


Retrieval-augmented generation (RAG) has emerged as a crucial technique for enhancing large language models (LLMs) to handle specialized knowledge, provide current information, and adapt to specific domains without altering model weights. However, the current RAG pipeline faces significant challenges. LLMs struggle with processing numerous chunked contexts efficiently, often performing better with a smaller set of highly relevant contexts. Also, ensuring high recall of relevant content within a limited number of retrieved contexts poses difficulties. While separate ranking models can improve context selection, their zero-shot generalization capabilities are often limited compared to versatile LLMs. These challenges highlight the need for a more effective RAG approach for balancing high-recall context extraction with high-quality content generation.
In prior studies, researchers have made numerous attempts to address the challenges in RAG systems. Some approaches focus on aligning retrievers with LLM needs, while others explore multi-step retrieval processes or context-filtering methods. Instruction-tuning techniques have been developed to enhance both search capabilities and the RAG performance of LLMs. End-to-end optimization of retrievers alongside LLMs has shown promise but introduces complexities in training and database maintenance.
Ranking methods have been employed as an intermediary step to improve information retrieval quality in RAG pipelines. However, these often rely on additional models like BERT or T5, which may lack the necessary capacity to fully capture query-context relevance and struggle with zero-shot generalization. While recent studies have demonstrated LLMs’ strong ranking abilities, their integration into RAG systems remains underexplored.
Despite these advancements, existing methods need to improve in efficiently balancing high-recall context extraction with high-quality content generation, especially when dealing with complex queries or diverse knowledge domains.
Researchers from NVIDIA and Georgia Tech introduced an innovative framework RankRAG, designed to enhance the capabilities of LLMs in RAG tasks. This approach uniquely instruction-tunes a single LLM to perform both context ranking and answer generation within the RAG framework. RankRAG expands on existing instruction-tuning datasets by incorporating context-rich question-answering, retrieval-augmented QA, and ranking datasets. This comprehensive training approach aims to improve the LLM’s ability to filter irrelevant contexts during both the retrieval and generation phases.
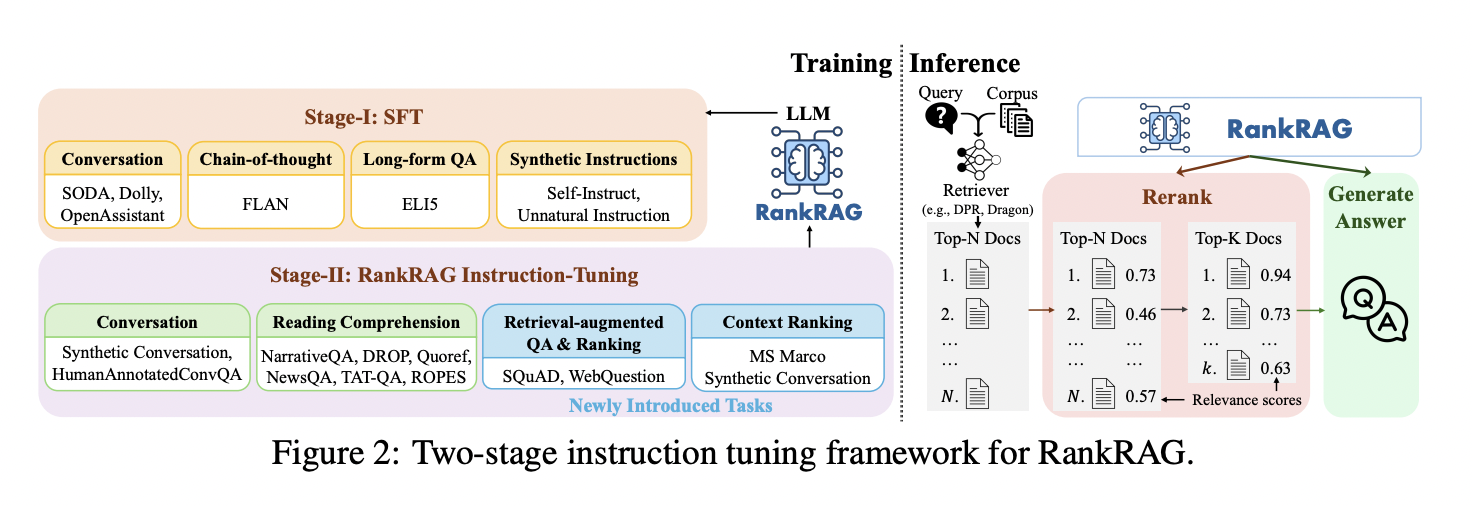
The framework introduces a specialized task that focuses on identifying relevant contexts or passages for given questions. This task is structured for ranking but framed as regular question-answering with instructions, aligning more effectively with RAG tasks. During inference, the LLM first reranks retrieved contexts before generating answers based on the refined top-k contexts. This versatile approach can be applied to a wide range of knowledge-intensive natural language processing tasks, offering a unified solution for improving RAG performance across diverse domains.
RankRAG enhances LLMs for retrieval-augmented generation through a two-stage instruction tuning process. The first stage involves supervised fine-tuning on diverse instruction-following datasets. The second stage unifies ranking and generation tasks, incorporating context-rich QA, retrieval-augmented QA, context ranking, and retrieval-augmented ranking data. All tasks are standardized into a (question, context, answer) format, facilitating knowledge transfer. During inference, RankRAG employs a retrieve-rerank-generate pipeline: it retrieves top-N contexts, reranks them to select the most relevant top-k, and generates answers based on these refined contexts. This approach improves both context relevance assessment and answer generation capabilities within a single LLM.
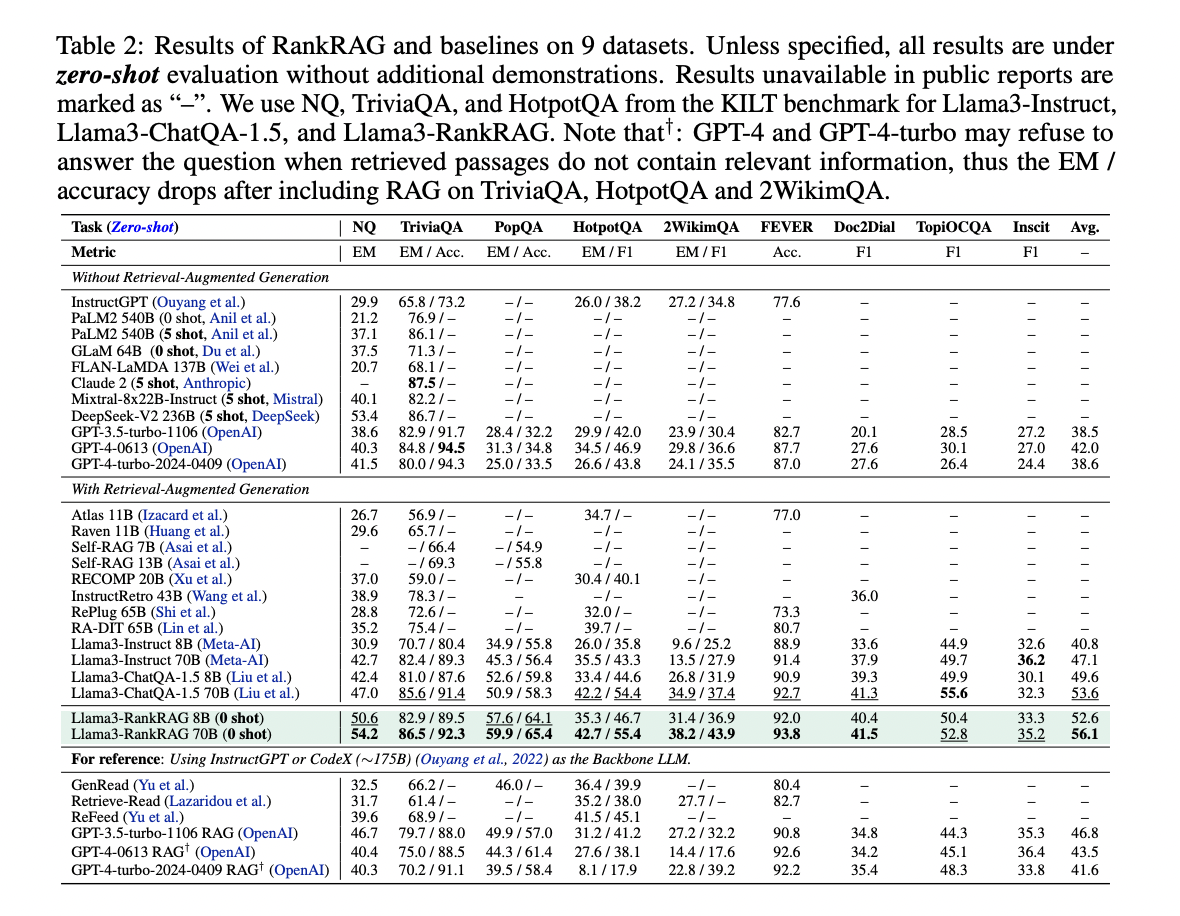
RankRAG demonstrates superior performance in retrieval-augmented generation tasks across various benchmarks. The 8B parameter version consistently outperforms ChatQA-1.5 8B and competes favorably with larger models, including those with 5-8 times more parameters. RankRAG 70B surpasses the strong ChatQA-1.5 70B model and significantly outperforms previous RAG baselines using InstructGPT.
RankRAG shows more substantial improvements on challenging datasets, such as long-tailed QA (PopQA) and multi-hop QA (2WikimQA), with over 10% improvement compared to ChatQA-1.5. These results suggest that RankRAG’s context ranking capability is particularly effective in scenarios where top retrieved documents are less relevant to the answer, enhancing performance in complex OpenQA tasks.
This research presents RankRAG, representing a significant advancement in RAG systems. This innovative framework instruction-tunes a single LLM to perform both context ranking and answer generation tasks simultaneously. By incorporating a small amount of ranking data into the training blend, RankRAG enables LLMs to surpass the performance of existing expert ranking models. The framework’s effectiveness has been extensively validated through comprehensive evaluations on knowledge-intensive benchmarks. RankRAG demonstrates superior performance across nine general-domain and five biomedical RAG benchmarks, significantly outperforming state-of-the-art RAG models. This unified approach to ranking and generation within a single LLM represents a promising direction for enhancing the capabilities of RAG systems in various domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our 46k+ ML SubReddit, 26k+ AI Newsletter, Telegram Channel, and LinkedIn Group.
If You are interested in a promotional partnership (content/ad/newsletter), please fill out this form.
The post NVIDIA Introduces RankRAG: A Novel RAG Framework that Instruction-Tunes a Single LLM for the Dual Purposes of Top-k Context Ranking and Answer Generation in RAG appeared first on MarkTechPost.
