
The hardest part about working in AI and machine learning is keeping up with it all. I send a weekly email to summarize what’s most important for software engineers to understand about the developments in AI. Subscribe to join 5700+ engineers getting these in their inbox each week.
I’ve decided to name this series “ML for SWEs” to better reflect what it is and who it’s for. Let me know what you think!
This was a huge week for AI. Here’s everything software engineers need to know. We’ll cover:
Manus
Model Context Protocol (MCP)
Google’s AI releases
Andrew Ng: You Should Still Learn How to Code
OpenAI wants to ban Chinese AI

Manus is an AI agent released by a Chinese startup. It made waves on X when it was released with a very impressive demo. Manus can plan trips, surf the web, analyze data, build websites, and more all autonomously and asynchronously.
This is the best “general use” AI agent we’ve seen so far. It isn’t that far ahead of other AI agents in how well it performs tasks, but it can perform a wider range of tasks well. AI agents have huge potential for productivity gain especially in coding when multiple bugs/tickets, etc. can be worked on asynchronously for a huge time gain.
Manus made the massive wave it did partially because of its performance, but also because of its origin. Social media loves to blow up the China vs USA AI debate so impressive models from Chinese startups tend to be amplified. Note: This doesn’t take away from how impressive their achievement is.
Impressive Chinese AI can be concerning (more on that later), but generally the performance and implications of Chinese models is overblown for impressions on social media. For more on Manus, read this resource by to understand why Manus matters and check out testing its capabilities.

Model Context Protocol (MCP) is an open standard for providing context to AI models. This means defining and confining tool use, data access, and more. It was released by Anthropic at the end of last year.
Essentially, MCP works by creating an MCP client on the AI-side and an MCP server on the tool side. The MCP client takes care of interpreting the intent of the AI system and sends it to the MCP server which validates whether that intent is allowed. If it’s allowed, the server completes the action. If it’s not, the MCP server blocks it.
If the MCP server is defined well, it makes it easy to plug-and-play with different AI by connecting them to a given tool using a standard MCP server. Hooking in a new AI just requires defining a new MCP client, which should be lightweight and easy. The goal of using MPC is to minimize overhead for making a change and increase security and privacy by ensuring AI doesn’t have access to things it shouldn’t have access to.
MCP has been met with mixed reviews from AI experts as some believe it unnecessary. As software engineers, we understand the importance of standards and how they make building complex systems easier. We also understand how poor standards tend to fragment systems more as new standards are constantly created to improve the old but infrequently see high adoption.
For more on MCP, here’s a more comprehensive overview.
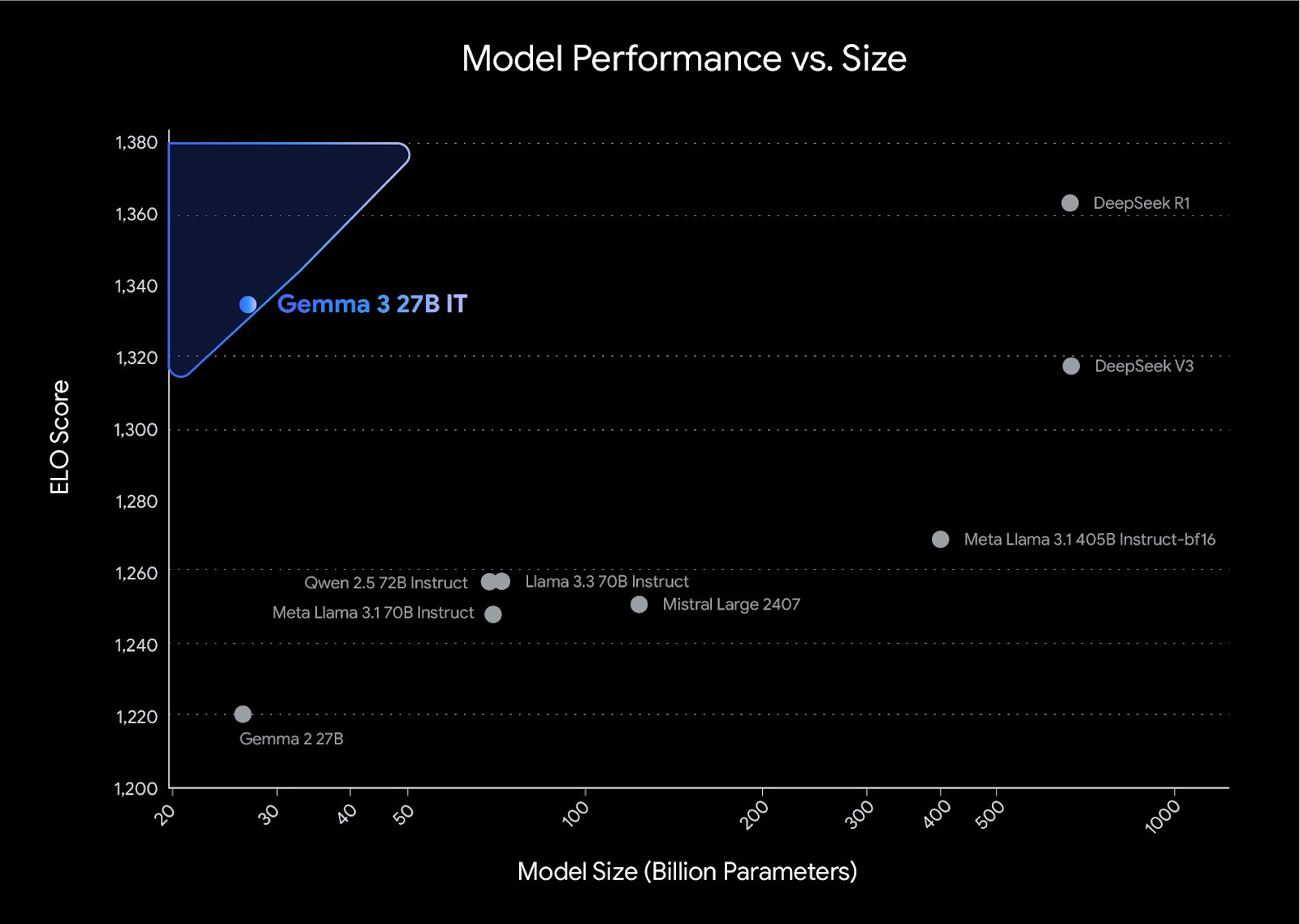
Google released Gemma 3 this past week. It’s an open model that touts high performance (see image above) and can be run on a single TPU. It’s small (only 27 billion parameters), performant, efficient, open, and natively multimodal. It seems like an excellent choice for building, just be aware of what is restricted by its license. It’s great to have Google iterating on an open model and seeing the gains they are.
Google also released updates to its core Gemini products and models. Gemini 2.0 Flash is now natively generates images and is the first model that works accurately to edit images via AI. You can give it a try on AI studio right now. I tried this out myself and it works really well.
Google also updated its Deep Research tool to use Gemini 2.0 Flash Thinking so Deep Research now has reasoning capabilities. They also made this tool free to everyone. You can try it now on the Gemini app/web app. Now that Gemini Deep Research is free, resources are slammed so your research may take a while.
Lastly, Google introduced Gemini robotics, bringing Gemini 2.0 to the physical world. Check out more about that here.

Andrew Ng beautifully stated an argument I (and many others in the ML engineering space) have been making for a while. Teaching people NOT to learn how to code because AI will automate it is not only incorrect and silly, but has potential for long-term negative ramifications in the field of computer science.
He puts forward a quote by a Turing Award and Nobel Prize winner: “It is far more likely that the programming occupation will become extinct [...] than that it will become all-powerful. More and more, computers will program themselves.” We’ve seen quotes like this frequently in the past few years as AI has gotten better at coding.
Andrew Ng’s quote is different because it’s from 1960 when software engineering transitioned away from punch cards to keyboards with terminals. He goes on to write about how programming becoming easier is even more of a reason to learn to code.
I highly recommend reading the full post or his newsletter which the post was an excerpt from (I highly recommend subscribing).

The past day or two there has been a lot of discussion about OpenAI calling for a ban on Chinese models/training processes in the United States. The overwhelming opinion on social media is anti-OpenAI, but I would recommend caution and taking time to think before agreeing with it.
Just like many things on social media, the nuance regarding this subject has been lost and the opinion echoed is that which is most engaging—not that which is most correct (occasionally these align, but not usually). There are real security considerations the US must consider regarding foreign AI.
Controlling the spread of information comes with incredible power. The party with this control has the potential for tremendous influence. We’ve seen this throughout history through propaganda of various forms. This is also why there has been so much debate about the credibility of the mainstream media in the past 5-10 years.
LLMs are now a primary source of information. Therefore, the party with control of an LLM can influence those using it. Thus, if Chinese AI becomes the most popular in the US (or any other country), China (who is seen as an opponent to the US) can gain tremendous influence over US citizens.
We’ve already seen bias within Chinese LLMs. If you want to experience it for yourself, ask DeepSeek models about Tiananmen Square or Taiwanese sovereignty. This becomes more concern when you realized the potential for undetectable bias and influence to be present in LLM output.
This is the same argument in favor of banning TikTok. TikTok is also a primary source of information and I’d urge you to take the same factors into consideration when considering that argument. Again, the situation is much more complex than social media makes it seem.
In fact, both arguments seem cut-and-dry to me based on the precedent China themselves have set. Regarding information control, China bans US products to ensure they don’t influence the Chinese population. Regarding TikTok, China doesn’t allow it themselves and instead promote a better alternative.
The counterargument I see frequently is that banning a competitor shouldn’t be necessary and we should let the free market play out. This isn’t an effective argument when national security is concerned. In this case, we don’t care about the outcome of competition, we care very much more about the impact of that outcome.
Giving a foreign country (whoever it is) too much influence over your own populace is a losing play with very severe consequences. I can’t understand anyone who doesn’t agree with this.
What baffles me most about this anti-OpenAI argument is that it’s the same people using Chinese model releases on social media for clicks because of the dire consequences of China beating the US in AI that are also against OpenAI’s statement about China beating the US having dire consequences.
The arguments entirely against OpenAI fail to consider the power of information control and the national security threats it raises. This is expected on social media, but as a reader of Society’s Backend, I want you to be more informed.
In case you missed last week’s update, here it is: Apple Pushing Their AI Back Isn't as Bad as You Think.
Below is my entire reading list from this week as a thank you to my paid subscribers. You can support Society’s Backend from just $3/mo and get the entire list each week. Don’t forget that your company might have a learning budget you can use to do so!
