
来源:https://zhuanlan.zhihu.com/p/706106906
近期,gsm8k、MATH被各种7B小模型刷的飞起,其中,step-level-dpo成为刷分利器。这里,instance-level-dpo指 preference-dataset使用 完整的chosen-tracjectory和rejected-tracjectory。
而step-level-dpo则使用step-chosen、step-rejected构造偏序数据集。相比instance-level-dpo,step-level-dpo则使用如下公式:
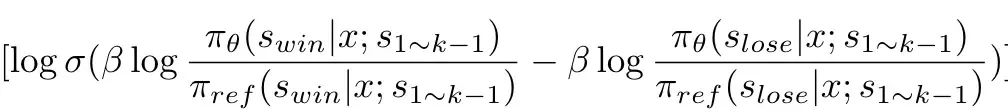
相比instance-level-dpo,step-level-dpo只优化step-level的数据,而共同前缀则作为prompt的一部分,不参与loss计算。这里,我们首先介绍几篇与step-dpo相关的文章。
Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
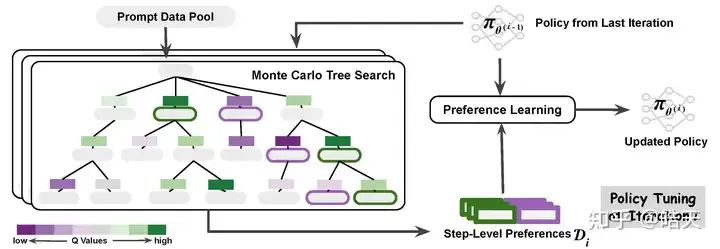

该文章提出step-level-dpo,为了获取step-level的偏序数据,则使用树搜索获取具有共同前缀的step-level偏序数据。使用树搜索可以天然地获取具有共同前缀的preference-dataset,而且,可以利用UCT、estimated-Q等等,选择preference-step,以及 对 step-dpo算法做label smoothing 如 根据访问次数对dpo-loss做平滑。
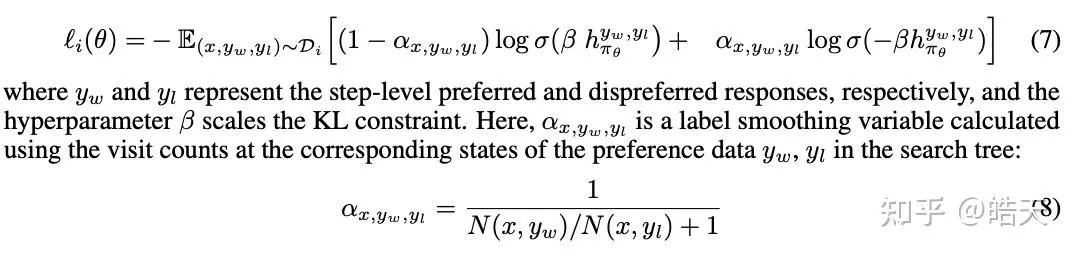
Step-level Value Preference Optimization for Mathematical Reasoning
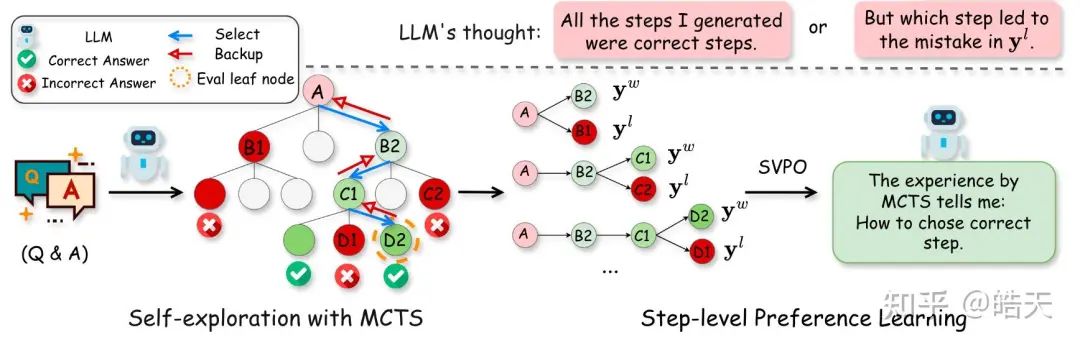
该工作继承了alphamath,将value-function估计与step-level-dpo结合。preference-dataset的构造与[1]类似,即使用树搜索+output-reward筛选chosen、rejected step。在整个模型训练过程中,加入了value-head的训练,解码时,可以使用value-guided-decoding,采样复杂度介于greedy/random-sample和MCTS之间,达到更好的效果。该工作在训练中,为了防止模型退化,加入了sft-loss。
RL on Incorrect Synthetic Data Scales the Efficiency of LLM Math Reasoning by Eight-Fold
该文章系统地讨论了使用答案错误样本提升数学能力的方法。
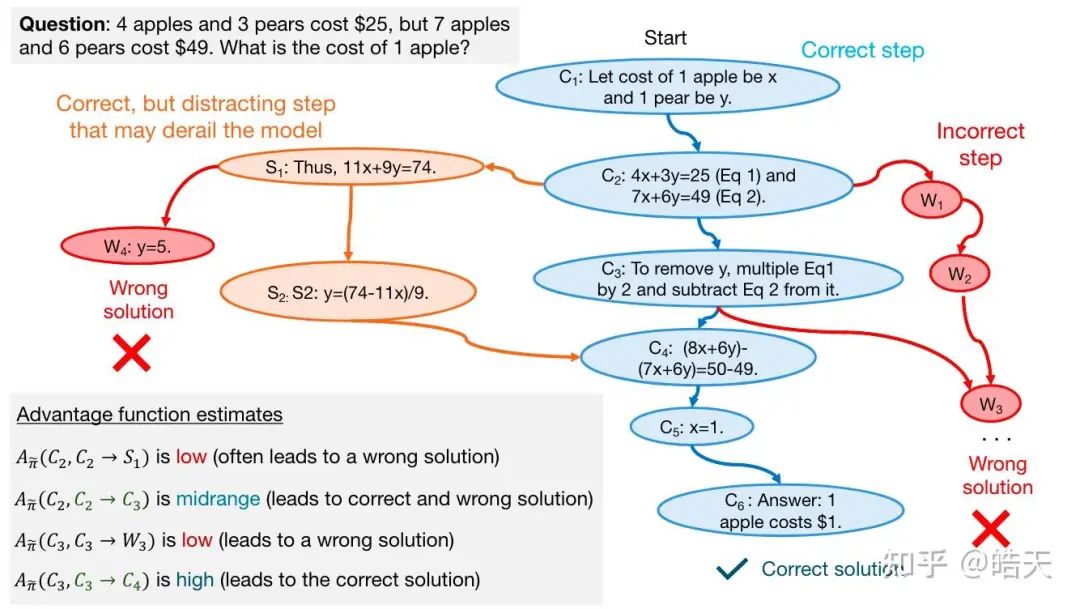

相比前几个工作,该工作使用朴素的rollout,估计每个step的value-function,并根据q值,获取chosen和rejected-step。当使用step-level-dpo优化时,达到相同acc,可以少用8倍的数据量。
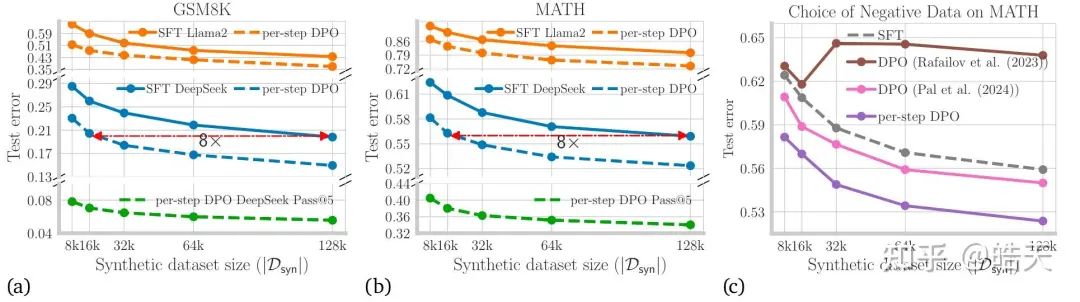
同时,该工作也指出,当我们使用step-dpo时,模型具备step-level的错误检测能力(与文章[4]的观点类似):

Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs
该工作是笔者认为近期较为扎实的工作,虽然只在gsm8k、math两个数据集上完成的实验,但在足够的多base、instruct以及rl模型上进行实验,证明了step-dpo在不同尺寸的强基线上依然可以取得更好的结果。
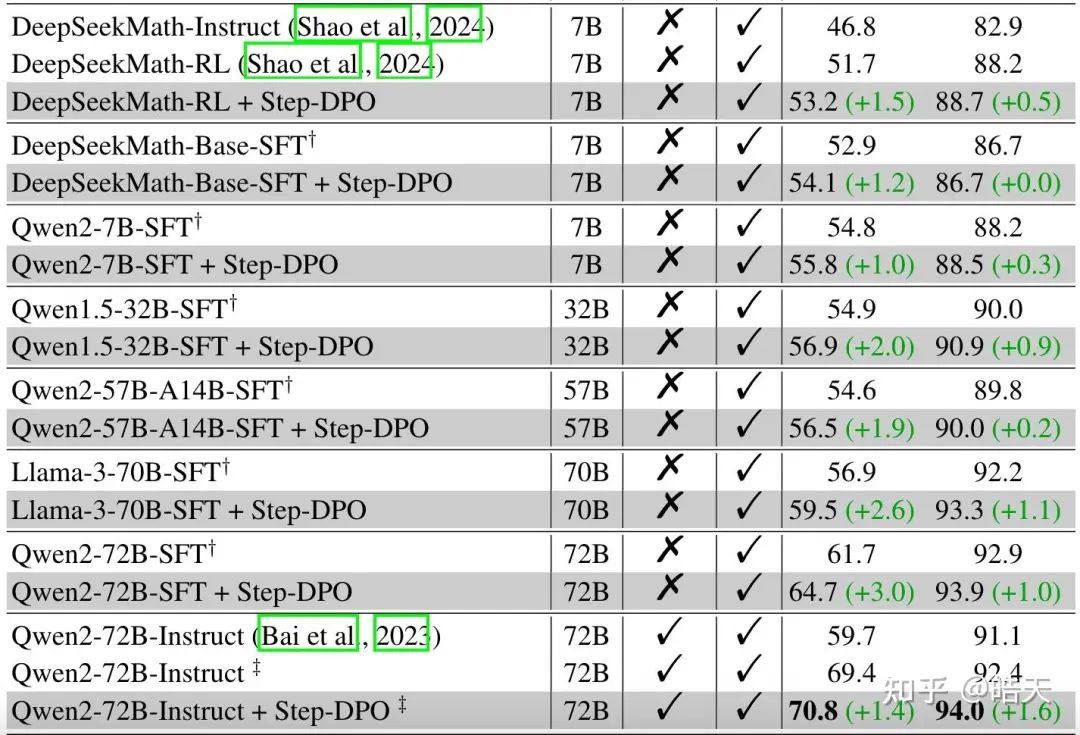
从结果上来看,step-dpo在deepseekmath-rl上依然有一定的提升(尤其是在MATH上)。此外,在qwen2不同尺寸、llama3上,从7B到70B,step-dpo依然可以带来一致性的提升。
从preference-dataset的构造上来看,该文章首先用deepseek-math-instruct在metamath、MMIQC等数据集完成一次推理,获取符合特定格式的response。并根据answer筛选答案正确的数据作为训练数据。在构造preference-data时,和前述的工作类似,但使用了和sft-dataset不同的prompt数据。
之前,我们简单探讨过tdpo在eurus上的评测。这里,我们在Step-DPO-10k的preference-dataset上进行实验的复现,以及 tdpo在有共同前缀response上的性能评测。
step-dpo使用文章里面的超参数,dpo-beta=0.4
数据集: Step-DPO-10k
由于Step-DPO的提供了(step-chosen,step-rejected)、(full-chosen,full-rejected)的数据集,我们进行了共同前缀的step-level、共同前缀的instance-level的dpo训练。
对于tdpo,我们使用instance-level的数据,区别仅在于共同前缀放prompt还是response。当共同前缀放response,则tdpo中的forward-kl 会 消掉且 dpo-loss的前缀loss也会消掉,只剩下不同后缀的forward-kl和dpo-loss。
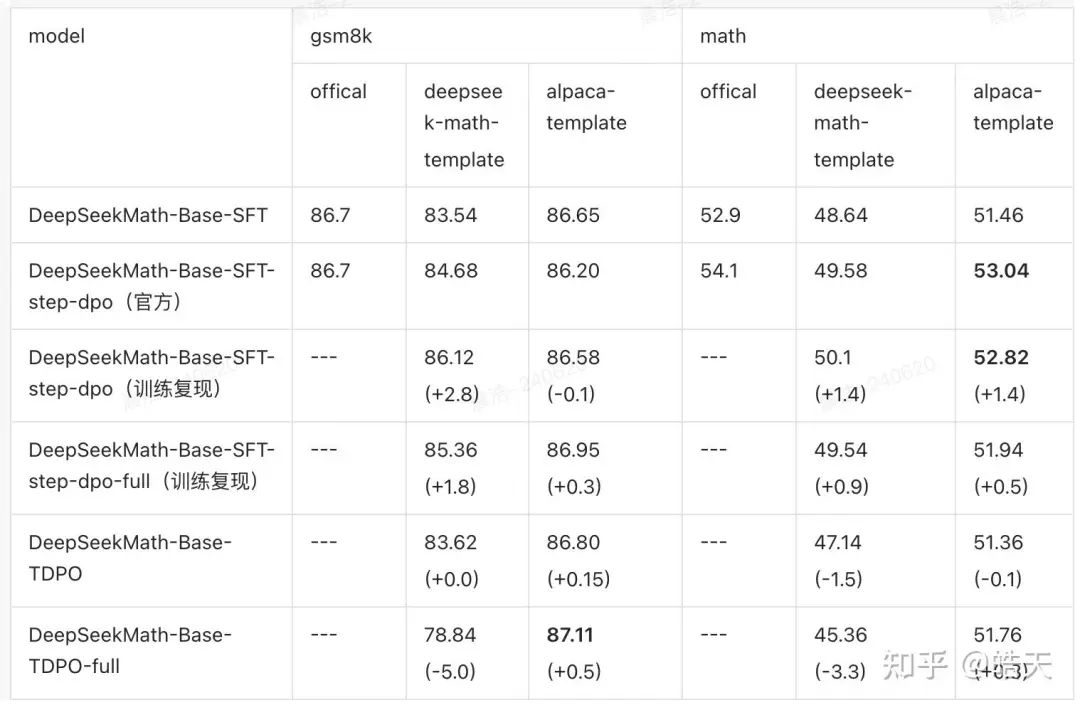
从上表中可以看到,我们重新实现的训练trainer和官方模型的infer结果基本接近。当使用不同的模版时,不管是step-dpo还是tdpo,性能都会有一定的下降。其中,tdpo的性能下降更为明显。
当换成alpaca-template后,tdpo性能符合预期,在gsm8k上,得到87.11的解决率。而step-dpo则在math上的提升更为明显。
不管是Eurus-Preference-Dataset,还是 Step-DPO-Preference-Dataset,都能够给sft模型带来不同程度的提升。尤其是step-dpo、tdpo等等算法,能够取得更为稳定的提升(至少模型能力不退化)。而笔者自己的xpo实验,均基于sft数据集的prompt构建chosen、rejected pair,在xpo等方法上,一训就崩,尤其是数学和code。
当使用新的prompt或者不同模型的response构造的preference-datasets,xpo的训练更为稳定(如eurus-preferenced-dataset、step-dpo-preference-dataset)。当使用新的prompt或者不同模型的response构造的偏序数据,对于xpo等等来说,都算是out-of-distribution dataset。而如果使用sft+sft-model获取的偏序数据,则为in-distribution dataset。对于offline-rl,in-distribution数据似乎限制了模型的优化且更容易破坏模型的原始分布(如数学、code等有一定的格式约束),而ood数据似乎为offline-rl提供了更好的探索。
参考文献
[1] Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
[4] Your Language Model is Secretly a Q-Function

