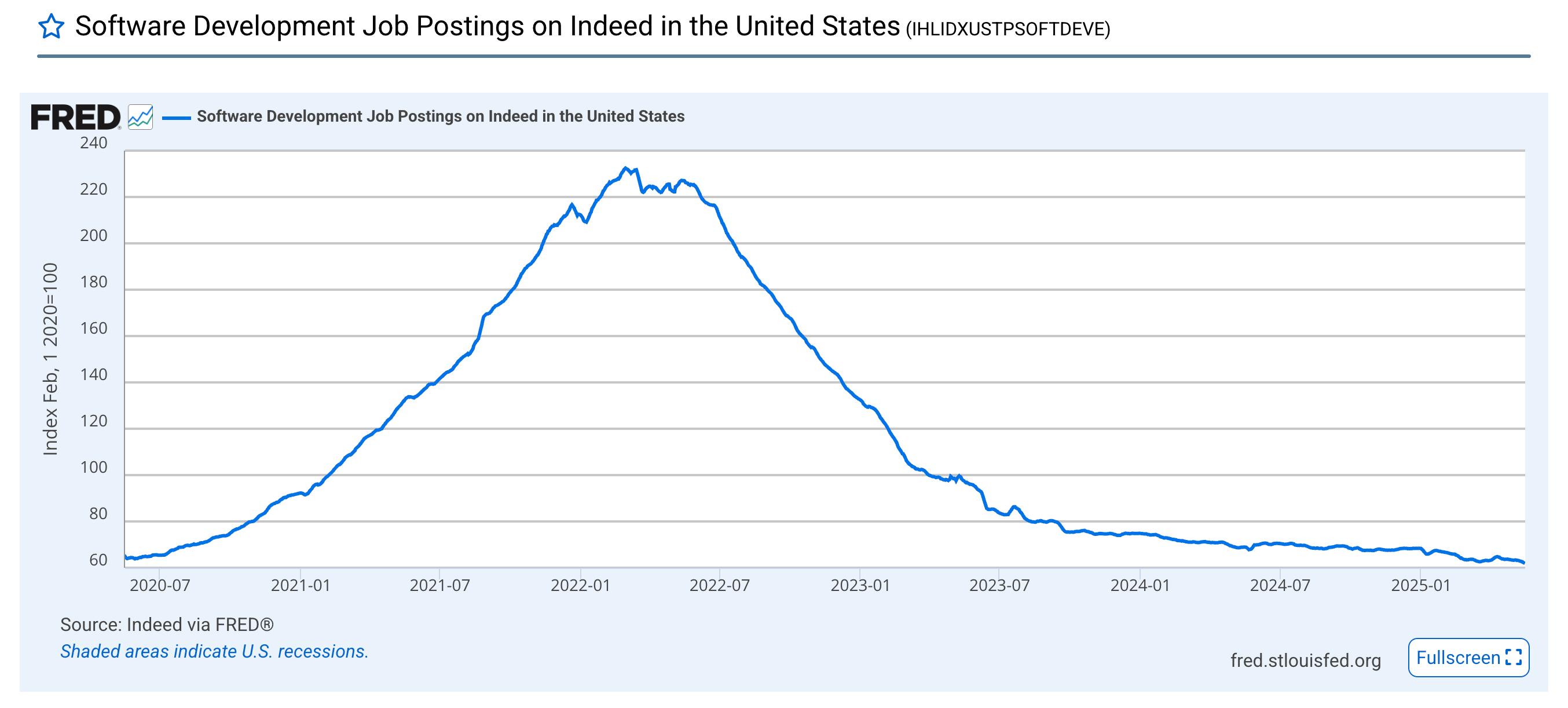
Side note: A less rigorous publication than the one you’re reading could observe correlation of the rise of coding agents with the infamous Indeed software developer job postings chart and conclude causation:
However our sense is that, especially with the frontier labs launching effectively unlimited usage plans, the competitive war in coding agents has come to the point where the norm of charging a premium over token usage as a coding agent GPT wrapper has now FLIPPED to offering discounts in order to get your usage data.
That’s insane, you say. Lighting VC money on fire at negative margins is unsustainable!
Latent.Space is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Realizing The Value of User Data
The CodeGen, and now SWE Agent2, market3 has thus progressed as such:
First, charge a small flat fee for a new product category (Copilot)
Then, offer a free consumer edition and make money in enterprise (Codeium)
Then seek out the high end of the category and charge a premium (Devin)
Then broaden audience to noncoders (Bolt) and be MORE agentic (Windsurf)
Charge flat-rate or free to get user data to build products + models (Codex, Jules)
As the average MMLU and SWEBench of every model goes up, so does the competition for increasingly advanced data to build those models. If we have exhausted GitHub and StackOverflow as datasets reflecting the average programmer, then we need elite ones per domain, and so on. We have heard rumors that there are now niche data services - in the style of Scale and Turing - that employ ex-industry professional humans specialized in creating/labeling medical, financial and coding data for labs, paying up to $500k/year per human. A scaled operation of 100 of these would cost an easy $50m/year.
That’s 6.25 TRILLION tokens of GPT4.1. The average coder consumes about 2m tokens a day per Claude Code numbers, so if you could figure out a way to collect useful data to your domain, you can justify giving away tokens as an alternative to paying for data - probably more because your users are the most specifically suited, self selected and self motivated labelers you will ever get. This is why you can kind of justify that Perplexity is classifying free tier costs as R&D if you squint really hard.
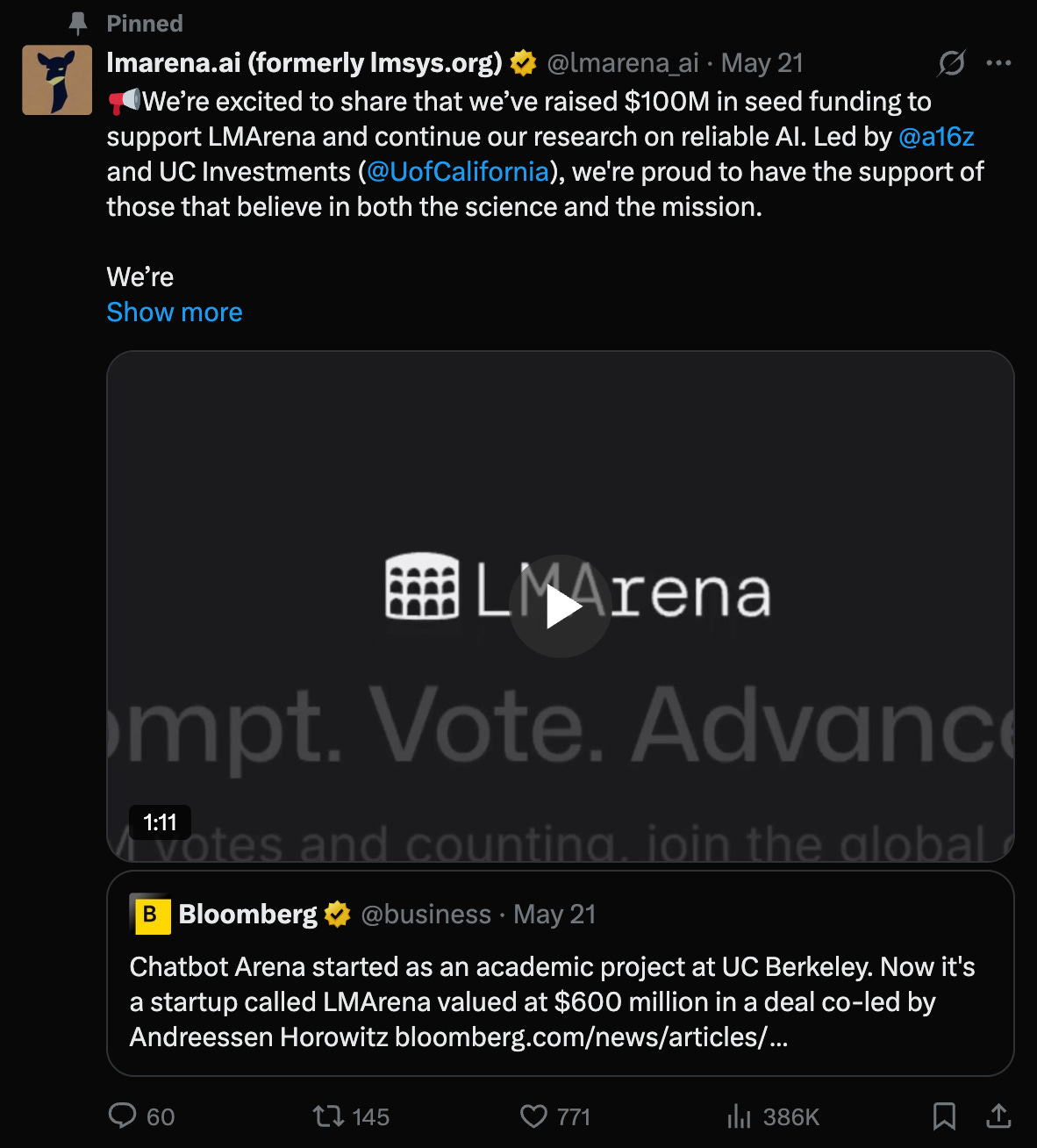
When we first wrote about the Four Wars of the AI Stack, most of the conversation was around data acquisition from traditional content houses and synthetic data for the rest. While synthetic data is still relevant e.g. for changing the Robotics scaling curve, the Data War is now fully focused on getting *YOUR* data as model input and grader. The best bellwether for this is LMArena’s $100m Seed round, done a few months ago but announced this week and raising a lot of eyebrows:
given recent drama with Meta and Cohere, though of course it is the only eval with dozens of mentions at Google I/O.
Just as Airbnb doesn’t own hotels and Uber doesn’t own cars, this is an LLM Evals, aka LLM Data, company that doesn’t employ any of the human raters it uses to derive its scores. One appeal of using LMArena beside the warm fuzzies of “giving back” is that all inference in the battles are free, presumably subsidized by every provider partner. The arrival of a16z, Felicis, and other top tier VCs means there is only one way this goes: You will start getting paid if you are a good LMArena participant4.
In other words, GPT wrappers will go from charging a premium on tokens, to charge + flat rate, to free, to now we pay you to use tokens from us with good feedback.
And if LMArena can get a $100m blessing to do this for their users… why shouldn’t you?
Vibe Coding vs Tiny Teams
A few people have asked my opinion on the vibecoding trend. At almost every SF house party, a technical engineer or three will sheepishly admit that they’ve been vibe coding, like it’s some sort of vice. We even went ahead and put in a Vibe Coding category in the AIE CFP. But ultimately we nixed it in favor of “Tiny Teams”: the rising trend of small but extremely productive teams augmented by SWE Agents (not necessarily making AI products). The simplest (but hardest) statement of this is “teams with more m in ARR than employees”5, which is rarefied air but already reached by @levelsio6, Cognition, Bolt, Gumloop and Gamma.
Tiny Teams are the scaled form of second type of AI Engineer predicted in The 1000x AI Engineer, and is the more realistic near term version of the “one person unicorn” that every thoughtleader is fantasizing about. Tiny Teams are easily profitable - most tech businesses are 60%-90% margin and most cash compensation should be <$250k - and therefore are also likely to lead to Pegasus and other outcomes.
The way I put it to a friend recently is that “vibe coding” is a slop attractor, while “Tiny Teams” focuses on productivity. One might look askance at Rick Rubin’s new book on Vibe Coding as one such instantiation, whereas it’s pretty hard to deny that a Tiny Team (in the way we have defined it) is an unambiguously Good Thing and a direct consequence of declining end-user costs in SWE Agents.
At the end of the day, of course, have a good idea of what you are building (aka Product Management) is paramount, when everywhere you look an AI builder appears:
This is a prediction made without any prior knowledge of LMArena plans, but we’re putting it down for posterity. Anastasios and Wei-Lin are smart guys.