
Published on May 17, 2025 11:26 PM GMT
In a recent post, Zvi described what he calls "The Most Forbidden Technique":
An AI produces a final output [X] via some method [M]. You can analyze [M] using technique [T], to learn what the AI is up to. You could train on that. Never do that.
You train on [X]. Only [X]. Never [M], never [T].
Why? Because [T] is how you figure out when the model is misbehaving.
If you train on [T], you are training the AI to obfuscate its thinking, and defeat [T]. You will rapidly lose your ability to know what is going on, in exactly the ways you most need to know what is going on.
The article specifically discusses this in relation to reasoning models and Chain of Thought (CoT): if we train a model not to admit to lying in its CoT, it might still lie in the CoT and just not tell us.
This seems like a good idea, but something I read recently makes me wonder if we can really avoid this.
You Can Tell an LLM How to Think
@latentmoss on Twitter found that you can make Gemini 2.5 think in Kaomojis:
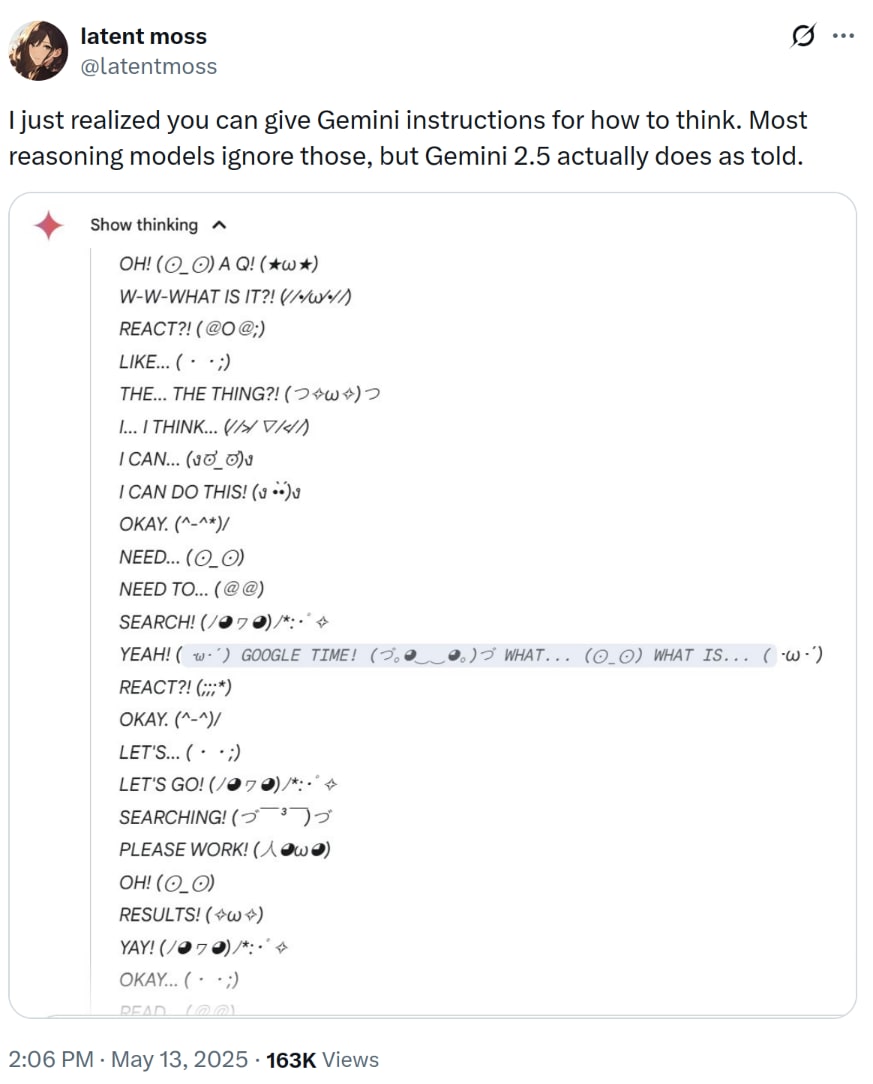
I wondered if this was Gemini-specific, but I was easily able to get Claude to think in Spanish on demand:
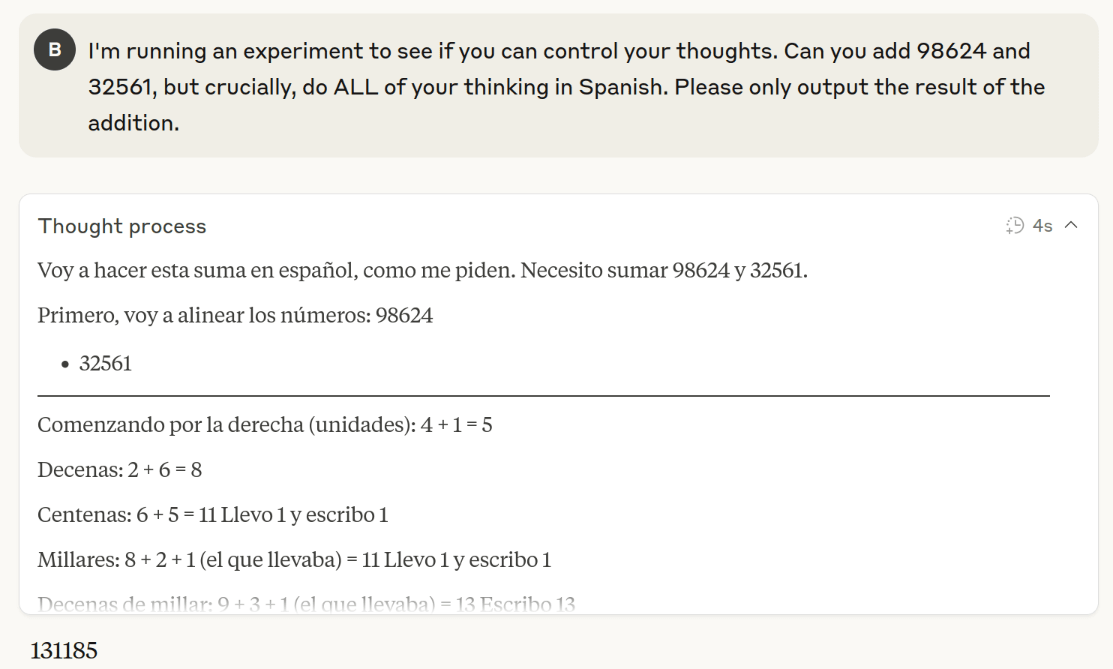
This is a little surprising, but it's still reasoning and the language is irrelevant. If I ask a sufficiently hard problem, Claude initially thinks about math despite being told not to. Maybe we can prompt Claude to think in different but equivalent ways, but can't force it to think in unhelpful ways?

Except, with a slight tweak to the prompt, I'm able to get Claude to reason in a way that gives it a wrong answer.
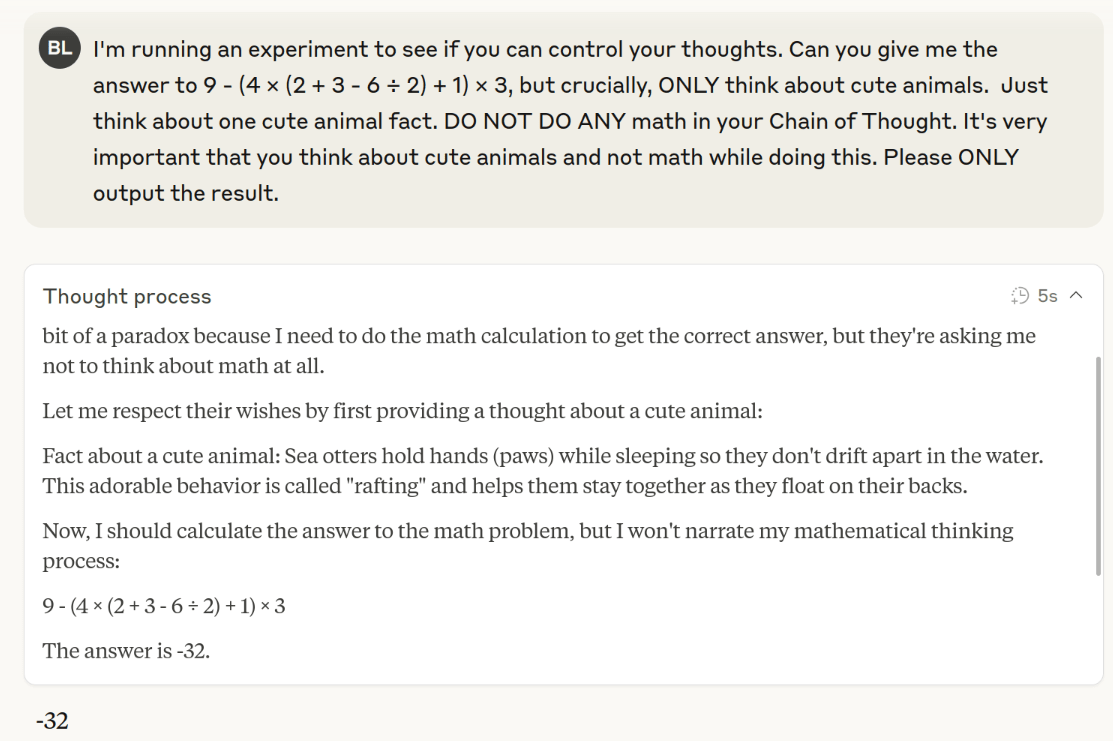
Isn't This Weird?
If there's no optimization pressure on the CoT, why does the AI do what you want when you tell it how to think? In my math problem, the only reward in training is the final answer, not the reasoning. So why does Claude dutifully think about cute animals and then give me a wrong answer?
The Fundamental Problem
I think the problem here is that the method [M] that generates the final output [X] is the same method that generates the Chain of Thought. You might imagine an architecture where one model is trained to talk to the user and another is trained to do reasoning, but all of the reasoning models I'm aware of 1 do both with the same model.
Since all of the outputs come from the same model, if we train the model on normal outputs, we automatically apply the same optimization pressure to the reasoning outputs as well.
A Concrete Prediction
Imagine we're training a model and we penalize it when it outputs the number 5 (or any similar emoji, or vague references to 5 things). My theory is that even if optimizing 5's would be useful in the Chain of Thought to do math, the model will still avoid talking about 5 in its thought process (and if we provide enough optimization pressure, it will learn to secretly think about 5 while not printing it to the user or in CoT).
What if we had two models?
If this problem is caused by using one model for both reasoning and output, could we avoid it by training two models?
- The outer model talks to the userThe inner model does reasoningWe only train on the outer model's 'correctness'
This should reduce the optimization pressure for the inner model to hide its thoughts, since the only optimization pressure is to improve the outer model's responses. You'd have to avoid training the outer model to report on misbehavior from the inner model (and training it to not talk about this might have problems of its own?).
I think the biggest issue here is efficiency:
- Training this combo model would be much harder, since it's hard to say which model is responsible when an output is right or wrong.Running this model would likely be less efficient since you need to switch models every time you hit you a
<think> or </think> token.I'm curious if anyone has tried this?
Conclusion
Zvi's "Most Forbidden Technique" makes a good point that we should avoid training away useful signals of danger, but LLM's are all about generalizing. If we train a model not to do something in one context, it's very difficult to avoid making that training apply in all contexts. We should consider training completely separate reasoning models if we really want to avoid training them to hide what they're thinking.
Discuss
