

- Scientific News Letter-
科研成果速览

网络技术的持续发展对隐私保护和数据安全、处理提出了更高要求。如何运用新技术防范黑客攻击,保护数据安全,并提升数据处理效率是亟待解决的问题。交叉信息研究院高鸣宇研究组近期提出了隐私保护机器学习场景的神经网络架构搜索方法Seesaw,TEE环境下Path ORAM批量化加载算法Bulkor,高效图模式匹配框架PimPam,以及软硬件协同设计方案NDPBridge。该项成果分别发布于国际顶级会议ICML、S&P、SIGMOD、ISCA。
Seesaw:通过线性算子补偿非线性缺失的隐私保护机器学习推理 (ICML 2024)
随着数据隐私越来越被重视,基于隐私保护的机器学习应运而生。由于需要使用加密技术来保护用户数据隐私,因此其计算开销非常大,而主要瓶颈来源于非线性激活函数(如ReLU和Sigmoid)的计算。虽然现有工作试图通过减少非线性运算的数量来降低计算开销,但这往往会导致模型精度下降,使得模型精度和执行延迟之间不可兼得。
近期,高鸣宇研究组提出了一种用于隐私保护机器学习场景的神经网络架构搜索方法Seesaw,运用两种技术来解决上述困境:(1)增加更多的线性运算以恢复模型的表征能力;(2)通过残差连接重复使用已有的非线性运算的结果。Seesaw在搜索过程中考虑了线性运算的数量对在线/离线延迟的影响,并采用了新的搜索和训练策略来高效探索扩大后的搜索空间,最终得到最优的神经网络架构。
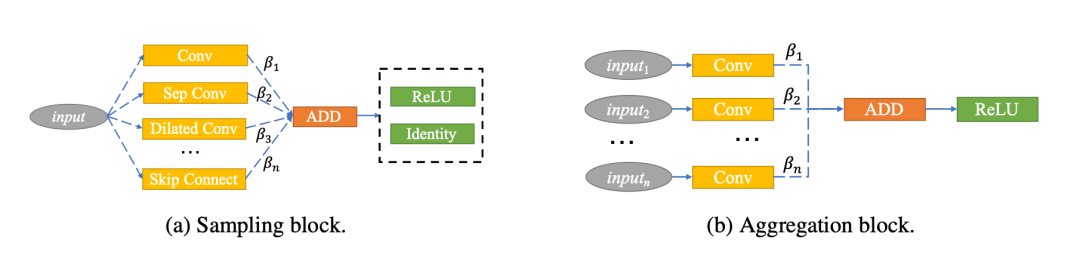
图:Seesaw检索空间的核心构建模块
实验证明,Seesaw能够显著提升模型精度与执行延迟之间的帕累托最优边界。在ImageNet上,相比最先进的同类工作SENet, Seesaw在相同71%精度下,在线延迟降低1.68倍;在相同190秒延迟下,精度提高3.65%。在CIFAR100上, Seesaw在相同70%精度下,在线延迟降低1.53倍;在相同8秒延迟下,精度提高0.25%。总之, Seesaw通过补偿非线性减少所带来的精度损失,突破了隐私保护机器模型中精度与延迟之间原有的折中,有助于更加高效地部署延迟敏感的应用。
论文题目:
Compensating for Nonlinear Reduction with Linear Computations for Private Inference
论文作者:
Fabing Li, Yuanhao Zhai, Shuangyu Cai,
Mingyu Gao
论文链接:
http://people.iiis.tsinghua.edu.cn/~gaomy/pubs/seesaw.icml24.pdf
BULKOR:使能ORAM的批量化加载
(S&P2024)
尽管现代加密和身份验证技术可以保护数据内容,但攻击者仍然可以通过仅观察敏感数据的访问模式来执行高级侧信道攻击,以获取私密信息。不经意随机访问存储(ORAM)协议,比如Path ORAM,是解决此问题的通用方案。ORAM可结合硬件安全技术例如可信执行环境(TEE),将客户端的部分控制逻辑放入TEE中,以减少网络通信成本。然而,与完全可信的客户端不同,TEE保护数据内容,但不保护其访问模式。在这种情况下,可信内存和不可信内存都需要做到不经意访问,这需要在TEE内设计更复杂的ORAM控制器。一些工作基于此设计了更高效的安全数据处理系统。但是很少有工作考虑到TEE环境下ORAM的初始化加载问题,此问题影响了ORAM的进一步应用。
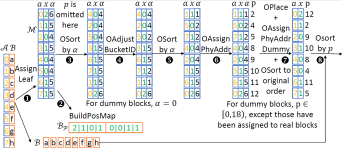
图:Path ORAM批量化加载算法示意图
由此,研究组提出了一个名为Bulkor的TEE环境下Path ORAM批量化加载算法,它从一开始就完全独立且随机地分配Path ORAM中每个数据块的路径。然后它根据先前分配的路径,高效和不经意地调整ORAM树中每个数据块的实际位置,以消除任何容量溢出问题。在此过程中无需更改先前分配的路径,从而不影响安全性。另外,所有块的分配和位置调整这些过程都是在元数据上进行的,位置固定后将最终位置信息提供给原数据块,因此对于数据块研究组只需做一次不经意排序,从而降低了性能开销。相对于之前的方案,研究组可将理论复杂度由降低到。实验结果显示其实际性能显着优于先前系统Oblix和ZeroTrace,达8.7至54.6倍和5.8倍至533.1倍。
论文题目:
BULKOR: Enabling Bulk Loading for Path ORAM
论文作者:
Xiang Li, Yunqian Luo, Mingyu Gao
论文链接:https://people.iiis.tsinghua.edu.cn/~gaomy/pubs/bulkor.s&p24.pdf
PimPam: 在真实存内计算硬件上的高效图模式匹配框架 (SIGMOD 2024)
在大数据时代,图是对数据内在关联性的有效刻画,也是许多领域研究对象的高度抽象,例如社交网络、生物数据等都可以抽象为图。图模式匹配则是分析和提取图内信息的有效手段之一,有着广泛的应用。基于传统CPU的图模式匹配效率往往受到内存带宽的限制,近年来兴起的存内计算架构提供的高带宽和低访问时延有效解决了这一问题,但其有限的内存容量和通信限制也对研究者提出了新的挑战。
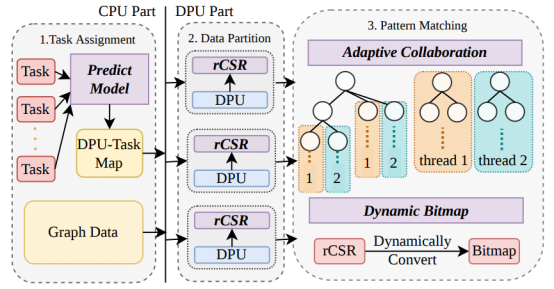
图:PimPam框架示意图
高鸣宇课题组提出了首个基于真实存内计算硬件的高效图模式匹配框架PimPam。PimPam基于UPMEM这一架构,相比传统的实现做了四个创新,以解决诸如负载均衡、数据分配等问题:
1)PimPam提出了一个高效的模型来预测每个任务的工作量,从而实现任务的均匀分配。
2)PimPam设计了一种新的数据格式,更加紧凑地表示每个子图,有效地利用了每个计算单元有限的内存容量。
3)每个计算单元内部使用了一种自适应的协作算法,根据数据特点动态调整线程的协作方式,避免了并行度退化问题。
4)PimPam会动态地构建和销毁子邻接矩阵的位图表示,在有限内存限制下进一步加速特定模式的匹配速度。
论文题目:
PimPam: Efficient Graph Pattern Matching on Real Processing-in-Memory Hardware
论文作者:
Shuangyu Cai, Boyu Tian, Huanchen Zhang,
Mingyu Gao
论文链接:http://people.iiis.tsinghua.edu.cn/~gaomy/pubs/pimpam.sigmod24.pdf
NDPBridge:在近 DRAM Bank 处理架构中的跨 Bank 协调支持 (ISCA 2024)
近数据处理架构是一条缓解内存墙问题、降低内存访问开销的重要技术路线。其中,近DRAM bank架构在DRAM bank附近集成计算逻辑,每个bank及其周围的计算逻辑构成独立单元,可以高效并行访问和处理数据。但是,近DRAM bank架构同样面临两点主要挑战。首先,不同的单元互相隔离,无法进行跨单元通信。此外,由于系统由上千个单元组成,单元间的负载均衡也需要得到高效支持。
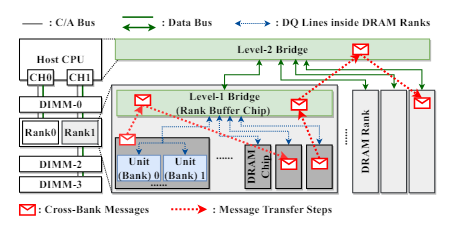
图:NDPBridge整体架构
高鸣宇课题组提出一种软硬件协同设计方案NDPBridge,在硬件层面,引入硬件桥,通过复用DRAM内部现有硬件接口和连线资源,在DRAM内部支持了跨bank传输。在软件层面,在上述硬件通讯机制基础上,他们设计了层次化和数据传输感知的调度方案,高效支持了跨单元负载均衡。
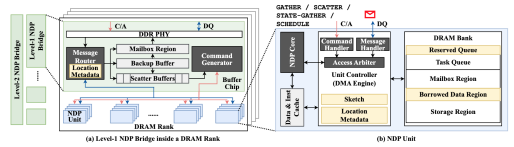
图:NDPBridge中NDP单元和桥接部分的详细硬件结构
NDPBridge在性能、开销和适用性等方面具有显著优点,具体包括:1. 相较于现有近DRAM bank处理方案,实现了平均2.23倍、最高2.98倍性能提升。2. 硬件修改开销较小,对于DRAM内部芯片的尺寸和接口没有修改,且所有的修改均限制在现有的近数据处理产品修改过的硬件模块中。3. 该架构对软件适配性较好,可应用至多种类型的应用和不同的数据规模。此外,由于该架构实现了自动的跨单元通信优化和负载均衡,大大降低了上层程序员的编程负担。
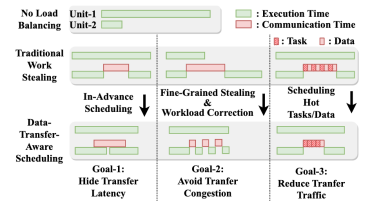
图:三个数据传输感知调度的关键设计
论文题目:
NDPBridge: Enabling Cross-Bank Coordination in Near-DRAM-Bank Processing Architectures
论文作者:
Boyu Tian, Yiwei Li, Li Jiang, Shuangyu Cai,
Mingyu Gao
论文链接:
https://people.iiis.tsinghua.edu.cn/~gaomy/pubs/ndpbridge.isca24.pdf
研究组简介

高鸣宇现为清华大学交叉信息研究院助理教授,博士生导师。博士毕业于美国斯坦福大学。研究方向为计算机系统结构。其课题组尤其关注人工智能和大数据等数据密集型应用,围绕数据的“安全、存储、计算”三个维度,探索新一代计算机硬件架构与软件系统的设计与优化。具体而言,高鸣宇研究组在数据安全方面,结合通用处理器可信执行环境和密码学算法专用加速硬件两条路线,构建安全高效的新一代计算系统;在数据存储方面,以存算一体和异构存储两种新型架构为核心,提出一系列硬件创新设计与软件优化技术;在数据计算方面,面向神经网络、图计算、稀疏张量等关键数据算法,设计多种高效的专用加速硬件架构和编译软件框架。课题组近五年在上述研究方向上发表了20余篇计算机系统方向的国际顶级学术会议论文,包括ISCA、ASPLOS、OSDI、SIGMOD等旗舰会议。部分科研成果已成功转化为初创公司。
编辑 | 姜月亮
审核 | 吕厦敏

