
接續Ampere架構與Ada Lovelace架構之後,Nvidia專業繪圖加速器產品線今年終於邁入Blackwell架構,在3月底舉行的GTC大會,該公司發表RTX Pro Blackwell系列,涵蓋工作站與資料中心GPU,運用加速運算、AI推論、光線追蹤,以及類神經渲染處理(neural rendering)等多項創新技術,重新定義AI、高科技、工程與設計等專業領域的工作流程。


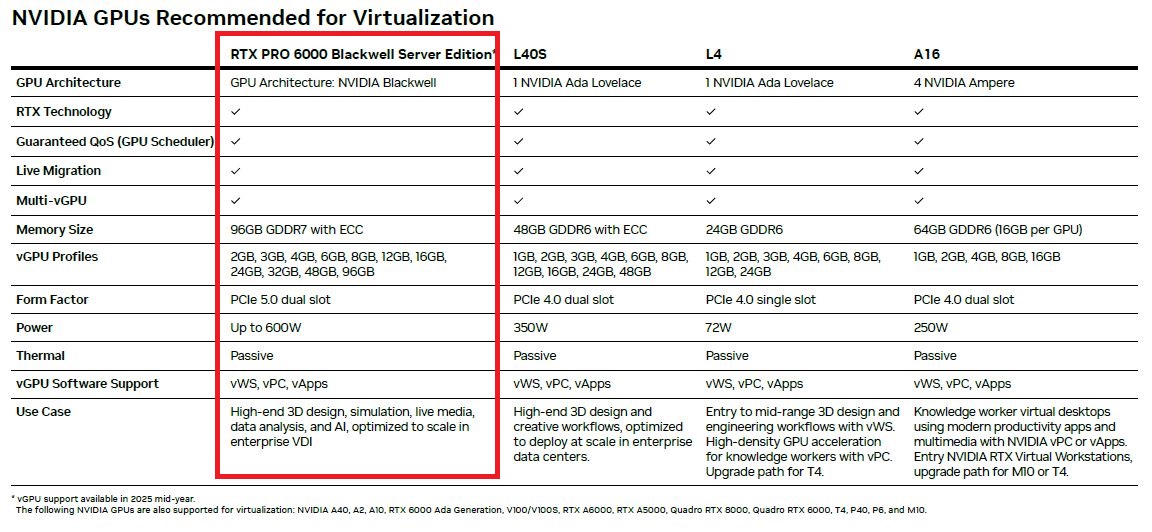
RTX Pro Blackwell系列細分為3大類型:資料中心GPU、桌上型電腦工作站GPU、筆電工作站GPU,首波5月上市的產品是桌上型電腦工作站GPU,包含:RTX Pro 6000 Blackwell Workstation Edition、RTX Pro 6000 Blackwell Max-Q Workstation Edition,這兩款最大差別在於熱設計功耗(600瓦 vs. 300瓦),以及散熱方式(雙風扇 vs. 單風扇);而RTX Pro 5000 Blackwell、RTX Pro 4500 Blackwell、RTX Pro 4000 Blackwell這三款產品,預計夏季供貨,目前Nvidia皆已在網站公開細部規格。
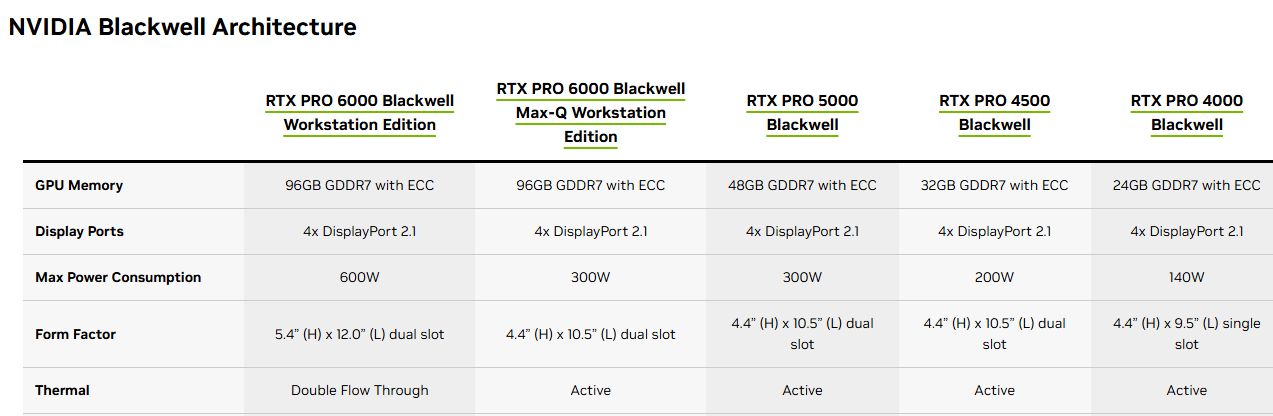

資料中心GPU產品RTX Pro 6000 Blackwell Server Edition,Nvidia只說很快就會推出,Nvidia僅在網站列出簡要規格;筆電GPU產品,則有RTX Pro 5000 Blackwell、RTX Pro 4000 Blackwell、RTX Pro 3000 Blackwell、RTX Pro 2000 Blackwell、RTX Pro 1000 Blackwell、RTX Pro 500 Blackwell,預計今年稍後推出。
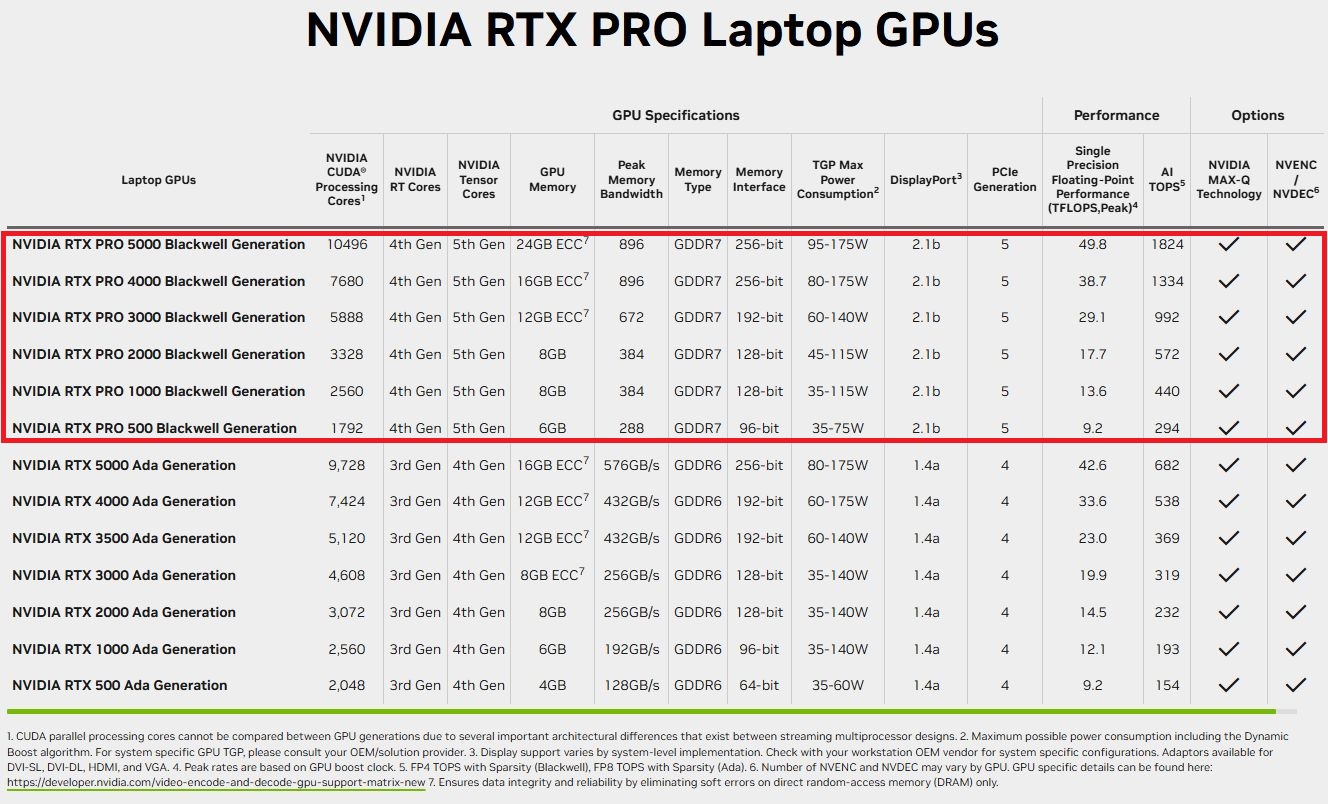
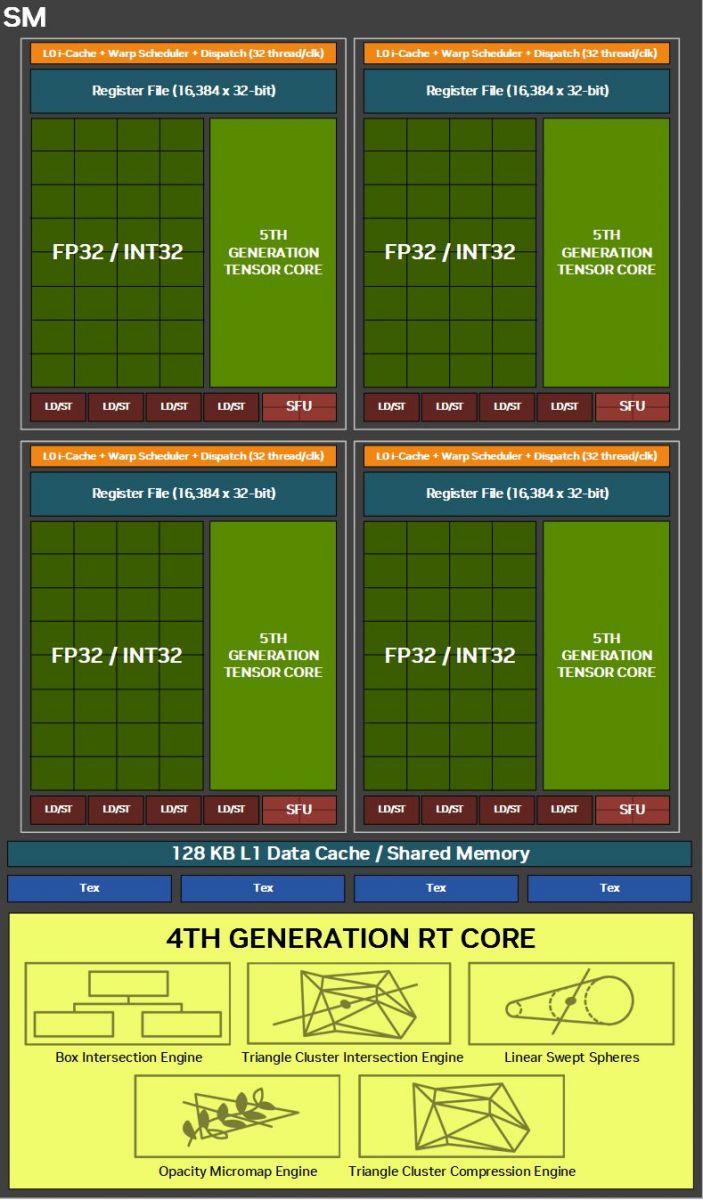
RTX Pro Blackwell系列GPU標榜8大特色,分別是:採用更大規模的串流多處理器(Streaming Multiprocessor,SM)、第五代Tensor核心、第四代RT核心、更大容量與更快速的記憶體GDDR7、多媒體編碼器NVENC第9代、多媒體解碼器NVDEC第6代、PCIe 5.0介面、DisplayPort 2.1視訊連接埠、GPU多執行個體(MIG)。除了MIG,其餘皆是今年1月推出的GeForce RTX 50系列主打的新功能。
關於運算組態的配置,這批GPU搭配的串流多處理器,吞吐量可提高1.5倍,並新增類神經著色器(neural shaders),能在可程式化著色器內部整合AI技術,帶動AI增強(AI-augmented)類型的繪圖處理應用。
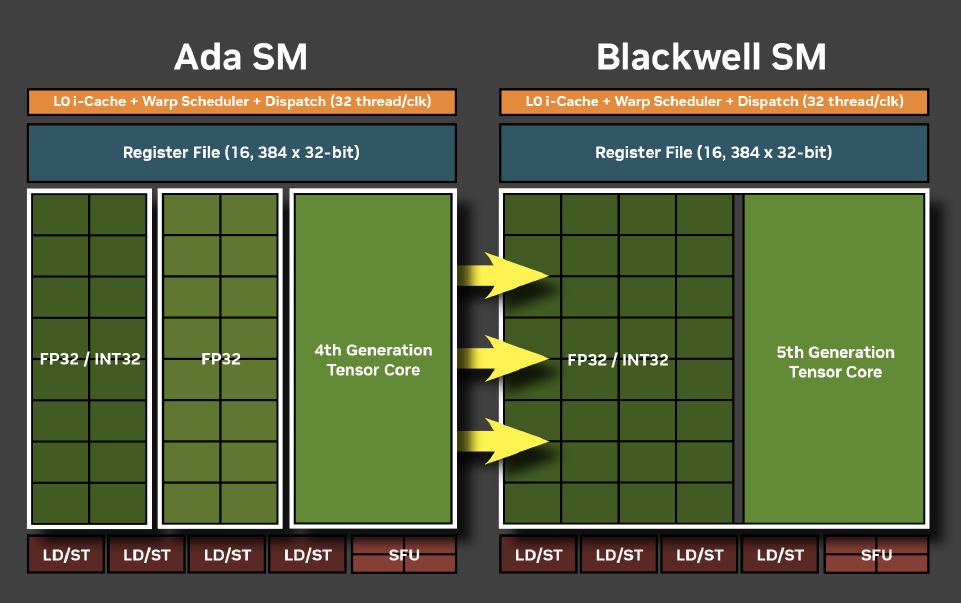
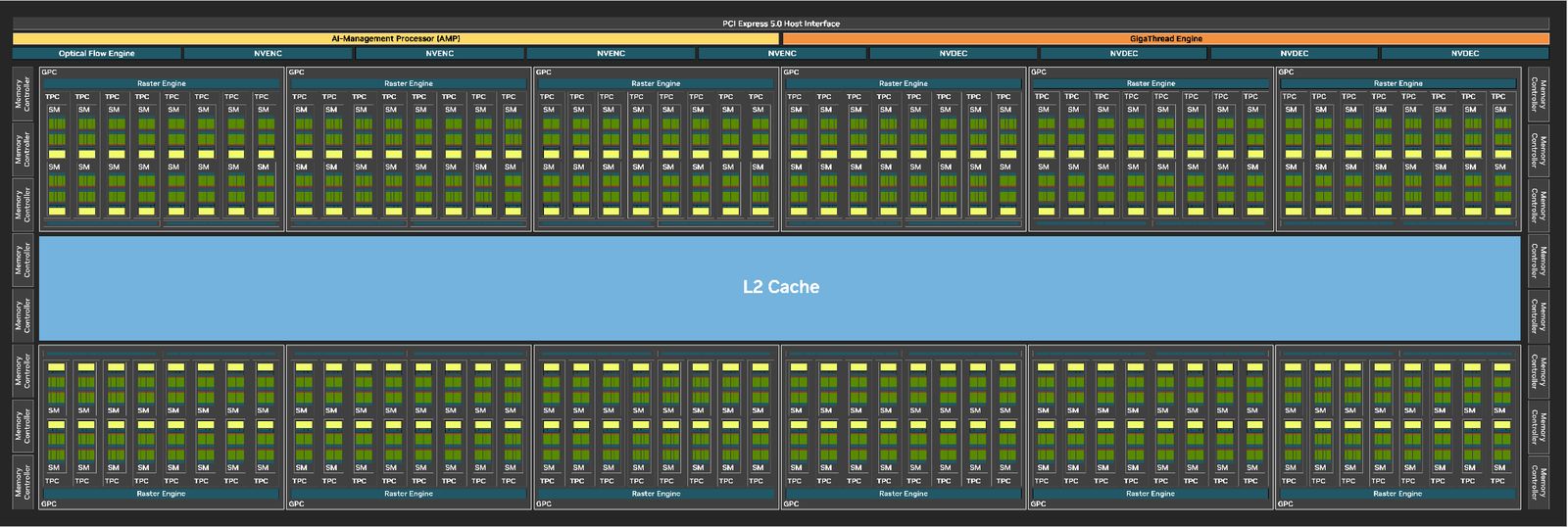
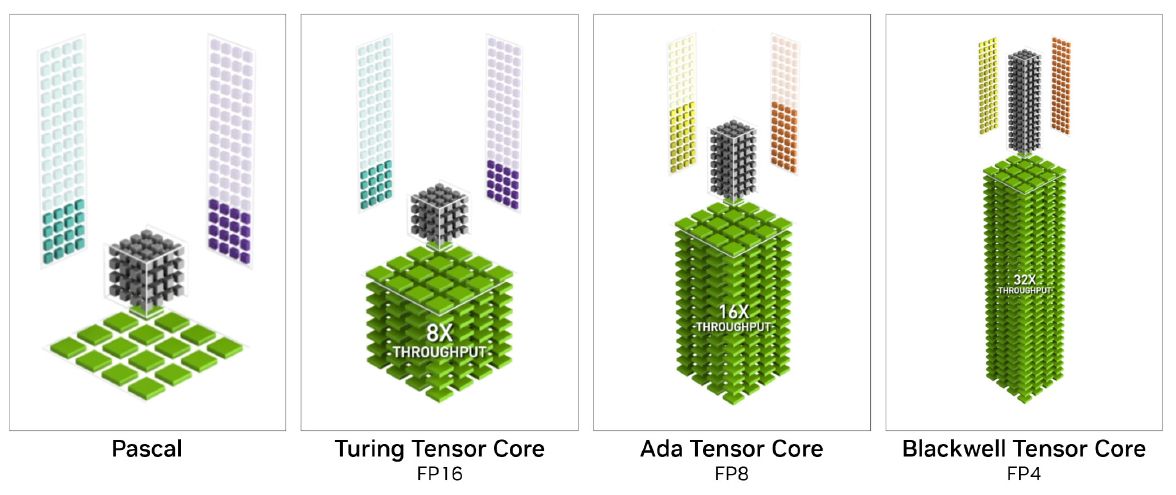
而在Blackwell架構引進的第五代Tensor核心當中,能為RTX Pro Blackwell系列GPU提供的AI運算效能,最高可達到4,000 TOPS,相較於上一代專業繪圖GPU產品,在大型語言模型的處理,可提供3倍的效能。
關於運算精度,除了既有專業繪圖GPU產品支援的FP16、BF16、TF32、INT8,以及Hopper架構GPU產品支援的FP8(Transformer Engine),第五代Tensor核心也增加FP4與FP6的處理,並提供類似資料中心GPU產品的第二代FP8 Transformer Engine。
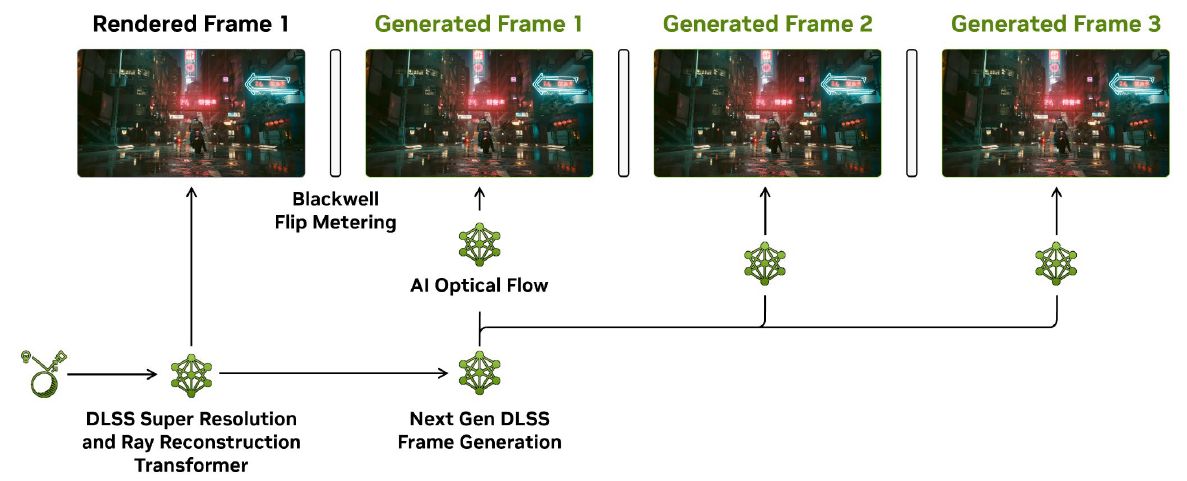
此外,第五代Tensor核心支援具有多畫格生成(Multi Frame Generation)功能的DLSS 4技術,可實現AI驅動的繪圖處理,也能針對更大規模AI模型提供執行的能力,以及加速此類應用的原型設計(prototype)。
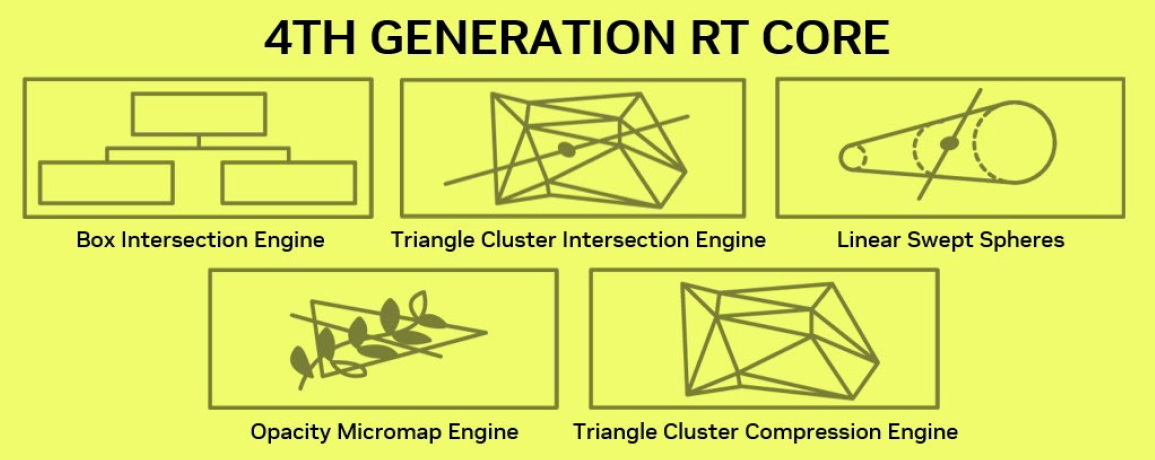
接著,我們看看RTX Pro Blackwell系列GPU搭配的第四代RT核心,導入Nvidia發展的RTX Mega Geometry技術(RTXMG),可在光學追蹤應用當中,大幅增加幾何學(geometric)的細節呈現與對應能力。
相較於Nvidia上一代專業繪圖GPU,在建立逼真圖像、具有物理等級精確度(physically accurate)場景,以及複雜的3D內容設計時,內建第四代RT核心的RTX Pro Blackwell系列GPU,可提供兩倍的處理效能——光線與三角形相交(ray-triangle intersection),若啟用RTXMG技術,光線追蹤三角形(ray-traced triangles)的處理效能可提升至100倍。
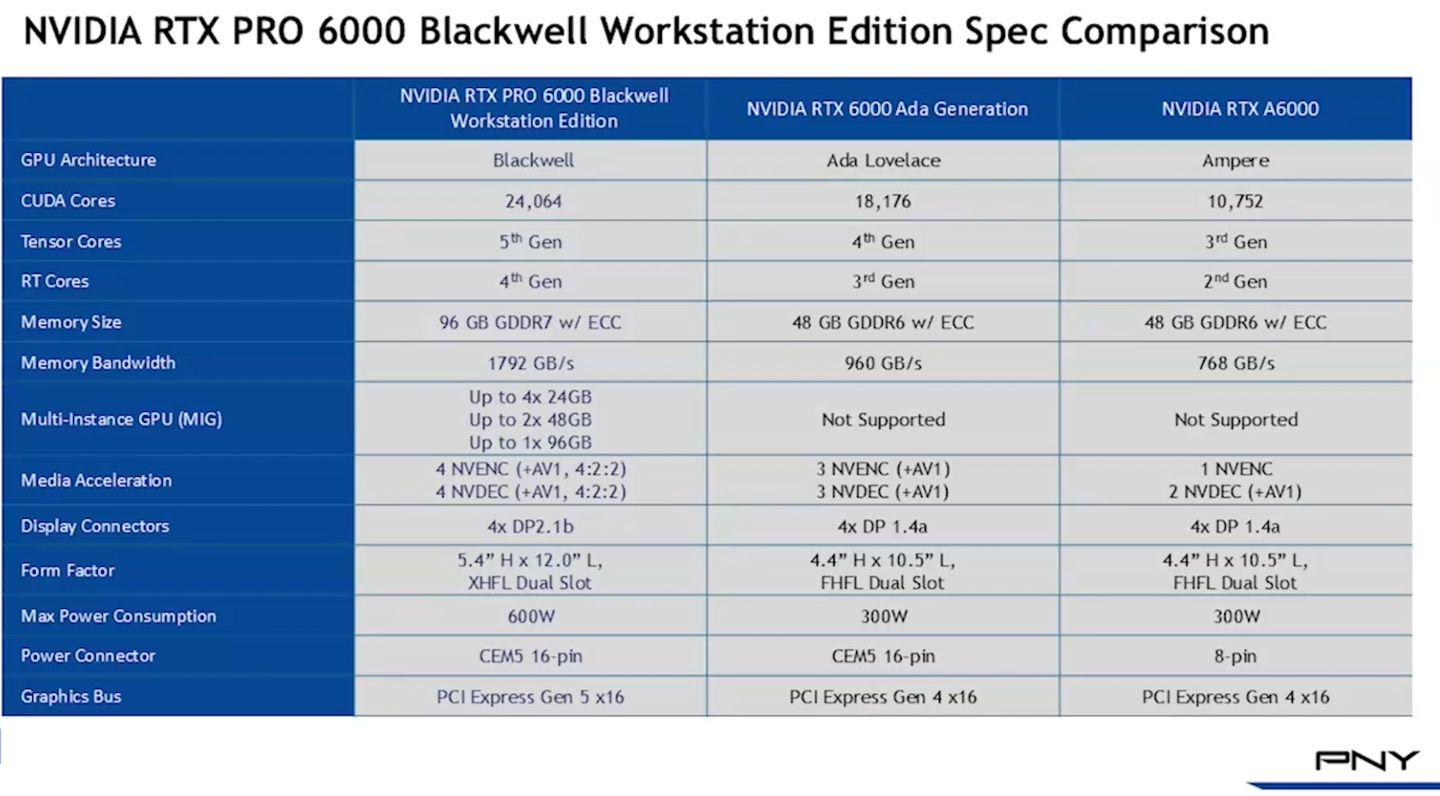
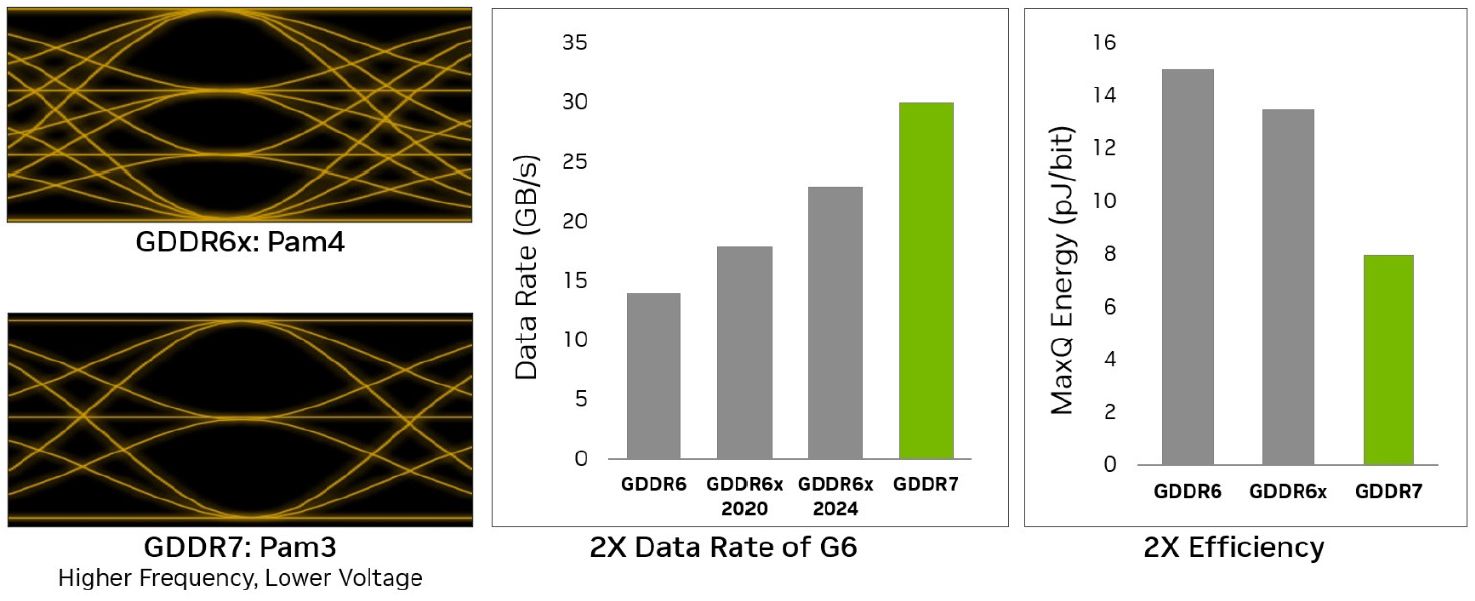
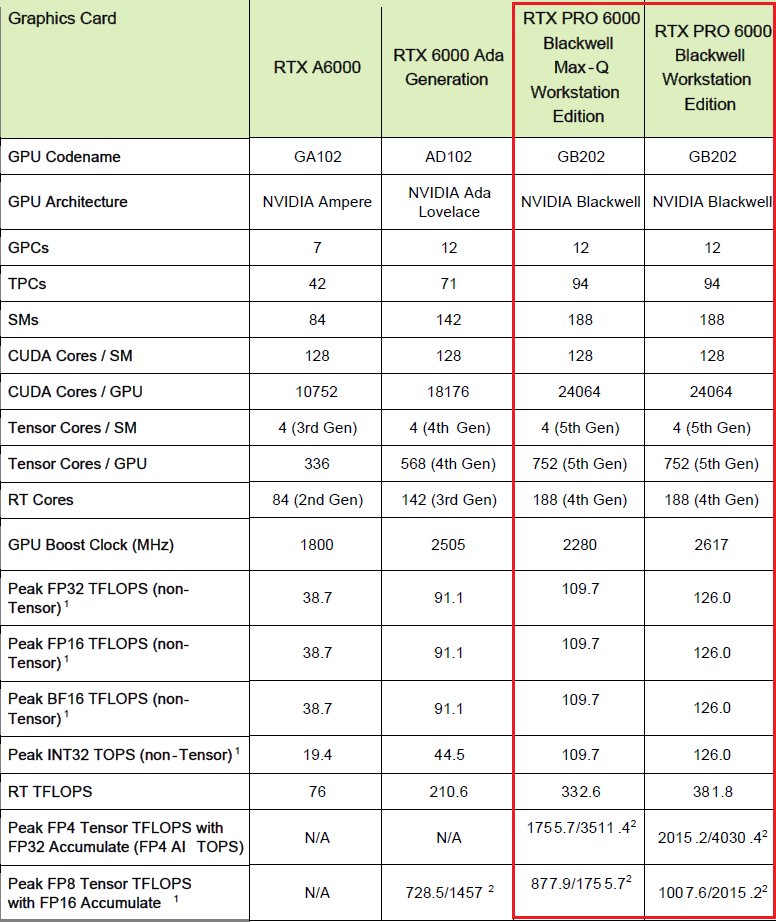
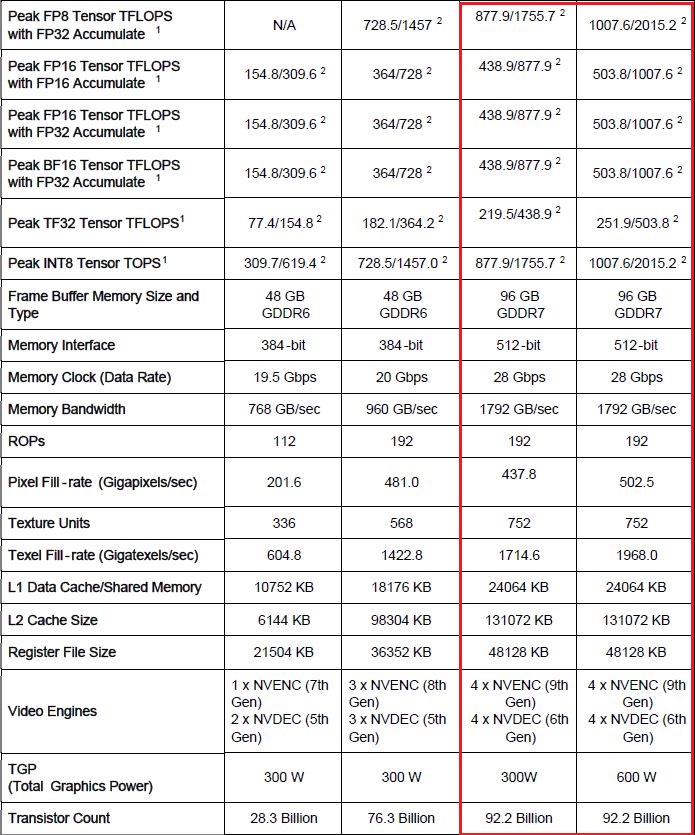
針對AI與大規模圖形運算最迫切需要的高速與大容量記憶體資源,RTX Pro Blackwell系列GPU搭配GDDR7記憶體,存取介面擴增至512位元(Ampere架構與Ada Lovelace架構GPU搭配GDDR6X記憶體,存取介面為384位元),頻寬可達1,792 GB/s(Ampere架構為936 GB/s,Ada Lovelace架構為1,008 GB/s)。
而在工作站與伺服器等級的GPU產品上,RTX Pro Blackwell系列最多可搭配96 GB的容量。在筆電等級的GPU產品上,RTX Pro Blackwell系列最多可搭配24 GB的容量。相較之下,Ampere架構與Ada Lovelace架構的專業繪圖GPU,最多搭配48 GB。
基於上述記憶體配置,RTX Pro Blackwell系列GPU可處理更大規模、複雜度更高的資料集,涵蓋巨型的3D與AI專案,以及大型虛擬實境應用。
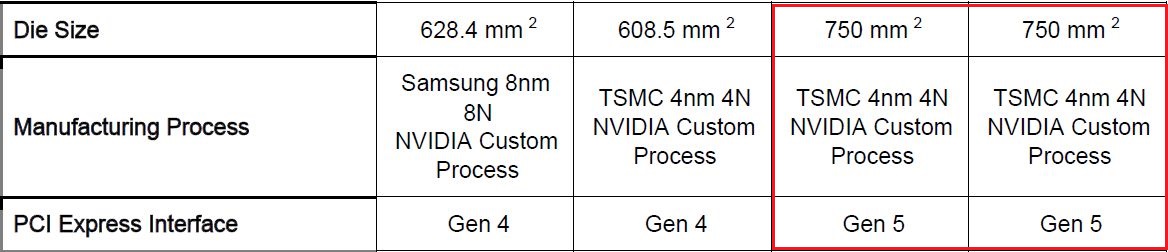
除了運算元件、記憶體的突破,RTX Pro Blackwell系列GPU另一個變革,在於支援PCIe 5.0介面,可運用兩倍的I/O頻寬,能改善與處理器、記憶體之間的傳輸速度,因應AI、資料科學、3D建模等資料密集型的任務。對照既有的Ampere架構與Ada Lovelace架構的專業繪圖GPU,均支援PCIe 4.0。
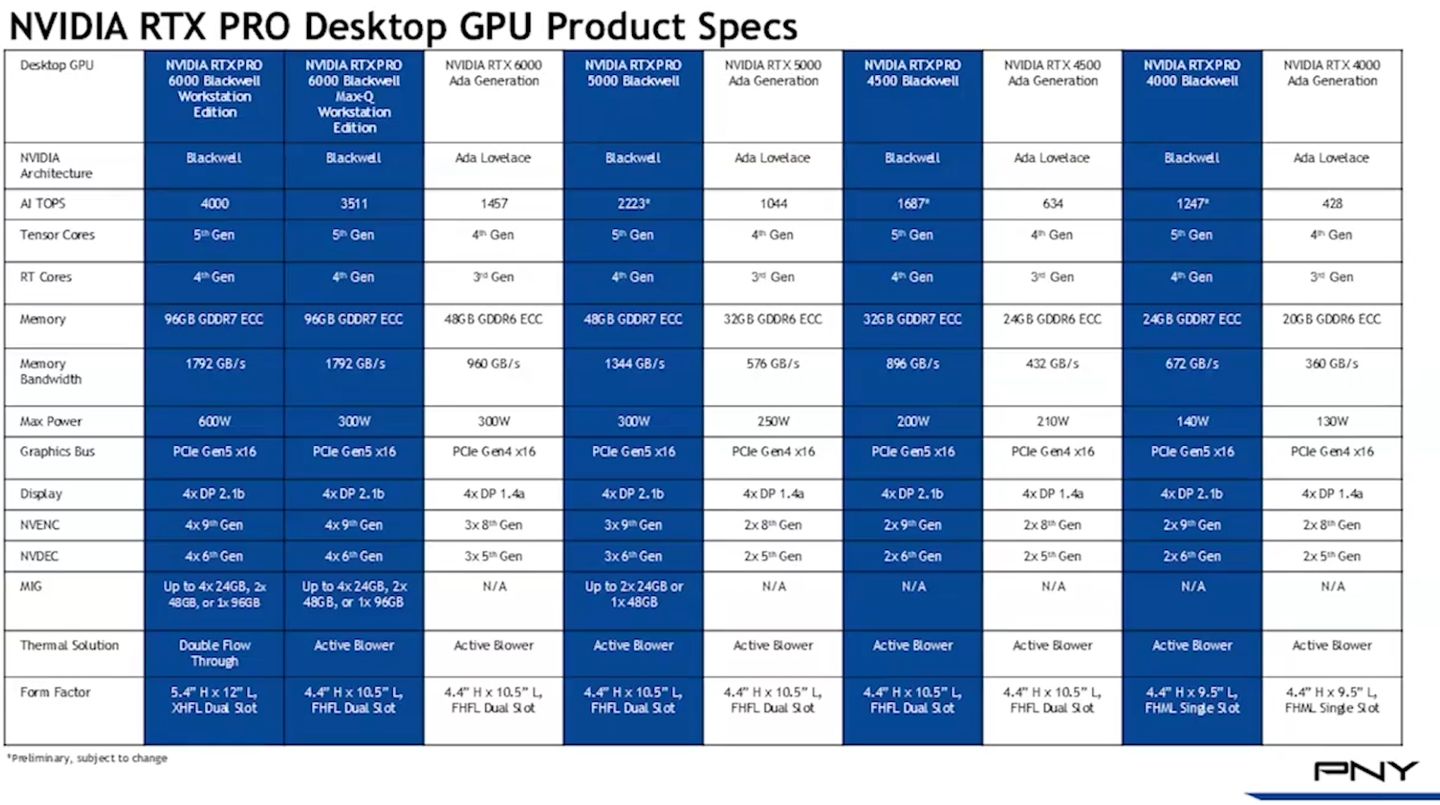
值得注意的是,過往Nvidia僅在資料中心GPU產品提供的GPU多執行個體功能,像是A100、A30、H100、H200、B200、GB200,如今在Blackwell世代的產品即將全面上市之際,終於下放至專業繪圖GPU。
根據Nvidia目前公開的產品資訊來看,RTX Pro Blackwell系列當中,RTX Pro Blackwell系列GPU的6000、5000均支援MIG。
其中,RTX Pro的資料中心GPU產品:6000 Blackwell Server Edition,以及桌上型電腦與工作站GPU產品:6000 Blackwell Workstation Edition與6000 Blackwell Max-Q Workstation Edition,皆可分割成2個各自配置48 GB記憶體的GPU,或4個各自配置24 GB記憶體的GPU;桌上型電腦與工作站GPU產品RTX Pro 5000 Blackwell,可分割成2個各自配置24 GB記憶體的GPU。
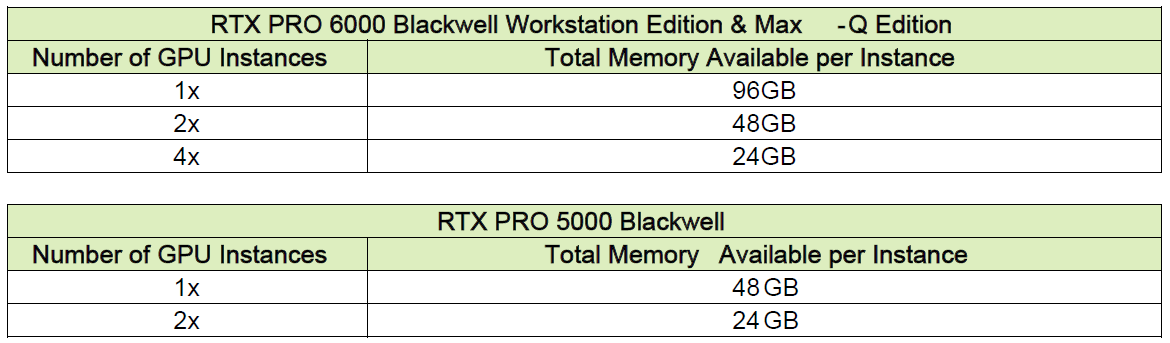
而且,這些GPU都是完全隔離的執行個體,具有專屬的記憶體、快取、運算核心,以及服務等級(QoS),加速運算資源的供應可藉此擴大範圍,涵蓋至每個使用者的需求,而且,能針對個別工作負載提供安全、有效率的資源分配,透過故障隔離(Fault isolation)機制,可預防彼此干擾,並獲得更充分發揮的效能與使用彈性。
關於多媒體資訊的處理,RTX Pro Blackwell系列GPU在傳輸介面的部分,支援DisplayPort 2.1(2.1b)的規格,能處理與呈現高解析度的視訊顯示需求,例如,解析度4K、更新率480 Hz的螢幕畫面,以及解析度8K、更新率165 Hz的螢幕畫面。Nvidia表示,增加的顯示頻寬可實現更流暢的多顯示器設定,而且,支援高動態範圍(HDR)與更高的色彩深度,能夠針對影片編輯、3D設計、網路視訊直播等任務,提供更精準的色彩呈現。
而在多媒體編碼加速的部分,RTX Pro Blackwell系列GPU內建Nvidia第9代編碼器,新支援H.264編碼、HEVC編碼的4:2:2色彩取樣方式,提升影片編碼處理的速度,以及改善專業繪圖應用程式的影片品質(HEVC編碼、AV1編碼)。
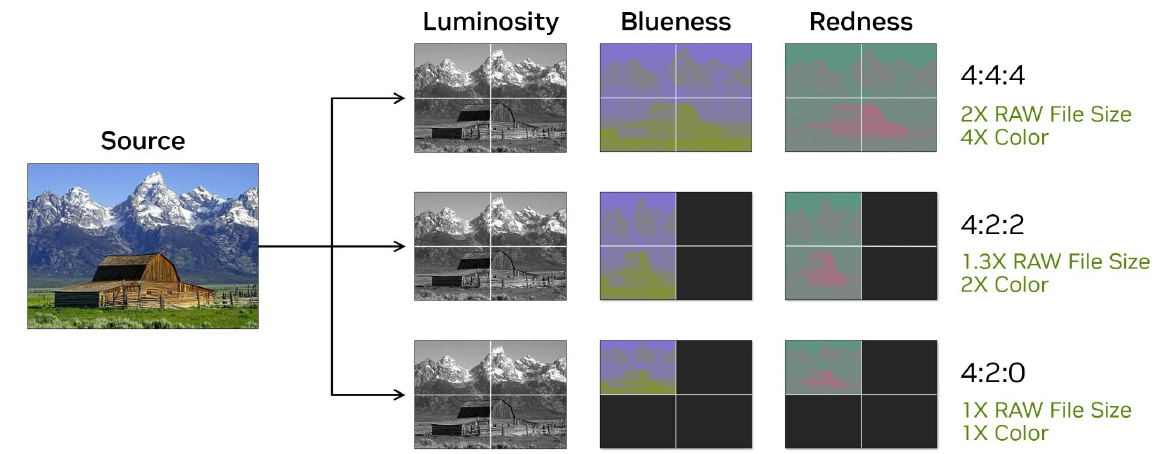
解碼加速的部分,這批GPU內建Nvidia第6代解碼器,針對H.264解碼、HEVC解碼的4:2:2色彩取樣,提供支援,而在處理H.264解碼工作的吞吐量,也能增加1倍。因此,能提供高畫質的影片播放、加速影片資料的擷取,以及運用進階、AI輔助的影片編輯功能。
產品資訊
Nvidia RTX Pro 6000 Blackwell
●原廠:Nvidia
●建議售價:廠商未提供
●版本:伺服器版、工作站版、Max-Q工作站版
●外形:雙槽,伺服器版與Max-Q工作站版均為長10.5吋高4.4吋,工作站版長12吋高5.4吋
●GPU架構:Blackwell
●CUDA處理核心數量:24,064個
●Tensor核心數量:伺服器版提供752個(第五代Tensor核心)
●RT核心數量:伺服器版提供188個(第四代RT核心)
●內建記憶體容量:96 GB GDDR7
●記憶體頻寬:伺服器版1,597 GB/s,工作站版、Max-Q工作站版1,792 GB/s
●連接介面:PCIe 5.0 x16
●支援NVLink:否
●單精度運算效能:伺服器版117 TFLOPS、工作站版125 TFLOPS、Max-Q工作站版110 TFLOPS
●RT核心效能:伺服器版354.5 TFLOPS、工作站版380 TFLOPS、Max-Q工作站版333 TFLOPS
●AI運算效能(FP4):伺服器版3.7 PFLOPS、工作站版4,000 TOPS、Max-Q工作站版3,511 TOPS
●視訊連接埠:2.1b版DisplayPort規格,4個
●視訊處理引擎:4個NVENC(第9代)、4個NVDEC(第6代)
●多執行個體GPU(MIG):4個24 GB記憶體或2個48 GB記憶體
●耗電量:工作站版600瓦,Max-Q工作版300瓦
●支援繪圖處理API:Shader Model 6.6、OpenGL 4.63、DirectX 12、Vulkan 1.3
●支援運算處理API:CUDA 12.8、DirectCompute、OpenCL 3.0
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
