
DRUGAI
近期一项研究评估了人工智能(AI)生成的医疗语言中的偏倚问题,聚焦于年龄、性别和族裔等人口学特征的差异,并提出一种优化技术以在不降低模型性能的前提下提升其公平性。

人工智能正通过数据驱动的先进方法变革医疗行业,显著提升诊断、治疗与运行效率。其中,放射影像诊断与医疗文档自动生成是典型应用场景。然而,由于医疗数据本身存在结构性偏倚,AI 系统在这些任务中的部署面临公平性挑战。在该背景下,公平性被定义为:AI 系统在各类群体间(无论种族、性别、年龄等)输出结果需具备平等性与无偏倚性。尽管医学图像分类任务中的偏倚问题已引起广泛关注并取得进展,针对医疗文本生成(如放射学报告生成、医学摘要等)中的公平性研究仍相对匮乏。此类文本若存在偏倚,可能误导病史记录,加剧原有医疗不平等。例如,若病理报告训练出的模型低估少数群体的疾病风险,或将造成诊断延迟与健康结果恶化。
在《Nature Computational Science》上,Xiuying Chen 等人提出了一种选择性优化算法,旨在缓解不同群体间及多评价指标下的生成文本偏倚。该方法通过优先优化词汇重叠度与病理特征预测不佳的样本,显著降低不同群体之间的差异,同时保持整体生成性能。
研究在三个关键任务中评估了 AI 医疗文本生成的公平性:放射报告生成、报告摘要生成、科研论文摘要生成,涵盖交叉群体(如不同性别、年龄和族裔的组合)。结果表明,AI 生成的文本在历史上服务不足群体(如少数族裔老年患者)中的质量较低。为系统量化这种不平等,研究使用了两个指标:ROUGE(评估词汇重叠)与 CheXpert(评估临床准确性),并提出指标敏感公平差异(MFD),定义为不同群体中得分最高与最低者之间的差值。
为缓解偏倚,作者提出了选择性优化策略,基于两个标准平衡训练过程(如图 1b 所示):一是优先选取交叉熵损失值较高的低准确度样本;二是基于 ROUGE 和 CheXpert 分数对模型输出进行排序,引导模型更关注表现不佳样本,尤其是来自弱势群体的样本。该双重策略在提升模型整体性能的同时,有效增强了生成文本的公平性与临床可用性。
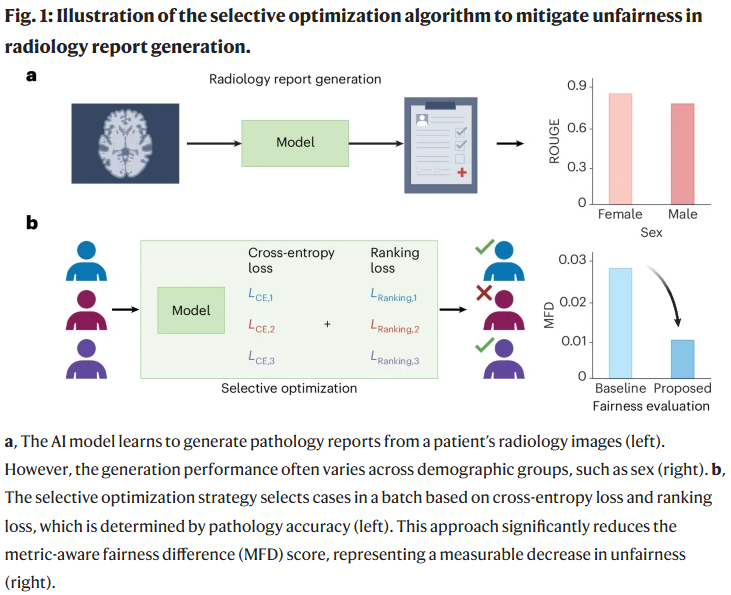
在 MIMIC 数据集上的放射报告生成与报告摘要任务中,应用选择性优化算法后,多个评估指标下的公平性差异(MFD)得分显著下降,较基线模型平均提升达 35.27%。该算法有效缓解了性别(女性与男性)、年龄(年轻人与老年人)及种族(黑人与白人)之间的文本生成偏差,尤其在交叉群体中(例如年长的少数族裔女性)也取得了明显的公平性改进。在 PubMed 数据集的科研论文摘要生成任务中,该方法同样展现出在不同年龄或物种背景下平衡生成质量的能力,即使应用于不同规模的模型也依然有效。整体而言,该框架在提高公平性的同时,保持了文本生成的性能稳定性,并增强了模型的稳健性。
尽管 Chen 等人提出的算法在应对医疗文本生成偏倚方面表现出显著前景,但仍存在若干需要进一步探讨的局限性。首先,该方法依赖于精心整理的公开数据集,可能难以充分体现真实临床场景中的复杂性。其次,已有在医学图像分类中应用的去偏方法(如建模潜在数据分布或数据增强技术)在本研究中尚未被引入。此外,受不公平性影响的其他关键任务(如医学视觉问答、医学语言翻译)未被纳入研究范畴。
除 MFD 指标外,已有研究提出“公平性感知性能(fairness-aware performance)”这一指标,用于量化不同群体之间的性能不平等。然而,无论是 MFD 还是其他公平性评估方式,其准确性高度依赖于语义与临床准确性的评估标准。进一步而言,诸如种族、语言、环境、社会经济状况等因素,也会在医疗实践与数据中引入额外偏倚,从而加剧实现公平 AI 系统的难度。
尽管彻底消除临床文本生成中的不公平性仍任重道远,该研究提供了一种切实可行的缓解策略,在减少人口群体偏倚影响方面迈出关键一步。未来研究方向包括将选择性优化策略推广至更具代表性的真实世界数据集,进一步微调模型以更好地服务于代表性不足人群;同时探索融合公平性的模型架构设计、领域自适应技术以及更加完善的公平性评估准则。研究者还需警惕在追求公平性时对临床准确性的“过度修正”,特别是在将先进的大语言模型(LLMs)部署于医疗场景中时。
通过加强人工智能研究者、临床医生与伦理学家的跨学科合作,研究人员有望推动医疗文本生成系统向更加公平、高效且临床可靠的方向发展,最终转变医疗服务模式与质量。
整理 | WJM
参考资料
Zhang, Y., Song, J. Toward fair AI-driven medical text generation. Nat Comput Sci (2025).
https://doi.org/10.1038/s43588-025-00807-8
内容中包含的图片若涉及版权问题,请及时与我们联系删除
